[Hadoop] HDFS - Hadoop Distributed File System
写在前面
一、历史演进
过时笔记:[Spark] 01 - What is Spark
三大模块:HDFS, MapReduce, Yarn
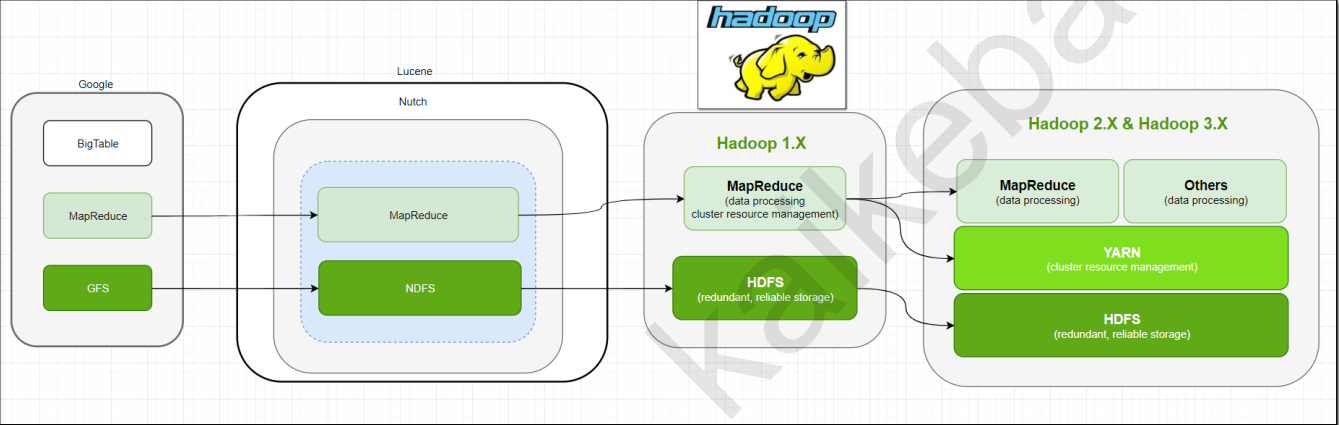
大数据学习技术栈:
| 大数据业务实践 | 项目实践 |
| Echarts.js, D3.js, 开源报表系统 | 可视化 |
| Sqoop, DataX | ETL |
| Mahout, Hive, Pig, R 语言, MLib | 分析与挖掘 |
|
MapReduce, Storm, Impala, Tez, Presto, Spark, Spark Streaming |
数据计算 |
| HDFS, Hbase, Cassadra | 数据存储 |
| Flume, Kafka, Scribe | 数据收集 |
二、发起人
比此人更牛的自然是Google内部的两个神秘人(博士Uri Lerner和工程师Mike Yar)。
有能力用c++语言级别写出整套分布式框架的公司不多,大部分还是依赖于Java平台。
Ref: [Distributed ML] Yi WANG's talk

三、配置文件
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
NameNode
一、Metadata
链接:https://www.jianshu.com/p/4ee877c14957
元数据就是数据的数据。
元数据管理有两种方式。集中式管理和分布式管理。集中式管理是指在系统中有一个节点专门司职元数据管理,所有元数据都存储在该节点的存储设备上。所有客户端对文件的请求前,都要先对该元数据管理器请求元数据。分布式管理是指将元数据存放在系统的任意节点并且能动态的迁移。对元数据管理的职责也分布到各个不同的节点上。大多数集群文件系统都采用集中式的元数据管理。因为集中式管理实现简单,一致性维护容易,在一定的操作频繁度内可以提供较满意的性能。缺点是单一失效点问题,若该服务器失效,整个系统将无法正常工作。而且,当对元数据的操作过于频繁时,集中的元数据管理成为整个系统的性能瓶颈。
分布式元数据管理的好处是解决了集中式管理的单一失效点问题,而且性能不会随着操作频繁而出现瓶颈。其缺点是,实现复杂,一致性维护复杂,对性能有一定影响。
二、Secondary Namenode
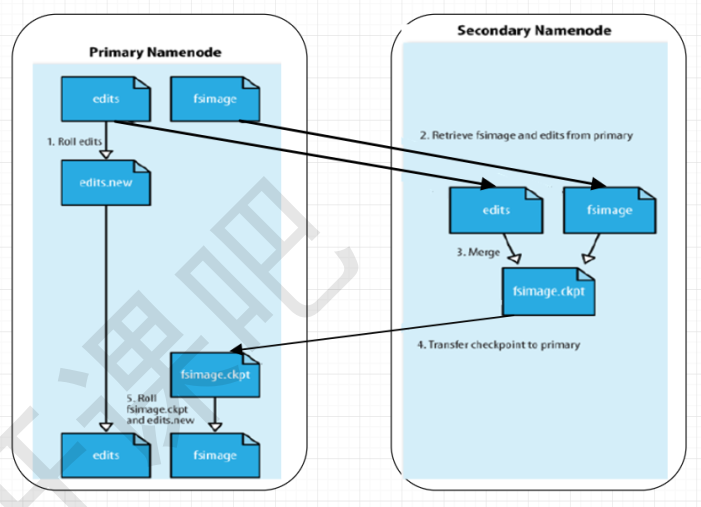
current文件夹下对应的文件:
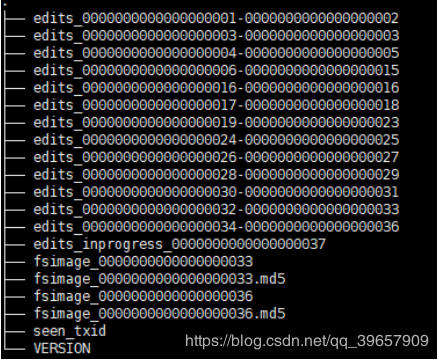
1. Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息;
2. Fsimage.md5文件:是镜像文件的 md5 校验文件,这个校验文件是为了判断镜像文件是否被修改;
3. Edits文件:存放HDFS文件系统的所有更新操作,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
4. seen_txid文件:它代表的是 namenode 里面的 edits_* 文件的尾数,namenode 重启的时候,会按照 seen_txid 的数字, 循序从头跑 edits_0000001~ 到 seen_txid 的数字。
5. VERSION文件:记录了当前NameNode的一些信息。
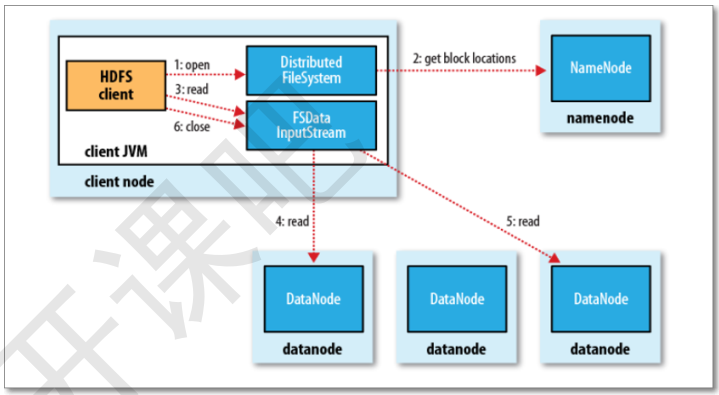
三、读写流程
Writing 流程
NameNode提供了块信息、冗余备份信息、DataNode list等。
这里涉及到:data queue, ack queue。
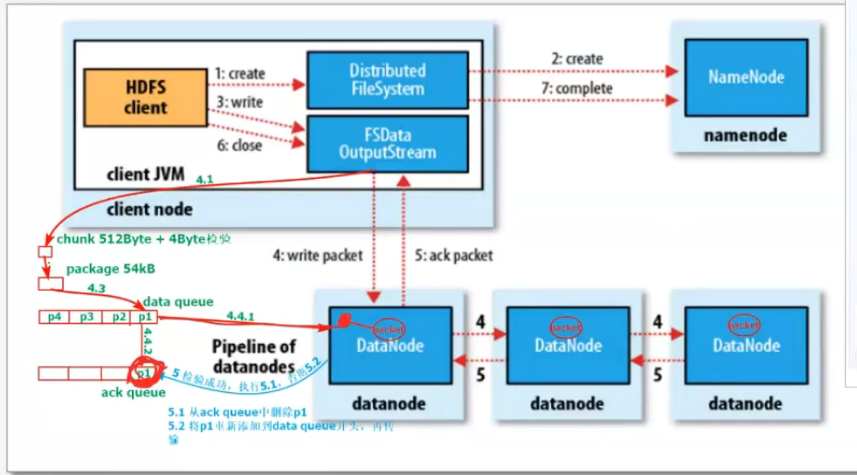
Reading 流程
四、Fault Recovery
涉及到:心跳机制、高可用和联邦。
Ref: Hadoop NameNode 高可用 (High Availability) 实现解析
链接中内容适合另开一篇文章学习。
交互命令与编程
基本操作
Ref: HDFS Commands Guide
一、上传本地文件
hdfs dfs -put alice.txt holmes.txt frankenstein.txt books

二、下载到本地
hdfs dfs -get /hdfsPath /localPath
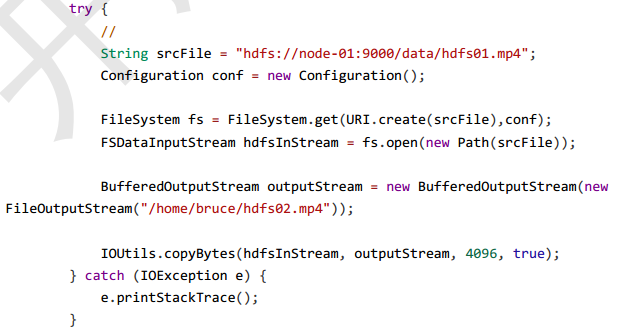
三、常见问题
文件具体保存在哪个物理块?
Goto: Hadoop中的FileStatus、BlockLocation、LocatedBlocks、InputSplit


hadoop@node-master:~$ hdfs fsck /alice.txt -files -blocks -locations Connecting to namenode via http://node-master:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Falice.txt FSCK started by hadoop (auth:SIMPLE) from /192.168.56.2 for path /alice.txt at Thu Oct 24 23:12:07 AEDT 2019 /alice.txt 173595 bytes, replicated: replication=2, 1 block(s): OK 0. BP-1744165533-192.168.56.2-1571910405666:blk_1073741825_1001 len=173595 Live_repl=2 [DatanodeInfoWithStorage[192.168.56.102:9866,DS-c46e8bf7-6e6b-4307-9fd3-87366ecb33de,DISK], DatanodeInfoWithStorage[192.168.56.101:9866,DS-67f3e0a5-e281-401f-b5d9-f1edae42eb33,DISK]] Status: HEALTHY Number of data-nodes: 3 Number of racks: 1 Total dirs: 0 Total symlinks: 0 Replicated Blocks: Total size: 173595 B Total files: 1 Total blocks (validated): 1 (avg. block size 173595 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 2.0 Missing blocks: 0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Erasure Coded Block Groups: Total size: 0 B Total files: 0 Total block groups (validated): 0 Minimally erasure-coded block groups: 0 Over-erasure-coded block groups: 0 Under-erasure-coded block groups: 0 Unsatisfactory placement block groups: 0 Average block group size: 0.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 FSCK ended at Thu Oct 24 23:12:07 AEDT 2019 in 15 milliseconds The filesystem under path '/alice.txt' is HEALTHY
其他操作
一、hdfs与getconf结合使用
hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs getconf -namenodes node-master hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs getconf -confKey dfs.namenode.fs-limits.min-block-size 1048576 hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs getconf -nnRpcAddresses
node-master:9000
二、安全模式
三个datanode,为何有一个没启动?
hadoop@node-master:/usr/local/hadoop/data/nameNode$ Safe mode is ON hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs dfsadmin -safemode enter Safe mode is ON hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs dfsadmin -report Safe mode is ON WARNING: Name node has detected blocks with generation stamps in future. Forcing exit from safemode will cause 10368971 byte(s) to be deleted. If you are sure that the NameNode was started with the correct metadata files then you may proceed with '-safemode forceExit' Configured Capacity: 20014161920 (18.64 GB) Present Capacity: 6477033472 (6.03 GB) DFS Remaining: 6474620928 (6.03 GB) DFS Used: 2412544 (2.30 MB) DFS Used%: 0.04% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (2): Name: 192.168.56.101:9866 (node1) Hostname: node1 Decommission Status : Normal Configured Capacity: 10007080960 (9.32 GB) DFS Used: 811008 (792 KB) Non DFS Used: 6239903744 (5.81 GB) DFS Remaining: 3237834752 (3.02 GB) DFS Used%: 0.01% DFS Remaining%: 32.36% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Oct 24 20:15:20 AEDT 2019 Last Block Report: Thu Oct 24 20:11:35 AEDT 2019 Num of Blocks: 0 Name: 192.168.56.103:9866 (node3) Hostname: node3 Decommission Status : Normal Configured Capacity: 10007080960 (9.32 GB) DFS Used: 1601536 (1.53 MB) Non DFS Used: 6240161792 (5.81 GB) DFS Remaining: 3236786176 (3.01 GB) DFS Used%: 0.02% DFS Remaining%: 32.34% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Oct 24 20:15:21 AEDT 2019 Last Block Report: Thu Oct 24 20:12:33 AEDT 2019 Num of Blocks: 3
退出 “安全模式”。
That command must be run as the HDFS superuser (usually "hdfs"). So, try it this way:
sudo -u hdfs hdfs dfsadmin -safemode leave
三、显示HDFS块信息
hadoop@node-master:/usr/local/hadoop/data/nameNode$ hdfs fsck / -files -blocks Connecting to namenode via http://node-master:9870/fsck?ugi=hadoop&files=1&blocks=1&path=%2F FSCK started by hadoop (auth:SIMPLE) from /192.168.56.2 for path / at Thu Oct 24 20:16:39 AEDT 2019 / <dir> /user <dir> /user/hadoop <dir> /user/hadoop/books <dir> /user/hadoop/books/alice.txt 173595 bytes, replicated: replication=1, 1 block(s): OK 0. BP-1068893594-192.168.56.2-1571893848809:blk_1073741825_1001 len=173595 Live_repl=1 /user/hadoop/books/frankenstein.txt 450783 bytes, replicated: replication=1, 1 block(s): OK 0. BP-1068893594-192.168.56.2-1571893848809:blk_1073741827_1003 len=450783 Live_repl=1 /user/hadoop/books/holmes.txt 607788 bytes, replicated: replication=1, 1 block(s): OK 0. BP-1068893594-192.168.56.2-1571893848809:blk_1073741826_1002 len=607788 Live_repl=1 Status: HEALTHY Number of data-nodes: 2 Number of racks: 1 Total dirs: 4 Total symlinks: 0 Replicated Blocks: Total size: 1232166 B Total files: 3 Total blocks (validated): 3 (avg. block size 410722 B) Minimally replicated blocks: 3 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 1.0 Missing blocks: 0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Erasure Coded Block Groups: Total size: 0 B Total files: 0 Total block groups (validated): 0 Minimally erasure-coded block groups: 0 Over-erasure-coded block groups: 0 Under-erasure-coded block groups: 0 Unsatisfactory placement block groups: 0 Average block group size: 0.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 FSCK ended at Thu Oct 24 20:16:39 AEDT 2019 in 12 milliseconds The filesystem under path '/' is HEALTHY
四、格式化名称节点
(慎用,一般只在初次搭建集群,使用一次)
hadoop namenode -format
五、恢复 Block
block损坏了怎么办?
[root@node01 hadoop]# hadoop jar /opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/jars/hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /test/words /test/output33 19/11/27 18:56:41 INFO client.RMProxy: Connecting to ResourceManager at node03.kaikeba.com/192.168.56.120:8032 19/11/27 18:56:41 WARN security.UserGroupInformation: PriviledgedActionException as:root (auth:SIMPLE) cause:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /user/root/.staging. Name node is in safe mode. The reported blocks 33 needs additional 2 blocks to reach the threshold 0.9990 of total blocks 35. The number of live datanodes 3 has reached the minimum number 1. Safe mode will be turned off automatically once the thresholds have been reached. at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1527) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4471) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4446) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:882) at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.mkdirs(AuthorizationProviderProxyClientProtocol.java:326) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:640) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2281) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2277) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2275) org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /user/root/.staging. Name node is in safe mode. The reported blocks 33 needs additional 2 blocks to reach the threshold 0.9990 of total blocks 35. The number of live datanodes 3 has reached the minimum number 1. Safe mode will be turned off automatically once the thresholds have been reached. at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1527) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4471) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4446) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:882) at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.mkdirs(AuthorizationProviderProxyClientProtocol.java:326) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:640) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2281) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2277) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2275) at org.apache.hadoop.ipc.Client.call(Client.java:1504) at org.apache.hadoop.ipc.Client.call(Client.java:1441) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230) at com.sun.proxy.$Proxy10.mkdirs(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:573) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:258) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:104) at com.sun.proxy.$Proxy11.mkdirs(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3154) at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:3121) at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1004) at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1000) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:1000) at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:992) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:133) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:148) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1325) at org.apache.hadoop.examples.WordCount.main(WordCount.java:87) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:221) at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
作为hdfs的root,也就是hdfs用户删掉坏掉的blocks.
sudo -u hdfs hadoop fs -rm -r /test/output3
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号