[Spark] 02 - Practice PySpark
RDD编程基础
PySpark 启动
一、PySpark 资源导航
Ref: Spark与Python结合:PySpark初学者指南
Ref: Spark 编程指南简体中文版
二、SparkContext
SparkContext 的作用
用Python来连接Spark:可以使用RD4s并通过库Py4j来实现。
PySpark Shell将Python API链接到Spark Core并初始化Spark Context。(SparkContext是Spark应用程序的核心)
1.Spark Context设置内部服务并建立到Spark执行环境的连接。
2.驱动程序中的Spark Context对象协调所有分布式进程并允许进行资源分配。
3.集群管理器执行程序,它们是具有逻辑的JVM进程。
4.Spark Context对象将应用程序发送给执行者。
5.Spark Context在每个执行器中执行任务。
SparkContext 初始化
统计带有字符“a”或“b”的行数。
from pyspark import SparkContext sc = SparkContext("local", "first app") logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md" logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count() numBs = logData.filter(lambda s: 'b' in s).count() print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
三、SparkConf
SparkConf包含了Spark集群配置的各种参数。
from pyspark import SparkConf, SparkContext conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077") sc = SparkContext(conf=conf)
以下是SparkConf最常用的一些属性
-
-
set(key,value) - 设置配置属性。
-
setMaster(value) - 设置主URL。
-
setAppName(value) - 设置应用程序名称。
-
get(key,defaultValue = None) - 获取密钥的配置值。
-
setSparkHome(value) - 在工作节点上设置Spark安装路径。
-
RDD创建
一、加载文件
.textFile()方法从三个方式读取内容:HDFS, LOCAL, S3
Local
读取本地文件,生成一个RDD (就是lines)。
# RDD lines变量
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") # 三个斜杠
lines.foreach(print)
lines.first()
lines.saveAsTextFile("...") # 把RDD写入到文本文件中
HDFS
以下三个等价。为了区别本地读取,读方式采用了三斜杠。
lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") lines = sc.textFile("/user/hadoop/word.txt") lines = sc.textFile("word.txt")
lines.saveAsTextFile("writeback") # 把RDD写入到HDFS文件中
addFile函数
原文链接:https://blog.csdn.net/guohecang/article/details/52095387
在Apache Spark中,您可以使用 sc.addFile 上传文件(sc是您的默认SparkContext),并使用 SparkFiles.get 获取工作者的路径。
我们在使用Spark的时候有时候需要将一些数据分发到计算节点中。
(1)一种方法是将这些文件上传到HDFS上,然后计算节点从HDFS上获取这些数据。
(2)我们也可以使用addFile函数来分发这些文件。
注意,如果是spark程序通过yarn集群上加载配置文件,path必须是集群hdfs的绝对路径,如:viewfs://58-cluster//home/hdp_lbg_supin/resultdata/zhaopin/recommend/config/redis.properties。
from pyspark import SparkContext from pyspark import SparkFiles finddistance = "/home/hadoop/examples_pyspark/finddistance.R" finddistancename = "finddistance.R" sc = SparkContext("local", "SparkFile App") sc.addFile(finddistance) print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
二、通过并行集合列表创建RDD
每个元素i相当与一行。
array = [1,2,3,4,5] rdd = sc.parallelize(array) rdd.foreach(print)
序列化
序列化用于Apache Spark的性能调优。
通过 "网络发送" 或 "写入磁盘" 或 "持久存储在内存中" 的所有数据都应序列化。
PySpark支持用于性能调优的自定义序列化程序。
from pyspark.context import SparkContext from pyspark.serializers import MarshalSerializer sc = SparkContext("local", "serialization app", serializer = MarshalSerializer()) print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10)) sc.stop()
RDD操作
[Transformation操作]
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD转化操作

对数据分别为{1, 2, 3}和{3, 4, 5}的RDD进行针对两个RDD的转化操作

[Action操作]
对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD行动操作

一、"转换" 操作

filter(func)
lines = sc.textFile("file:///<path>") linesWithSpark = lines.filter(lambda line: "Spark" in lines) linesWithSpark.foreach(print)
map(func)
data = [1,2,3,4,5] rdd1 = sc.parallelize(data) rdd2 = rdd1.map(lambda x: x+10) rdd2.foreach(print)
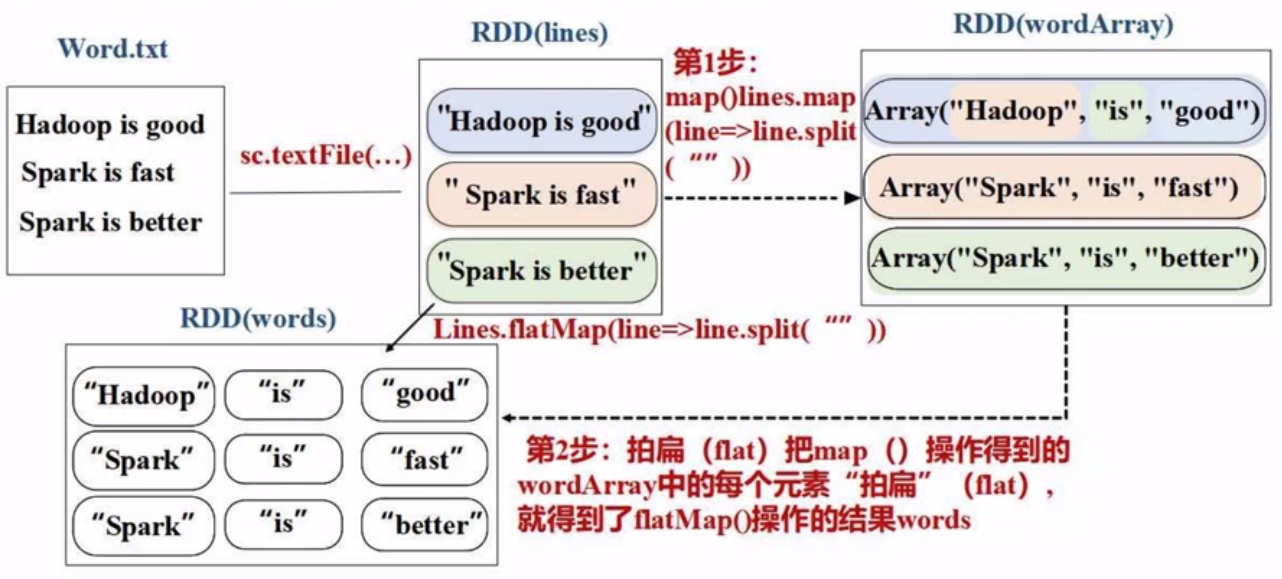
flatMap
所谓flat,就是最后要的是 “单词的集合”。
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") words = lines.flatMap(lambda line:line.split(" "))
流程本质上就是:[[...], [...], [...]] --> flat降维 --> [...]
groupByKey
根据key把value归并起来。
words = sc.parallelize([("Hadoop",1), ("is",1), ...) words1 = words.groupByKey() words1.foreach(print)

下图左边的输入,可以通过map(lambda word: (word,1))来获得。

reduceByKey
进一步地,直接将groupByKey的values经过reduce处理后可变为一个值。

二、"行动" 操作
惰性机制。
rdd = sc.parallelize([1,2,3,4,5]) rdd.count() rdd.take(3) # 以数组的形式返回数据集中的前n个元素 rdd.reduce(lambda a,b:a+b) rdd.collect() # 以数组的形式返回数据集中的所有元素 rdd.foreach(lambda elem:print(elem))
三、RDD常见操作
(1) RDD代表 Resilient Distributed Dataset,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。
from pyspark import SparkContext sc = SparkContext("local", "count app") words = sc.parallelize ( ["scala", "java", "hadoop", "spark", "akka", "spark vs hadoop", "pyspark", "pyspark and spark"] )
方法测试:
>>> words_filter = words.filter(lambda x: 'spark' in x) >>> filtered = words_filter.collect() >>> print("Fitered RDD -> %s" % (filtered)) Fitered RDD -> ['spark', 'spark vs hadoop', 'pyspark', 'pyspark and spark'] >>> words_map = words.map(lambda x: (x, 1)) >>> mapping = words_map.collect() >>> print("Key value pair -> %s" % (mapping)) Key value pair -> [('scala', 1), ('java', 1), ('hadoop', 1), ('spark', 1), ('akka', 1), ('spark vs hadoop', 1), ('pyspark', 1), ('pyspark and spark', 1)] >>> words.cache() ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
>>> caching = words.persist().is_cached >>> print("Words got chached > %s" % (caching)) Words got chached > True
(2) 这个也是非常类似与python中的api。
from pyspark import SparkContext from operator import add
sc = SparkContext("local", "Reduce app") nums = sc.parallelize([1, 2, 3, 4, 5])
方法测试:
>>> adding = nums.reduce(add) >>> print("Adding all the elements -> %i" % (adding)) Adding all the elements -> 15
(3) 类似sql中的join。
from pyspark import SparkContext sc = SparkContext("local", "Join app")
方法测试:
>>> x = sc.parallelize([("spark", 1), ("hadoop", 4)]) >>> y = sc.parallelize([("spark", 2), ("hadoop", 5)]) >>> joined = x.join(y) >>> joined PythonRDD[16] at RDD at PythonRDD.scala:53 # 说明joined是个惰性的rdd。
>>> final = joined.collect() >>> print("Join RDD -> %s" % (final)) Join RDD -> [('hadoop', (4, 5)), ('spark', (1, 2))]
四、“持久化” 的必要性
没用持久化
list = ["Hadoop”, “Spark", "Hive"] rdd = sc.parallelize(list)
print(rdd.count()) # 动作操作,触发一次从头到尾的计算 print(','.join(rdd.collect())) # 以逗号作为分隔把这三个字符串连接起来,python使用; # 动作操作,触发一次从头到尾的计算
使用持久化
.persist(MEMORY_AND_DISK)
.persist(MEMORY_ONLY) ---> .cache() # 简洁写法
list = ["Hadoop”, “Spark", "Hive"] rdd = sc.parallelize(list)
# 第一次行动计算时,才真正的缓存持久化 rdd.cache()
print(rdd.count()) print(','.join(rdd.collect())) # 这里便不需要在从头到尾计算,因为rdd已缓存
rdd.unpersist()
原始的方式,如下所示:
StorageLevel决定如何存储RDD。在Apache Spark中,StorageLevel决定RDD是应该存储在内存中还是存储在磁盘上,或两者都存储。它还决定是否序列化RDD以及是否复制RDD分区。
让我们考虑以下StorageLevel示例,其中我们使用存储级别 MEMORY_AND_DISK_2, 这意味着RDD分区将具有2的复制。
from pyspark import SparkContext import pyspark sc = SparkContext ( "local", "storagelevel app" ) rdd1 = sc.parallelize([1,2]) rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 ) rdd1.getStorageLevel() print(rdd1.getStorageLevel())
RDD分区
Ref: Spark-RDD 分区
一、分区好处
增加并行性
多节点同时计算。

减少通信开销
(UserId, UserInfo) join (UserID, LinkInfo) ---> (UserID, UserInfo, LinkInfo)
一个文件非常大,分块存储在不同的机器上,谓之 “分块”。
左图:每一个块,有所有rows的一部分信息;
右图:没一个块,只有一部分rows的信息。
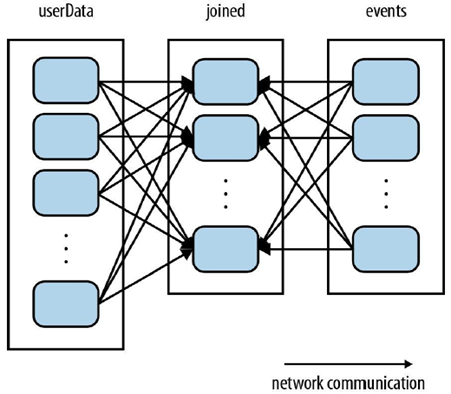

左图三步骤:
(1) join操作会将两个数据集中的所有的键的哈希值都求出来,
(2) 将哈希值相同的记录传送到同一台机器上,
(3) 之后在该机器上对所有键相同的记录进行join操作。
这种情况之下,每次进行join都会有数据混洗的问题,造成了很大的网络传输开销。
右图三过程:
(1) 由于UserData表比events表要大得多,所以选择将UserData进行分区。
(2) 之后Spark就会知晓该RDD是根据键的哈希值来分区的。
(3) 这样在调用join()时,Spark就会利用这一点。当调用UserData.join(events)时,Spark只会对events进行数据混洗操作,将events中特定的UserID的记录发送到userData的对应分区所在的那台机器上。
二、分区原则
手动分区
尽量等于集群中的逻辑cpu core的数量。
弹性RDD的演示:
list = [1,2,3,4,5] data = sc.parallelize(list, 2) len(data.glom().collect())
2 rdd = data.repartition(1) len(rdd.glom().collect())
1
自定义分区
三种分区方式:
- HashPartitioner(默认)
- RangePartitioner(默认)
- 自定义分区
分配分区的index。
from pyspark import SparkConf, SparkContext def MyPartitioner(key): print("MyPartitioner is running") print('The key is %d' % key) return key % 10
自定义分区。
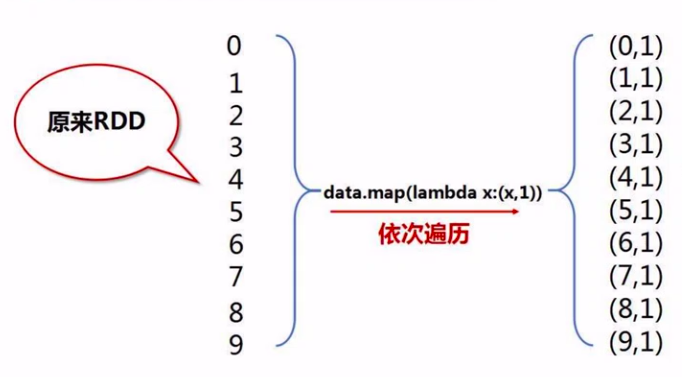
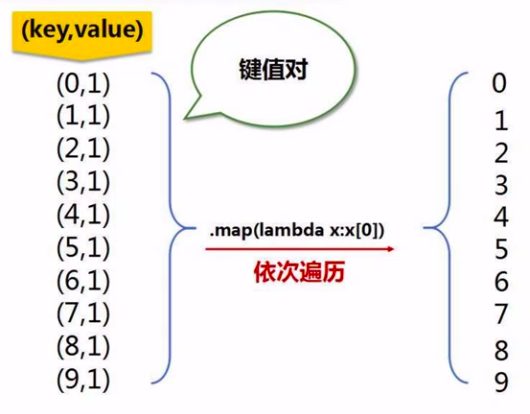
def main(): print("The main function is running") conf = SparkConf().setMaster("local").setAppName("MyApp") sc = SparkContext(conf = conf) # 把这些数字分成5个分区 data = sc.parallelize(range(10), 5) data.map(lambda x: (x,1)) \ .partitionBy(10, MyPartitioner) \ .map(lambda x: x[0]) \ .saveAsTextFile("file:///usr/local/spark/mycode/rdd/partitioner") # 目录地址,10个分区是10个文件 if __name__ == '__main__': main()
map(lambda x: (x, 1))
map(lambda x: x[0])
三、调试方式
因为分了10个区,所以最后生成了10个文件。
# python sol
python3 TestPartitioner.py
# spark sol
spark-submit TestPartitioner.py
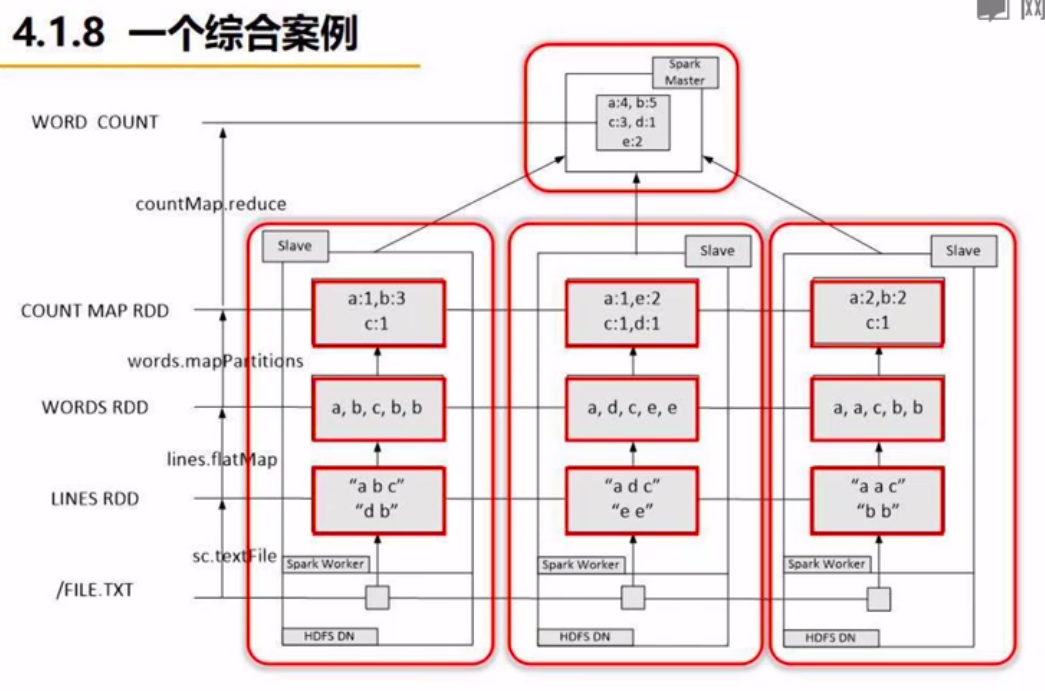
栗子:word count
一、进行词频统计
其实就是上文中RDD操作的一个综合应用。
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
wordCount = lines.flatMap(lambda line: line.split(" "))
.map(lambda word: (word,1))
.reduceByKey(lambda a,b:a+b)
print(wordCount.collect())
二、过程解析
将统计内容分配到各个节点,计算出分区的统计结果,之后再reduce到master统计出最终结果。
键值对RDD
一、如何创建
从文件中加载
flatMap, map即可得。

通过并行集合创建
直接flat即可。

二、如何转换
常见的转换方法如下。
reduceByKey(lambda a,b: a+b)
# 等价于:
groupByKey().map(lambda t: (t[0], sum(t[1]))) # (one,1) (two,(1,1)) (three,(1,1,1))
pairRDD.keys().foreach() pairRDD.values().foreach()
pairRDD.sortByKey().foreach() # 降序排序sortByKey(False) d1.reduceByKey(lambda a,b: a+b).sortBy(lambda x: x,False) # 默认是key排序 d1.reduceByKey(lambda a,b: a+b).sortBy(lambda x: x[0],False) # key排序 d1.reduceByKey(lambda a,b: a+b).sortBy(lambda x: x[1],False) # value排序
pairRDD.mapValues(lambda x: x+1) # 只针对dict的value操作 pairRdd1.join(pairRDD2) # 根据key,把value归并起来,类似于:flatMap+map
栗子:average sales
一、计算每天平均销量

二、代码
x[0]代表值的总和。
x[1]代表值的个数。
rdd = sc.parallelize([("spark",2), ("hadoop", 6), ("hadoop", 4), ("spark", 6)]) rdd.mapValues(lambda x: (x,1)). \
... reduceByKey(lambda x,y: (x[0]+y[0], x[1]+[1]). \
... mapValues(lambda x: x[0]/x[1]).collect()
广播与累积器
一、共享变量
默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想要共享某个变量,那么这种方式是做不到的。
因此,Spark提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。
- Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,而不会为每个task都拷贝一份副本。更大的用处是优化性能,减少网络传输以及内存消耗。
- Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。
二、实例演示
Broadcast
广播变量用于跨所有节点保存数据副本。此变量缓存在所有计算机上,而不是在具有任务的计算机上发送。
class pyspark.Broadcast ( sc = None, value = None, pickle_registry = None, path = None )
示例代码:
from pyspark import SparkContext sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value print "Stored data -> %s" % (data) elem = words_new.value[2] print "Printing a particular element in RDD -> %s" % (elem)
Accumulator
累加器变量用于通过关联和交换操作聚合信息。例如,您可以使用累加器进行求和操作或计数器(在MapReduce中)。
from pyspark import SparkContext sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x): global num num+=x
rdd = sc.parallelize([20,30,40,50]) rdd.foreach(f) final = num.value print "Accumulated value is -> %i" % (final)
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号