
常用中间件(消息队列MessageQueue,高级消息队列Rabbitmq)
MesssageQueue(MQ)消息队列是一种应用程序对应用程序的通信方法。是消费者生产者模型的一个典型代表。
- 消息队列的实际意义
- 异步消息解耦,例如在外卖订单处理系统中,订单系统通过消息队列和配送系统、商家系统、后台系统等进行消息通信,实现了消费者和生产者之间对数据信息操作的解耦
- 流量削峰作用,在请求系统的外层,使用消息队列作为一个请求的缓冲池
- 常见的消息队列
- ActiveMQ
- RabbitMQ,应用场景广泛
- ZeroMQ
- Kafka
- MetaMQ
- RocketMQ
rabitmq,中文文档http://rabbitmq.mr-ping.com/,其他参考:https://blog.csdn.net/weixin_39735923/article/details/79288578
- rabbitMQ是用Erlang开发的基于AMQP协议的消息中间件,或消息队列
- 使用rabbitmy之前,先要启动rabbitmq的服务。
- 安装
- mac,Linux系统
- 安装brew
- 方式一,按brew官方推荐方式,https://brew.sh/,资源不稳定
- 方式二,使用镜像自动安装,源不稳定,不一定能成功,在终端执行
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" - 方式三,按镜像官网步骤,安装清华镜像https://mirrors.tuna.tsinghua.edu.cn/help/homebrew/
- 使用brew install rabbitmq
- 配置环境变量
- vim ~/.bash_profile
- 添加上 export PATH=$PATH:/usr/local/sbin
- 立即启用环境变量,source ~/.bash_profile
- 配置环境变量
- 安装brew
- windows系统
- 先安装erlang,
- 下载rabbitmq
- erlang下载地址:http://www.erlang.org/downloads
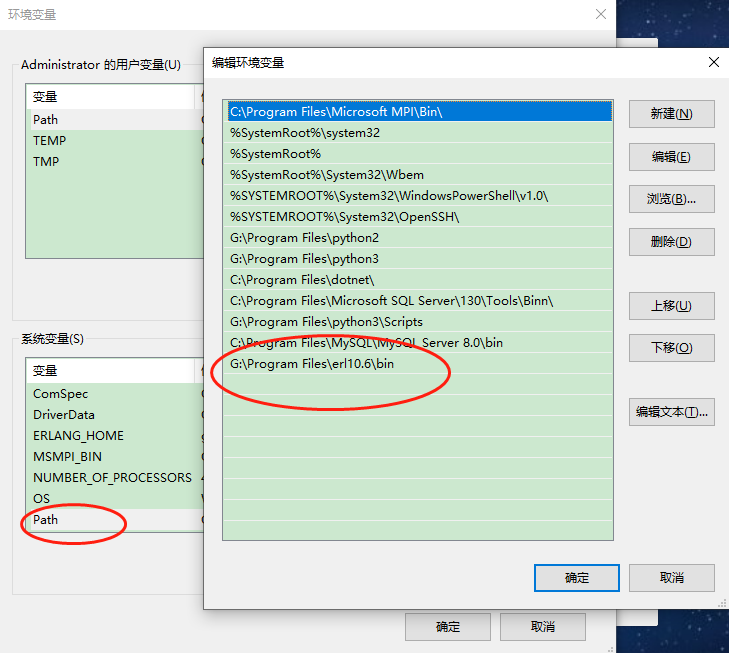
- 在安装完erlang程序后,注意配置环境变量
- 配置完成,在cmd终端中,输入erl执行看效果
- 在安装完erlang程序后,注意配置环境变量
-
rabbitmq下载地址:http://www.rabbitmq.com/download.html
- 下载双击安装rabbitmq
- 在cmd终端中,进入rabbitmq的安装目录中的sbin文件夹
- 执行,rabbitmq-plugins enable rabbitmq_management
- 添加环境变量,rabbitmq下面的sbin目录到path路径中
- 在sbin文件夹中执行rabbitmq-server开启服务
- rabbitmqctl stop停止服务
- mac,Linux系统
- 启动命令:
rabbitmq-server -detached(后台运行) - 启用web管理插件 rabbitmq-plugins enable rabbitmq_management
- 浏览器中,访问rabbitmq,默认地址,http://localhost:15672
- 默认登录用户名和密码均为guest
消息的生产端控制流程:
1、实例化链接,2、声明管道,3、声明队列queue,4、发布消息,5、关闭链接
消息的消费端控制流程:
1、实例化链接,2、声明管道,3、声明队列(在确认已经由生产端声明好的前提下可以省略,为防止消费端先于生产端启动,进而因无队列报错。),4、定义回调的功能函数,5、接收消息的设置(),6、开始通过管道接收消息。
主要的消息处理模式及关键参数:
- 简单模式,常用于追求效率的情况下
- 应答参数,常用于追求数据安全情况下
- 消息持久化处理
- 交换机模式
- 发布订阅
- 关键字模式
- 通配符模式
一个简单模式消息交互的例子
- 生产者消费者模型
-
![]() 简单模式生产者
简单模式生产者import pika # 链接rabbitmq conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() # 创建队列 channel.queue_declare(queue='hello') # 向指定队列插入数据,exchage为空表示简单模式,routing_key指定队列,body设置内容 channel.basic_publish(exchage='',routing_key='hello',body='msg,hello world') #状态提示 print('sent msg')
![]() 简单模式消费者
简单模式消费者import pika # 链接rabbitmq conn = pika.BlockingConnection(pika.connectionParameters('localhost')) channel = connection.channel() # 创建队列,如果消费者执行时,生产者队列还未生成,则创建队列,如果生产者已经创建了对应的队列,不执行 channel.queue_declare(queue='hello') # 回调函数 def my_callback(ch,method,properties,body): print('received msg') # 设置监听参数 channel.basic_consume(queue='hello',auto_ack=True,on_message_callback=my_callback) print('开始监听…………') channel.start_consuming()
-


一个应答模式消息交互的例子
- 在简单模式下,消费者拿到生产者在rabbitmq中存储的数据,处理过程中,如果出现异常,则数据丢失。生产者服务器崩
- 为了防止这种情况,需要将应答参数auto_ack有True改为手动应答False。同时,在处理的回调函数中,必须添加一个删除数据命令, ch.basic_ack(delivery_tag=method.delivery_tag)
- 应答模式的生产者和简单模式一致,主要是消费者端进行逻辑调整
-
![]() 应答模式消费者
应答模式消费者# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() my_channel.queue_declare(queue='hello') def my_callback(ch, method, properties, body): print('received msg %s' % body) info = input('>>>>是否销毁数据Y/N:') if info.upper() == 'Y': ch.basic_ack(delivery_tag=method.delivery_tag) # 手动应答,根据执行结果,判断是否删除内容 my_channel.basic_consume(queue='hello', auto_ack=False, # 关闭自动应答 on_message_callback=my_callback) my_channel.start_consuming()
队列服务的持久化:
- 简单模式情况下,当rabbitmq服务器端停掉服务后,重启rabbitmq后数据丢失。
- 为了实现,重启rabbitmq后队列仍然存在
- 在声明队列的时候,用持久化参数 durable=True。同一队列的声明(包括生产者,消费者)都加上。可持久化的队列,即支持持久化的信息,同时支持普通信息
- 在发布消息的时候,由生产者控制,通过 properties = pika.BasicProperties( delivery_mode = 2,)) 的设置,实现消息的持久化
- 消息持久化示例
-
![]() 持久化处理+应答生产者
持久化处理+应答生产者# !/usr/bin/env python # -*- coding:utf-8 -*- import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() channel.queue_declare(queue='hello2',durable=True) # 声明队列为可持久化的 channel.basic_publish(exchange='', routing_key='hello2', body='msg:normal', ) # 非持久化数据信息 channel.basic_publish(exchange='', routing_key='hello2', body='msg_hello_world', properties = pika.BasicProperties( delivery_mode = 2,)) #持久化的数据信息 print('sent hello msg')
![]() 持久化+应答消费者
持久化+应答消费者# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() my_channel.queue_declare(queue='hello2',durable=True) # 声明队列为可持久化的 def my_callback(ch, method, properties, body): print('received msg %s' % body) info = input('>>>>是否销毁数据Y/N:') if info.upper() == 'Y': ch.basic_ack(delivery_tag=method.delivery_tag) # 手动应答,根据执行结果,判断是否删除内容 my_channel.basic_consume(queue='hello2', auto_ack=False, # 关闭自动应答 on_message_callback=my_callback) my_channel.start_consuming()
-
实现消息的高效分发:
- 默认的消息分发机制,是轮训分发。即,监听同一个队列的不同消费者客户端,接收消息是以简单轮训的顺序依次获取消息的。生产者向队列发布的第一条,给监听队列的第一个客户端,第二条,给第二个……这种效率是比较低的。
- 为了高效的实现消息的分发,就要实现,消息处理未完成的客户端,不接受消息
- 在生产者客户端,通过监测是否还有没处理完的消息, channel.basic_qos(prefetch_count = 1)
- 示例
-
![]() 生产者
生产者# !/usr/bin/env python # -*- coding:utf-8 -*- import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() # 声明队列为可持久化的 channel.queue_declare(queue='hello3') i=1 while i<50: channel.basic_publish(exchange='', routing_key='hello3', body='msg:normal', ) # 非持久化数据信息 print('sent hello msg') i+=1 print('done')
![]() 消费者,为了启动多个,pycharm需要在configurations中修改消费者的Allow parallelrun
消费者,为了启动多个,pycharm需要在configurations中修改消费者的Allow parallelrun# !/usr/bin/env python # -*- coding:utf-8 -* import pika import time,random conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 创建队列 my_channel.queue_declare(queue='hello3') # 定义处理信息的回调函 timer = random.randrange(1,50) def my_callback(ch, method, properties, body): print('处理时间%s'%timer) time.sleep(timer) print('received msg %s' % body) # 如果当前客户端未处理完就不接受新消息的分发 my_channel.basic_qos(prefetch_count=1) # 设置监听队列 my_channel.basic_consume(queue='hello3', auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
-
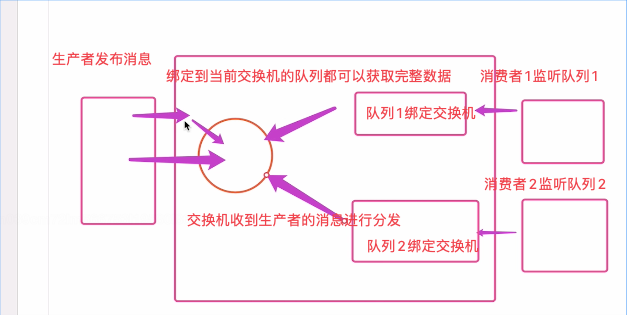
广播和消息订阅:
- exchange类似于一个消息的转发器,不同的exchange类型,提供了不同的不同的消息发布方式。
- 纯广播模式,所有的订阅者都能接收到
- 纯广播模式fanout具体实现:
- 生产者,
- 首先创建了链接和管道,
- 不生声明队列而是声明exchange,定义消息转发器的名称、类型。exchage_type=‘fanout’
- 交换机的类型exchage_type常见的方式:
- fanout,纯广播方式。消息的生产者不用声明队列,在接收消息的时候消费者用声明随机队列,用完以后消息队列丢掉。
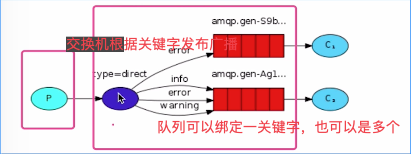
- direct,定向接收。用于关键字模式
- topic,通配符模式
- 交换机的类型exchage_type常见的方式:
- 然后消息发布的时候,根据交换机的名称,定义不同的消息发布方式。
- 发布消息通过exchange的名称,指定交换机目标
- 消费者
- 创建链接和管道
- 声明exchange
- 声明需要监听的队列,这里队列的名称,可以设置为随机生成,使用queue_name = queue_ret.method.queue获取随机生成的队列名
- 根据queue_name,绑定队列到交换机上
- 定义处理信息的回调函数
- 设置监听队列参数
- 开始监听
- 示例
-
![]() 发布订阅fanout模式生产者
发布订阅fanout模式生产者# !/usr/bin/env python # -*- coding:utf-8 -*- import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 channel.exchange_declare(exchange='ex1', exchange_type='fanout') # 发送消息,通过exchange定义发送消息的交换机目标 channel.basic_publish(exchange='ex1', routing_key='hello2', body='msg:exchage_fanout', ) print('sent hello msg')
![]() 发布订阅fanout模式消费者
发布订阅fanout模式消费者# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex1', exchange_type='fanout') # 创建队列 queue_ret = my_channel.queue_declare('',exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上 my_channel.queue_bind(exchange='ex1',queue=queue_name) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
-
- 生产者,
- 关键字模式direct:
-
关键字模式的具体实现
- 生产者
- 指定交换机类型为exchange_type为direct
- 在设置发布信息的时候,使用routing_key指定当前信息的关键字。必须是消费者能接受的关键字,才能被收到
- 消费者
- 指定交换机类型exchange_type为direct
- 向交换机绑定队列的时候,通过关键字参数,routing_key='自定义的消息关键字' 进行绑定,每次只能给管道绑定一个队列,如果需要绑定多个关键字的队列,需要逐一添加绑定,或者进行循环遍历。
- 示例
-
![]() 关键字模式生产者
关键字模式生产者# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex2', exchange_type='direct') # 创建队列 queue_ret = my_channel.queue_declare('', exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上 key_list = ['warning', 'info', 'error'] for msg_key in key_list: my_channel.queue_bind(exchange='ex2' , queue=queue_name, routing_key=msg_key) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
![]() 关键字模式消费者1,只接受error关键字的内容
关键字模式消费者1,只接受error关键字的内容# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex2', exchange_type='direct') # 创建队列 queue_ret = my_channel.queue_declare('', exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上,routing_key设置可以接收的消息的关键字 my_channel.queue_bind(exchange='ex2', queue=queue_name, routing_key='error' ) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
![]() 关键字模式消费者2,接受error,info,warning关键字的内容
关键字模式消费者2,接受error,info,warning关键字的内容# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex2', exchange_type='direct') # 创建队列 queue_ret = my_channel.queue_declare('', exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上 key_list = ['warning', 'info', 'error'] for msg_key in key_list: my_channel.queue_bind(exchange='ex2' , queue=queue_name, routing_key=msg_key) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
-
- 生产者
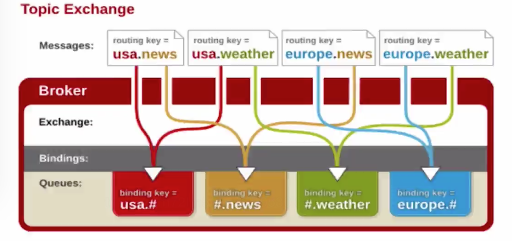
- 通配符模式topic:
- 上面的关键字模式只能进行消息关键字的完全匹配,要实现模糊匹配就需要使用通配符模式
- 通配符模式上,只有两个占位符( #,* ),其中,#匹配一个或多个此,*只匹配一个词,这里和正则表达式区别
-
![]()
- 通配符模式的具体实现
- 生产者
- exchange_type,定义为topic
- 消费者
- exchange_type同样指定为topic
- 定义routing_key的时使用通配符 *,#,实现模糊匹配
- 示例
-
![]() 生产者
生产者# !/usr/bin/env python # -*- coding:utf-8 -*- import random import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 channel.exchange_declare(exchange='ex3', exchange_type='topic') key_list = ['warning.0','warning.2', 'info', 'error'] # 发送消息,通过exchange定义发送消息的交换机目标,routing_key设置当前消息的关键字信息 i = 1 while i < 50: msg_type = random.choice(key_list) print('关键字%s'%msg_type) channel.basic_publish(exchange='ex3', routing_key=msg_type, body='msg:exchage_%s' % msg_type, ) i += 1 print('sent hello msg')
![]() 消费者1,使用*通配符定义规则
消费者1,使用*通配符定义规则# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex3', exchange_type='topic') # 创建队列 queue_ret = my_channel.queue_declare('', exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上,routing_key设置可以接收的消息的关键字,使用占位符定义匹配模式 my_channel.queue_bind(exchange='ex3', queue=queue_name, routing_key='warning.*' ) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
![]() 消费者2,使用#通配符进行匹配规则指定
消费者2,使用#通配符进行匹配规则指定# !/usr/bin/env python # -*- coding:utf-8 -* import pika conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) my_channel = conn.channel() # 声明交换机,exchange定义交换机名称,exchange_type定义交换机类型 my_channel.exchange_declare(exchange='ex3', exchange_type='topic') # 创建队列 queue_ret = my_channel.queue_declare('', exclusive=True) # 第一个参数 ‘’,表示不指定队列名称,第二个参数执行自动生成随机的队列名称 queue_name = queue_ret.method.queue # 获取上面随机生成的队列名称 # 将队列绑定到交换机上 key_list = ['info', 'error'] my_channel.queue_bind(exchange='ex3' , queue=queue_name, routing_key='warning.#') for msg_key in key_list: my_channel.queue_bind(exchange='ex3' , queue=queue_name, routing_key=msg_key) # 定义处理信息的回调函数 def my_callback(ch, method, properties, body): print('received msg %s' % body) # 设置监听队列 my_channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=my_callback) my_channel.start_consuming()
-
- 生产者
rpc(remote proceduer call)消息队列服务的实现
rabbitmq常用方法
常用的方法介绍
