


扫盲记-第二篇-基于深度学习的图像超分辨率
超分辨率(Super-Resolution, SR)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。
端到端的基于深度学习的单张图像超分辨率方法(Single Image Super-Resolution, SISR),2014年SRCNN是深度学习用在超分辨率重建上的开山之作,SRCNN的网络结构非常简单,仅仅用了三个卷积层,网络结构如下图所示:
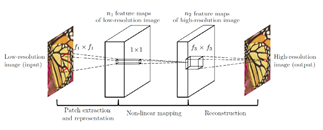
SRCNN首先使用双三次(bicubic)插值将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,最后输出高分辨率图像结果。SRCNN将三层卷积的结构解释成三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。三个卷积层使用的卷积核的大小分为为9x9,1x1和5x5,前两个的输出特征个数分别为64和32。使用均方误差(Mean Squared Error, MSE)作为损失函数,有利于获得较高的PSNR。
2016年FSRCNN是对SRCNN的改进,主要在三个方面:一是在最后使用了一个反卷积层放大尺寸,因此可以直接将原始的低分辨率图像输入到网络中,而不是像SRCNN那样需要先通过bicubic方法放大尺寸;二是改变特征维数,使用更小的卷积核和使用更多的映射层;三是可以共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要微调整fine-tuning最后的反卷积层。
由于FSRCNN不需要在网络外部进行放大图片尺寸的操作,同时通过添加收缩层和扩张层,将一个大层用一些小层来代替,因此FSRCNN与SRCNN相比有较大的速度提升。FSRCNN在训练时也可以只fine-tuning最后的反卷积层,因此训练速度更快。FSRCNN与SCRNN的结构对比如下图所示:
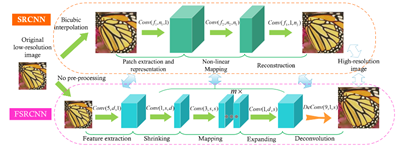
FSRCNN可以分为五个部分:
特征提取:SRCNN中针对的是插值后的低分辨率图像,选取的卷积核大小为9×9,FSRCNN直接对原始的低分辨率图像进行操作,因此卷积核大小可以选小一点,设置为5×5;
收缩:通过应用1×1的卷积核进行降维,减少网络的参数,降低计算复杂度;
非线性映射:感受野大,能够表现的更好。在SRCNN中,采用的是5×5的卷积核,但是由于5×5的卷积核计算量会比较大。因此,FSRCNN改用两个串联的3×3的卷积核替代一个5×5的卷积核,同时两个串联的小卷积核需要的参数3×3×2=18比一个大卷积核5×5=25的参数量要小。FSRCNN网络中通过m个核大小为3×3的卷积层进行串联。
扩张:低维度的特征带来的重建效果不是太好,因此,应用1×1的卷积核进行扩维,相当于收缩的逆过程;
反卷积层:可以简单的看作是卷积层的逆操作,如果步长为n,那么尺寸放大n倍,实现了上采样的操作。FSRCNN中激活函数采用PReLU,损失函数仍然是均方误差-MSE。
2016年ESPCN类似SRCNN方法,由于SRCNN需要将低分辨率图像通过上采样插值得到与高分辨率图像相同大小的尺寸,再输入到网络中,这意味着要在较高的分辨率上进行卷积操作,从而增加了计算复杂度。ESPCN采用了一种直接在低分辨率图像尺寸上提取特征,计算得到高分辨率图像的高效方法。ESPCN网络结构如下图所示:

ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为r2的与输入图像大小一样的特征图像。再将特征图像每个像素的r2个通道重新排列成一个r x r的区域,对应高分辨率图像中一个r x r大小的子块,从而大小为H x W x r2的特征图像被重新排列成rH x rW x 1的高分辨图像。在ESPCN网络中,图像尺寸放大过程的插值函数被隐含地包含在前面的卷积层中,可以自动学习得到。由于卷积运算都是在低分辨率图像尺寸大小上进行,因此运算效率会比较高。训练时,可以将输入的训练数据,预处理成重新排列操作前的格式,如将21×21的单通道图,预处理成9个通道的7×7图,这样在训练时,就不需要做重新排列的操作。此外,ESPCN激活函数采用tanh替代了ReLU,损失函数为均方误差。
2016年VDSR指出输入的低分辨率图像和输出的高分辨率图像在很大程度上是相似的,即低分辨率图像携带的低频信息与高分辨率图像携带的低频信息相近,训练时带上这部分低频信息会多花费大量的时间,因此,仅需要学习高分辨率图像和低分辨率图像之间的高频部分信息的残差即可。残差网络结构(residual network)特别适合用来解决超分辨率问题,VDSR是最直接明显的学习残差的结构,其网络结构如下图所示:
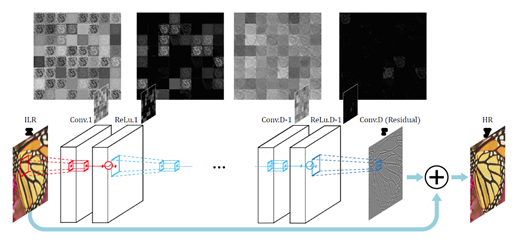
VDSR将插值后得到的变成目标尺寸的低分辨率图像作为网络的输入,再将这个图像与网络学到的残差相加得到最终的网络的输出。VDSR主要有4点贡献:
1.加深了网络结构(20层),使得越深的网络层拥有更大的感受野,VDSR选取3×3的卷积核,深度为D的网络拥有(2D+1)×(2D+1)的感受野。
2.采用残差学习,残差图像比较稀疏,大部分值都为0或者比较小,因此收敛速度快。VDSR还应用了自适应梯度裁剪(Adjustable Gradient Clipping),将梯度限制在某一范围内,也能够加快收敛过程。
3.VDSR在每次卷积前都对图像进行补0操作(padding),这样保证了所有的特征图和最终的输出图像在尺寸上都保持一致,解决了图像通过逐步卷积会越来越小的问题。VDSR实验证明补0操作对边界像素的预测结果也能够得到提升。
4.VDSR将不同倍数的图像混合在一起训练,这样训练出来的一个模型就可以解决不同倍数的超分辨率问题。
2016年RED采用了由对称的卷积层-反卷积层构成的网络结构,作为一个编码-解码框架可以学习由低质图像到原始图像端到端的映射,网络结构如下图所示:
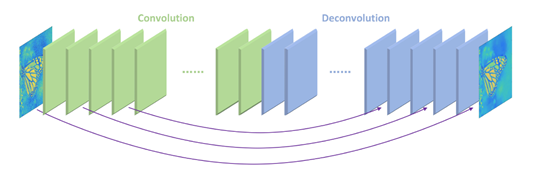
RED网络的结构是对称的,每个卷积层都有对应的反卷积层。卷积层用来获取图像的抽象内容,反卷积层用来放大特征尺寸并且恢复图像细节。卷积层将输入图像尺寸减小后,再通过反卷积层上采样变大,使得输入输出的尺寸一样。每一组镜像对应的卷积层和反卷积层有着跳线连接结构,将两部分具有同样尺寸的特征(要输入卷积层的特征和对应的反卷积层输出的特征)做相加操作(类似ResNet操作)后再输入到下一个反卷积层。这样的结构能够让反向传播信号能够直接传递到底层,解决了梯度消失问题,同时能将卷积层的细节传递给反卷积层,能够恢复出更干净的图片。网络中有一条线是将输入的图像连接到后面与最后的一层反卷积层的输出相加,也就是VDSR中用到的方式,因此RED中间的卷积层和反卷积层学习的特征是目标图像和低质图像之间的残差。RED的网络深度为30层,损失函数用的均方误差。
2017年SRDenseNet在稠密块(dense block)中将每一层的特征都输入给之后的所有层,使所有层的特征都串联(concatenate)起来,而不是像ResNet那样直接相加。这样的结构给整个网络带来了减轻梯度消失问题、加强特征传播、支持特征复用、减少参数数量的优点。一个稠密块的结构如下图所示:
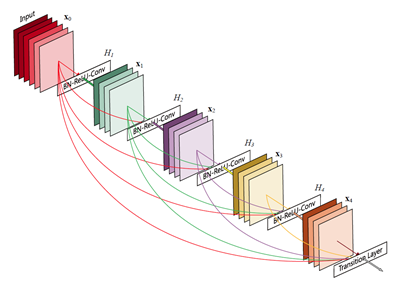
SRDenseNet将稠密块结构应用到了超分辨率问题上,取得了不错的效果,网络结构如下图所示:
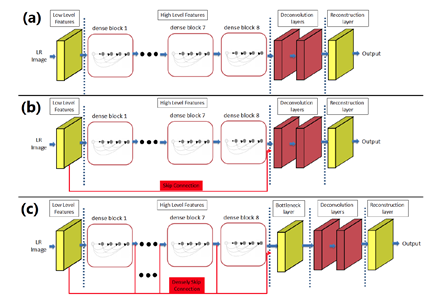
SRDenseNet可以划分成四个部分:首先,用一个卷积层学习低层的特征;接着,用多个稠密块学习高层的特征;然后,通过几个反卷积层学到上采样滤波器参数;最后,通过一个卷积层生成高分辨率输出图像。
2017年SRGAN(SRResNet)将生成对抗网络(Generative Adversarial Network, GAN)用在引入到超分辨率问题上。训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节,使人不能有好的视觉感受。SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更加的相似。SRGAN的工作:生成器G通过低分辨率的图像生成高分辨率图像,由鉴别器D判断输入的图像是由G生成的,还是数据库中的原图像(真图像)。当G能成功骗过D的时,即可通过这个GAN完成超分辨率。使用用均方误差优化SRResNet(SRGAN的生成网络部分),能够得到具有很高的峰值信噪比的结果。在训练好的VGG模型的高层特征上计算感知损失来优化SRGAN,并结合SRGAN的判别网络D,能够得到峰值信噪比不高但具有逼真视觉效果的输出结果,SRGAN网络结构如下图所示:
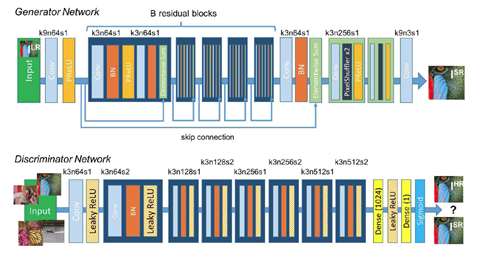
在生成网络部分SRResNet部分G包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。在判别网络部分D包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。实验结果表明,采用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分的细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。
2017年EDSR去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量,EDSR的网络结构如下图所示:
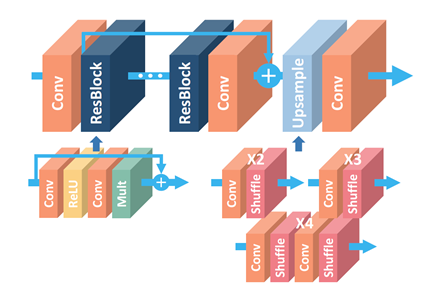
EDSR在结构上与SRResNet相比,EDSR把批规范化处理(batch normalization, BN)操作给去掉。由于原始的ResNet开始是被提出来解决高层的计算机视觉问题,如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的解决方式。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样既能够减少高倍数上采样模型的训练时间,同时训练结果也更好。
来源于网络

 浙公网安备 33010602011771号
浙公网安备 33010602011771号