NLP经典代码复盘-Word2Vec-介绍+逐行代码解析
Part1-相关介绍
对于计算机,它是如何判断一个词的词性,是动词还是名词的呢?
我们有一系列样本(x,y),对于计算机技术机器学习而言,这里的 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射:
首先,这个数学模型 f(比如神经网络、SVM)只接受数值型输入;
而 NLP 里的词语,是人类语言的抽象总结,是符号形式的(比如中文、英文、拉丁文等等);
如此一来,咱们便需要把NLP里的词语转换成数值形式,或者嵌入到一个数学空间里;
我们可以把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量
一种简单的词向量是one-hot encoder,其思想跟特征工程里处理类别变量的 one-hot 一样 (如之前所述,本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语)



当然,传统的one-hot 编码仅仅只是将词符号化,不包含任何语义信息。而且词的独热表示(one-hot representation)是高维的,且在高维向量中只有一个维度描述了词的语义 (高到什么程度呢?词典有多大就有多少维,一般至少上万的维度)。所以我们需要解决两个问题:1 需要赋予词语义信息,2 降低维度。
这就轮到Word2Vec出场了。
word2vec是Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,基本出发点是上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似


Word2vec模式下的两个模型:CBOW和SkipGram

CBOW
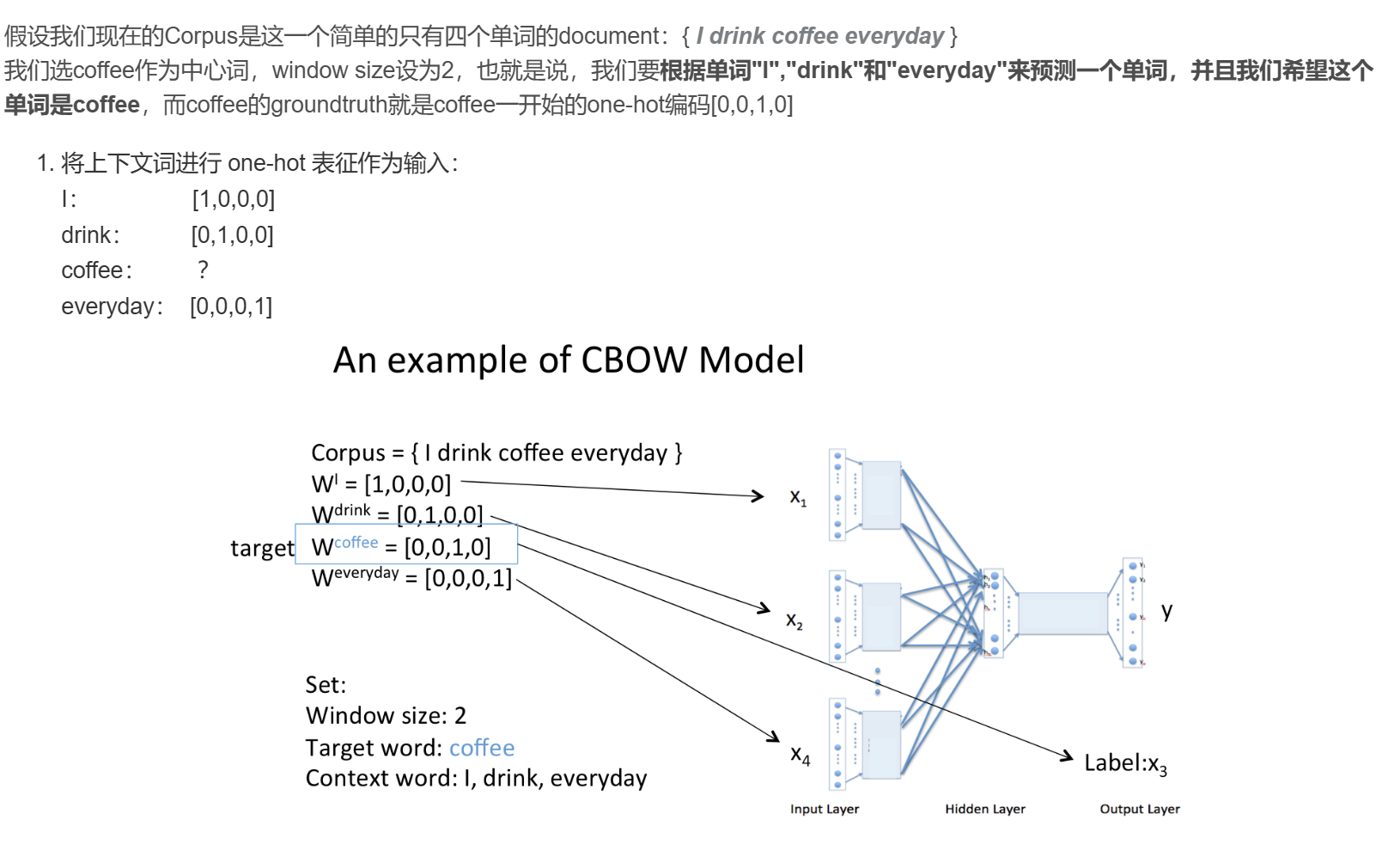
CBOW 模型训练的基本步骤包括:
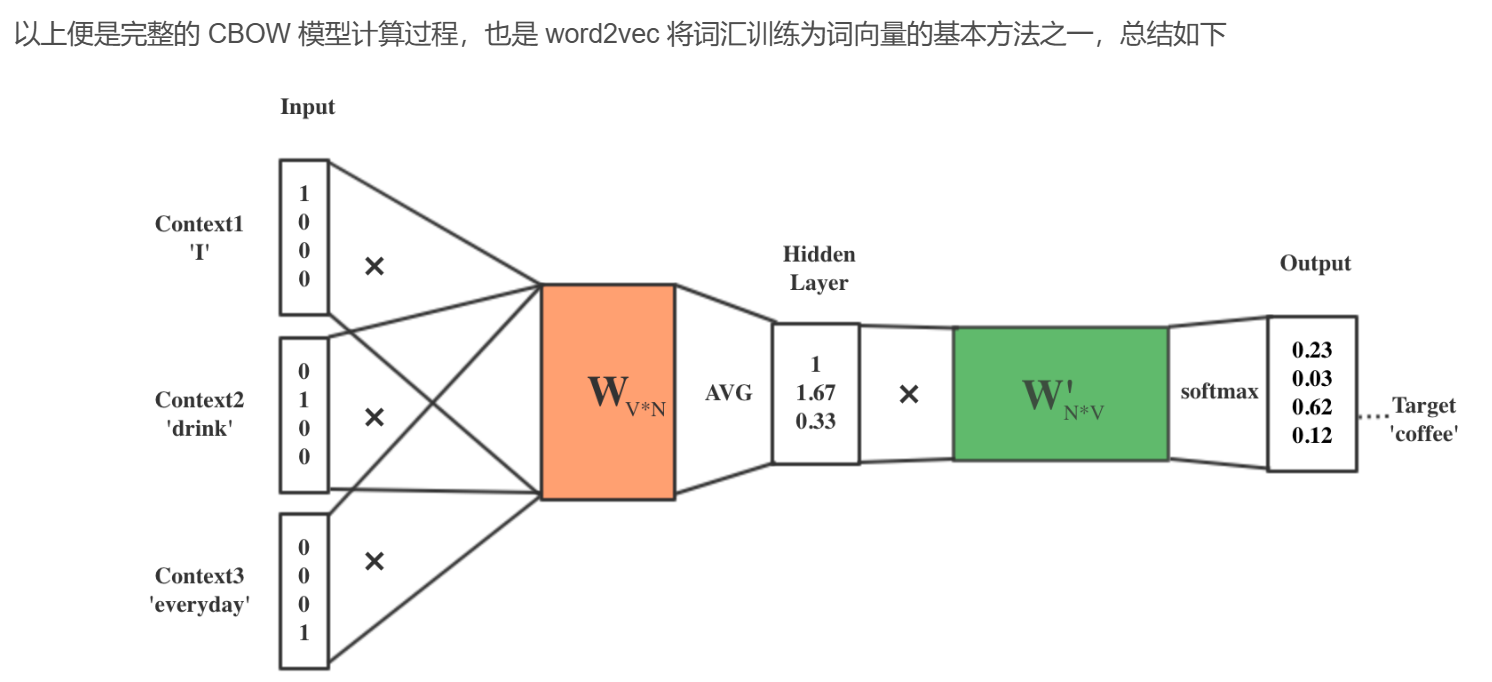
将上下文词进行 one-hot 表征作为模型的输入,其中词汇表的维度为 V,上下文单词数量为C ;
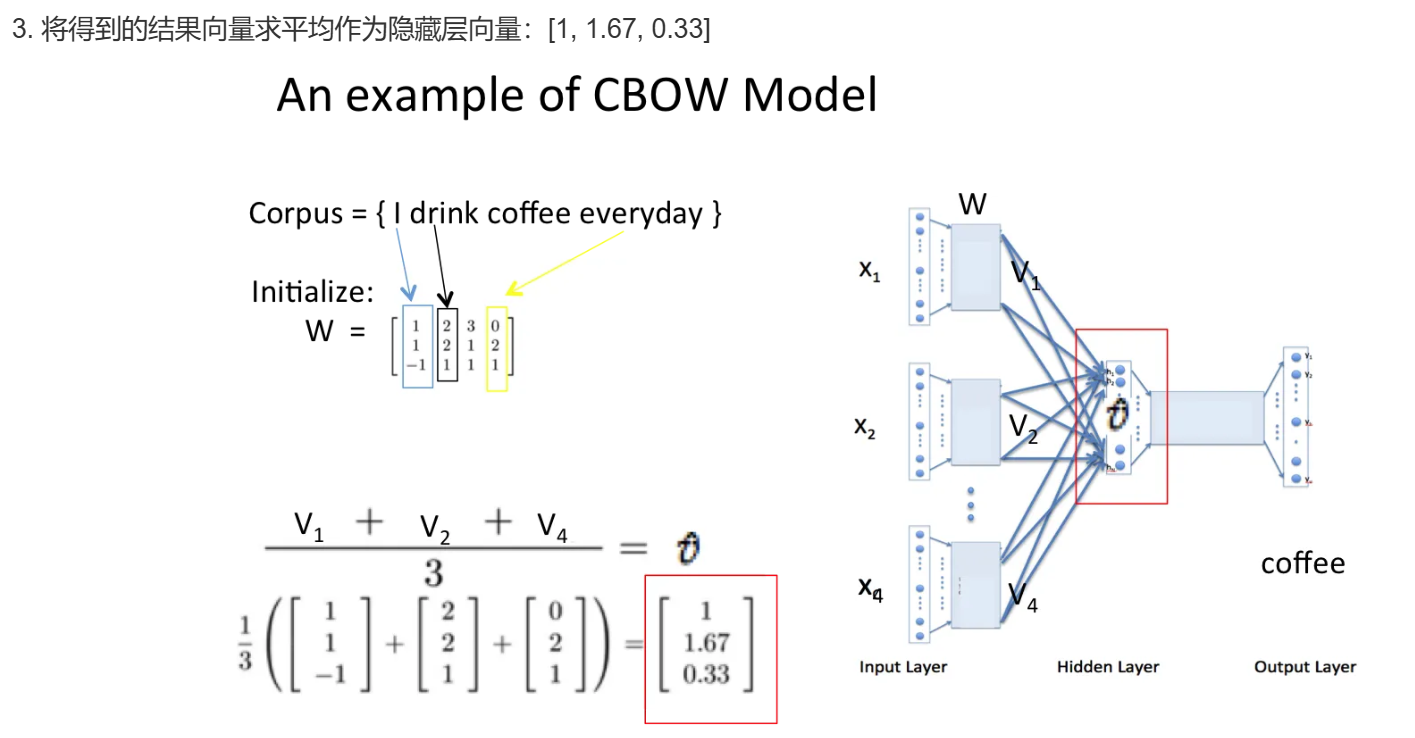
然后将所有上下文词汇的 one-hot 向量分别乘以输入层到隐层的权重矩阵W;
将上一步得到的各个向量相加取平均作为隐藏层向量;
将隐藏层向量乘以隐藏层到输出层的权重矩阵W’;
将计算得到的向量做 softmax 激活处理得到 V 维的概率分布,取概率最大的索引作为预测的目标词





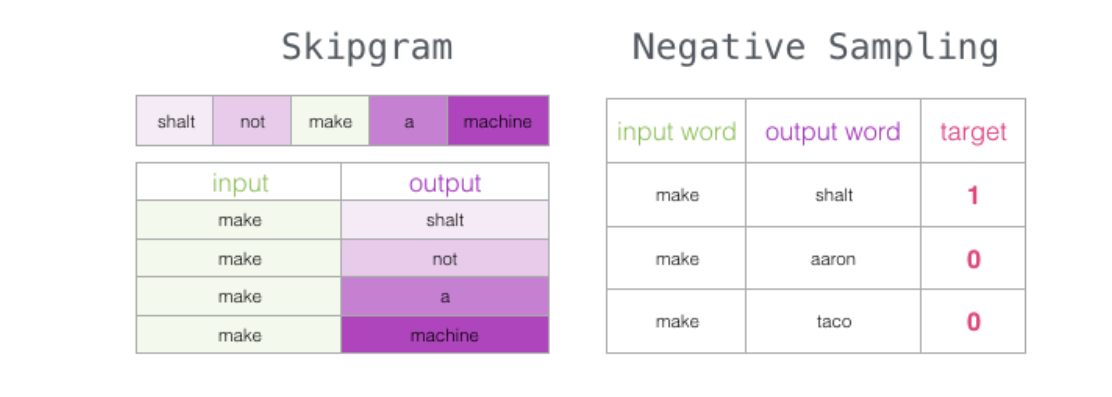
Skip-gram
上面讨论过Skip-gram的最简单情形,即 y 只有一个词。
当 y 有多个词时,网络结构如下:可以看成是 单个x->单个y 模型的并联,cost function 是单个 cost function 的累加(取log之后,图来自2014年Xin Rong的文章)。

负例采样
标记邻居的负例样本:
Part2-代码逐行解释
# 导入必要的库 import numpy as np import torch import torch.nn as nn import torch.optim as optim import matplotlib.pyplot as plt # 定义随机批次生成函数 def random_batch(): random_inputs = [] random_labels = [] # 随机选择batch_size个样本的索引,不重复 random_index = np.random.choice(range(len(skip_grams)), batch_size, replace=False) for i in random_index: # 将目标词转换为one-hot编码 random_inputs.append(np.eye(voc_size)[skip_grams[i][0]]) # target word的one-hot向量 random_labels.append(skip_grams[i][1]) # context word的索引 return random_inputs, random_labels # 定义Word2Vec模型类 class Word2Vec(nn.Module): def __init__(self): super(Word2Vec, self).__init__() # 定义两个线性层,注意W和WT不是转置关系 self.W = nn.Linear(voc_size, embedding_size, bias=False) # 输入层到隐藏层的权重矩阵 self.WT = nn.Linear(embedding_size, voc_size, bias=False) # 隐藏层到输出层的权重矩阵 def forward(self, X): # X的shape是[batch_size, voc_size] hidden_layer = self.W(X) # 生成词嵌入,shape: [batch_size, embedding_size] output_layer = self.WT(hidden_layer) # 预测上下文词,shape: [batch_size, voc_size] return output_layer # 主程序 if __name__ == '__main__': # 设置超参数 batch_size = 2 # 每批处理的样本数 embedding_size = 2 # 词嵌入的维度 # 准备训练数据 sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit", "dog cat animal", "cat monkey animal", "monkey dog animal"] word_sequence = " ".join(sentences).split() # 将所有句子连接并分词 word_list = " ".join(sentences).split() word_list = list(set(word_list)) # 获取唯一词列表 word_dict = {w: i for i, w in enumerate(word_list)} # 创建词到索引的映射 voc_size = len(word_list) # 词表大小 # 生成Skip-gram对,窗口大小为1 skip_grams = [] for i in range(1, len(word_sequence) - 1): target = word_dict[word_sequence[i]] # 当前词的索引 context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]] # 前后词的索引 for w in context: skip_grams.append([target, w]) # 添加(目标词,上下文词)对 # 初始化模型、损失函数和优化器 model = Word2Vec() criterion = nn.CrossEntropyLoss() # 使用交叉熵损失 optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器 # 训练循环 for epoch in range(5000): # 获取随机批次数据 input_batch, target_batch = random_batch() input_batch = torch.Tensor(input_batch) target_batch = torch.LongTensor(target_batch) optimizer.zero_grad() # 清零梯度 output = model(input_batch) # 前向传播 # 计算损失 loss = criterion(output, target_batch) if (epoch + 1) % 1000 == 0: print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward() # 反向传播 optimizer.step() # 更新参数 # 可视化词嵌入结果 for i, label in enumerate(word_list): W, WT = model.parameters() # 获取模型参数 x, y = W[0][i].item(), W[1][i].item() # 获取每个词的二维坐标 plt.scatter(x, y) # 绘制散点 plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show() # 显示图像
Part3-学习链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号