
lambda表达式-02 Stream详解
一、什么是Stream?Stream有什么优点呢?
Stream是处理数组和集合的API

二、Sream的生成操作:
1 String[] arr = new String[]{"2", "3", "4"}; 2 Stream.of(arr).forEach(System.out::println); 3 //通过集合来生成 4 List<String> list = Arrays.asList("a", "b", "c"); 5 Stream<String> stream = list.stream(); 6 stream.forEach(System.out::println); 7 8 Stream<Integer> generate11 = Stream.generate(() ->1); 9 // generate11.forEach(System.out::println); 10 generate11.limit(10).forEach(System.out::println); 11 //使用iterator 12 Stream<Integer> iterate = Stream.iterate(2, (x) -> x + 1); 13 iterate.limit(10).forEach(System.out::println);
三、Stream的中间操作:注意:只要不到最终执行结果,流是不会执行的,这样大大的节省内存空间。 只要中间是取到的Stream,那么他永远不会执行 可以通过filter测试
List<Integer> list = Arrays.asList(1,2, 3, 4, 5, 6);
//中间操作过滤
// list.stream().filter(x->x%2==0).forEach(System.out::println);
//求和
// int sum =list.stream().mapToInt(x -> x + 1).sum();
//取最大值
// Optional<Integer> max = list.stream().max((a, b) -> a - b);
// System.out.println(max.get());
//求集合的最小值
// System.out.println(list.stream().min((a, b) -> a - b).get());
//取任何一个
System.out.println(list.stream().findFirst().get());
}
四:手写stream的操作:

通过一系列流操作返回一个集合和去重操作:
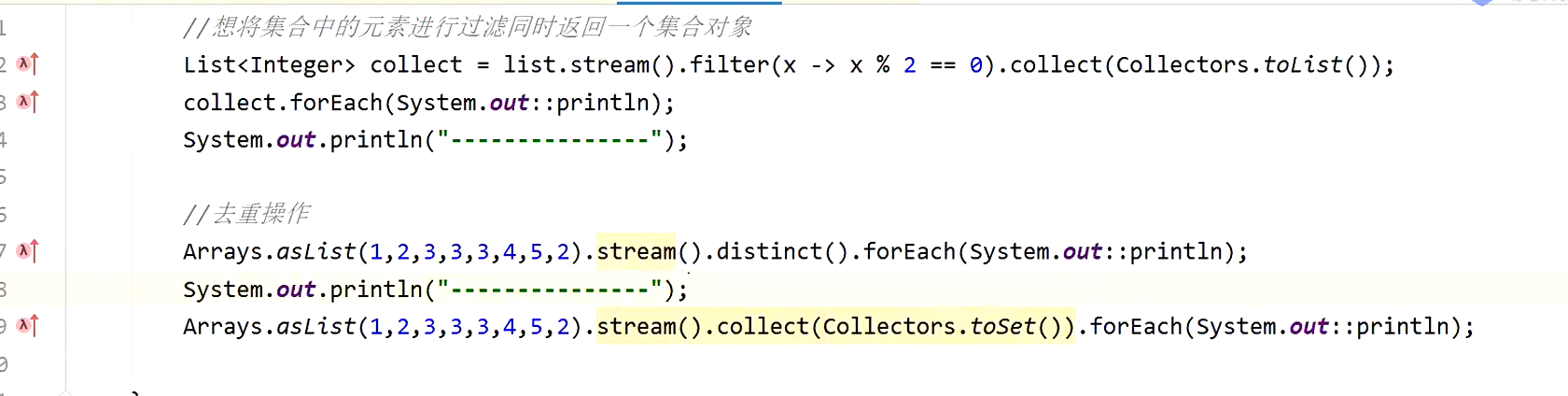
SKIP 跳过多少个 mapToInt转换为Int--实现分页查询的功能

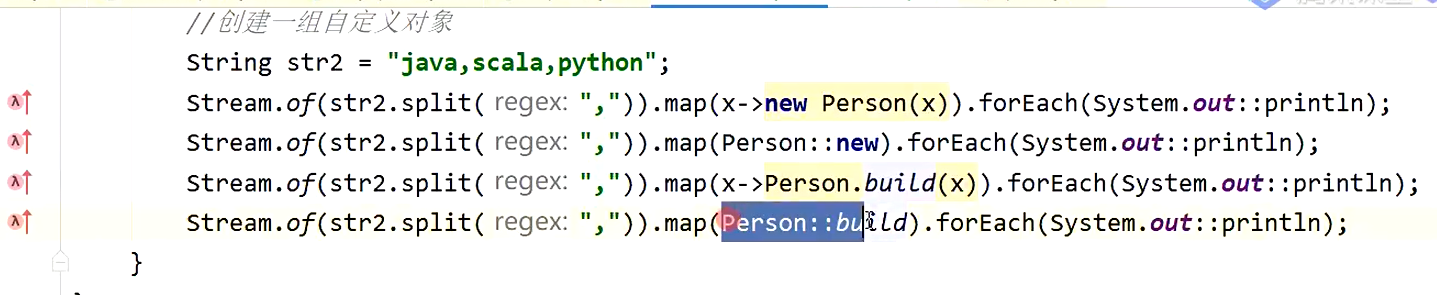
五:创建一组自定义对象
六:基于Stream的项目使用:
List<OmsBannerManager> selectList = omsBannerManagerMapper.selectList(new QueryWrapper<>()); List<OmsBannerManager> collect = selectList.stream().filter(x -> null != x.getStartTime() && null != x.getEndTime()).filter(x -> { Date startTime = x.getStartTime(); return compareDate(startTime); }).filter(x -> x.getSurplusDay() > 0).map(x -> x.setSurplusDay(x.getSurplusDay() - 1)).map(x -> x.getSurplusDay() == 0 ? x.setStatus("1") : x ).collect(Collectors.toList()); this.saveOrUpdateBatch(collect);
七:ListStream基于对象的使用:
public class StreamTest { public static void main(String[] args) { List<Person> personList = new ArrayList<Person>(); personList.add(new Person("Tom", 8900, 23, "male", "New York")); personList.add(new Person("Jack", 7000, 25, "male", "Washington")); personList.add(new Person("Lily", 7800, 21, "female", "Washington")); // 求总数 Long count = personList.stream().collect(Collectors.counting()); // 求平均工资 Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary)); // 求最高工资 Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare)); // 求工资之和 Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary)); // 一次性统计所有信息 DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary)); System.out.println("员工总数:" + count); System.out.println("员工平均工资:" + average); System.out.println("员工工资总和:" + sum); System.out.println("员工工资所有统计:" + collect); } }
判断有没有大于其中某一个的值:
boolean a = students.steam().anyMatch(item -> item.getAge() > 35) 判断同学集合有没有年龄大于35岁的。
七:list转换为map。可以根据String,format设置不同的key,也可以设置不同value
Map<String, String> collect = strings.stream().collect(Collectors.toMap(info -> String.format("%s-%s", info, info), info -> info));
八:jdk8对map的迭代方式
// JDK8的迭代方式 map.forEach((key, value) -> { System.out.println(key + ":" + value); }); }
九:peek的操作:
peek最主要的日志打印,debug使用。不会改变流中的值,但是如果流中存放的是对象,是会改变对象的属性。https://blog.csdn.net/weixin_42218169/article/details/117357054
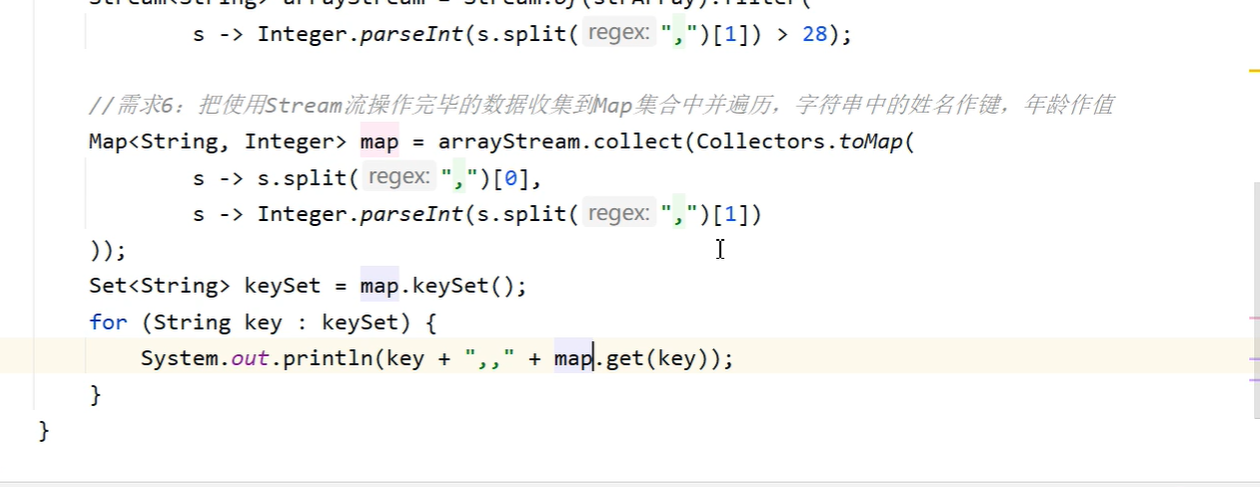
10:将list转换为map
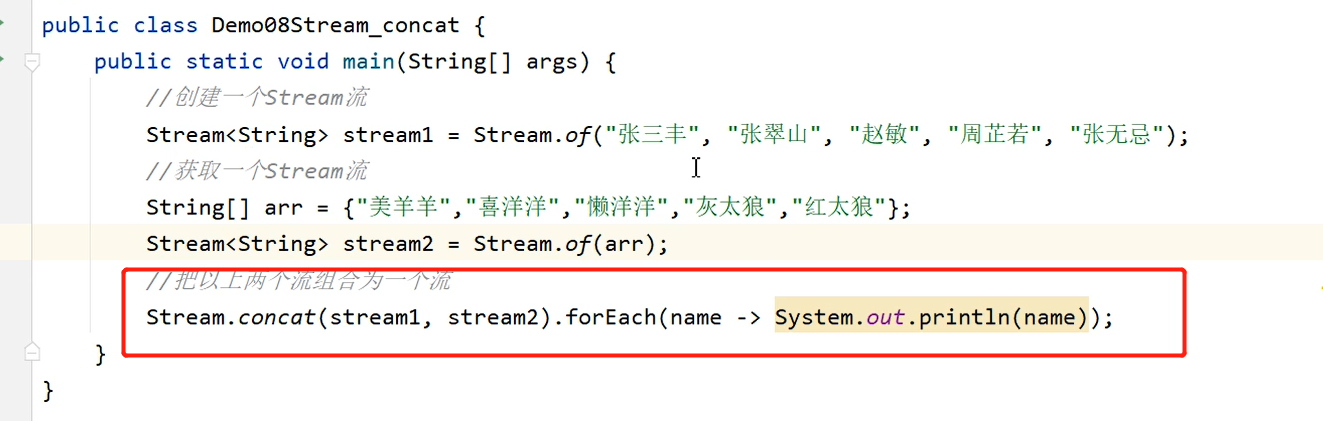
11、concat将两个以上的流合并成一个流
12、reduce的使用
1.Math.max(a,b) 可以比较大小 Integer.sum()计算两个数的之和。
// 1.求出所有年龄的总和
Integer sumAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).map(Person::getAge) // 实现数据类型的转换
.reduce(0, Integer::sum);
System.out.println(sumAge);
// 2.求出所有年龄中的最大值
Integer maxAge = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).map(Person::getAge) // 实现数据类型的转换,符合reduce对数据的要求
.reduce(0, Math::max); // reduce实现数据的处理
System.out.println(maxAge);
Person person = Stream.of(
new Person("张三", 18)
, new Person("李四", 22)
, new Person("张三", 13)
, new Person("王五", 15)
, new Person("张三", 19)
).max((a, b) -> a.age - b.age
).get();
System.out.println(person);
// 3.统计 字符 a 出现的次数
Integer count = Stream.of("a", "b", "c", "d", "a", "c", "a")
.map(ch -> "a".equals(ch) ? 1 : 0)
.reduce(0, Integer::sum);
System.out.println(count);
13、对流中的数据进行聚合运算 当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作,比如获得最大值,最小值,求和,平均值,统计数量。
Optional<Person> maxAge = Stream.of( new Person("张三", 18) , new Person("李四", 22) , new Person("张三", 13) , new Person("王五", 15) , new Person("张三", 19) ).collect(Collectors.maxBy((p1, p2) -> p1.getAge() - p2.getAge())); 当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作,比如获得最大值,最小值,求和,平均值,统计数量。
.collect(Collectors.summingInt(Person::getAge))
ollect(Collectors.averagingInt(Person::getAge));
.collect(Collectors.counting());
14、
/** * 分组计算 */ @Test public void test04(){ // 根据账号对数据进行分组 Map<String, List<Person>> map1 = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).collect(Collectors.groupingBy(Person::getName)); map1.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v)); System.out.println("-----------"); // 根据年龄分组 如果大于等于18 成年否则未成年 Map<String, List<Person>> map2 = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).collect(Collectors.groupingBy(p -> p.getAge() >= 18 ? "成年" : "未成年")); map2.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v)); } 输出结果: k=李四 v=[Person{name='李四', age=22, height=177}, Person{name='李四', age=15, height=166}] k=张三 v=[Person{name='张三', age=18, height=175}, Person{name='张三', age=14, height=165}, Person{name='张三', age=19, height=182}] ----------- k=未成年 v=[Person{name='张三', age=14, height=165}, Person{name='李四', age=15, height=166}] k=成年 v=[Person{name='张三', age=18, height=175}, Person{name='李四', age=22, height=177}, Person{name='张三', age=19, height=182}]
多级分组操作:
/** * 分组计算--多级分组 */ @Test public void test05(){ // 先根据name分组,然后根据age(成年和未成年)分组 Map<String,Map<Object,List<Person>>> map = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).collect(Collectors.groupingBy( Person::getName ,Collectors.groupingBy(p->p.getAge()>=18?"成年":"未成年" ) )); map.forEach((k,v)->{ System.out.println(k); v.forEach((k1,v1)->{ System.out.println("\t"+k1 + "=" + v1); }); }); } 输出结果: 李四 未成年=[Person{name='李四', age=15, height=166}] 成年=[Person{name='李四', age=22, height=177}] 张三 未成年=[Person{name='张三', age=14, height=165}] 成年=[Person{name='张三', age=18, height=175}, Person{name='张三', age=19, height=182}]
15、对数据流的分区 操作 流的分区操作 流的分区操作和分组操作基本一致,就是把map的key 改为true和false
/** * 分区操作 */ @Test public void test06(){ Map<Boolean, List<Person>> map = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).collect(Collectors.partitioningBy(p -> p.getAge() > 18)); map.forEach((k,v)-> System.out.println(k+"\t" + v)); } 输出结果: false [Person{name='张三', age=18, height=175}, Person{name='张三', age=14, height=165}, Person{name='李四', age=15, height=166}] true [Person{name='李四', age=22, height=177}, Person{name='张三', age=19, height=182}]
16、对流中的数据做拼接操作:Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
/** * 对流中的数据做拼接操作 */ @Test public void test07(){ String s1 = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).map(Person::getName) .collect(Collectors.joining()); // 张三李四张三李四张三 System.out.println(s1); String s2 = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).map(Person::getName) .collect(Collectors.joining("_")); // 张三_李四_张三_李四_张三 System.out.println(s2); String s3 = Stream.of( new Person("张三", 18, 175) , new Person("李四", 22, 177) , new Person("张三", 14, 165) , new Person("李四", 15, 166) , new Person("张三", 19, 182) ).map(Person::getName) .collect(Collectors.joining("_", "###", "$$$")); // ###张三_李四_张三_李四_张三$$$ System.out.println(s3); }
17、并行流
获取并行流的两种方式:
public void test02(){ List<Integer> list = new ArrayList<>(); // 通过List 接口 直接获取并行流 Stream<Integer> integerStream = list.parallelStream(); // 将已有的串行流转换为并行流 Stream<Integer> parallel = Stream.of(1, 2, 3).parallel();
18、并行流的测试
本文来自博客园,作者:Jerry&Ming,转载请注明原文链接:https://www.cnblogs.com/jerry-ming/p/16032119.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号