oreacle中sql关键字的使用
1、数据集合的操作
--并集,将两个集合中的所有数据都进行显示,但是不包含重复的数据 select * from emp where deptno =30 union select * from emp where sal >1000; --全集,将两个集合的数据全部显示,不会完成去重的操作 select * from emp where deptno =30 union all select * from emp where sal >1000; --交集,两个集合中交叉的数据集,只显示一次 select * from emp where deptno =30 intersect select * from emp where sal >1000; --差集,包含在A集合而不包含在B集合中的数据,跟A和B的集合顺序相关 select * from emp where deptno =30 minus select * from emp where sal >1000;
2、模糊查询关键字的使用:
%:表示任意个字符,包括零个;
_:表示一个任意字符;
3、case when then的使用 注意:Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略
SELECT s.s_id, s.s_name, s.s_sex, CASE WHEN s.s_sex = '1' THEN '男' WHEN s.s_sex = '2' THEN '女' ELSE '其他' END as sex, s.s_age, s.class_id FROM t_b_student s WHERE 1 = 1
<select id="selectAllProblems" resultMap="BaseResultMap"> select id,column_name,problem_id, car_mode, title from ( select t1.id, (case when #{lang} = 'zh' then t1.column_name when #{lang} = 'en' then t1.english_column_name when #{lang} = 'fr' then t1.french_column_name when #{lang} = 'es' then t1.spanish_column_name when #{lang} = 'ru' then t1.russian_column_name end) as column_name, t2.id as problem_id, t2.car_mode, (case when #{lang} = 'zh' then t2.problem_title when #{lang} = 'en' then t2.english_problem_title when #{lang} = 'fr' then t2.french_problem_title when #{lang} = 'es' then t2.spanish_problem_title when #{lang} = 'ru' then t2.russian_problem_title end) as title from oms_content_manage_column t1, oms_content_manage_problem t2 where t1.id = t2.problem_column_id <if test="title != null and title != ''"> and (case when #{lang} = 'zh' then t2.problem_title when #{lang} = 'en' then t2.english_problem_title when #{lang} = 'fr' then t2.french_problem_title when #{lang} = 'es' then t2.spanish_problem_title when #{lang} = 'ru' then t2.russian_problem_title end) like '%' || #{title} || '%' </if> and t1.column_state = '1' and t2.problem_subsystem in ('01', '03') and t2.problem_state = '1' and t2.display_flag = '1' and t2.car_mode = #{autoType} and t2.del_flag = 0 and t1.del_flag = 0 order by t1.column_sort desc,t2.problem_sort desc ) union all select id,column_name,problem_id, car_mode, title from ( select t1.id, (case when #{lang} = 'zh' then t1.column_name when #{lang} = 'en' then t1.english_column_name when #{lang} = 'fr' then t1.french_column_name when #{lang} = 'es' then t1.spanish_column_name when #{lang} = 'ru' then t1.russian_column_name end) as column_name, t2.id as problem_id, t2.car_mode, (case when #{lang} = 'zh' then t2.problem_title when #{lang} = 'en' then t2.english_problem_title when #{lang} = 'fr' then t2.french_problem_title when #{lang} = 'es' then t2.spanish_problem_title when #{lang} = 'ru' then t2.russian_problem_title end) as title from oms_content_manage_column t1, oms_content_manage_problem t2 where t1.id = t2.problem_column_id <if test="title != null and title != ''"> and (case when #{lang} = 'zh' then t2.problem_title when #{lang} = 'en' then t2.english_problem_title when #{lang} = 'fr' then t2.french_problem_title when #{lang} = 'es' then t2.spanish_problem_title when #{lang} = 'ru' then t2.russian_problem_title end) like '%' || #{title} || '%' </if> and t1.column_state = '1' and t2.problem_subsystem in ('01', '03') and t2.problem_state = '1' and t2.display_flag = '1' and t2.car_mode is null and t2.del_flag = 0 and t1.del_flag = 0 order by t1.column_sort desc,problem_sort desc ) </select>
select id, case when column_name is not null then '中' else '' end as columnName, case when english_column_name is not null then '英' else '' end as englishColumnName, case when french_column_name is not null then '法' else '' end as frenchColumnName, case when spanish_column_name is not null then '西' else '' end as spanishColumnName, case when russian_column_name is not null then '俄' else '' end as russianColumnName from oms_content_manage_column
and case when t.AUDIT_ROLE = 'national_service_manager' then t2.COUNTRY_CODE else #{countryList[0]} end in <foreach collection="countryList" item="country" open="(" close=")" separator=","> #{country,jdbcType=VARCHAR} </foreach>
4、in/not in 的作用:
(1)in 常用于条件表达式(where)中,它的作用是对某个范围内的数据进行操作,查询或删除。字段值只要满足这个范围之内的任意一个即可
(2)not in 作用是查询不在某个范围内的数据,字段值同时不满这个范围的所有值。
2、语法:
(1)select * from TableName(表名) where 字段 in (value1,value2,…);
(2)select * from TableName(表名) where 字段 not in (value1,value2,…);
(3)select 字段1,字段2,… from 表名 where 字段 in/not in (value1,value2,…);
5、EXIST 和not exist 关键字的使用 in和not in的区别
SELECT ID,NAME FROM A WHERE EXIST (SELECT * FROM B WHERE A.ID=B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=1)
---> SELECT * FROM B WHERE B.AID=1有值,返回真,所以有数据
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=2)
---> SELECT * FROM B WHERE B.AID=2有值,返回真,所以有数据
SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=3)
---> SELECT * FROM B WHERE B.AID=3无值,返回假,所以没有数据
NOT EXISTS 就是反过来
SELECT ID,NAME FROM A WHERE NOT EXIST (SELECT * FROM B WHERE A.ID=B.AID)
执行结果为
3 A3
===========================================================================
EXISTS = IN,意思相同不过语法上有点点区别,好像使用IN效率要差点,应该是不会执行索引的原因
SELECT ID,NAME FROM A WHERE ID IN (SELECT AID FROM B)
NOT EXISTS = NOT IN ,意思相同不过语法上有点点区别
SELECT ID,NAME FROM A WHERE ID NOT IN (SELECT AID FROM B)
链接如下:https://www.cnblogs.com/xuanhai/p/5810918.html
6、oreacle中list的使用
判断list <if test="countryList == null or countryList.size == 0"> 是否在集合中: <if test="roleSet != null and roleSet.size > 0"> and t.AUDIT_ROLE in <foreach collection="roleSet" item="role" open="(" close=")" separator=","> #{role,jdbcType=VARCHAR} </foreach> </if>
7、oreacle中时间比较 获取当前时间 时间比较范围
如果都是date类型可以直接比较:
<if test="repairStartDate!=null and endRepairDate!=null " > AND o.REPAIR_TIME between #{repairStartDate} and #{endRepairDate} </if>
更改日期类型格式比较:
select trunc(123.128,2) from dual; --截断数据,按照位数去进行截取,但是不会进行四舍五入的操作
and to_char(t.item_Date,'yyyy-MM-dd') = to_char(#{omsOldMaterialHandleVO.itemDate},'yyyy-MM-dd')
当前时间在某个时间范围内:
当前日期进行截取 yy截取到年 mm截取到月 dd截取到日
select TO_CHAR ( TRUNC (SYSDATE, 'yy'), 'YYYY-MM-DD hh24:mi:ss' ) from dual;
AND TO_CHAR ( TRUNC (SYSDATE, 'dd'), 'YYYY-MM-DD hh24:mi:ss' ) BETWEEN TO_CHAR ( ra.RECTIFICATION_ENDTIME, 'YYYY-MM-DD hh24:mi:ss' ) AND TO_CHAR ( TRUNC (ra.RECTIFICATION_ENDTIME) + 30, 'YYYY-MM-DD hh24:mi:ss' )
8、NVL关键字的使用
1、NVL(表达式A,表达式B)
如果表达式A为空值,NVL返回值为表达式B的值,否则返回表达式A的值。该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是表达式A和表达式B的数据类型必须为同一个类型。
例:
2、NVL2(表达式A,表达式B,表达式C)
9、listagg关键字使用: 使用 listagg() WITHIN GROUP () 将多行合并成一行(比较常用)
SELECT OCP.*, su.realName AS currentHandlerName, ( SELECT listagg ( CAST ( su1.realname AS VARCHAR2 (500) ), ',' ) WITHIN GROUP ( ORDER BY OCA.SERVICE_INCENTIVE_ID ) FROM oms_ser_incentive_result OCA
https://blog.csdn.net/sinat_36257389/article/details/81004843
其中cast函数的使用:
一、转换列或值
语法:cast( 列名/值 as 数据类型 )
用例:
1)、转换列
--将empno的类型(number)转换为varchar2类型。
select cast(empno as varchar2(10)) as empno from emp;
10、oreacle中group by 设计到分组会取最大值 最小值 和的值计算 max min sum
例如: 设计的案例可以查询如下:
https://www.cnblogs.com/haozhengfei/p/e6a9a2f95b0b85887857e00176e800a8.html
https://baijiahao.baidu.com/s?id=1664040284917893293&wfr=spider&for=p
11、oracle之nulls last
select * from 表 where 条件 order by 某个字段 (asc/descv) nulls last;
nulls first和nulls last是Oracle Order by支持的语法
如果Order by 中指定了表达式Nulls first则表示null值的记录将排在最前(不管是asc 还是 desc)
如果Order by 中指定了表达式Nulls last则表示null值的记录将排在最后 (不管是asc 还是 desc)
12、oreacle之关联Update
UPDATE OMS_CARINFO_RECTIFICATION t1 SET T1.is_repair ='1' WHERE t1.lathe_number= '20H86BX-0105' and EXISTS(SELECT 1 FROM RECTIFICATION_ACTIVITY_INFO T2 WHERE t1.service_id = t2.id and t2.RECTIFICATION_ACTIVITY_NUM = 'B20220101') ; UPDATE ( select t1.is_repair from OMS_CARINFO_RECTIFICATION t1,RECTIFICATION_ACTIVITY_INFO t2 where t1.service_id = t2.id and t2.RECTIFICATION_ACTIVITY_NUM = 'B20220101' and t1.lathe_number= '20H86BX-0105' )t set is_repair='1';
13、oreacle值coalesec
coalesec(case1,case2) 如果第一个为空的话,取第二个的值。
14、row_number() over(partition by 列名1 order by 列名2 desc)的使用
表示根据 列名1 分组,然后在分组内部根据 列名2 排序,而此函数计算的值就表示每组内部排序后的顺序编号,可以用于去重复值
select *
FROM
dms_warranty_material dm
LEFT JOIN dms_warranty_order do ON dm.warranty_order_no = do.WARRANTY_ORDER_NO
LEFT JOIN (
SELECT
*
FROM
(
SELECT
ah. ID,
ah.audit_by,
ah.audit_time,
ah.audit_role,
ah.main_id,
ah.audit_type,
ROW_NUMBER () OVER (
PARTITION BY ah.main_id
ORDER BY
ah.audit_time DESC
) AS code_id
FROM
dms_warranty_audit_history ah
WHERE
ah.del_flag = 0
AND ah.audit_role LIKE '%OVERSEA%'
AND ah.audit_type = '00'
)
WHERE
code_id = 1
) oah ON oah.main_id = do. ID
LEFT JOIN (
SELECT
*
FROM
(
SELECT
ah. ID,
ah.audit_by,
ah.audit_time,
ah.audit_role,
ah.main_id,
ah.audit_type,
ROW_NUMBER () OVER (
PARTITION BY ah.main_id
ORDER BY
ah.audit_time DESC
) AS code_id
FROM
dms_warranty_audit_history ah
WHERE
ah.del_flag = 0
AND ah.audit_role LIKE '%SETTLE%'
AND ah.audit_type = '00'
)
WHERE
code_id = 1
) sah ON sah.main_id = do. ID
WHERE
dm.del_flag = 0
其中 在关联字表的时候,where 写在主表外面 和写在字表里面是有区别的。写在字表里面是 过滤字表的数据,写在外面是过滤主表的数据。
15.为了防止sql注入 不等于用 1 <> 1
16.exists关键字
/*exists(sub-query),当exists中的子查询语句能查到对应结果的时候, 意味着条件满足 相当于双层for循环 --现在要查询部门编号为10和20的员工,要求使用exists实现 */ select * from emp where deptno = 10 or deptno = 20; --通过外层循环来规范内层循环 select * from emp e where exists (select deptno from dept d where (d.deptno = 10 or d.deptno = 20) and e.deptno = d.deptno)
17.取两个日期的交集之和
SUM (LEAST (table.date,#{req.date1}) - GREATEST (table.date1,#{req.date1}))
18.判断数据是否包含 find_in_set
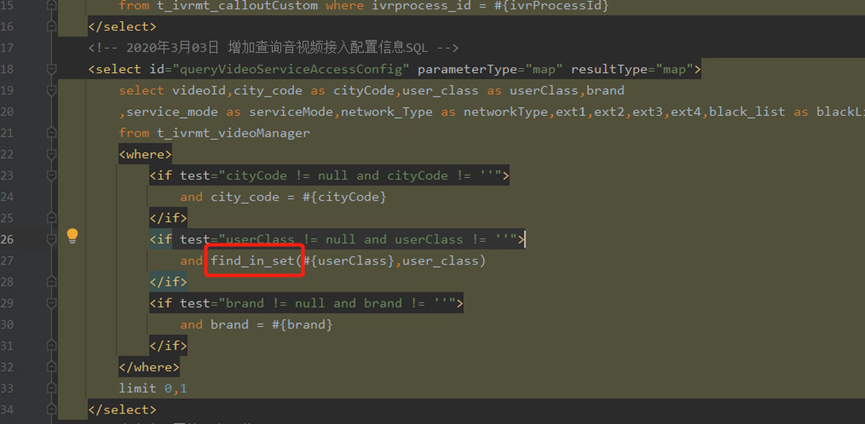
19.当我们在写sql的时候,不便于查询条件的时候
${ew.customSqlSegment}在使用时,相当与 where + queryWrapper内的条件
${ew.sqlSegment}相当于queryWrapper内的条件
xml文件:@Param(Constants.WRAPPER) Wrapper<对象> wrapper111
https://blog.csdn.net/web15870359587/article/details/123424173
20,如果我们要查询不是固定的列,那么可以用${},
在Mybatis中,${column} 会被直接替换,而 #{value} 会使用 ? 预处理。 注意:#{value}预处理:!!!----->对于使用#{}形式导入的参数,会在预处理的时候加上''单引号,
参考:https://www.cnblogs.com/bulter/p/14940517.html
21.关于update的理解:首先要查询到要更新的那一条数据,通过existx来判断,如果为true拿到这条数据。然后通过逐个字段更新。主表只可以用在字表的最外层上。
UPDATE 表名称 表昵称 表昵称.字段名 = ( SELECT t1.字段名 FROM ( SELECT pt.字段名, pt.order_code, pt.part_code, ROW_NUMBER () OVER ( PARTITION BY pt.part_code, pt.order_code ORDER BY pt.create_time ASC ) AS code_id FROM oms_lack_parts pt WHERE pt.del_flag = 0 ) t1 WHERE t1.code_id = 1 AND t1.order_code = 表昵称.order_code AND t1.part_code = 表昵称.part_code ), 表昵称.unmet_Basic_Amount = ( SELECT SUM (unmet_Basic_Amount) FROM oms_lack_parts t1 WHERE t1.part_code = 表昵称.part_code AND t1.order_code = 表昵称.order_code ), --数量 表昵称.reject_Times = ( SELECT SUM (reject_Times) FROM oms_lack_parts t1 WHERE t1.part_code = 表昵称.part_code AND t1.order_code = 表昵称.order_code ) WHERE EXISTS ( SELECT 0 FROM ( SELECT tt. ID, tt.part_code, tt.order_code, tt.lack_code, tt.lack_status, tt.create_time, ROW_NUMBER () OVER ( PARTITION BY tt.part_code, tt.order_code ORDER BY tt.create_time ASC ) AS code_id, ROW_NUMBER () OVER ( PARTITION BY tt.part_code, tt.order_code ORDER BY tt.create_time DESC ) AS code_id2, tt.字段名 FROM oms_lack_parts tt INNER JOIN ( SELECT T .PART_CODE, T .order_code FROM OMS_LACK_PARTS T WHERE T .DEL_FLAG = '0' GROUP BY T .PART_CODE, T .ORDER_CODE HAVING COUNT (T .PART_CODE) > 1 ) t1 ON tt.part_code = t1.part_code AND tt.order_code = t1.order_code INNER JOIN oms_order_bill ob ON tt.order_code = ob.order_code AND ob.del_flag = 0 AND ob.supplier_code = '0000802964' ) T WHERE T .code_id2 = 1 AND T . ID = 表昵称. ID );
22.多行转一行 用的方法:WMSYS.WM_CONCAT排序
本文来自博客园,作者:Jerry&Ming,转载请注明原文链接:https://www.cnblogs.com/jerry-ming/p/15958236.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号