

数据结构与算法--双向链表
双向链表
为什么要讨论双向链表
-
单链表的结点有指向后继的指针域,找后继节点方便(找后继节点的时间复杂度是O(1))
-
单链表没有指向前驱结点的指针域,找前驱结点必须再次从表头出发(时间复杂度是O(n))
-
双向链表:在单链表的每个结点里面再增加一个指向直接前驱的指针域prior,这样链表中就形成了有两个方向不同的链,故称为双向链表
双向链表的结构可定义如下:
typedef struct DuLNode{ Elemtype data; struct DuLNode *prior,*next; }DuLNode,*DuLinkList;

双向循环链表
和单链的循环表类似,双向链表也可以有循环表
- 让头结点的前驱指针指向链表的最后一个结点
- 让最后一个结点的后继指针指向头结点

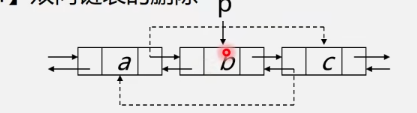
双向链表结构的对称性(设指针p指向某一结点):
p->prior->next=p=p->next->prior
双向链表中的操作(如ListLength\GetElem等)和线性链表相同。但是再插入、删除的时候,需要同时修改两个方向的指针,两者操作的时间复杂度均为O(n).
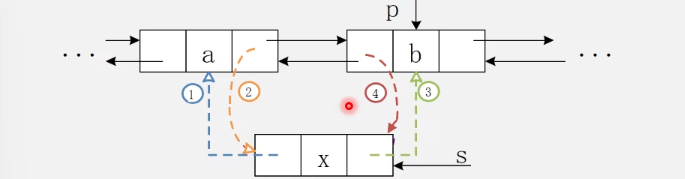
【算法】双链表的删除
- 关键步骤
-
1.p->prior->next=p->next; 2.p->next->prior=p->prior;
void ListDelete_Dul(DuLink &L,int i,Elemtype &e){
//删除带头结点的双向链表L的第i个元素,并用e返回
if(!(p=GetElemP_DuL(L,i))) return ERROR;
e = p->data;
p->prior->next = p->next;
p->next->prior=p->prior;
free(p);
return OK;
}//ListDelete_Dul

 浙公网安备 33010602011771号
浙公网安备 33010602011771号