# 搭建hadoop3.1.3环境
参考:https://blog.csdn.net/qq_29983883/article/details/108748444
使用三台虚拟机进行搭建,分别为node1,node2,node3
配置hosts
192.168.48.136 node1
192.168.48.139 node2
192.168.48.141 node3
添加java环境
首选在orcle网站下载jdk安装包,传送门
解压安装到/java目录下,修改/etc/profile文件,添加java路径
[root@localhost opt]# cp -af /etc/profile /etc/profile_bak
[root@localhost opt]# echo "JAVA_HOME=/java/jdk1.8.0_161" >> /etc/profile
[root@localhost opt]# echo "PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
[root@localhost opt]# echo "CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar" >> /etc/profile
[root@localhost opt]# echo "export JAVA_HOME" >> /etc/profile
[root@localhost opt]# echo "export PATH" >> /etc/profile
[root@localhost opt]# echo "export CLASSPATH" >> /etc/profile
[root@localhost opt]# source /etc/profile
下载并解压hadoop-3.1.3.tar.gz
下载地址:https://archive.apache.org/dist/hadoop/common/
mkdir -p /export/servers/ && tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/ && mv /export/servers/hadoop-3.1.3 /export/servers/hadoop
将hadoop路径配置到/etc/profile
export HADOOP_HOME=/export/servers/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
添加完执行source /etc/profile
创建目录
mkdir /export/servers/hadoop/dfs
mkdir /export/servers/hadoop/dfs/data
mkdir /export/servers/hadoop/dfs/name
mkdir /export/servers/hadoop/tmp
修改hadoop配置文件/export/servers/hadoop/etc/hadoop/hadoop-env.sh,添加Java路径
export JAVA_HOME=/java/jdk1.8.0_161
修改core-site.xml文件,文件所在目录/export/servers/hadoop/etc/hadoop,添加下面内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml ,添加下面内容
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<!-- Master为当前机器名或者IP地址 -->
<value>hdfs://node1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<!-- 以下为存放节点命名的路径 -->
<value>/export/servers/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!-- 以下为存放数据命名的路径 -->
<value>/export/servers/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<!-- 备份次数,因为有2台DataNode-->
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<!-- Web HDFS-->
<value>true</value>
</property>
</configuration>
修改yarn-site.xml文件,添加下面内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- Master为当前机器名或者ip号 -->
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<!-- Node Manager辅助服务 -->
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<!-- Node Manager辅助服务类 -->
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<!-- CPU个数,需要根据当前计算机的CPU设置-->
<value>1</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<!-- Resource Manager管理地址 -->
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!-- Resource Manager Web地址 -->
<value>node1:8088</value>
</property>
</configuration>
修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<!-- MapReduce Framework -->
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<!-- MapReduce JobHistory, 当前计算机的IP -->
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<!-- MapReduce Web App JobHistory, 当前计算机的IP -->
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/export/servers/hadoop</value>
</property>
</configuration>
修改sbin/start-yarn.sh和sbin/stop-yarn.sh文件,添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改sbin/start-dfs.sh和sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在/export/servers/hadoop/etc/hadoop/workers里删除localhost添加node1 node2 node3
将配置好的文件传递到其他两个节点上
scp -r ./hadoop node2:$PWD
scp -r ./hadoop node3:$PWD
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
分别在node2和node3上执行source /etc/profile
启动hadoop
最后在node1上执行hadoop namenode -format格式化文件系统
执行成功后,在node1执行./sbin/start-all.sh,执行结果如下
[root@node1 hadoop]# ./sbin/start-all.sh
Starting namenodes on [node1]
Last login: Mon Jul 4 00:31:13 PDT 2022 on pts/0
Starting datanodes
Last login: Mon Jul 4 00:32:12 PDT 2022 on pts/0
node2: datanode is running as process 2904. Stop it first.
node3: datanode is running as process 55423. Stop it first.
Starting secondary namenodes [node1]
Last login: Mon Jul 4 00:32:15 PDT 2022 on pts/0
Starting resourcemanager
Last login: Mon Jul 4 00:32:21 PDT 2022 on pts/0
resourcemanager is running as process 5057. Stop it first.
Starting nodemanagers
Last login: Mon Jul 4 00:32:27 PDT 2022 on pts/0
node2: nodemanager is running as process 2999. Stop it first.
node3: nodemanager is running as process 55533. Stop it first.
若出现如下ssh报错,请确认是否已经免密登录了其他服务器,或执行
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
在node1执行jps显示如下
[root@node1 hadoop]# jps
5057 ResourceManager
10804 Jps
10661 NodeManager
9992 DataNode
9775 NameNode
在node2上执行jps
[root@k8s-master1 servers]# jps
2999 NodeManager
2904 DataNode
3678 Jps
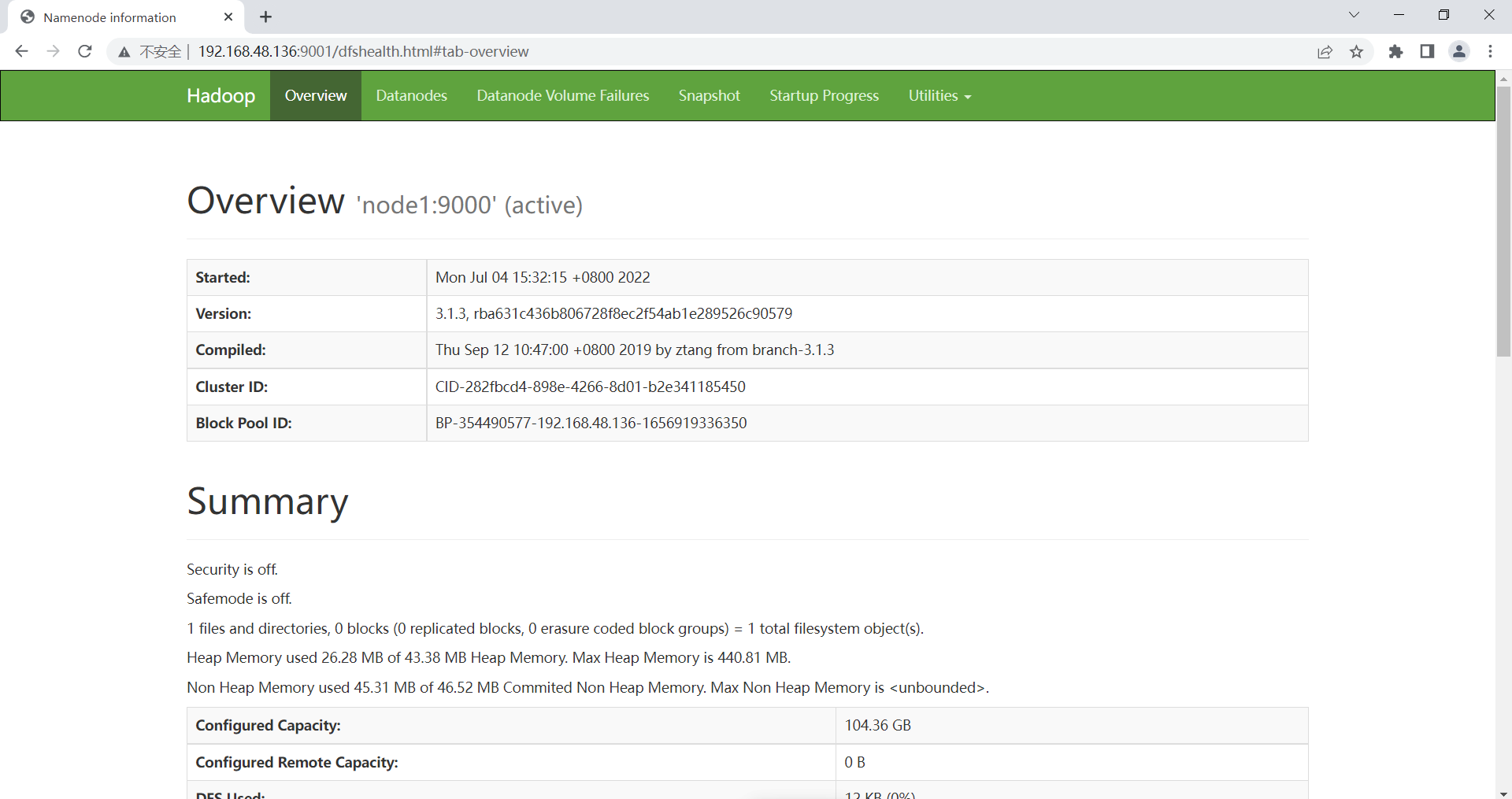
访问http://192.168.48.136:9001显示
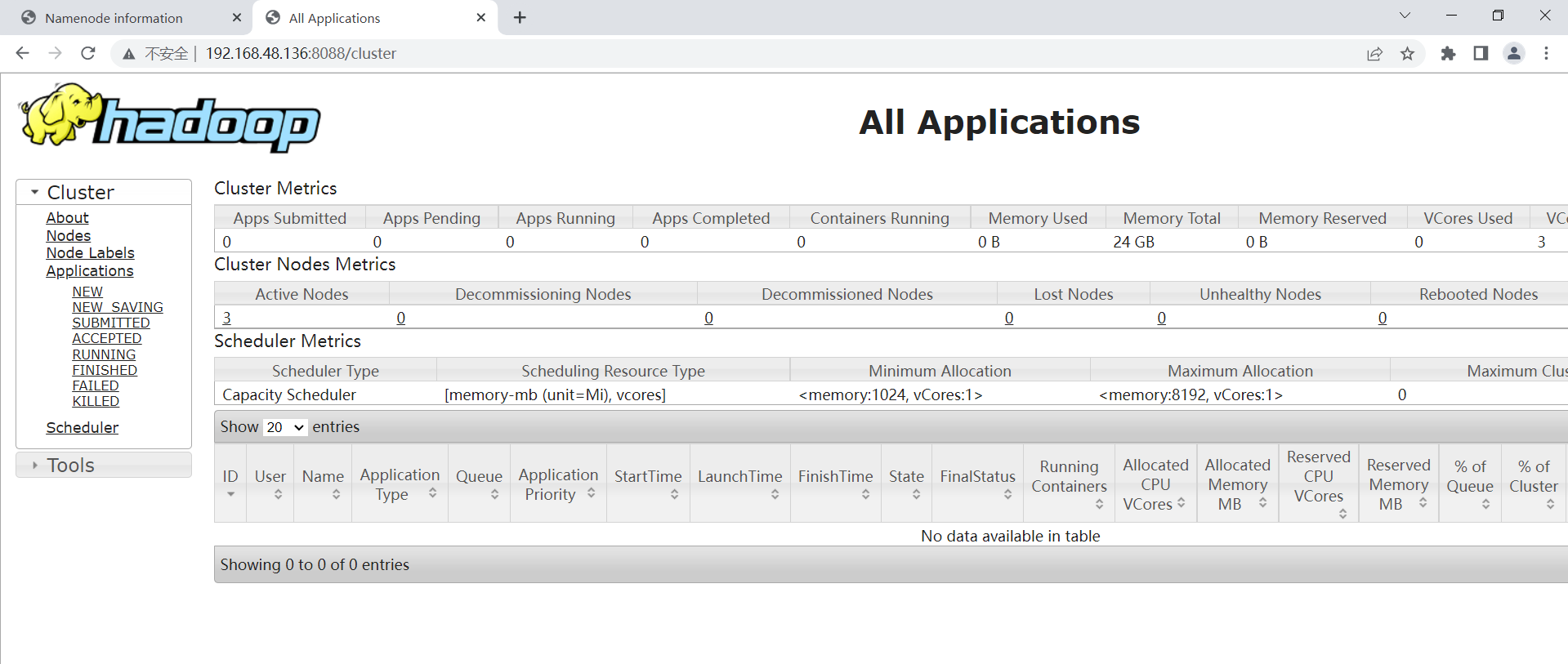
访问http://192.168.48.136:8088/cluster
本文来自博客园,作者:Jerry·,转载请注明原文链接:https://www.cnblogs.com/jerry-0910/p/16443161.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号