数据采集与融合技术第二次作业
作业一
天气数据爬取实验
作业内容
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库
实践过程
-
信息定位
F12查看页面元素后发现,所需信息位于ul下的li标签中
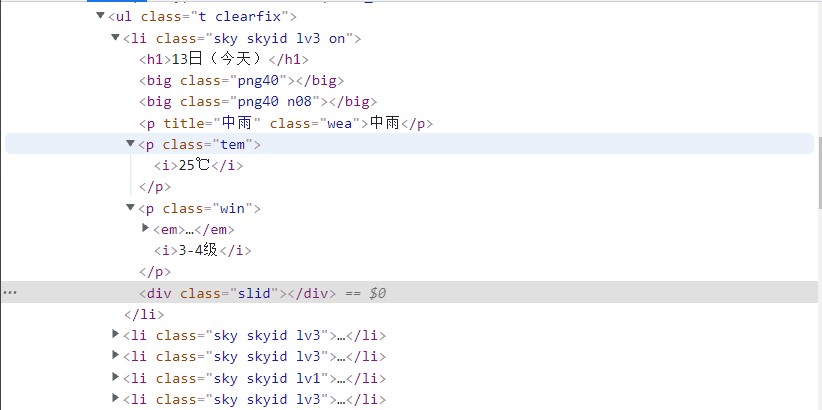
li标签中元素较少,且信息较为简单,所以直接使用li.text获取字符串后,再对每个信息进行截取即可
for li in soup.find('ul', attrs={"class": "t clearfix"}).children: if isinstance(li, element.Tag): winfo = [] info = li.text si = info.split("\n") for i in si: if (i != ""): winfo.append(i) infos.append(winfo) -
数据保存
利用pyodbc库实现对SQL Server数据库的写入操作
def save_to_mytsql(result): # 数据库连接 conn = pyodbc.connect('DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\捷;PWD=29986378;Trusted_Connection=yes') cur = conn.cursor() i=1; # 数据写入 for s in result: sql='insert into weather([地区],[日期], [天气信息],[温度]) values(?,?,?,?)' cur.execute(sql,("福州",s[0],s[1],s[2])) print(s[0]) i+=1 conn.commit() conn.close()
作业结果
-
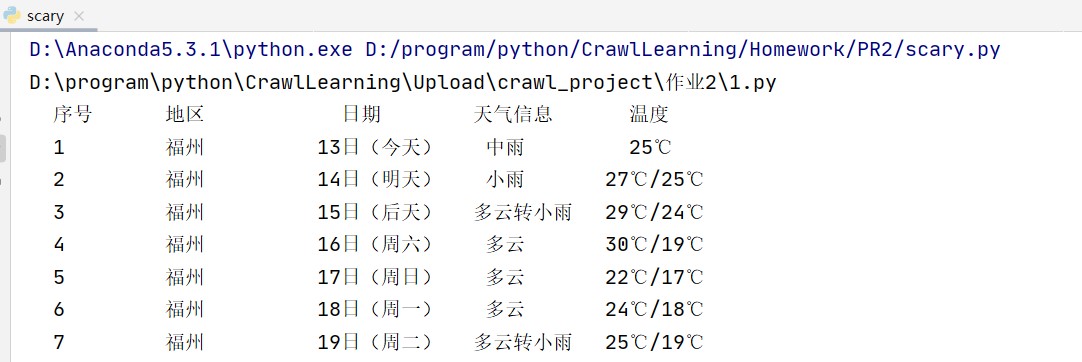
控制台输出:
-
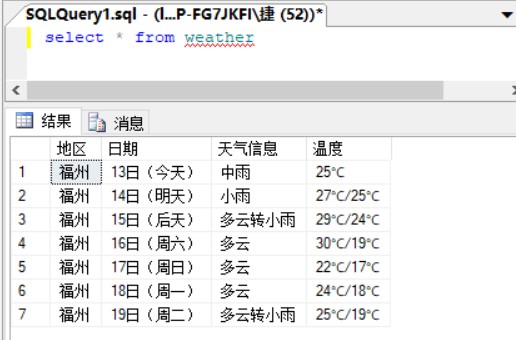
数据库查询:
心得体会
遇到子标签较少的情况,可直接利用text获取所有数据后进行分割得到所需数据。
作业二
股票数据爬取实验
作业内容
用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。东方财富网:https://www.eastmoney.com
实践过程
-
抓包与链接规律寻找
F12网页抓包结果如下:
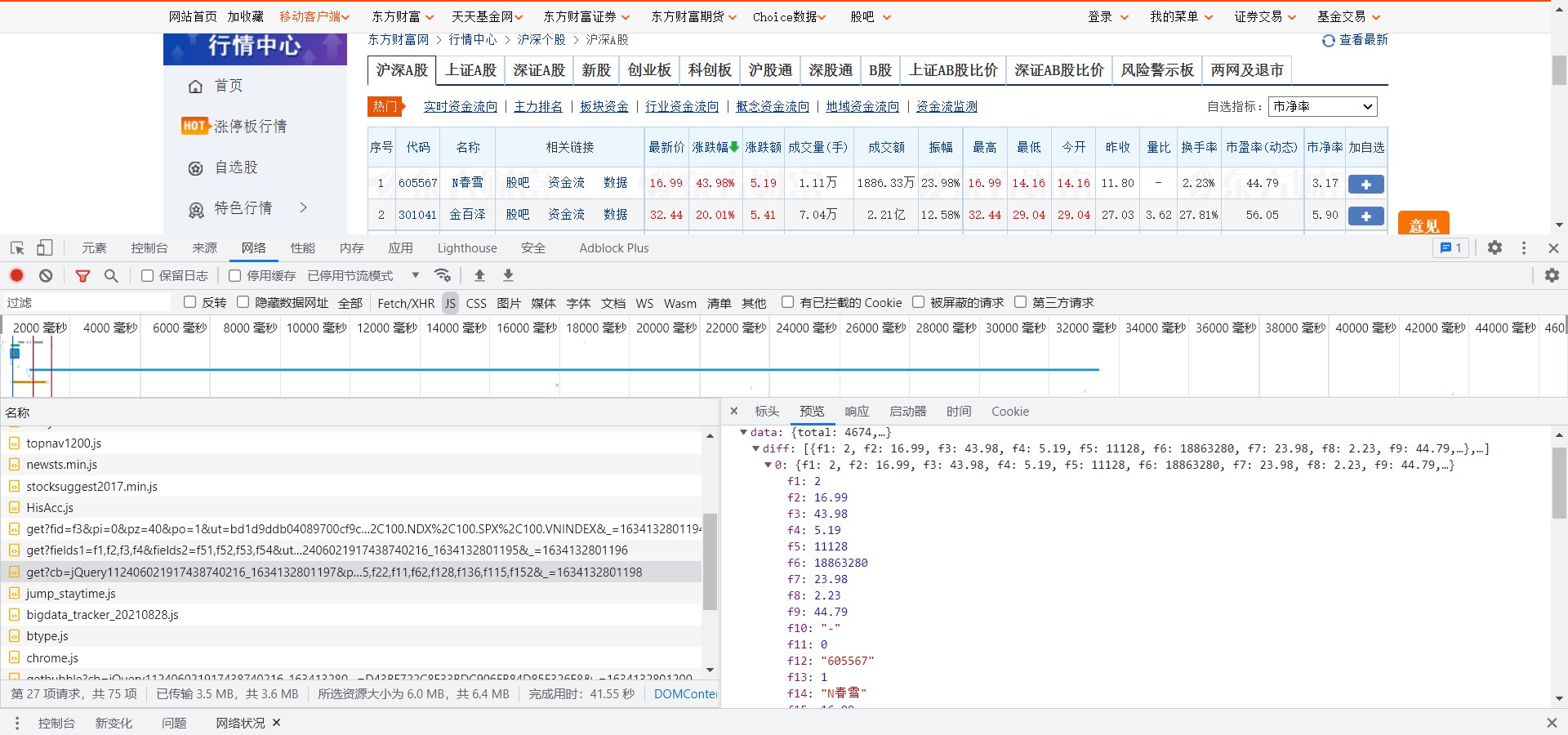
查看请求链接:

翻页抓取不同的包后发现 翻页参数为pn
板块切换可通过传入参数cmd来实现
故请求部分链接代码如下:
cmd = { "上证指数":"C.1", "深圳指数":"C.5", "沪深A股":"C._A", "上证A股":"C.2", "深圳A股":"C._SZAME", "新股":"C.BK05011", "中小板":"C.13", "创业板":"C.80"} url = "http://85.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124007120583477941156_1634089185302&pn="+str(page)+"&cmd="+cmd+"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f11&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152" r = requests.get(url) -
信息爬取与规范化
先将存储股票信息的data部分从字符串中截取出来
pat = '"diff":\[(.*?)\]' data = re.compile(pat,re.S).findall(r.text)再对截取出的信息进行规范化:
-
经过观察可发现,每个{}中存储一支股票的信息,故考虑利用字符串split()方法先将不同股票分开
-
后利用json.load方法将字符串转换为字典形式便于后续数据提取
-
最后可直接通过字典key值找到对应value值
具体实现方法:
data = getHtml(cmd,page) # 每一支股票分开 datas = data[0].split('},') infos = [] for info in datas: if info[-1]!="}": info = info+"}" # 将字符串转换为字典形式 infos.append(json.loads(info)) -
-
信息输出
控制台输出方式与上次实验相似,不具体赘述。
数据库保存,利用pyodbc库实现对SQL Server数据库的写入操作
def save_to_mytsql(result): # 数据库连接 conn = pyodbc.connect('DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\捷;PWD=29986378;Trusted_Connection=yes') cur = conn.cursor() i=1; # 数据写入 for stock in result: sql='insert into stock([代码],[名称],[最新价格],[涨跌幅],[涨跌额],[成交量],[成交额],[振幅],[最高],[最低]) values(?,?,?,?,?,?,?,?,?,?)' cur.execute(sql,(stock[0],stock[1],stock[2],stock[3],stock[4],stock[5],stock[6],stock[7],stock[8],stock[9])) i+=1 conn.commit() conn.close()
作业结果
-
控制台输出
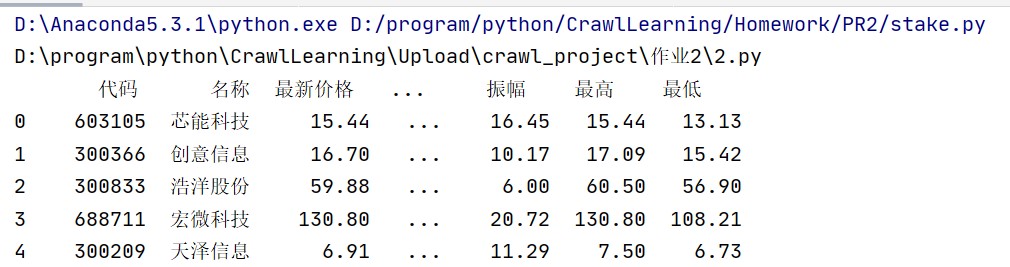
-
数据库查询

心得体会
一次页面刷新会有许多请求,善用筛选器可以帮助我们更快速寻找到需要的包。
字符串转字典方式:利用json.load()。但是该方法存在限制,所有的key值需要用双引号包裹,不然无法正确解析,会报错。
作业三
大学排名爬取实验
作业内容
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
实践过程
-
题目分析与方法选择
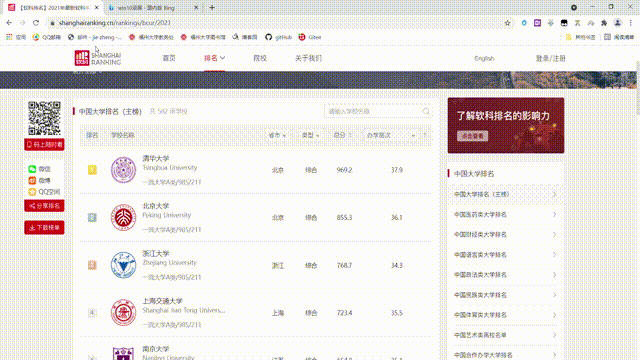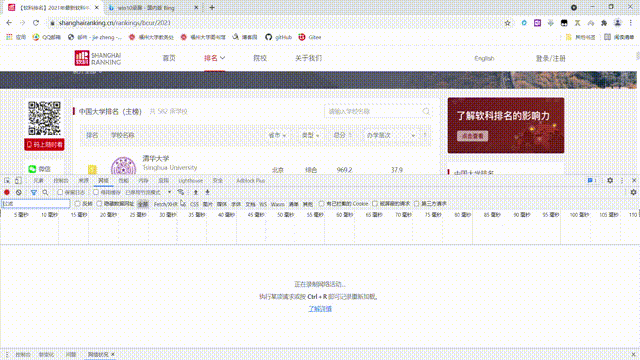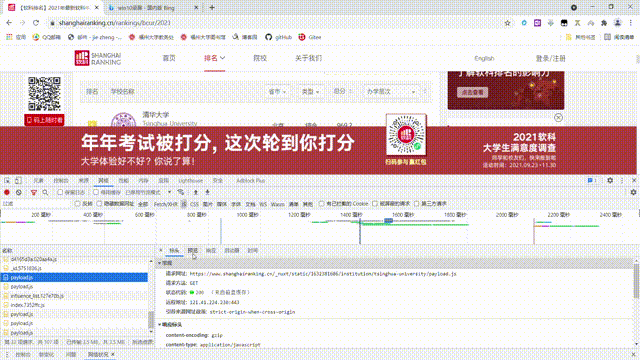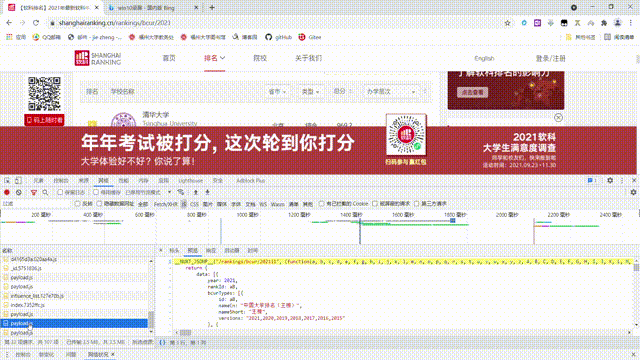
院校排名其实已经爬取多次,但这次与之前几次的不同之处在于这次需要爬取所有院校信息,故使用翻页的方法较为繁琐,所以选择采用直接抓取json包一次性获取所有排名信息。
抓取过程如下:
-
爬取数据规范化处理
由于数据中存在多对大括号,故截取信息的正则表达式为
pat = 'univData:\[(\{.*?\})\]' data = re.compile(pat, re.S).findall(r.text)本题与上一题数据的差别在于,key值未用双引号,故不可直接将字符串转换为字典,所以选择使用re库来获取所需内容。
data = getHtmlByUrlib(url) datas = data[0].split('},') infos =[] for school in datas: name = re.search(r'univNameCn:"(.*?)"',school).group(1) # 获取院校名 score = re.search(r'score:(\d*\.*\d*)',school).group(1) # 获取总分 # 部分院校总分未统计 if score=="": score = '未知' infos.append([name,score])对爬取数据进行观察发现,院校总分存在空值,使用“'未知'对空值进行填充
-
数据输出与保存
数据保存至数据库:
conn = pyodbc.connect('DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\捷;PWD=29986378;Trusted_Connection=yes') cur = conn.cursor() i=1; # 数据写入 for s in result: sql='insert into school([ranknum],[name], [score]) values(?,?,?)' cur.execute(sql,(i,s[0],s[1])) print(s[0]) i+=1 conn.commit() conn.close()
作业结果
-
控制台输出

-
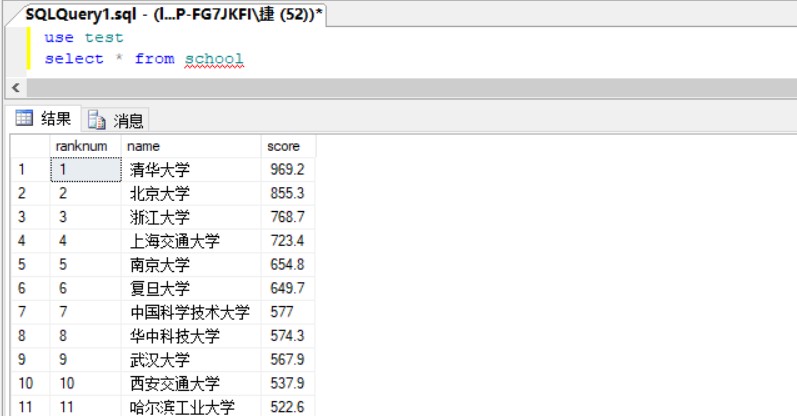
数据库查询
心得体会
本题在刚开始尝试时想沿用第二题的思路,但发现一些问题。一是信息截取部分,由于信息中还存在一组{},直接用问题二会导致信息截取不全,故将表达式修改为匹配[{}]形式;二是本想直接转换为字典,但是却发现key值格式错误,无法正确转换,所以最后还是使用了re进行匹配。
如果一次要爬取全部的数据,直接抓包要比翻页爬取更加方便。

