

Meta的跨时代赌注:字节级Transformer彻底消灭不必要的计算

人工智能的近代历史上,很少有研究敢于挑战现有前沿AI模型的基础。
而Meta正是通过推出字节级Transformer(BLTs),试图解决AI当前最大的问题之一,同时让AI模型的思维方式更加接近人类。
今天,您将更清晰地了解AI,揭示它的局限性,并提供一个直观的解决方案,解决那些曾让硅谷许多人彻夜难眠的问题。或许,您还会了解到Meta下一代模型Llama 4的秘密。
让我们开始吧!
Tokenization争议
虽然我们已经非常擅长训练能够模拟智能的模型(尽管实际上更多是记忆,就像我们之前讨论过的那样),但这些模型在处理数据的方式上仍然非常反直觉。
静态计算问题
并非所有问题都是平等的。由于人类的能量和认知带宽有限,我们会根据问题的重要性调整“思考的努力”。例如,解复杂的数学问题和为宝宝唱摇篮曲显然需要不同程度的脑力投入。
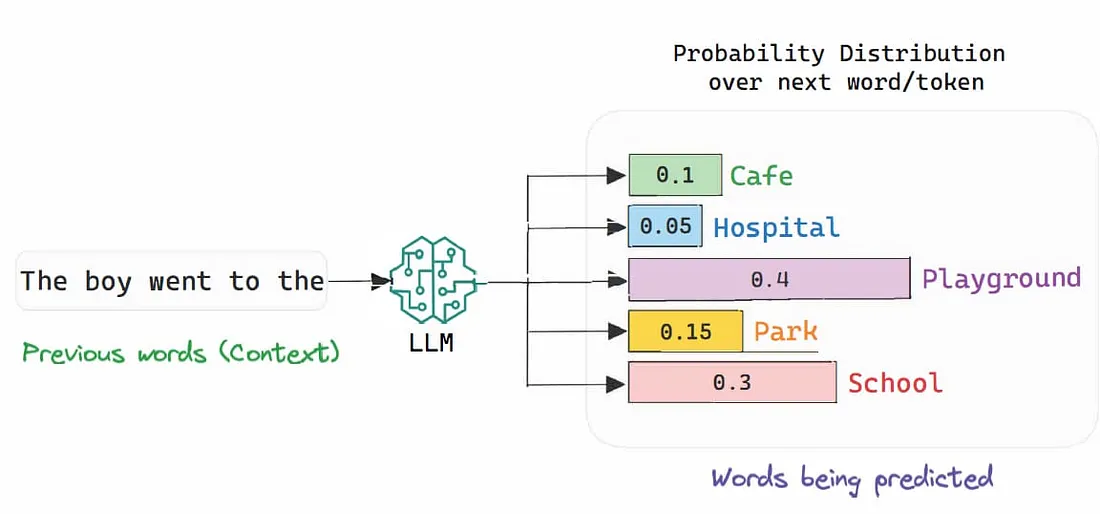
正如您可能知道的,大型语言模型(LLM)和大型推理模型(LRM)通过预测文本序列中的下一个单词来“工作”(例如,“波兰的首都是…”会输出“华沙”,尽管实际过程要复杂一些)。
然而,人类并不会对每个单词投入相同的计算,但当前的模型对每一次预测分配的计算量却完全相同。实际上,运行模型的GPU执行的计算量在每种情况下完全相同(随着文本序列长度的增加,计算需求也会增长,但每次预测的成本与预测任务无关)。
简单来说,模型背后存在大量不必要的计算。而造成这一问题的原因正是所谓的“tokenization”。
Token的重要作用
您可能听说过“token”这个词。在文本处理中,它通常是单词或子单词,也就是模型实际预测的单位;LLM并不预测整个单词,而是预测token,这些token可以是完整单词,也可以不是。
这种tokenization的理念适用于所有数据模态。从文本到视频生成,所有生成式AI模型都会在预处理阶段执行某种形式的tokenization。
但您可能不知道,这些token是在模型训练之前就选定的。一个token词汇表被决定后,模型会基于该词汇表进行训练。当然,更新、更强大的模型往往会拥有更大的词汇表。
在预测时,模型会根据词汇表中的每个token的概率对其进行排名,然后基于它是合理延续的可能性选择下一个token。
然而,tokenization存在两个主要问题:
-
模型“被迫”选择词汇表中的某个token,无论如何。如果序列需要一个从未见过的字母组合(例如一个新单词),那也无能为力。
-
序列被分解为token的方式是固定的,这限制了模型决定哪些部分的序列更值得计算。相反,整个序列被视为同等重要。
但现在,Meta决定彻底抛弃这种方法。取而代之的是,BLTs在字节级处理序列,这带来了惊人的影响。
模型自己决定
虽然在字节级处理序列、以字节为单位切分被认为是难以解决的问题,但Meta找到了方法。如果Meta的意图是个风向标,那么他们的下一代模型Llama 4可能会引发AI领域的真正革命。
Transformer并行化
或许您不知道,当前模型(如ChatGPT)并不是按顺序处理序列,而是所有单词同时处理。在tokenization之后,所有单词会被同时输入模型,模型会执行以下两项操作:
-
混合操作:即注意力机制,它使序列中的单词彼此“对话”,更新每个单词相对于前序单词的“意义”(比如一个形容词会寻找它修饰的名词,更新其“整体意义”,不仅仅是捕捉它作为单词的内在意义,还包括它与名词的关系)。
-
知识嵌入操作:模型利用核心知识为序列添加更多意义。例如,对于序列“Michael Jordan played the game of…”,模型会根据对Michael Jordan的知识判断下一个单词是“basketball”,即使序列本身没有提供任何暗示。
简而言之,前者将每个单词与序列中的其他单词联系起来进行上下文化,而后者使用已有知识为序列增加必要信息。这就是像ChatGPT这样的模型“理解”您说的话的方式。但需要注意的是,这一过程是对序列中的每个token并行完成的。
到这里,您可能已经意识到问题所在:由于tokenization固定了序列如何被分块,无论复杂性如何,整个序列都被一视同仁,每个token都分配了相同的计算资源,包括像“really”或“umm”这样提供价值极小的辅助词也得到了与其他单词同等的处理力度。
这就是BLTs登场的地方。
迈向动态计算
当BLT模型接收到一个序列时,它会将其分解为字节块。这些块的大小是动态的。为了简化理解(详细技术实现涉及一个计算字节熵的辅助模型),模型会评估每个字节的“惊讶程度”。
换句话说,模型会问自己:“根据前面的单词,我看到这个字节有多意外?” 如果答案是“很意外”,模型就会结束前一个块,开始一个新块。这个过程听起来很复杂,但用一个例子就可以说明白。
比如,当开始一个文本序列时,基本上词汇表中的每个字母在某种程度上都是合理的候选字母。这时,熵(即惊讶程度)非常高。
但是,如果模型看到序列“The famous composer from Salzburg known as Moz…” 时,接下来的字母候选很少,因为这个名字已经让人联想到“art”,即Mozart。在这种情况下,预测的难度非常低。
因此,惊讶程度也很低,这意味着模型对接下来的预测非常有信心。它不需要开始一个新块,而是将“art”加入到现有块中,这样整个序列的词就被当作一个整体处理。
正如下面所示,这意味着序列的“块”数量会随着块的大小增加而减少,因为容易预测的单词被分组到一起形成更大的块。
换句话说,虽然tokenization(BPE)是固定地将序列切分成小块(总是相同的方式),而BLT(熵算法)允许更大的块,即使块更大,它们传递的信息量和分解成小块的效果相同。

BPE Tokenization vs Byte Patching
如我们之前讨论的,这种方式非常理想,因为当块变大时,序列的块数量会减少,而这些块又是并行处理的,每块分配的计算量相同。这意味着模型需要处理的块更少,从而大大减少计算量。
核心思想是,我们希望在块的大小和每块的信息位数之间取得最大化。如果我能将两个小块合并为一个,而传递的信息量相同(例如“Mozart”和“Moz”和“art”传递的信息是一样的),我们就可以用更少的成本获得同样的价值。
总之,BLTs在计算资源的使用上要聪明得多,它们把资源用在真正需要的地方。
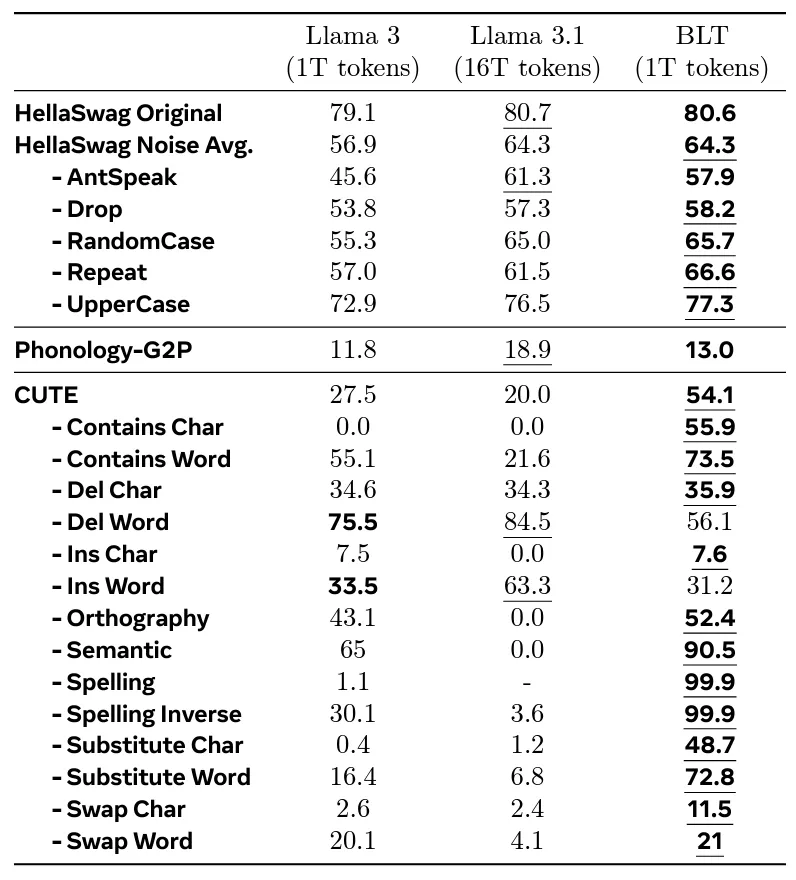
当Meta用与Llama 3相同的训练预算测试BLTs时,他们观察到性能非常相似,而BLT却表现出了大幅度减少的计算成本。令人印象深刻的是,BLT Llama的表现甚至超过了经过16倍更多训练数据的Llama 3.1。
总结思考
总的来说,Meta可能向世界展示了一种更高效计算前沿AI模型的方法,这是行业内梦寐以求的目标。
这些模型在保持或提升性能的同时,计算更高效,这对一个正在努力让产品更具性价比的行业来说,是一个令人震惊的进步。
而且,这种想法完全说得通。
为什么AI不能“决定”每个问题需要分配多少计算资源?难道它们不应该能够在真正重要的时候使用计算资源吗?
这项研究的优点就在于,这不是一个极其晦涩的问题,而是任何人都可以读懂并说“这完全有道理”的内容。
这也是为什么Llama 4(如果这项研究能在预训练之前完成)很可能会成为第一个大规模的BLT模型。而很快,大多数AI实验室都会将这种新的框架作为默认选择。
随着AI通过LLM操作系统(或AI操作系统)可能变得无处不在,强大的AI加速器(如Jetson)逐渐普及到终端消费者,并且大多数前沿AI实验室都在努力让模型变得更小(如微软的Phi-4,以及Meta的字节级Transformer),这个行业似乎正以惊人的速度成熟,从炫技演示转向真正能够提供价值的产品。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号