

人工智能模型学习到的知识是怎样的一种存在?

前一篇:《设计和训练人工智能模型的意义是什么?》
序言:在上一篇文章中,我们通过大型互联网社交平台的一个常规需求场景,举例说明了如何使用人工智能模型来解决常规程序无法解决的应用问题。这让我们明白,人类设计和训练人工智能模型并不是为了“无聊”,也不是出于某些阴谋论而刻意突破人工智能技术,而是为了在实际生产活动中解决计算机程序无法处理的问题,同时帮助人类应对重复性工作。
本节的重点是对前面几个小节的汇总。我们知道,人工智能学习到的知识是一个黑盒。本节我会通过一种可视化的方法来观察人工智能学习的知识。这仅仅是一种观察,并不是说我们理解它学习到了什么。我们还将简单介绍如何将其他项目中学习到的“嵌入”知识重复使用到自己的项目中。
可视化"嵌入"
要可视化嵌入,我们可以使用一个叫做 Embedding Projector 的工具。它自带了很多现有的数据集,但在本节中,你会看到如何从我们刚刚训练的模型中获取数据,并使用这个工具来可视化它。
首先,我们需要一个函数来反转词索引。现在它是以单词作为标记,键作为值,但我们需要把它反过来,这样我们就有了要在投影器上绘制的单词值。下面是实现的方法:
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
我们还需要提取嵌入中向量的权重:
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape)
如果按照本章的优化,这将输出 (2000, 7)——我们使用了 2000 个词汇量,嵌入为 7 维。如果我们想探索某个单词及其向量细节,可以使用这样的代码:
print(reverse_word_index[2])
print(weights[2])
这将产生以下输出:
new
[ 0.8091359 0.54640186 -0.9058702 -0.94764805 -0.8809764 -0.70225513
0.86525863]
所以,单词 “new” 就由这些在各个轴上的七个系数组成的向量表示。
Embedding Projector 使用两个制表符分隔值(TSV)文件,一个用于向量维度,一个用于元数据。以下代码将为你生成它们:
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
如果你在使用 Google Colab,可以用以下代码或从文件面板中下载 TSV 文件:
try:
from google.colab import files
except ImportError:
pass
else:
files.download('vecs.tsv')
files.download('meta.tsv')
一旦有了这些文件,就可以在投影器上按下 Load 按钮来可视化嵌入,如图 6-17 所示。
在生成的对话框中,在推荐的位置使用向量和元数据 TSV 文件,然后在投影器上点击 Sphereize Data。这会让单词聚集在一个球面上,给你一个关于这个分类器二元性质的清晰可视化。它只被训练在讽刺和非讽刺的句子上,所以单词往往聚集在某一个标签上(图 6-18)。
图6-17:使用嵌入投影器
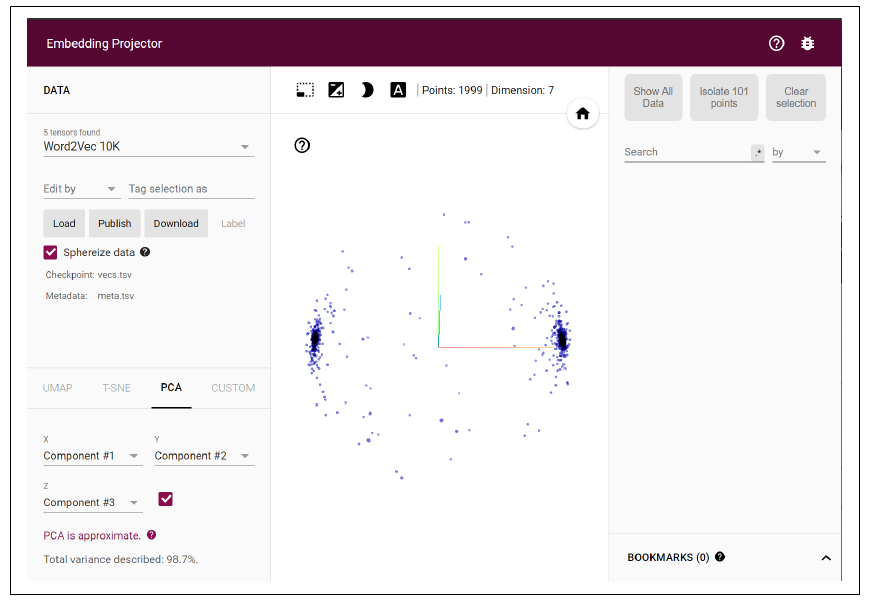
图6-18:可视化讽刺嵌入
光看截图可不行,你得自己亲自试试才知道!你可以旋转中心的球体,探索每个“极”上的词,看看它们对整体分类有啥影响。你还可以选择词语,在右边的面板显示相关的词。玩一玩,试试看吧。
使用 TensorFlow Hub 的预训练嵌入
除了自己训练嵌入外,还有个办法就是用已经预训练好的嵌入,它们被打包成了 Keras 层供你使用。在 TensorFlow Hub 上有很多这样的资源可以探索。需要注意的是,它们还可能帮你处理分词的逻辑,所以你不用像之前那样自己搞定分词、序列化和填充了。
TensorFlow Hub 在 Google Colab 上已经预装好了,所以本节的代码可以直接用。如果你想在自己的机器上安装它作为依赖项,需要按照指示安装最新版本。
举个例子,对于讽刺数据,不用再处理分词、词汇管理、序列化、填充啥的逻辑了,一旦你有了完整的句子和标签集,你可以这么做。首先,把它们分成训练集和测试集:
training_size = 24000
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
有了这些之后,你可以这样从 TensorFlow Hub 下载一个预训练的层:
import tensorflow_hub as hub
hub_layer = hub.KerasLayer(
"https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1",
output_shape=[20], input_shape=[],
dtype=tf.string, trainable=False
)
这个层用了 Swivel 数据集的嵌入,训练于 130GB 的 Google 新闻。使用这个层会对你的句子进行编码,分词,用 Swivel 学到的词嵌入,然后把你的句子编码成一个单一的嵌入。最后这一点值得记住。我们到目前为止用的技术是直接用词编码,基于所有的词来分类内容。用这样的层,你得到的是整句话被聚合成一个新的编码。
然后,你可以用这个层来创建模型架构,替代之前的嵌入层。下面是一个使用它的简单模型:
model = tf.keras.Sequential([
hub_layer,
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.0001, beta_1=0.9,
beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy', optimizer=adam,
metrics=['accuracy'])
这个模型在训练中会迅速达到最高准确率,而且不会像我们之前看到的那样过拟合。50 个 epoch 的准确率显示,训练和验证非常同步(图 6-19)。
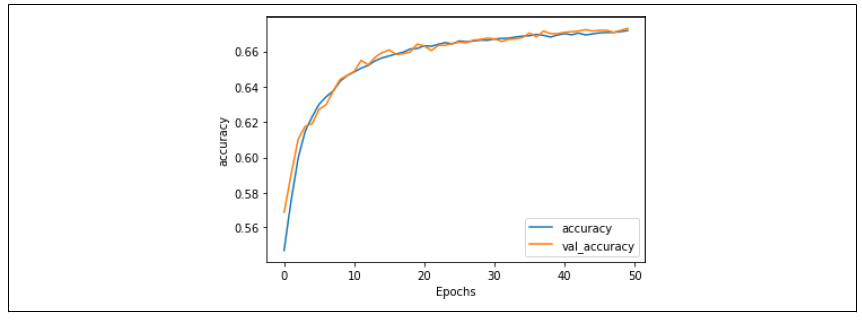
图 6-19:使用 Swivel 嵌入的准确率指标
损失值也同样同步,表明我们拟合得非常好(图 6-20)。
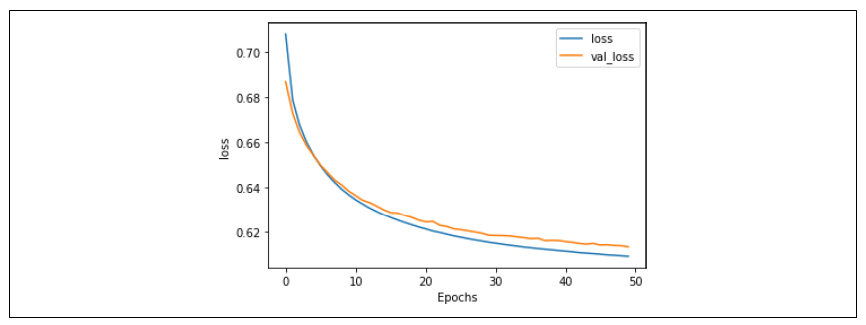
图 6-20:使用 Swivel 嵌入的损失指标
不过值得注意的是,总体准确率(大约 67%)还是挺低的,毕竟掷个硬币都有 50% 的概率猜对!这是因为把所有基于词的嵌入编码成了一个基于句子的嵌入——在讽刺性标题的情况下,似乎个别词对分类有很大的影响(见图 6-18)。所以,虽然使用预训练的嵌入可以让训练更快、过拟合更少,但你也应该明白它们的用处,它们可能并不总是最适合你的场景。
总结
在本章中,你构建了你的第一个模型来理解文本中的情感。它通过将第 5 章中的标记化文本映射到向量来实现。然后,使用反向传播,它根据包含它的句子的标签来学习每个向量的适当“方向”。最后,它能够使用一组词的所有向量来建立句子中情感的概念。你还探索了优化模型以避免过拟合的方法,并看到了表示你词语的最终向量的一个漂亮的可视化。
虽然这是一个不错的句子分类方法,但它只是把每个句子当作一堆词来处理。没有涉及固有的序列,而词语出现的顺序对于确定句子的真实含义非常重要,所以考虑序列来改进我们的模型是个好主意。我们将在下一章引入一种新的层类型——循环层,这是循环神经网络的基础。你还会看到另一个预训练的嵌入,叫做 GloVe,它允许你在迁移学习的场景中使用基于词的嵌入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号