

两个节点swarm实现方案总结
以下是两个节点 Docker Swarm 集群从搭建到精通的完整指南,包含详细步骤、原理说明和实战技巧:
一、双节点 Swarm 架构图解
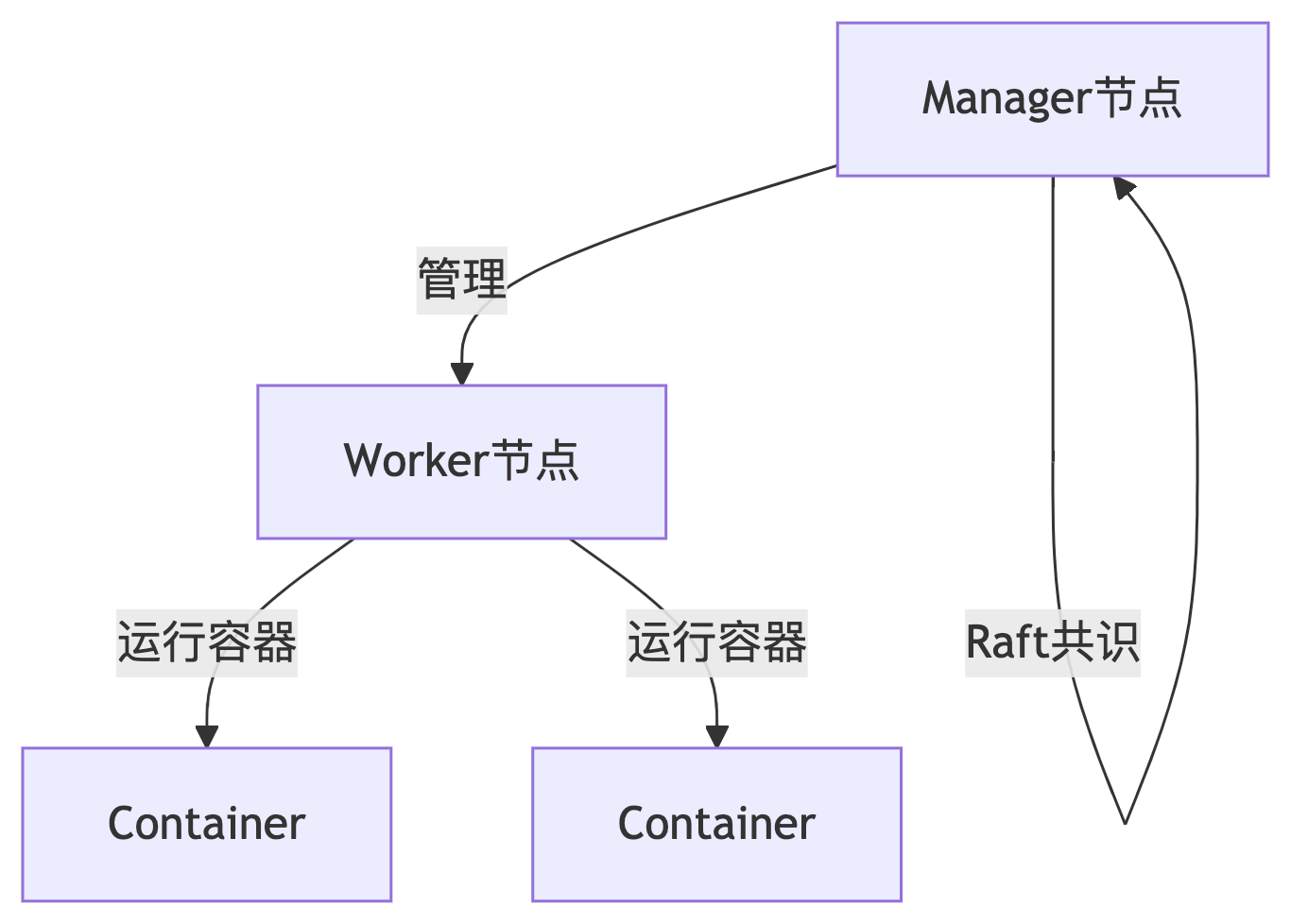
二、环境准备(两个节点)
1. 节点要求
| 节点类型 | 配置要求 | 推荐规格 |
|---|---|---|
| Manager | 固定IP,开放2377/7946/4789端口 | 2核CPU/4GB内存 |
| Worker | 能访问Manager节点 | 2核CPU/4GB内存 |
2. 初始化前检查
# 在两个节点执行:
docker --version # 需 ≥ 20.10
sudo systemctl enable docker
sudo ufw allow 2377/tcp # 开放Swarm端口
三、详细搭建步骤
1. Manager节点初始化
# 在Manager节点执行(替换为实际内网IP)
docker swarm init --advertise-addr 192.168.1.100
# 成功输出示例:
Swarm initialized: current node (dxn1) is now a manager.
To add a worker to this swarm, run:
docker swarm join --token SWMTKN-1-xxx 192.168.1.100:2377
2. Worker节点加入集群
# 在Worker节点执行Manager返回的命令
docker swarm join --token SWMTKN-1-xxx 192.168.1.100:2377
# 成功输出:
This node joined a swarm as a worker.
3. 验证集群状态
# 在Manager节点执行
docker node ls
# 正常输出示例:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
dxn1* manager1 Ready Active Leader
jbn2 worker1 Ready Active
四、双节点服务部署实战
1. 部署跨节点服务
# 在Manager节点执行
docker service create \
--name web \
--replicas 4 \
--publish published=8080,target=80 \
--constraint 'node.role==worker' \ # 限制只在Worker运行
nginx:alpine
2. 查看服务分布
docker service ps web
# 输出示例(应分布在两个节点):
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE
a1b2 web.1 nginx:alpine worker1 Running Running 1m
c3d4 web.2 nginx:alpine manager1 Running Running 1m
...
3. 测试故障转移
# 模拟Worker节点宕机
docker node update --availability drain worker1
# 观察容器自动迁移
watch docker service ps web # 所有容器应迁移到Manager
五、双节点网络配置
1. 创建Overlay网络
docker network create -d overlay \
--subnet 10.1.0.0/24 \
--gateway 10.1.0.1 \
mynet
2. 部署互联服务
# 数据库服务(仅Worker)
docker service create \
--name db \
--network mynet \
--constraint 'node.role==worker' \
-e MYSQL_ROOT_PASSWORD=secret \
mysql:8.0
# Web服务(连接数据库)
docker service create \
--name app \
--network mynet \
-e DB_HOST=db \
--publish 8000:8000 \
my-app:latest
六、双节点高可用策略
1. 提升Worker为Manager(推荐)
# 在Manager节点执行
docker node promote worker1
# 验证
docker node ls # worker1的MANAGER STATUS应显示Reachable
2. Raft共识机制验证

测试Leader故障:
# 停止Manager1的Docker服务
sudo systemctl stop docker
# 在Manager2验证
docker node ls # Manager2应自动成为Leader
七、数据持久化方案
1. 共享存储方案(NFS)
# 在两节点安装NFS客户端
sudo apt install nfs-common
# 挂载共享卷
sudo mount -t nfs NAS_IP:/data /mnt/shared
# 使用绑定挂载
docker service create \
--name fileserver \
--mount type=bind,source=/mnt/shared,target=/data \
nginx:alpine
2. 节点标签定向存储
# 给Worker添加标签
docker node update --label-add storage=ssd worker1
# 部署时指定标签
docker service create \
--name cache \
--constraint 'node.labels.storage==ssd' \
--mount type=volume,source=cache_data,target=/data \
redis:alpine
八、监控与日志
1. 部署监控栈
# 在Manager节点执行
docker service create \
--name prometheus \
--publish 9090:9090 \
--mount type=bind,source=/path/to/prometheus.yml,target=/etc/prometheus/prometheus.yml \
prom/prometheus
docker service create \
--name grafana \
--publish 3000:3000 \
grafana/grafana
2. 日志收集配置
docker service create \
--name logspout \
--mode global \
--mount type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock \
gliderlabs/logspout \
syslog://LOG_SERVER_IP:514
九、故障排查指南
1. 节点失联排查
# 检查节点状态
docker node inspect worker1 --pretty
# 检查网络连通性
docker exec -it <container> ping worker1
# 查看Swarm日志
journalctl -u docker -f | grep swarm
2. 服务部署失败
# 查看失败详情
docker service ps --no-trunc web
# 检查资源限制
docker node inspect self --format '{{ .Description.Resources }}'
十、升级为生产环境
1. 安全加固措施
# 启用TLS加密
docker swarm init --advertise-addr 192.168.1.100 --cert-expiry 720h
# 限制管理端口访问
sudo ufw allow from 192.168.1.0/24 to any port 2377
2. 备份与恢复
# 备份Swarm配置
docker swarm ca --rotate # 更新CA证书
tar czvf swarm-backup.tar.gz /var/lib/docker/swarm
# 灾难恢复
docker swarm init --force-new-cluster
通过以上步骤,您可以在两个节点上构建具备基础高可用能力的Swarm集群。关键要点:
-
通过
docker node promote实现双Manager高可用 -
使用
constraints控制服务分布 -
共享存储解决数据持久化问题
-
监控和日志系统必不可少
实际生产环境中建议至少使用3个Manager节点,但双节点架构已能满足大多数开发和测试场景需求。
郭慕荣博客园

 浙公网安备 33010602011771号
浙公网安备 33010602011771号