python-python基础9
本章内容:
- paramiko模块
- 多线程threading
- 守护线程
- 线程锁
- 信号量
- 事件
- 队列queue
一、paramiko模块(第三方模块,需要另外安装)
该模块基于SSH用于连接远程服务器并执行相关操作
SSHClient
用于连接远程服务器并执行基本命令
import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='192.168.242.132', port=22, username='root', password='225325') # 执行命令,返回三个结果,stdin:标准输入,stdout:标准输出 或 stderr:标准错误 stdin, stdout, stderr = ssh.exec_command('df') #标准输出和标准错误只会有一个有结果 res,err=stdout.read(),stderr.read() # 获取命令结果 if res: result=res else: result=err print(result.decode()) # 关闭连接 ssh.close()
SFTPClient
用于连接远程服务器并执行上传下载
基于用户名密码上传下载
import paramiko transport = paramiko.Transport(('192.168.242.129', 22)) transport.connect(username='root', password='225325') sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py #sftp.put('test.py', '/tmp/test_from_win') # 将remove_path 下载到本地 local_path sftp.get('/tmp/bs.yaml', 'fromlinux.txt') transport.close()
二。进程与线程
什么是进程(process)?
程序的执行实例称为进程。
每个过程都提供执行程序所需的资源。 进程具有虚拟地址空间,可执行代码,系统对象的打开句柄,安全上下文,唯一的进程标识符,环境变量,优先级类别,最小和最大工作集大小以及至少一个执行线程。 每个进程都从单个线程(通常称为主线程)开始,但是可以从其任何线程中创建其他线程。
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
例如,我们在使用qq聊天, qq做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听其它人给你发的消息、同时还能把别人发的消息显示在屏幕上呢?你会说,操作系统不是有分时么?但我的亲,分时是指在不同进程间的分时呀, 即操作系统处理一会你的qq任务,又切换到word文档任务上了,每个cpu时间片分给你的qq程序时,你的qq还是只能同时干一件事呀。
再直白一点, 一个操作系统就像是一个工厂,工厂里面有很多个生产车间,不同的车间生产不同的产品,每个车间就相当于一个进程,且你的工厂又穷,供电不足,同一时间只能给一个车间供电,为了能让所有车间都能同时生产,你的工厂的电工只能给不同的车间分时供电,但是轮到你的qq车间时,发现只有一个干活的工人,结果生产效率极低,为了解决这个问题,应该怎么办呢?。。。。没错,你肯定想到了,就是多加几个工人,让几个人工人并行工作,这每个工人,就是线程!
什么是线程(thread)?
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
线程是执行上下文,它是CPU执行指令流所需的所有信息。
CPU给您一种错觉,即它同时进行多个计算。它通过在每次计算上花费一些时间来做到这一点。之所以可以这样做,是因为它具有每次计算的执行上下文。就像您可以与朋友共享一本书一样,许多任务可以共享一个CPU。
从技术上讲,执行上下文(因此是线程)由CPU寄存器的值组成。
最后:线程与进程不同。线程是执行的上下文,而进程是与计算相关联的一堆资源。一个进程可以具有一个或多个线程。
澄清:与进程关联的资源包括内存页(进程中的所有线程都具有相同的内存视图),文件描述符(例如,打开的套接字)和安全凭证(例如,启动进程的用户的ID)处理)。
进程与线程的区别
- 线程共享创建它的进程的地址空间; 进程具有自己的地址空间。
- 线程可以直接访问其进程的数据段。 进程具有其父流程数据段的副本。
- 线程可以直接与其进程中的其他线程通信。 进程必须使用进程间通信与同级进程进行通信。
- 新线程很容易创建; 新进程需要复制父进程。
- 线程可以对同一进程的线程进行相当多的控制。 进程只能控制子进程。
- 主线程的更改(取消,优先级更改等)可能会影响该进程其他线程的行为; 对父进程的更改不会影响子进程。
简单的多线程示例:
import threading,time def run(n): print("task",n) time.sleep(2) t1=threading.Thread(target=run,args=("t1",)) t2=threading.Thread(target=run,args=("t2",)) t1.start() t2.start()
用多线程并行执行run这个任务的时候,可以同时打印出"task t1"和"task t2",而不需要打印出"task t1"后等两秒后在执行run(t2)
继承式调用:
import threading,time class MyThread(threading.Thread): def __init__(self,n): super(MyThread,self).__init__() self.n=n def run(self): #定义每个线程要运行的函数,函数名不能改 print("running ",self.n) t1=MyThread("t1") t2=MyThread("t2") t1.start() t2.start()
计算多个线程全部执行完所耗费的时间:
import threading,time def run(n): print("task",n) time.sleep(2) start_time=time.time() t_obj=[] for i in range(50): #用循环的方式一次启动50个线程 t=threading.Thread(target=run,args=("t---%s"%i,)) t.start() t_obj.append(t) print("线程全部启动") for r in t_obj: r.join() #join的意思是等待线程的执行结果后再往下执行 print("全部线程执行完所耗费的时间:",time.time()-start_time)
执行这个python文件是一个主线程,在这个主线程中生成50个子线程,它们都是独立运行,互不影响的,也就是说,每个线程启动后,不会等这个线程执行完毕才开始执行下一个进程。所以把每个线程启动后,加进t_obj列表中,同时把这个列表中的每个线程实例join(),这样就可以让50个线程都执行完后,最后执行主线程的print(),计算时间。
threading.current_thread() : 查看当前运行这条命令的线程类型(主线程或子线程)
threading.active_count() : 查看当前线程个数
守护线程:
import threading import time def run(n): print("task",n) time.sleep(2) start_time=time.time() t_obj=[] for i in range(50): #用循环的方式一次启动50个线程 t=threading.Thread(target=run,args=("t---%s"%i,)) t.setDaemon(True) #把当前线程设置为守护线程 t.start() t_obj.append(t) print("线程全部启动") #for r in t_obj: # r.join() #join的意思是等待线程的执行结果 print("全部线程执行完所耗费的时间:",time.time()-start_time)
把50个子线程都设置为守护线程后,只要主线程执行完退出,不管守护线程有没有执行完,都会跟着退出
Python GIL(Global Interpreter Lock)
在CPython中,全局解释器锁(即GIL)是一个互斥体,可以防止多个本机线程一次执行Python字节码。 锁定是必要的,主要是因为CPython的内存管理不是线程安全的。 (但是,由于存在GIL,因此其他功能也逐渐依赖于它所执行的保证。)无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行
python多线程不适合cpu密集型任务,只适合IO密集型任务。
因为python的多线程是假的多线程,即同一时间只能在一颗cpu上以上下文切换的方式来执行任务,如果是cpu密集型任务,需要大量的cpu运算时间,而python多线程的上下文切换也会耗费很多cpu时间,所以cpu密集型任务还不如用单线程。
那cpu密集型任务该如何解决呢?可以用多进程的方式,下一章讲。
线程锁(互斥锁Mutex)
一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果多个线程同时要修改同一份数据,可能会有问题。
例:2个线程同时修改sum这个变量
import threading sum = 0 loopSum = 1000000 def myAdd(): global sum,loopSum for i in range(loopSum): sum +=1 def myMinu(): global sum,loopSum for i in range(loopSum): sum-=1 if __name__ == '__main__': print("Starting.The sum is {0}".format(sum)) #开始多线程实例 t1=threading.Thread(target=myAdd,args=()) t2=threading.Thread(target=myMinu,args=()) t1.start() t2.start() t1.join() t2.join() print("Done.The sum is {0}.".format(sum))

原因是,当一个线程在修改一个变量时,比如sum+1,还没修改完,但是时间到了,被要求释放GIL,那么另外一个线程进来修改这个变量比如sum-1,修改完成写进内存,此时sum=-1,然后刚刚没执行完的线程sum+1继续执行,执行完后把结果存进变量,此时sum=1,但是这个结果是一个错误的结果,因为两个线程都执行完的话sum应该等于0.
为了避免这种情况出现,我们应该在每个线程修改变量之前加一个线程锁,当这个线程修改这个变量的时候,其它线程不能操作这个变量,当那个线程修改完成,释放锁以后,另一个线程才能继续操作这个变量。看一个加锁的示例:
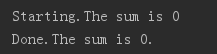
import threading sum = 0 loopSum = 100000 def myAdd(): global sum,loopSum for i in range(loopSum): lock.acquire() #申请锁 sum +=1 lock.release() #释放锁 def myMinu(): global sum,loopSum for i in range(loopSum): lock.acquire() sum-=1 lock.release() lock=threading.Lock() #生成一个线程锁实例 if __name__ == '__main__': print("Starting.The sum is {0}".format(sum)) #开始多线程实例 t1=threading.Thread(target=myAdd,args=()) t2=threading.Thread(target=myMinu,args=()) t1.start() t2.start() t1.join() t2.join() print("Done.The sum is {0}.".format(sum))
Semaphore(信号量)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据
import threading,time def run(n): semaphore.acquire() print("run the thread:%s\n" %n) time.sleep(1) semaphore.release() semaphore=threading.BoundedSemaphore(3) #生成一个信号量实例,最多允许3个线程同时执行 for i in range(10): t=threading.Thread(target=run,args=(i,)) t.start() while threading.active_count()!=1: pass else: print("线程执行完毕")
Events(事件)
事件是一个简单的同步对象。
该事件表示一个内部标志,并且线程
可以等待设置标志,或者自己设置或清除标志。
event= threading.Event()
#客户端线程可以等待标志设置
event.wait()
#服务器线程可以设置或重置它
event.set()
event.clear()
如果设置了该标志,则wait方法不会执行任何操作。
如果该标志被清除,则等待将阻塞,直到再次设置。
任何数量的线程都可以等待同一事件。
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。
import threading,time event=threading.Event() def Light(): count=1 event.set() #绿灯 while True: if count>5 and count<=10: event.clear() #清空标志位,红灯 print("\033[41;1m红灯亮\033[0m") elif count>10: event.set() print("\033[36;42;1m绿灯亮\033[0m") count=1 else: print("\033[36;42;1m绿灯亮\033[0m") count+=1 time.sleep(1) def car(name): while True: if event.is_set(): print("绿灯,%s开车"%name) time.sleep(1) else: print("红灯,%s停车"%name) event.wait() #等待标志位被设定 print("绿灯亮了,开车") light=threading.Thread(target=Light) light.start() car1=threading.Thread(target=car,args=("马自达",)) car1.start() car2=threading.Thread(target=car,args=("奥迪",)) car2.start()
不用event实现:
import threading,time def Light(): count=1 global redlight redlight = True while True: if count>5 and count<=10: print("\033[36;42;1m绿灯亮\033[0m") redlight = False elif count>10: print("\033[41;1m红灯亮\033[0m") redlight = True count=0 else: print("\033[41;1m红灯亮\033[0m") redlight = True count+=1 time.sleep(1) def car(name): while True: if redlight is True: print("红灯,停车") time.sleep(1) else: print("绿灯,开车") time.sleep(1) light=threading.Thread(target=Light) light.start() car1=threading.Thread(target=car,args=("car1",)) car1.start()
queue队列
主要作用
解耦,使程序实现松耦合(一个模块修改不会影响其他模块)
提高效率
队列与列表的关系
队列中数据只有一份,取出就没有了,区别于列表,列表数据取出只是复制了一份
当必须在多个线程之间安全地交换信息时,队列在线程编程中特别有用。
queue.Queue(maxsize=0) #先入先出
queue.LifoQueue(maxsize=0) #后入先出queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
优先级队列示例:
import queue q=queue.PriorityQueue(maxsize=10) #用优先级队列的方式创建队列,传一个元组进队列里,队列会根据元组中第一个数字来排序 q.put((36,"zhihao")) q.put((7,"zhang")) q.put((5,"zzh")) q.put((55,"xiaodu")) q.put((1,"jehu")) print(q.get()) print(q.get()) print(q.get()) print(q.get()) print(q.get())
执行结果:
(1, 'jehu') (5, 'zzh') (7, 'zhang') (36, 'zhihao') (55, 'xiaodu')
优先级队列的构造函数。 maxsize是一个整数,用于设置可以放入队列中的项目数的上限。 一旦达到此大小,插入将被阻塞,直到消耗队列项目。 如果maxsize小于或等于零,则队列大小为无限。
Queue.qsize()
Queue.empty() #return True if empty
Queue.full() # return True if full
Queue.put(item, block=True, timeout=None)
maxsize
maxsize 是实例化 Queue 类时的一个参数,默认为 0
Queue(maxsize=0) 可以控制队列中数据的容量
put
Queue.put(block=True, timeout=None)
block 用于设置是否阻塞, timeout 用于设置阻塞时等待时长
put_nowait() = put(block=False)
阻塞
当队列满了之后,put 就会阻塞,一直等待队列不再满时向里面添加数据
不阻塞
当队列满了之后,如果设置 put 不阻塞,或者等待时长到了之后会报错:queue.Full
get
Queue.get(block=True, timeout=None)
get_nowait() = get(block=False)
阻塞
当队列空了之后,get 就会阻塞,一直等待队列中有数据后再获取数据
不阻塞
当队列空了之后,如果设置 get 不阻塞,或者等待时长到了之后会报错:_queue.Empty
full & empty
Queue.empty()/Queue.full() 用于判断队列是否为空、满
尽量使用 qsize 代替
qsize
Queue.qsize() 用于获取队列中大致的数据量
注意:在多线程的情况下不可靠
因为在获取 qsize 时,其他线程可能又对队列进行操作了
生产者消费者模型:
import threading,time,queue q=queue.Queue(maxsize=10) def Produce(): count=1 while True: q.put("[apple%s]"%count) print("生产[apple%s]"%count) count+=1 time.sleep(1) def consumer(name): while True: a=q.get() print("%s 吃了%s"%(name,a)) time.sleep(1) p1=threading.Thread(target=Produce) p1.start() c1=threading.Thread(target=consumer,args=("zzh",)) c1.start() c2=threading.Thread(target=consumer,args=("jehu",)) c2.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号