【Python应用】爬取有道API,自制工具(Python爬虫:反爬破解)
有道翻译官网:http://fanyi.youdao.com/
打开网页,F12找到translate这个XHR文件中存在主要信息,找到最后的From Data(数据的来源,如何获取的,最后调用翻译)
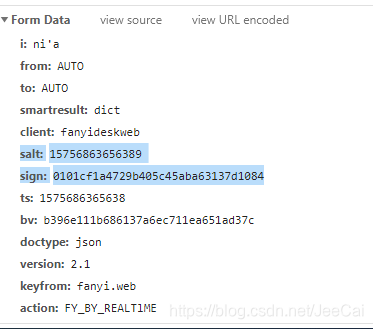
对于这两组数据,不知道是什么?(虽然bv也不知道是什么,不过好像对项目没有直接的影响)看到sign可能是一个十六进制的数据,通过找到fanyi.min.js(别问我怎么知道是这个文件,一个个JS文件打开来自己慢慢看,有没有自己想要的)
将JS文件用在线json网站:https://www.json.cn/解析出来,搜索salt,找到
salt:I,sign:n.md5(“fanyideskweb"+e+i+"n%A-rKaT5fb[Gy?;N5@Tj” ”)
n%A-rKaT5fb[Gy?;N5@Tj
这个是有道翻译内部的识别码,也无需破解,直接模仿浏览器访问就好

使用print(res.json())获取到网页返回的json值,我们需要的数据在translateResult这个字典的键值对中的‘tgt’里,然而这个是有三层的,所以前面保存空位,用[0][0]存空位,最后打印出来。
print(res.json()['translateResult'][0][0]['tgt'])
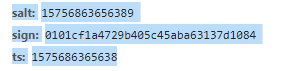
salt和ts只是后面一个数字不同,而ts是时间,和time.time()*1000返回的值一直,所以salt是时间加上一个随机数。
fanyi.min.js文件中搜索salt可知

获取到的后台json文件http://shared.ydstatic.com/fanyi/newweb/v1.0.22/scripts/newweb/fanyi.min.js
方便测试,全部代码下载:
一键三连呀!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号