
总结网站Mysql优化
Mysql存储引擎
选择合适的存储引擎Innodb myisam
myisam: 写入数据非常快,适合使用场合dedecms/phpcms/discuz/微博系统等写入、读取操作多的系统。
innodb: 适合业务逻辑比较强的系统,修改操作较多的,例如ecshop、crm、办公系统、商城系统。mysql5.5以上默认的存储引擎
mysql索引
添加索引
1.添加PRIMARY KEY(主键索引)
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.添加UNIQUE(唯一索引)
mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` )
3.添加INDEX(普通索引)
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.添加FULLTEXT(全文索引)
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.添加复合索引
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
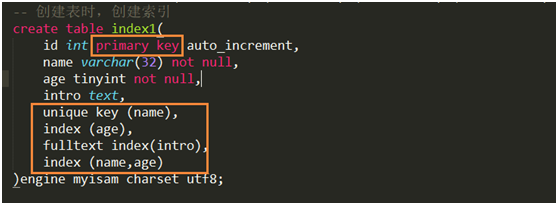

删除索引
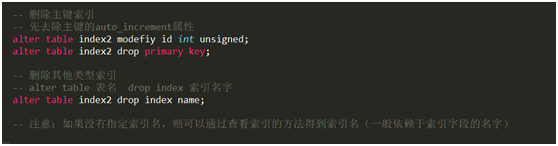
查看索引

创建索引注意事项

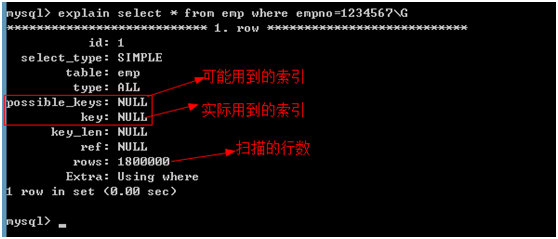
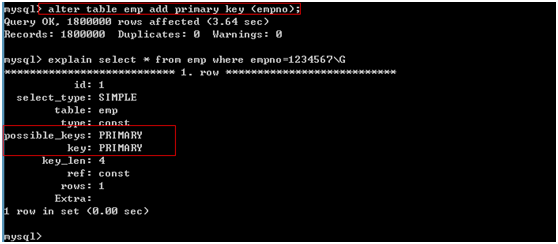
执行计划
主要用于分析sql语句的执行情况(并不执行sql语句)得到sql语句是否使用了索引,使用了哪些索引。
语法:explain sql语句\G 或 desc sql语句\G
前缀索引
通过字段前n位创建的索引就称为“前缀索引”。
如果一个字段内容的前边的n位信息已经足够标识当前的字段内容,就可以把字段的前n位获得出来并创建索引,该索引占据空间更小、运行速度更快
语法:alter table 表名 add key/index (字段(前n位位数))
查询缓存
mysql服务器提供的,用于缓存select语句结果的一种内部内存缓存系统。
如果开启了查询缓存,将所有的查询结果,都缓存起来,使用同样的select语句,再次查询时,直接返回缓存的结果即可
开启缓存
> show variables like ‘query_cache%’; //查看缓存使用情况
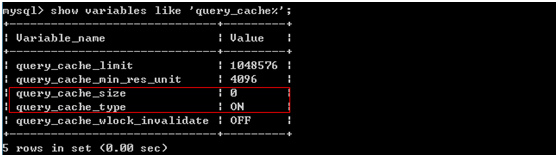
query_cache_size:缓存空间大小
query_cache_type:是否有开启缓存
query_cache_type = 1
query_cache_size = 134217728
注:在my.ini中开启
缓存失效
数据表的数据(数据有修改)有变化 或者 数据表结构(字段的增、减)有变化,则会清空全部的缓存数据,即缓存失效。
禁用缓存
sql_no_cache 不进行缓存
select sql_no_cache * from emp where empno=123456;
查看缓存使用情况
> show status like ‘Qcache%’; //查看缓存使用情况


分区技术
List分区
list :条件值为一个数据区。根据“字段的内容值”是否在某个“区域”中进行分区
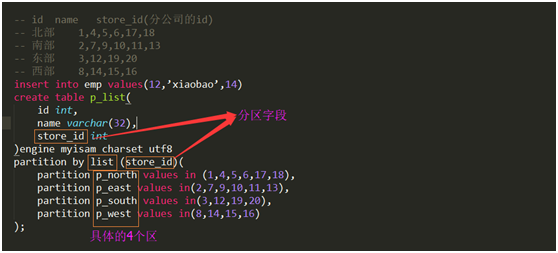
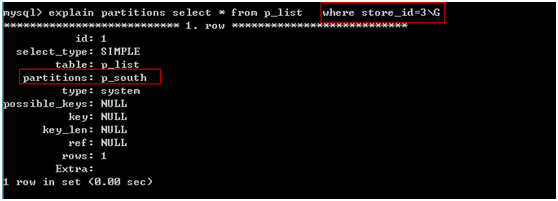
查询:explain partitions select * from p_list where store_id=20\G
关键:在使用分区时,where后面的字段必须是分区字段,才能使用到分区。
不使用分区字段的结果:
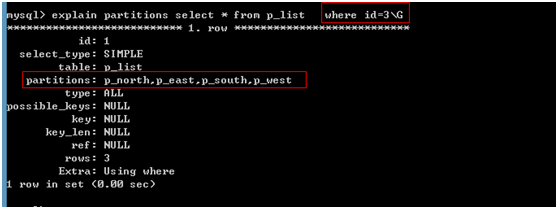
语法:
create table p_list(
id int,
name varchar(32),
store_id int
)engine myisam charset utf8
partition by list (store_id)(
partition p_north values in (1,4,5,6,17,18),
partition p_east values in(2,7,9,10,11,13),
partition p_south values in(3,12,19,20),
partition p_west values in(8,14,15,16)
);
Range分区
Hash分区
Key分区
删除分区
① 在key/hash领域不会造成数据丢失(删除分区后数据会重新整合到剩余的分区去)
② 在range/list领域会造成数据丢失
2)删除list类型分表(数据有对应丢失)
alter table p_list drop partition p_north;
注:分区里包含的数据也被删除
增加分区
求余方式: key/hash
> alter table 表名 add partition partitions 数量;
范围方式: range/list
> alter table 表名 add partition(
partition 名称 values less than (常量)
或
partition 名称 in (n,n,n)
);
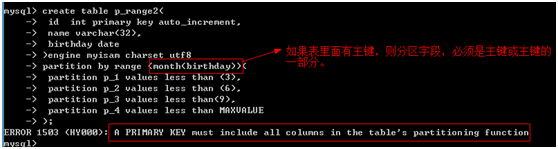
注意:创建分区的字段必须是主键(唯一)或主键(唯一)的一部分

前端优化
页面静态化(做缓存):真静态(ob缓存) ,伪静态(重写机制)
后端优化
表设计:
字段类型(int tinyint varchar char)
字段属性(not null,default,comment,primary key,auto_increment,unique key)
索引
存储引擎,默认innodb支持事务
查询优化:
使用连表查询 避免使用Like和select *
事务处理
数据库读写分离

 浙公网安备 33010602011771号
浙公网安备 33010602011771号