论文阅读笔记#2
论文阅读笔记#2
论文:word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method
作者:Yoav Goldberg and Omer Levy {yoav.goldberg,omerlevy}@gmail.com
The Introduction of Word2vec
NLP 里面,最细粒度的是 词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。
举个简单例子,判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射,但这里的数学模型 f(比如神经网络、SVM)只接受数值型输入,而 NLP 里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),**而 Word2vec,就是词嵌入( word embedding) 的一种 **[https://zhuanlan.zhihu.com/p/26306795]
one-hot encoder
所谓 one-hot encoder,其思想跟特征工程里处理类别变量的 one-hot 一样。本质上是用一个只含一个 1、其他都是 0 的向量来唯一表示词语。
Research Question
为了弄清楚 word2vec 的原理,并且解释里面的公式。
Mikolov 两篇原论文:
『Distributed Representations of Sentences and Documents』
贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec
『Efficient estimation of word representations in vector space』
贡献:专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling
来源:https://zhuanlan.zhihu.com/p/26306795
Methods
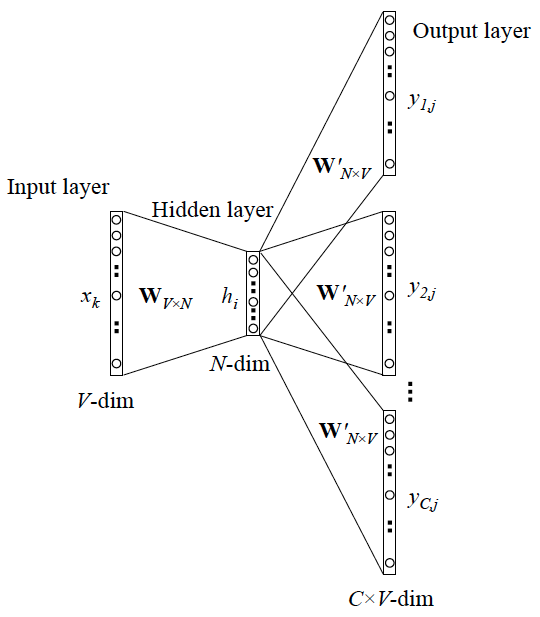
The skip-gram model
作用:用一个词语作为输入,来预测它周围的上下文
我们的目标是设置参数\(\theta\)的\(p(c|w;\theta)\)使corpus probability 最大化
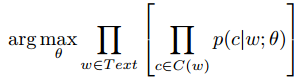
c是文本,w是词,C(w)是单词w的上下文集合。或者
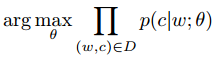
D是从文本中提取的所有单词和上下文对的集合
Parameterization of the skip-gram model
- \(p(c|w;\theta)\) 使用softmax, \(v_c\)和\(v_w\) (\(\in R^d\))是c和w的向量表示。\(\theta\)是\(v_{c_i},v_{w_i}\)
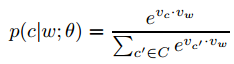
- 对希望最大化的式子取log
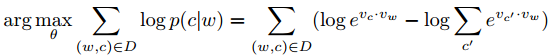
- 嵌入过程的假设:最大化上述目标会得到良好的嵌入效果\(v_w \forall w\in V\),也就是说相似的词会有相似的向量。(用分级hierarchical softmax替换softmax减少计算量)
Negative Sampling
Negative Sampling是用于更有效的提取词嵌入的方法。
实例:如果 vocabulary 大小为10000时, 当输入样本 ( "fox", "quick") 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word. negative sampling 的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。
\(p(D = 1|w, c)\) 为来自语料库的概率, $p(D = 0|w, c) = 1 - p(D = 1|w, c) $ 为不来自语料库的概率。\(\theta\)为控制参数$p(D = 1|w, c; θ) $。我们现在的目标是找到参数使概率最大化,所有的观察结果都来自数据:
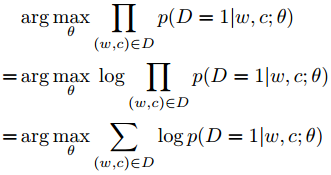
$p(D = 1|w, c; θ) $使用softmax定义:
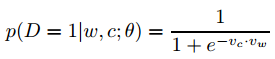
此时目标变为:
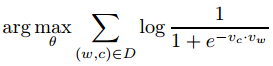
对于每对(w,c),当$p(D = 1|w, c; θ) = 1 \(时,会有一个trivial solution 。我们可以设置\)v_c=v_w$ and \(v_c\cdot v_w=K\) 来实现这种情况,当K足够大(实际K ≈ 40就达到)。
但是我们需要一种机制不让所有向量取到相同值,通过禁止某些(w, c)组合。对于一些(w,c)对使他们的\(p(D = 1|w, c; θ)\)值低。即随机抽样否定样本集合\(D'\)。目标优化如下(这里用的是整个$D ∪ D′ $ ):
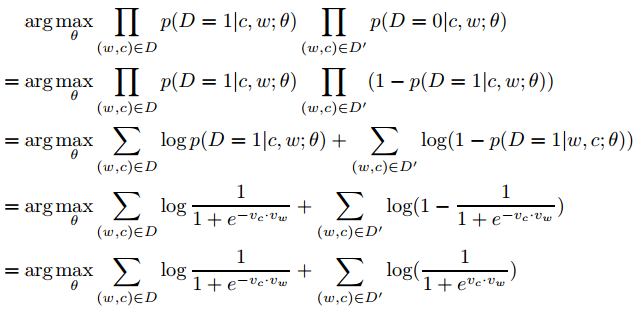
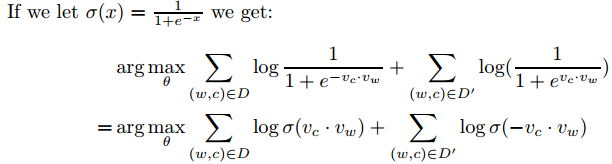
关于如何选择nagetive samples, 是根据他们出现概率来选的,而这个概率又和他们出现的频率有关。更常出现的词,更容易被选为negative sample(这里原文没看太懂,借鉴了别人的理解)。遵从如下概率:
-
\(p_{words}(w),p_{contexts}(c)\) 是单词和文本unigram 分布,Z是一个标准化常数。
-
取3/4是调试出来的结果
-
每个文本就是个词(所有词都是文本形式出现),因此$p_{words}(w)=p_{contexts}(c)=\frac{count(x)}{|Text|} $
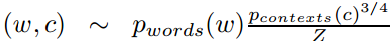
Dynamic window size
正在使用的窗口大小是动态的-参数k表示最大窗口大小。对于语料库中的每个单词,从1,..,k均匀采样窗口大小k '。
Effect of subsampling(子抽样) and rare-word pruning(罕见词剪修)
word2evc有两个额外的参数用于丢弃一些输入单词:出现少于最小计数次数的单词不被认为是单词或上下文,另外一个频繁的单词(由sample参数定义)被下采样。重要的是,这些词在生成上下文之前就从文本中删除了。这将增加某些单词的有效窗口大小。根据Mikolov等人[2]的研究,在某些基准上,对频繁词进行子抽样可以提高嵌入结果的质量。分段抽样的原始动机是,频繁的单词信息较少。这里我们看到了它的有效性的另一种解释:有效窗口大小增长,包括上下文词,既内容完整,并线性远离焦点词,从而使相似之处更贴近主题。
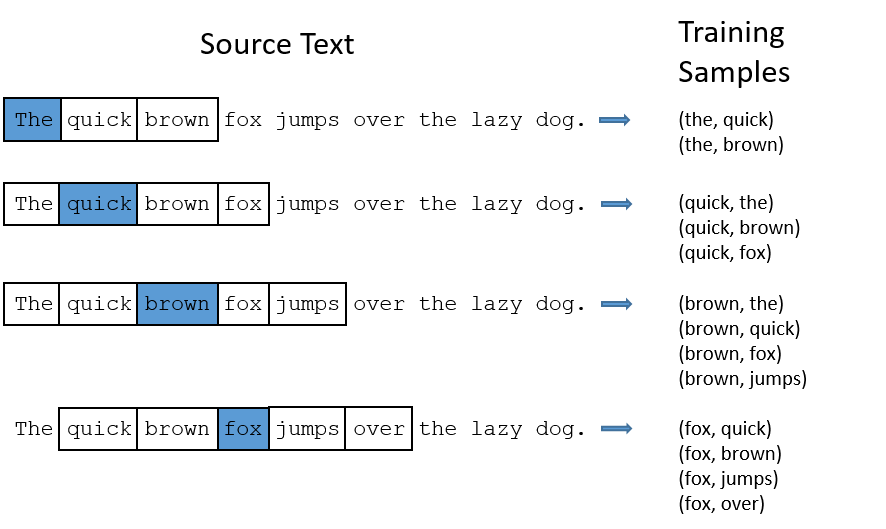
对于丢亲频繁出现的单词,相当于丢下像‘the’这种词:
-
(fox, the)没有传递信息
-
有太多the样本,过于容易,降低了训练效率
Else
把常见的词组作为一个单词
https://zhuanlan.zhihu.com/p/56106590
word2evc 作者指出像“Boston Globe“(一家报社名字)这种词对,和两个单词 Boston/Globe有着完全不同语义。所以更合理的是把“Boston Globe“看成一个单词,有他自己的word vector。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号