论文阅读笔记#1
论文阅读笔记#1
论文:CANE: Context-Aware Network Embedding for Relation Modeling
作者:Cunchao Tu1;2∗, Han Liu3∗, Zhiyuan Liu1;2y , Maosong Sun1;2
来源:acl2017
Github: https://github.com/thunlp/CANE
Research question
这篇论文在已有的网络嵌入(Network embedding, NE)基础上,假设一个顶点与不同的相邻顶点交互时通常表现出不同的aspects,并且应该分别具有不同的embeddings. 通过相互注意机制为顶点学习上下文感知嵌入(context-aware embeddings),并有望更精确地建模顶点之间的语义关系。
Some definitions and explanations
- 网络嵌入方法(Network Embedding)旨在学习网络中节点的低维度潜在表示,所学习到的特征表示可以用作基于图的各种任务的特征,例如分类,聚类,链路预测和可视化。(总结:将高维稀疏矩阵变为低维稠密矩阵);
- Embedding在数学上是一个函数,\(f:X->Y\),即将一个空间的点映射到另一个空间通常是高维抽象空间映射到低维具象空间;
- 一般映射到低维空间的表示具有分布式稠密表示的特性,计算机善于处理低纬度的信息;
The disadvantage of most NE
在真实的社交网络中,一个顶点在与不同的相邻顶点交互时可能会表现出不同的aspects. 现有的大多数NE方法只对每个顶点安排一个单一的嵌入向量,导致了以下两个可逆的问题:
- 这些方法不能灵活地处理一个顶点与不同邻居交互时的方向转换。
- 在这些模型中,一个顶点倾向于迫使其相邻顶点的embeddings彼此接近,这可能不是一直都是这样。
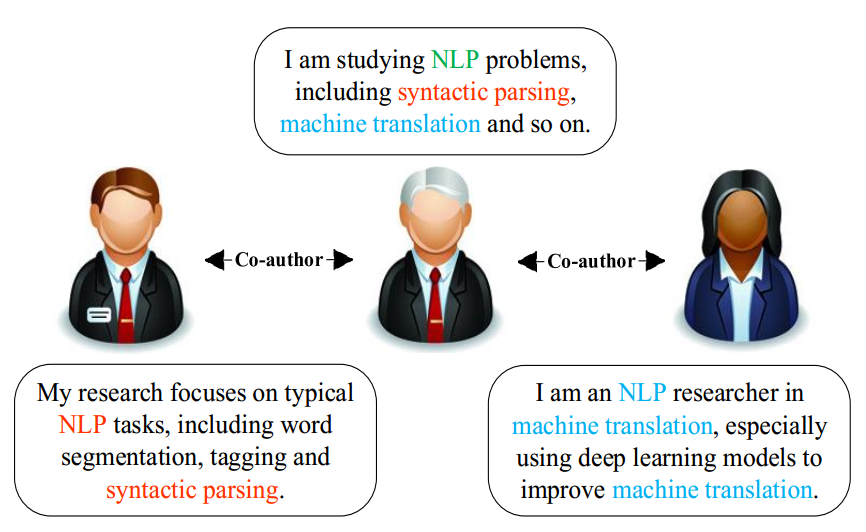
Hypotheses
- 以顶点\(u\) 和它的邻居顶点\(v\) 为例。当与不同的邻居交互时,\(u\)的 Context-free Embeddings 保持不变。相反,当面对不同的邻居时,的\(u\) Context-aware Embeddings 是动态的。当\(u\)与\(v\) 交互时,它们之间的context embeddings分别来源于它们的文本信息\(S_u\)和 \(S_v\) 。
- Context-free Embeddings:传统的NRL模型学习每个顶点的上下文无关嵌入。这意味着顶点的嵌入是固定的,不会因其上下文信息(即与之交互的另一个顶点)而改变。
- Context-aware Embeddings:与现有的学习上下文无关嵌入的NRL模型不同,CANE根据顶点的不同上下文学习不同的嵌入。对于边缘\(e_{u,v}\) , CANE学习上下文感知嵌入\(\mathrm{v}_{(u)}\) 和\(\mathrm{u}_{(v)}\)
- 假设网络是有向的,因为一条无向边可以看作是两条方向相反、权值相等的有向边
Methods
Formulation

Framework
Structure-based embedding 可以捕捉到网络结构中的信息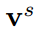
Textbased embedding 能捕捉到相关文本信息中的文本含义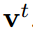
Vertex embeddings 

CANE旨在最大化边缘的总体目标如下:
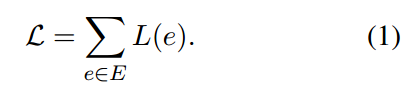
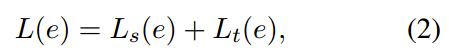
其中\(L_s(e)\)表示基于结构的目标,\(L_t(e)\)表示基于文本的目标。
Structure-based Objective
测量有向边缘的对数似然值
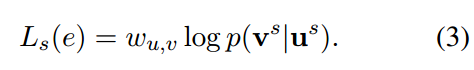
条件概率(softmax函数)
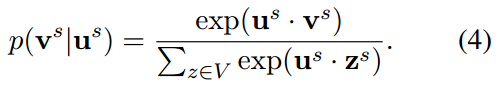
Text-based Objective (待探究)
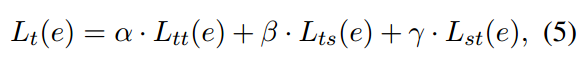
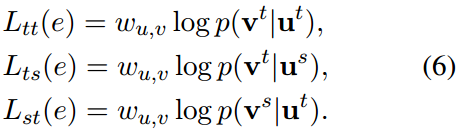
Context-Free Text Embedding
通过对比不同网络模型性能选择了CNN(卷积神经网络),以一个顶点的词序列作为输入,CNN通过查找、卷积和池化三层来获得基于文本的嵌入。
- Looking-up
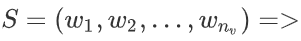
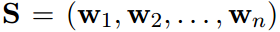
- Convolution
提取输入
 的局部特征,使用卷积矩阵
的局部特征,使用卷积矩阵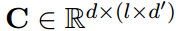 在长度为l的滑动窗口上进行卷积运算,
在长度为l的滑动窗口上进行卷积运算,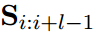 表示第i个窗口内嵌入词的拼接,
表示第i个窗口内嵌入词的拼接,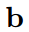
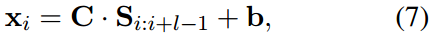
- Max-pooling
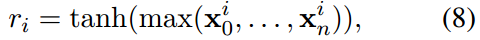
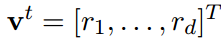
Context-Aware Text Embedding
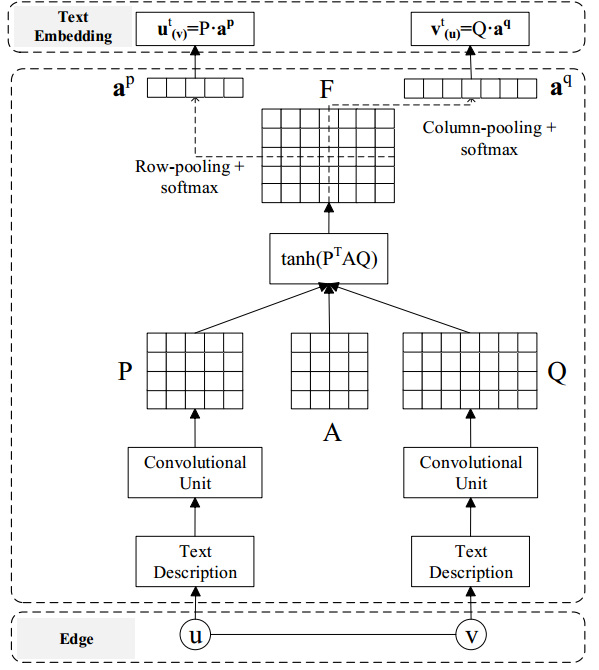
技术Attentive pooling (dos Santos et al.,2016)。它使CNN的池化层能够感知到边缘上的顶点对。
-
通过卷积层得到(m和n为\(S_u\)和\(S_v\)的长度),
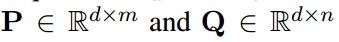
-
引入Attentive matrix 计算出 correlation matrix ,
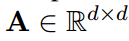
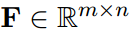 ,F中的每个元素\(F_{i,j}\)表示两个隐藏向量\(P_i\)和\(Q_j\)之间的成对相关得分。
,F中的每个元素\(F_{i,j}\)表示两个隐藏向量\(P_i\)和\(Q_j\)之间的成对相关得分。 -
沿着F的行和列进行池化操作,生成重要向量,分别称为行池化和列池化。由于表现优于max-pooling ,所以使用mean-pooling 。重要向量如下
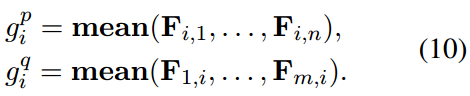
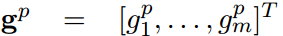

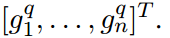
- 继续使用softmax函数计算出attention vectors
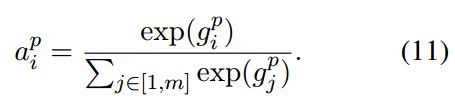
- u和v的context-aware text embeddings 计算为
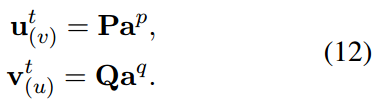
综上,对于给定的edge (u,v), 基于结构和文本的context-aware embeddings 为
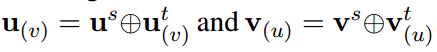
Optimization of CANE
使用negative sampling (Mikolov et al., 2013b)优化条件概率
关于negetive samplinghttps://zhuanlan.zhihu.com/p/56106590
其中k为negative样本数,σ为sigmoid函数。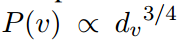 为顶点分布,其中\(d_v\)为\(v\)的出度.
为顶点分布,其中\(d_v\)为\(v\)的出度.
之后使用Adam(Kingma and Ba,2015) 优化转化的目标。
Investigate the effectiveness of CANE
作者在几个现实数据集上进行了链路预测实验来验证有效性。此外,还利用顶点分类来验证一个顶点的context-aware embeddings 是否可以组成一个高质量的context-free embedding 。
数据集:Cora 、HepTh 、Zhihu
基准:MMB、DeepWalk、LINE、Node2vec (Structure-only ). Naive Combination 、TADW 、CENE (Structure and Text ).
评价度量:AUC
AUC科普https://www.zhihu.com/question/39840928
Link Prediction
关于链接预测https://www.zhihu.com/question/273499382
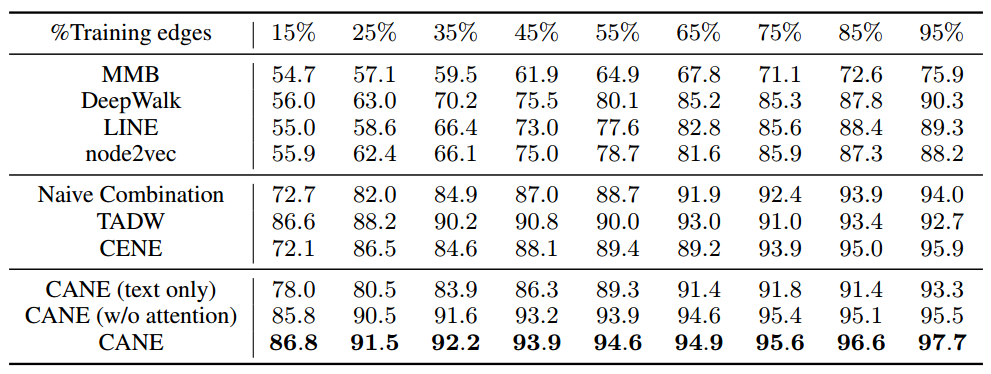
CANE可以学习高质量的上下文感知嵌入,这有助于精确估计顶点之间的关系。在链路预测任务上的实验结果表明了CANE算法的有效性和鲁棒性。
Vertex Classification
为了证明CANE解决这些问题的能力(global embedding ),通过简单地平均所有上下文件嵌入来生成顶点u的全局嵌入,如下所示:(其中N表示u上下文感知嵌入的个数)
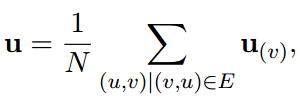
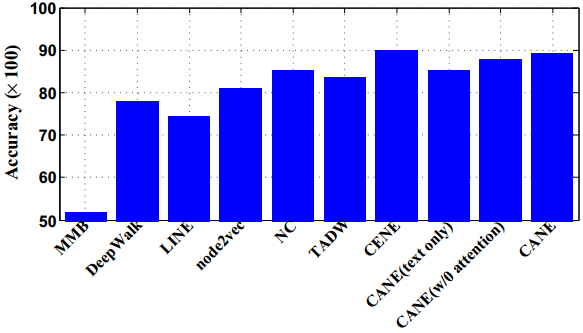
-
通过简单的平均运算,学习到的context-aware embeddings 可以转化为高质量的context-free embeddings ,并可进一步应用到其他网络分析任务中。
-
表明CANE可以灵活地处理各种网络分析任务。
Case Study
证明了mutual attention 对从文本信息中选择有意义的特征的重要性。
对于每个顶点对,可以得到每个卷积窗口的注意权值。为了获得单词的权重,本文将注意权重分配给这个窗口中的每个单词,并将单词的注意权重相加作为其最终的权重。

Edge#1的权重被分配给“reinforcement learning ”
Edge#2的权重被分配给“machine learning’’, “supervised learning algorithms” and “complex stochastic models”
A中的这些关键元素都可以在B和C中找到相应的词。这些关键要素对引文关系给出了准确的解释,这是很直观的。发现的顶点对之间的显著相关性反映了相互注意机制的有效性,以及CANE精确建模关系的能力。
Innovative Points
- 使用了相互注意机制为顶点学习上下文感知嵌入,解决了大多数NE模型的缺点
- 使用了CNN来得到Context-Free Text Embedding
- 使用negative sampling 优化条件概率,效率更高
- 使用AUC进行评估,结果更加可靠
- 在多个数据集上和多个现有模型进行比对来验证模型有效性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号