第七章:Python基础のXML操作和面向对象(一)
本課主題
- XML介绍与操作实战
- shutil 模块介绍与操作实战
- subprocess 模块介绍与操作实战
- 初探面向对象与操作实战
- 本周作业
XML介绍和操作实战
對於浏览器返回的字符串有以下幾種:
- HTML
- JSON,表现是列表和字典的格式
- XML
XML的應用
一个属性里包含多过属性,一类是页面上做展示的时候可以用到XML,就是为别人来调用(这也是字符串类型的一个XML格式数据);另外一类是配置文件。你可以从文件里打开一个XML文件,它返回的是一个XML形式的字符串;也可以通过发送 HTTP请求,返回一个 XML 形式的字符串
XML函数功能


class Element: """An XML element. This class is the reference implementation of the Element interface. An element's length is its number of subelements. That means if you want to check if an element is truly empty, you should check BOTH its length AND its text attribute. The element tag, attribute names, and attribute values can be either bytes or strings. *tag* is the element name. *attrib* is an optional dictionary containing element attributes. *extra* are additional element attributes given as keyword arguments. Example form: <tag attrib>text<child/>...</tag>tail """ 当前节点的标签名 tag = None """The element's name.""" 当前节点的属性 attrib = None """Dictionary of the element's attributes.""" 当前节点的内容 text = None """ Text before first subelement. This is either a string or the value None. Note that if there is no text, this attribute may be either None or the empty string, depending on the parser. """ tail = None """ Text after this element's end tag, but before the next sibling element's start tag. This is either a string or the value None. Note that if there was no text, this attribute may be either None or an empty string, depending on the parser. """ def __init__(self, tag, attrib={}, **extra): if not isinstance(attrib, dict): raise TypeError("attrib must be dict, not %s" % ( attrib.__class__.__name__,)) attrib = attrib.copy() attrib.update(extra) self.tag = tag self.attrib = attrib self._children = [] def __repr__(self): return "<%s %r at %#x>" % (self.__class__.__name__, self.tag, id(self)) def makeelement(self, tag, attrib): 创建一个新节点 """Create a new element with the same type. *tag* is a string containing the element name. *attrib* is a dictionary containing the element attributes. Do not call this method, use the SubElement factory function instead. """ return self.__class__(tag, attrib) def copy(self): """Return copy of current element. This creates a shallow copy. Subelements will be shared with the original tree. """ elem = self.makeelement(self.tag, self.attrib) elem.text = self.text elem.tail = self.tail elem[:] = self return elem def __len__(self): return len(self._children) def __bool__(self): warnings.warn( "The behavior of this method will change in future versions. " "Use specific 'len(elem)' or 'elem is not None' test instead.", FutureWarning, stacklevel=2 ) return len(self._children) != 0 # emulate old behaviour, for now def __getitem__(self, index): return self._children[index] def __setitem__(self, index, element): # if isinstance(index, slice): # for elt in element: # assert iselement(elt) # else: # assert iselement(element) self._children[index] = element def __delitem__(self, index): del self._children[index] def append(self, subelement): 为当前节点追加一个子节点 """Add *subelement* to the end of this element. The new element will appear in document order after the last existing subelement (or directly after the text, if it's the first subelement), but before the end tag for this element. """ self._assert_is_element(subelement) self._children.append(subelement) def extend(self, elements): 为当前节点扩展 n 个子节点 """Append subelements from a sequence. *elements* is a sequence with zero or more elements. """ for element in elements: self._assert_is_element(element) self._children.extend(elements) def insert(self, index, subelement): 在当前节点的子节点中插入某个节点,即:为当前节点创建子节点,然后插入指定位置 """Insert *subelement* at position *index*.""" self._assert_is_element(subelement) self._children.insert(index, subelement) def _assert_is_element(self, e): # Need to refer to the actual Python implementation, not the # shadowing C implementation. if not isinstance(e, _Element_Py): raise TypeError('expected an Element, not %s' % type(e).__name__) def remove(self, subelement): 在当前节点在子节点中删除某个节点 """Remove matching subelement. Unlike the find methods, this method compares elements based on identity, NOT ON tag value or contents. To remove subelements by other means, the easiest way is to use a list comprehension to select what elements to keep, and then use slice assignment to update the parent element. ValueError is raised if a matching element could not be found. """ # assert iselement(element) self._children.remove(subelement) def getchildren(self): 获取所有的子节点(废弃) """(Deprecated) Return all subelements. Elements are returned in document order. """ warnings.warn( "This method will be removed in future versions. " "Use 'list(elem)' or iteration over elem instead.", DeprecationWarning, stacklevel=2 ) return self._children def find(self, path, namespaces=None): 获取第一个寻找到的子节点 """Find first matching element by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Return the first matching element, or None if no element was found. """ return ElementPath.find(self, path, namespaces) def findtext(self, path, default=None, namespaces=None): 获取第一个寻找到的子节点的内容 """Find text for first matching element by tag name or path. *path* is a string having either an element tag or an XPath, *default* is the value to return if the element was not found, *namespaces* is an optional mapping from namespace prefix to full name. Return text content of first matching element, or default value if none was found. Note that if an element is found having no text content, the empty string is returned. """ return ElementPath.findtext(self, path, default, namespaces) def findall(self, path, namespaces=None): 获取所有的子节点 """Find all matching subelements by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Returns list containing all matching elements in document order. """ return ElementPath.findall(self, path, namespaces) def iterfind(self, path, namespaces=None): 获取所有指定的节点,并创建一个迭代器(可以被for循环) """Find all matching subelements by tag name or path. *path* is a string having either an element tag or an XPath, *namespaces* is an optional mapping from namespace prefix to full name. Return an iterable yielding all matching elements in document order. """ return ElementPath.iterfind(self, path, namespaces) def clear(self): 清空节点 """Reset element. This function removes all subelements, clears all attributes, and sets the text and tail attributes to None. """ self.attrib.clear() self._children = [] self.text = self.tail = None def get(self, key, default=None): 获取当前节点的属性值 """Get element attribute. Equivalent to attrib.get, but some implementations may handle this a bit more efficiently. *key* is what attribute to look for, and *default* is what to return if the attribute was not found. Returns a string containing the attribute value, or the default if attribute was not found. """ return self.attrib.get(key, default) def set(self, key, value): 为当前节点设置属性值 """Set element attribute. Equivalent to attrib[key] = value, but some implementations may handle this a bit more efficiently. *key* is what attribute to set, and *value* is the attribute value to set it to. """ self.attrib[key] = value def keys(self): 获取当前节点的所有属性的 key """Get list of attribute names. Names are returned in an arbitrary order, just like an ordinary Python dict. Equivalent to attrib.keys() """ return self.attrib.keys() def items(self): 获取当前节点的所有属性值,每个属性都是一个键值对 """Get element attributes as a sequence. The attributes are returned in arbitrary order. Equivalent to attrib.items(). Return a list of (name, value) tuples. """ return self.attrib.items() def iter(self, tag=None): 在当前节点的子孙中根据节点名称寻找所有指定的节点,并返回一个迭代器(可以被for循环)。 """Create tree iterator. The iterator loops over the element and all subelements in document order, returning all elements with a matching tag. If the tree structure is modified during iteration, new or removed elements may or may not be included. To get a stable set, use the list() function on the iterator, and loop over the resulting list. *tag* is what tags to look for (default is to return all elements) Return an iterator containing all the matching elements. """ if tag == "*": tag = None if tag is None or self.tag == tag: yield self for e in self._children: yield from e.iter(tag) # compatibility def getiterator(self, tag=None): # Change for a DeprecationWarning in 1.4 warnings.warn( "This method will be removed in future versions. " "Use 'elem.iter()' or 'list(elem.iter())' instead.", PendingDeprecationWarning, stacklevel=2 ) return list(self.iter(tag)) def itertext(self): 在当前节点的子孙中根据节点名称寻找所有指定的节点的内容,并返回一个迭代器(可以被for循环)。 """Create text iterator. The iterator loops over the element and all subelements in document order, returning all inner text. """ tag = self.tag if not isinstance(tag, str) and tag is not None: return if self.text: yield self.text for e in self: yield from e.itertext() if e.tail: yield e.tail 节点功能一览表
每一个节点都是一个 element 对象,节点里可以嵌套节点;这里的 book.xml 例子有 <书>:每本书分別都有<书名>,<作者>,<出版年份> 和 <价格> 4个属性。
<bookstore> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="web"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
- 把整个XML文件的树先取出来放在一个XML对象里,加载到内存里,它返回的是一个ElementTree 里的 ElementTree类型<class 'xml.etree.ElementTree.ElementTree'>
![]() ET.parse()
ET.parse()>>> from xml.etree import ElementTree as ET >>> xmltree = ET.parse('book.xml') >>> print(type(xmltree)) <class 'xml.etree.ElementTree.ElementTree'>
- 如果你想取它的根目录的话,调用getroot( )函数,它返回的是一个ElementTree 里的 Element类型 <class 'xml.etree.ElementTree.Element'> 。
![]() getroot()例子
getroot()例子>>> xmltree = ET.parse('book.xml') >>> root = xmltree.getroot() >>> print(root) <Element 'bookstore' at 0x10d065868> >>> print(type(root)) <class 'xml.etree.ElementTree.Element'>
- 用的 open( )函数打开一个XML文件,它返回的是XML形式的字符串,然后通过调用XML( )函数来读取/操作出XML格式的文件,它返回的也是一个 ElementTree 里的Element类型<class 'xml.etree.ElementTree.Element'> 。
![]() ET.XML()例子
ET.XML()例子>>> str_xmltree = open('book.xml','r').read() # 返回XML形式的字符串 >>> print(type(str_xmltree)) <class 'str'> >>> root = ET.XML(str_xmltree) >>> print(root) <Element 'bookstore' at 0x10d06eb88> >>> print(type(root)) <class 'xml.etree.ElementTree.Element'>
- 取出XML文件的 tag element,一個XML文件可以有很多 tag,tag 是構成XML格式的重要元素。 比如在上面 bookstore 的例子里,tag 分別是 <bookstore>、<book>、<title>、<author>、<year>、<price>,如果想找到一個 XML 的 Tag,就可以調用 tag变量來找。
![]() tag变量
tag变量>>> xmltree = ET.parse('book.xml') >>> root = xmltree.getroot() >>> print(root.tag) # 调用 tag 函数 bookstore >>> for child in root: #下一层也有下一层的Tag ... print(child.tag) ... book book book >>> for child in root: #下一层也有下一层的Tag ... print(child.tag) ... for grandchild in child: ... print(child.tag, grandchild.tag) ... book book title book author book year book price book book title book author book year book price book book title book author book year book price
- 取出XML文件Tag中的metadata/attribue,例如: <book category="cooking">,catergory = "cooking" 就是調用以下函数可以拿到的,返回的是一个字典类型。
![]() attrib变量
attrib变量>>> xmltree = ET.parse('book.xml') >>> root = xmltree.getroot() >>> for child in root: ... print(child.tag, child.attrib,type(child.attrib)) ... book {'category': 'cooking'} <class 'dict'> book {'category': 'children'} <class 'dict'> book {'category': 'web'} <class 'dict'>
- 想取出 Tag 裡值的話,例如: <author>Giada De Laurentiis</author>,可以調用 text变量
![]() text变量
text变量>>> xmltree = ET.parse('book.xml') >>> root = xmltree.getroot() >>> for child in root: ... for grandchild in child: ... print(child.tag+"-"+grandchild.tag+":", grandchild.text) ... book-title: Everyday Italian book-author: Giada De Laurentiis book-year: 2005 book-price: 30.00 book-title: Harry Potter book-author: J K. Rowling book-year: 2005 book-price: 29.99 book-title: Learning XML book-author: Erik T. Ray book-year: 2003 book-price: 39.95
-
如何生成新的XML文件
-
如何创建节点
-
如何创建XML
<data title="'CTO" age="50"> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2023</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2026</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2026</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
>>> from xml.etree import ElementTree as ET >>> tree = ET.parse('xo.xml') >>> root = tree.getroot() >>> for child in root: ... print(child.tag,child.attrib) ... for grandchild in child: ... print(grandchild.tag,grandchild.text) ... country {'name': 'Liechtenstein'} rank 2 year 2023 gdppc 141100 neighbor None neighbor None country {'name': 'Singapore'} rank 5 year 2026 gdppc 59900 neighbor None country {'name': 'Panama'} rank 69 year 2026 gdppc 13600 neighbor None neighbor None
shutil 模块介绍和操作实战
这个模块主要是为了处理文件、文件夹和压缩文件,它文件內容,權限,文件夾嵌套文件夾、壓縮文件的處理。
文件操作:打开文件以及读写文件
- 拷贝文件:從一個文件拷贝到另外一個文件,这里接受的是一个文件对象 <class '_io.TextIOWrapper'>
![]() 拷贝文件(方法一)
拷贝文件(方法一)import shutil # Copy a file from source to destination src = open("src.txt","r") #<class '_io.TextIOWrapper'> dest = open("dest.txt","w") #<class '_io.TextIOWrapper'> shutil.copyfileobj(src,dest)
- 拷贝文件:從一個文件拷贝到另外一個文件,这里接受的是一个文件字符串
![]() 拷贝文件(方法二)
拷贝文件(方法二)import shutil # Copy a file from source to destination shutil.copyfile("f1.log","f2.log")
- 只拷贝文件的权限
![]() 拷贝文件权限
拷贝文件权限import shutil shutil.copymode("f1.log","f2.log")
- 拷贝状态的信息,包括:mode bits, atime, mtime, flags
![]() 拷贝文件
拷贝文件import shut shutil.copystat("f1.log","f2.log")
- 拷贝文件和权限
![]() 拷贝文件和权限
拷贝文件和权限import shutil shutil.copy('f1.log', 'f2.log')
- 拷贝文件和状态信息
![]() 拷贝文件和状态信息
拷贝文件和状态信息import shutil shutil.copy2('f1.log', 'f2.log')
- 递归的去拷贝文件夹
![]() 递归的去拷贝文件夹
递归的去拷贝文件夹import shutil shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
- 递归的去移动文件,它类似mv命令,其实就是重命名
![]() 递归的去移动文件
递归的去移动文件import shutil shutil.move('folder1', 'folder3')
- 创建压缩包并返回文件路径
shutil.make_archive(base_name, format,...)
- xxxxx
Python 的压缩操作
对于解压单个文件来说,注意:zipfile 模块來解压指定文件只需要输入字符串,但 tarfile 模块必需传入一个 <class 'tarfile.TarInfo'>的对象才可以成功解压。
zipfile
- 压缩文件
![]() Zip压缩
Zip压缩import zipfile z = zipfile.ZipFile("examples.zip","w") z.write("f1.log") z.write("f2.log") z.close()
- 解压全部文件
![]() Zip解压全部
Zip解压全部import zipfile z = zipfile.ZipFile("examples.zip","r") z.extractall() z.close()
- 解压单个文件,调用 namelist( ) 去找一个压缩文件里有哪些文件 (返回字符串)
![]() Zip解压单个文件
Zip解压单个文件import zipfile z = zipfile.ZipFile("examples.zip","r") print(z.namelist()) #['f1.log', 'f2.log'] for item in z.namelist(): print(item) z.extract("f1.log") z.close()
tarfile
- 压缩文件
![]() tar压缩文件
tar压缩文件import tarfile tar = tarfile.open('example.tar','w') tar.add('f1.log', arcname='access.log') tar.add('f2.log', arcname='error.log') tar.close()
- 解压全部文件
![]() tar解压全部文件
tar解压全部文件import tarfile tar = tarfile.open("example.tar","r") tar.extractall() # 可设置解压地址 tar.close()
- 解压单个文件,tarfile 模块在解压单个文件时,只接受一个对象而不是字符串
![]() tar解压单个文件
tar解压单个文件import tarfile tar = tarfile.open("example.tar","r") # Return a TarInfo object <class 'tarfile.TarInfo'> for item in tar.getmembers(): print(item,type(item)) #传入字符串获取一个对象 obj = tar.getmember('access.log') print(obj) # <TarInfo 'access.log' at 0x1033499a8> tar.extract(obj) tar.close()
subprocess 模块介绍和操作实战
如果参数 shell=True,第一个参数接受的是数符串;如果参数 shell=False,第一个参数接受的是列表
- 返回状态码: subprocess.call( )
![]() subprocess 中的 "ls -la"
subprocess 中的 "ls -la">>> ret1 = subprocess.call(["ls","-l"],shell=False) -rw-r--r-- 1 jcchoiling staff 535 Sep 17 17:04 access.log >>> print(ret1) >>> ret2 = subprocess.call(["ls -l"],shell=True) -rw-r--r-- 1 jcchoiling staff 535 Sep 17 17:04 access.log >>> print(ret2)
- 执行命令,如果执行状态码是0,则返回0,否则抛异常: subprocess.check_call( )
- 执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常: subprocess.check_out( )
![]() 返回內容
返回內容>>> import subprocess >>> ret3 = subprocess.check_output(["ls -l"],shell=True) >>> ret3 b'total 80\n-rw-r--r-- 1 jcchoiling staff 535 Sep 17 17:04 access.log\n-rw-r--r-- 1 jcchoiling staff 1136 Sep 5 22:05 createxmlOps.py\ndrwxr-xr-x 9 jcchoiling staff 306 Sep 17 16:55 data\n-rw-r--r-- 1 jcchoiling staff 535 Sep 17 17:04 error.log\n-rw-r--r-- 1 jcchoiling staff 10240 Sep 17 17:04 example.tar\n-rw-r--r-- 1 jcchoiling staff 615 Sep 17 17:06 s1.py\n-rw-r--r-- 1 jcchoiling staff 198 Sep 17 18:03 s2.py\n-rw-r--r-- 1 jcchoiling staff 938 Sep 5 20:33 xmlOps.py\n-rw-r--r-- 1 jcchoiling staff 361 Sep 17 17:04 zipOps.py\n' >>> type(ret3) <class 'bytes'>
上面几个方法内部其实也是调用subprocess.Popen( )函数,它相当于创建一些管道,分别是数据输入管道,数据输出管道和输出错误管道

- 基本的 subprocess.Popen( )函数
![]() subprocess.Popen( )基本语法一
subprocess.Popen( )基本语法一import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) #第一个参数可以是字符串 ret2 = subprocess.Popen("mkdir t2", shell=True) #也可以是列表
- 也可以传入参数,指定特定路径
![]() subprocess.Popen( )基本语法二
subprocess.Popen( )基本语法二import subprocess obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
- 以下是创建管道的完整代码,首先要创建一个子对象,然后在创建的同时传入一些参数开通这三个管道,在适当的管道里分别写入或读取数据,最后每个管道都必需关闭才是完整
![]() subprocess中的管道通信例子一(完整遍)
subprocess中的管道通信例子一(完整遍)import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") obj.stdin.close() cmd_out = obj.stdout.read() obj.stdout.close() cmd_error = obj.stderr.read() obj.stderr.close() print(cmd_out) print(cmd_error)
- 另外可以調用 communicate( ) 函数来获取输出stdout.read( )和错误的信息。
![]() subprocess中的管道通信例子二(半简洁遍)
subprocess中的管道通信例子二(半简洁遍)import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) obj.stdin.write("print(1)\n") obj.stdin.write("print(2)") out_error_list = obj.communicate() print(out_error_list)
- 最简洁的方式是当创建完一条管道后,直接调用obj.communicate("需要传入的命令") 来完成整个写入、读取和关闭的过程。
![]() subprocess中的管道通信例子三(简洁遍)
subprocess中的管道通信例子三(简洁遍)import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) out_error_list = obj.communicate('print("hello")') print(out_error_list)
初探面向对象与操作实战
类是对对象的一些描述,是关于对象的蓝图,它包含方法、属性或者叫成员。
面向对象的目标是代码重用,可以把属性和函数封装到一个类中,也可以把它当作工厂,在每次创建对象时可以确保该对象有相同的属性和方法。比如以下例子:创建了一个obj 的对象,这个对象的类型是SQLHelper类,如果基于这个类把 hhost, uusername 和pwd 的参数赋值,此时你可以调用刚才这些参数,然后通过函数打印出来
>>> class SQLHelper: ... def fetch(self,sql): ... print(self.hhost) ... print(self.uusername) ... print(self.pwd) ... print(sql) ... ... def create(self,sql): ... pass ... ... def remove(self,nid): ... pass ... ... def modify(self,name): ... pass ... >>> obj = SQLHelper() >>> obj.hhost = 'cl.salt.com' >>> obj.uusername = 'janice' >>> obj.pwd = '123' >>> obj.fetch("Select * from A") cl.salt.com janice 123 Select * from A
优化以上的代码,如果 host, username 和 pwd 是一些共同的参数的话,其实不需要每次创建对象时都把它赋值,因为当创建一个对象的时候,Python 默认会找 __init__ 方法,这个方法我们称之为构造方法。此时,可以把一些通用的参数放在构造方法里,当创建对象时那些参数便会自动创建。
class SQLHelper: # 自动执行 def __init__(self): print("自动执行") self.hhost = 'cl.salt.com' self.uusername = 'janice' self.pwd = '123' # self 是一个形式参数,是自动会给传值的参数 def fetch(self,sql): print(self.hhost) print(self.uusername) print(self.pwd) print(sql) # 在类里的函数称之为方法 def create(self,sql): pass def remove(self,nid): pass def modify(self,name): pass obj1 = SQLHelper() print(obj1.hhost) print(obj1.uusername) print(obj1.pwd) """ 自动执行 cl.salt.com janice 123 """
如果每个对象的 hhost, uusername 和 pwd 都不一样的话,也可以在创建对象时,通过传入参数的方式,把数值传进去
class SQLHelper: # 自动执行 def __init__(self,a1,a2,a3): print("自动执行") self.hhost = a1 self.uusername = a2 self.pwd = a3 # self 是一个形式参数,是自动会给传值的参数 def fetch(self,sql): print(self.hhost) print(self.uusername) print(self.pwd) print(sql) # 在类里的函数称之为方法 def create(self,sql): pass def remove(self,nid): pass def modify(self,name): pass obj1 = SQLHelper('cl.salt.com','janice','123') print(obj1.hhost) print(obj1.uusername) print(obj1.pwd) obj2 = SQLHelper('c2.salt.com','alex','999') print(obj2.hhost) print(obj2.uusername) print(obj2.pwd) """ 自动执行 cl.salt.com janice 123 自动执行 c2.salt.com alex 999 """
面向对象编程的三大特性:
- 封装
- 继承
- 多态
封装
在对象里是可以封装任意类型的数据
>>> class f1(): ... def __init__(self,name,obj): ... self.name = name ... self.obj=obj ... >>> class f2(): ... def __init__(self,name,age): ... self.name = name ... self.age = age ... >>> f2_obj = f2("alex",11) >>> f1_obj = f1("aa",f2_obj) >>> print(f1_obj.obj.age) 11 >>> print(f1_obj.obj.name) alex >>> print(f1_obj.name) aa
课堂练习
练习一:在终端输出如下信息
小明,10岁,男,上山去砍柴
小明,10岁,男,开车去东北
小明,10岁,男,最爱大保健
老李,90岁,男,上山去砍柴
老李,90岁,男,开车去东北
老李,90岁,男,最爱大保健
class Person: def __init__(self,name,age,gender): self.name=name self.age=age self.gender=gender def chop_the_wood(self): return "上山去砍柴" def driving(self): return "开车去东北" def keep_fit(self): return "最爱大保健" p1 = Person('小明',10,'男') p2 = Person('老李',90,'男') print(p1.name + "," + str(p1.age) + "岁," + p1.gender + "," + p1.chop_the_wood()) print(p1.name + "," + str(p1.age) + "岁," + p1.gender + "," + p1.driving()) print(p1.name + "," + str(p1.age) + "岁," + p1.gender + "," + p1.keep_fit()) print(p2.name + "," + str(p2.age) + "岁," + p2.gender + "," + p2.chop_the_wood()) print(p2.name + "," + str(p2.age) + "岁," + p2.gender + "," + p2.driving()) print(p2.name + "," + str(p2.age) + "岁," + p2.gender + "," + p2.keep_fit())
1、创建三个游戏人物,分别是: 苍井井,女,18,初始战斗力1000 东尼木木,男,20,初始战斗力1800 波多多,女,19,初始战斗力2500 2、游戏场景,分别: 草丛战斗,消耗200战斗力 自我修炼,增长100战斗力 多人游戏,消耗500战斗力
class Avatar: def __init__(self,name,gender,age,initial_value): self.gender = gender self.name = name self.age = age self.initial_value = initial_value def 草丛战斗(self,avatar): self.initial_value -= 200 avatar.initial_value -= 200 def 自我修炼(self): self.initial_value += 100 return self.initial_value def 多人游戏(self,avatar): self.initial_value -= 500 avatar.initial_value -= 500 avatar1 = Avatar('苍井井','女',18,1000) avatar2 = Avatar('东尼木木','男',20,1800) avatar3 = Avatar('波多多','女',19,2500) print("{}|{}|{}|{}".format(avatar1.name,avatar1.age,avatar1.gender,avatar1.initial_value)) print("{}|{}|{}|{}".format(avatar2.name,avatar2.age,avatar2.gender,avatar2.initial_value)) print("{}|{}|{}|{}".format(avatar3.name,avatar3.age,avatar3.gender,avatar3.initial_value)) print("草丛战斗".center(50,"-")) avatar1.草丛战斗(avatar2) avatar1.草丛战斗(avatar2) print(avatar1.initial_value) print(avatar2.initial_value) print("自我修炼".center(50,"-")) avatar1.自我修炼() avatar1.自我修炼() print(avatar1.initial_value) print(avatar2.initial_value) print("多人游戏".center(50,"-")) avatar1.多人游戏(avatar2) avatar1.多人游戏(avatar2) print(avatar1.initial_value) print(avatar2.initial_value) """ 苍井井|18|女|1000 东尼木木|20|男|1800 波多多|19|女|2500 -----------------------草丛战斗----------------------- 600 1400 -----------------------自我修炼----------------------- 800 1400 -----------------------多人游戏----------------------- -200 400 """
继承
继承在面向对象编程里是一个很重要的特性,子类可以继承着父类的所有功能,这好比现实生活中父亲与儿子,儿子会继承着父亲的基因。继承也有分单继承和多继承,以下是一个单继承的例子。
class F2(F1) # F2是儿子,F1是父亲
>>> class S1: ... def F1(self): ... self.F2() ... def F2(self): ... print("S1的F2") ... >>> class S2(S1): ... def F3(self): ... self.F1() ... def F2(self): ... print("S2的F2") ... >>> s2 = S2() >>> s2.F3() S2的F2 >>> s1 = S1() >>> s1.F1() S1的F2
多继承意味着一个子类可以有多于一个的父类,然后父亲们的所有功能,儿子都会继承着,以下是一个多继承的例子。
class F3(F2,F1) # F3是儿子,F1和F2是父亲
class C0: def f2(self): print("C0") class C1(C0): def f1(self): pass class C2: def f2(self): print("C2") class C3(C1,C2): def f3(self): print("f3.....") c3 = C3() c3.f2() print(C3.__mro__) """ C0 (<class '__main__.C3'>, <class '__main__.C1'>, <class '__main__.C0'>, <class '__main__.C2'>, <class 'object'>) """
在这个例子中,C3继承着C1和C2,跟据Python的规定,假设已经创建了一个C3类型的对象,它的运行顺序应该是:
- 从对象本身的类里找__init__构造方法
- 然后这里调用了c3.f2( ) 这个方法,此时,Python会从左往右一直往上跟着父子的继承关系找F2( ) 这个方法。
- 在下列例子,它会先从C1类里找f2( ),C1有的话它会执行,如果没有的话,因为C1的父类是C0,此时Python会往上到C0类里找f2( )方法而不是往右边的C2类里找 f2( )。
- 如果所有链条的父类都没有f2( )方法的话,Python此时会在C3的第2个继承父类里找f2( )方法,直到找到为此。
![]()

这个是多继承例子,然而继承终点不是指向同一对象,但如果继承的时候,最于都会指向同一个父类的话,程序的运行顺序又会是怎么样呢?
class C_2: def f2(self): print("C-1") class C_1(C_2): def f2(self): print("C-1") class C0(C_2): def f1(self): print("C0") class C1(C0): def f1(self): pass class C2: def f2(self): print("C2") class C3(C1,C2): def f3(self): print("f3.....") c3 = C3() c3.f2() print(C3.__mro__) """ C-1 (<class '__main__.C3'>, <class '__main__.C1'>, <class '__main__.C0'>, <class '__main__.C_2'>, <class '__main__.C2'>, <class 'object'>) """
在这个例子中,C3继承着C1和C2,然后最终都指向C_2类,跟据Python的规定,假设已经创建了一个C3类型的对象,它的运行顺序应该是:
- 从对象本身的类里找__init__构造方法
- 然后这里调用了c3.f2( ) 这个方法,此时,Python会从左往右一直往上跟着父子的继承关系找f2( ) 这个方法,必须注意一点!!!!! 如果遇到共同类的话,它会在C3的第2个继承父类里找f2( )方法,而不是我们上一个例子看到的一直随着链条向上找f2( )
- 在下面例子,它会先从C1类里找f2( )方法,C1有的话它就会执行,如果没有的话,因为C1的父类是C0,所以此时的Python会往上到C0类里找f2( )方法而不是直接到C2类里。
- 但如果C0都没有的话,此时的Python不会再往上到C_2类里找,反而会在C3的第2个继承父类里找f2( )方法,直到找到为此,这是因为两个父类都有指向共同的曾祖父类。
![]()
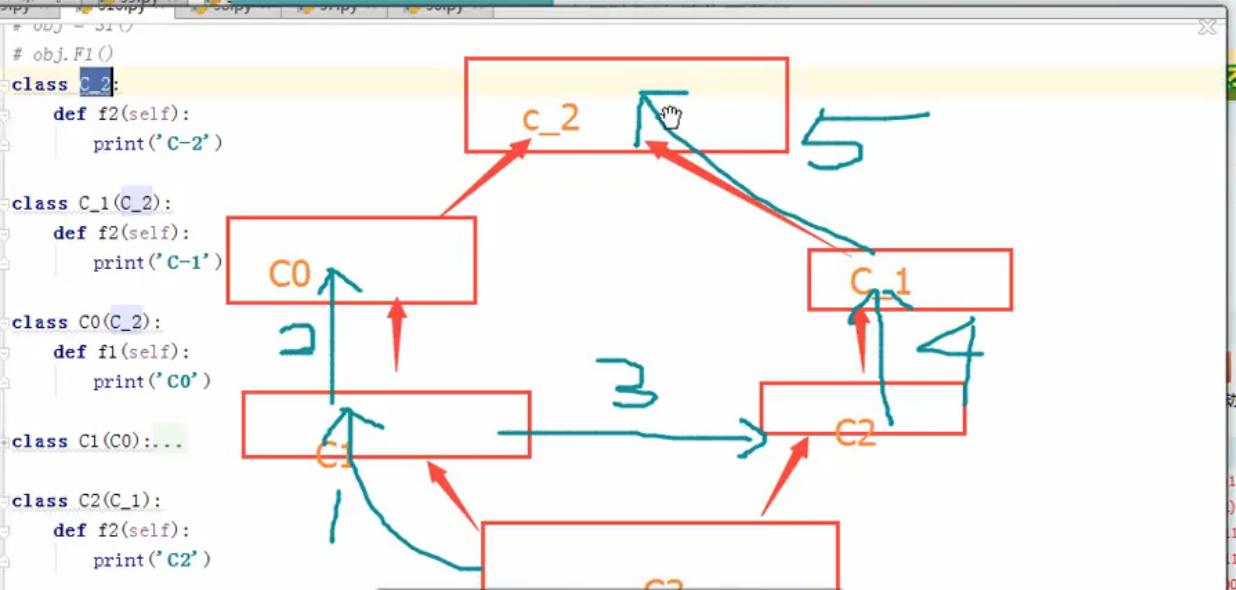
再来一个例子,这个继承关系的运行顺序必需很清晰,因为在往后读其他框架源码的时候,很多时候都运用了继承技巧,如果不了解的话就很容易在看源码的时候迷失了。下面例子假设S1类继承了S2、S3类,然后S2里有一个 process( )方法,S3里有构造方法,S3继承著S4,里面也有一個构造方法和一個 self.run( ) 方法,self.run( )再调用process( )方法。S4最后也继承著S5,S5里有一个 forever( )方法。
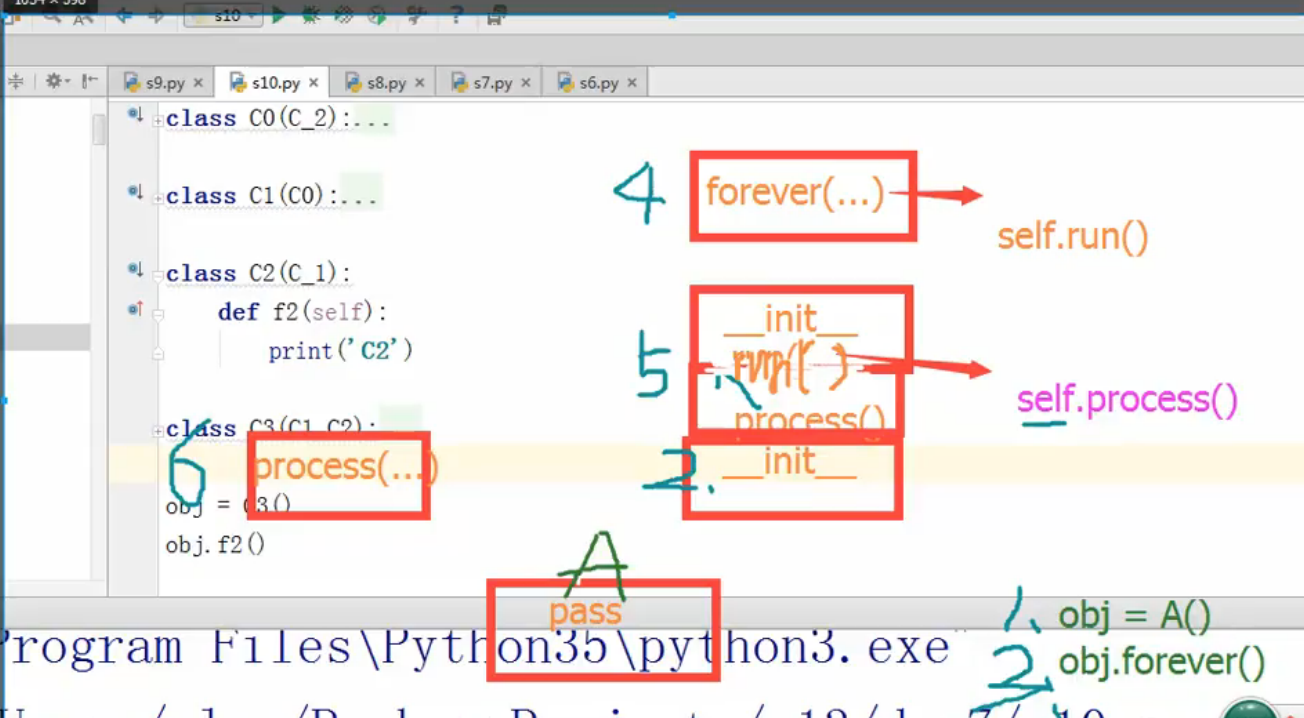
class s5: def forever(self): self.run() class s4(s5): def __init__(self): self.run() def run(self): self.process() def process(self): print("s4-process") class s3(s4): def __init__(self): self.name='s3-name' class s2: def process(self): print("s2-process...") class s1(s2,s3): pass obj = s1() print(obj.name) obj.forever() print(s1.__mro__) """ s3-name s2-process... (<class '__main__.s1'>, <class '__main__.s2'>, <class '__main__.s3'>, <class '__main__.s4'>, <class '__main__.s5'>, <class 'object'>) """
假设已经创建了一个C3类型的对象,它的运行顺序应该是:
- 从对象本身的类里找__init__构造方法,如果自身类没有__init__方法的话就到它的父类里找,在s2找不到,然后到s3找,找到第一个__init__方法就可以啦
- 然后执行第2行代码,obj.forever( ),Python 会首先到S2类找这个方法,没有便到s3类找,也没有会一直往链条的父类去找,直到s5类找到了forever( )方法
- 执行forever( )方法,不过这个方法是调用对象本身的self.run( )方法,此時會再從 s1类里再找一次 run( )方法:s1 --> s2 --> s3 --> s4 --> s5
- 找到在S4类里的run( )的方法,此时,它又调用process( )方法! (你心里会想是不是又要再重新从S1类再找一遍呀!) 没错!你猜对啦
- 先从S1类找 process( )方法,没有的话会到s2类里找!!!!! 终于找到啦!!!
- 所以运行后的结果是打印 s2-process 而不是 s4-process
![]()
Socket编程的例子
刚刚说过很多时候在读源码时都必需透晰理解类之间的继承关系,这里的一个例子就是关于 socket编程:
- 创建一个 ThreadingTCPServer( )的类;
- 执行对象的 serve_forever( )方法
import socketserver obj = socketserver.ThreadingTCPServer() #命令一 obj.serve_forever() #命令二
下面是创建一个 ThreadingTCPServer( ) 类的图解和运行顺序:
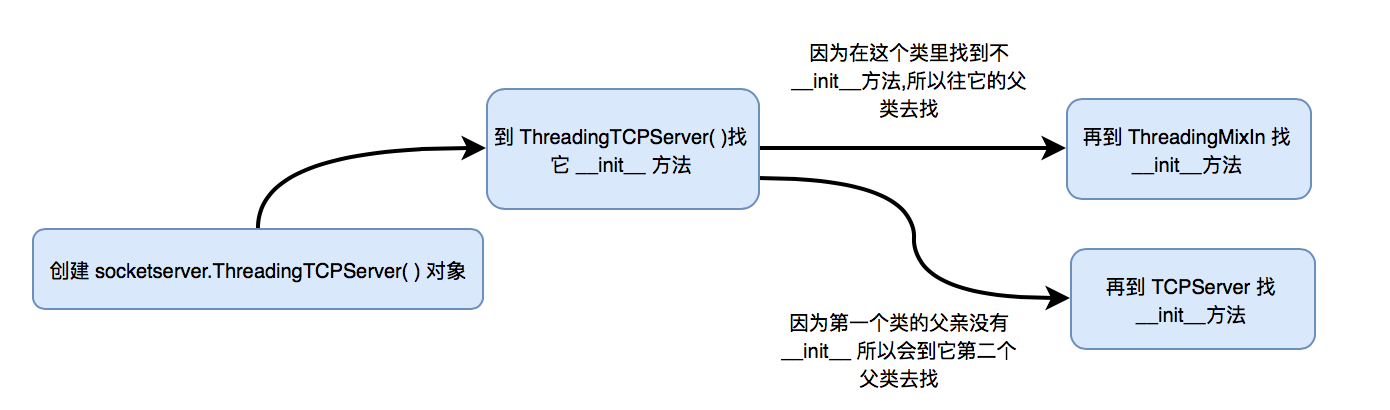
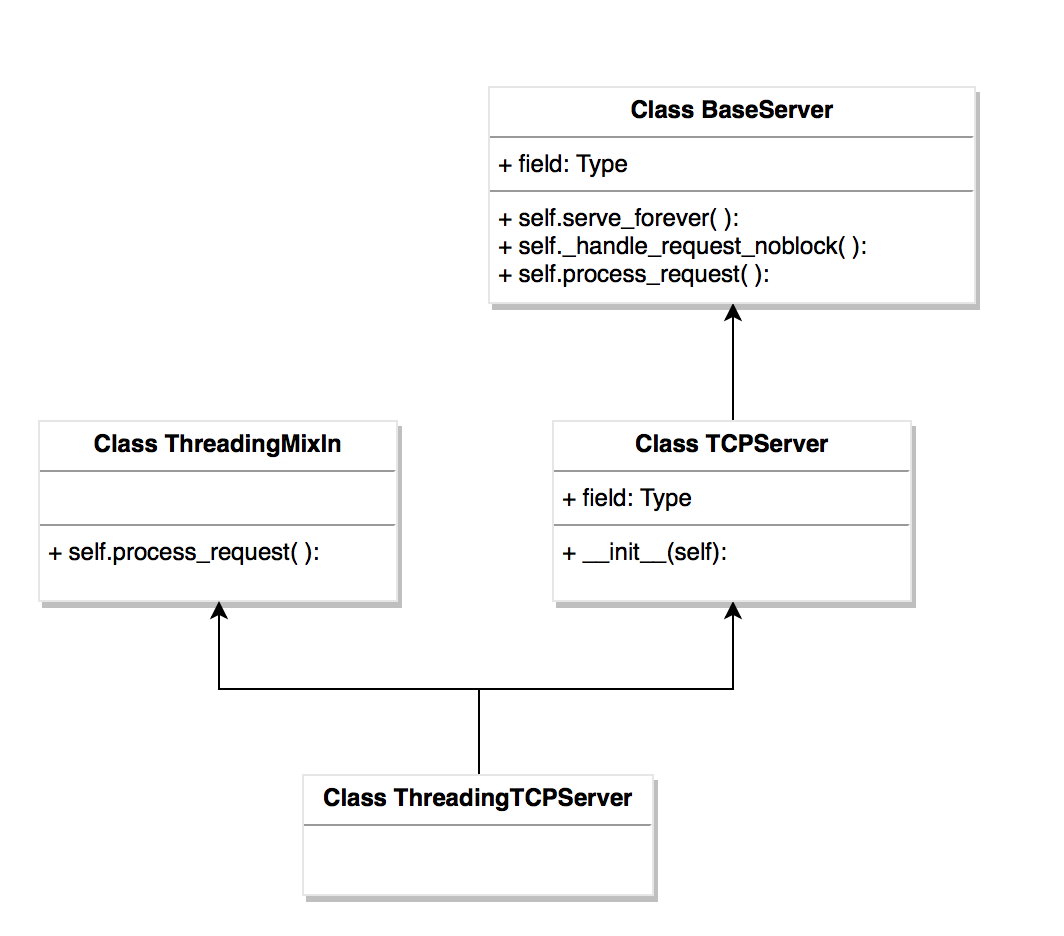
- 首先是创建了一个 socketserver.ThreadingTCPServer 的对象叫 obj,紧接着是找他的 __init__( )方法,下面是它的类,这里是一个空值。
![]()
class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass
- ThreadingTCPServer 继承者两个类,一个是 ThreadingMixIn,另外一个是 TCPServer,當在自己本身找不到 __init__( )方法,就會到它的父類去找 (ThreadingMixIn 或者 TCPServer),这里最终在 TCPServer 这个类里找到了 __init__( ) 方法,到這里命令一就完整啦
![]() TCPServer里的__init__( )方法
TCPServer里的__init__( )方法def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True): """Constructor. May be extended, do not override.""" BaseServer.__init__(self, server_address, RequestHandlerClass) self.socket = socket.socket(self.address_family, self.socket_type) if bind_and_activate: try: self.server_bind() self.server_activate() except: self.server_close() raise
- 现在是执行命令二:执行 obj.serve_forever( )方法,还是会先从 ThreadingTCPServer 类里找 serve_forever( )方法,但它并不存在,然后开始到它的父类,即 ThreadingMixIn 类里找,也会找不到发现 serve_forever( )方法。
![]() class ThreadingMixIn 源码
class ThreadingMixIn 源码class ThreadingMixIn: """Mix-in class to handle each request in a new thread.""" # Decides how threads will act upon termination of the # main process daemon_threads = False def process_request_thread(self, request, client_address): """Same as in BaseServer but as a thread. In addition, exception handling is done here. """ try: self.finish_request(request, client_address) self.shutdown_request(request) except: self.handle_error(request, client_address) self.shutdown_request(request) def process_request(self, request, client_address): """Start a new thread to process the request.""" t = threading.Thread(target = self.process_request_thread, args = (request, client_address)) t.daemon = self.daemon_threads t.start()
- 此时会到它的第2个父类里找:TCPSever 类
![]() class TCPServer 源码
class TCPServer 源码class TCPServer(BaseServer): """Base class for various socket-based server classes. Defaults to synchronous IP stream (i.e., TCP). Methods for the caller: - __init__(server_address, RequestHandlerClass, bind_and_activate=True) - serve_forever(poll_interval=0.5) - shutdown() - handle_request() # if you don't use serve_forever() - fileno() -> int # for selector Methods that may be overridden: - server_bind() - server_activate() - get_request() -> request, client_address - handle_timeout() - verify_request(request, client_address) - process_request(request, client_address) - shutdown_request(request) - close_request(request) - handle_error() Methods for derived classes: - finish_request(request, client_address) Class variables that may be overridden by derived classes or instances: - timeout - address_family - socket_type - request_queue_size (only for stream sockets) - allow_reuse_address Instance variables: - server_address - RequestHandlerClass - socket """ address_family = socket.AF_INET socket_type = socket.SOCK_STREAM request_queue_size = 5 allow_reuse_address = False def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True): """Constructor. May be extended, do not override.""" BaseServer.__init__(self, server_address, RequestHandlerClass) self.socket = socket.socket(self.address_family, self.socket_type) if bind_and_activate: try: self.server_bind() self.server_activate() except: self.server_close() raise def server_bind(self): """Called by constructor to bind the socket. May be overridden. """ if self.allow_reuse_address: self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self.socket.bind(self.server_address) self.server_address = self.socket.getsockname() def server_activate(self): """Called by constructor to activate the server. May be overridden. """ self.socket.listen(self.request_queue_size) def server_close(self): """Called to clean-up the server. May be overridden. """ self.socket.close() def fileno(self): """Return socket file number. Interface required by selector. """ return self.socket.fileno() def get_request(self): """Get the request and client address from the socket. May be overridden. """ return self.socket.accept() def shutdown_request(self, request): """Called to shutdown and close an individual request.""" try: #explicitly shutdown. socket.close() merely releases #the socket and waits for GC to perform the actual close. request.shutdown(socket.SHUT_WR) except OSError: pass #some platforms may raise ENOTCONN here self.close_request(request) def close_request(self, request): """Called to clean up an individual request.""" request.close()
- 也是找不到,TCPServer 也有一个父类叫 BaseServer
![]() class BaseServer 源码
class BaseServer 源码class BaseServer: """Base class for server classes. Methods for the caller: - __init__(server_address, RequestHandlerClass) - serve_forever(poll_interval=0.5) - shutdown() - handle_request() # if you do not use serve_forever() - fileno() -> int # for selector Methods that may be overridden: - server_bind() - server_activate() - get_request() -> request, client_address - handle_timeout() - verify_request(request, client_address) - server_close() - process_request(request, client_address) - shutdown_request(request) - close_request(request) - service_actions() - handle_error() Methods for derived classes: - finish_request(request, client_address) Class variables that may be overridden by derived classes or instances: - timeout - address_family - socket_type - allow_reuse_address Instance variables: - RequestHandlerClass - socket """ timeout = None def __init__(self, server_address, RequestHandlerClass): """Constructor. May be extended, do not override.""" self.server_address = server_address self.RequestHandlerClass = RequestHandlerClass self.__is_shut_down = threading.Event() self.__shutdown_request = False def server_activate(self): """Called by constructor to activate the server. May be overridden. """ pass def serve_forever(self, poll_interval=0.5): """Handle one request at a time until shutdown. Polls for shutdown every poll_interval seconds. Ignores self.timeout. If you need to do periodic tasks, do them in another thread. """ self.__is_shut_down.clear() try: # XXX: Consider using another file descriptor or connecting to the # socket to wake this up instead of polling. Polling reduces our # responsiveness to a shutdown request and wastes cpu at all other # times. with _ServerSelector() as selector: selector.register(self, selectors.EVENT_READ) while not self.__shutdown_request: ready = selector.select(poll_interval) if ready: self._handle_request_noblock() self.service_actions() finally: self.__shutdown_request = False self.__is_shut_down.set() def shutdown(self): """Stops the serve_forever loop. Blocks until the loop has finished. This must be called while serve_forever() is running in another thread, or it will deadlock. """ self.__shutdown_request = True self.__is_shut_down.wait() def service_actions(self): """Called by the serve_forever() loop. May be overridden by a subclass / Mixin to implement any code that needs to be run during the loop. """ pass # The distinction between handling, getting, processing and finishing a # request is fairly arbitrary. Remember: # # - handle_request() is the top-level call. It calls selector.select(), # get_request(), verify_request() and process_request() # - get_request() is different for stream or datagram sockets # - process_request() is the place that may fork a new process or create a # new thread to finish the request # - finish_request() instantiates the request handler class; this # constructor will handle the request all by itself def handle_request(self): """Handle one request, possibly blocking. Respects self.timeout. """ # Support people who used socket.settimeout() to escape # handle_request before self.timeout was available. timeout = self.socket.gettimeout() if timeout is None: timeout = self.timeout elif self.timeout is not None: timeout = min(timeout, self.timeout) if timeout is not None: deadline = time() + timeout # Wait until a request arrives or the timeout expires - the loop is # necessary to accommodate early wakeups due to EINTR. with _ServerSelector() as selector: selector.register(self, selectors.EVENT_READ) while True: ready = selector.select(timeout) if ready: return self._handle_request_noblock() else: if timeout is not None: timeout = deadline - time() if timeout < 0: return self.handle_timeout() def _handle_request_noblock(self): """Handle one request, without blocking. I assume that selector.select() has returned that the socket is readable before this function was called, so there should be no risk of blocking in get_request(). """ try: request, client_address = self.get_request() except OSError: return if self.verify_request(request, client_address): try: self.process_request(request, client_address) except: self.handle_error(request, client_address) self.shutdown_request(request) def handle_timeout(self): """Called if no new request arrives within self.timeout. Overridden by ForkingMixIn. """ pass def verify_request(self, request, client_address): """Verify the request. May be overridden. Return True if we should proceed with this request. """ return True def process_request(self, request, client_address): """Call finish_request. Overridden by ForkingMixIn and ThreadingMixIn. """ self.finish_request(request, client_address) self.shutdown_request(request) def server_close(self): """Called to clean-up the server. May be overridden. """ pass def finish_request(self, request, client_address): """Finish one request by instantiating RequestHandlerClass.""" self.RequestHandlerClass(request, client_address, self) def shutdown_request(self, request): """Called to shutdown and close an individual request.""" self.close_request(request) def close_request(self, request): """Called to clean up an individual request.""" pass def handle_error(self, request, client_address): """Handle an error gracefully. May be overridden. The default is to print a traceback and continue. """ print('-'*40) print('Exception happened during processing of request from', end=' ') print(client_address) import traceback traceback.print_exc() # XXX But this goes to stderr! print('-'*40)
- 在 BaseServer 里找到了 serve_forever( )方法,这个方法又调用了一个叫 self._handle request nonblock(),它又会再调用 self.process_request(request, client_address)。最於我們可以在 ThreadingMixIn 類里找到了 process_request(self, request, client_address) 的方法。
Socket编程例子的继承关系图
本周作业
运用面向对象来写一个选课系统
背景:这是一个 pay-as-you-go 的网上选课系统,学生可以在选该学期想学习的课程,每个课程都有它相对应的课时,学费和难易度,每个老师都有他自己的姓名,爱好,姓别,专长,老师的功能是负责授课;每个学生也有他的姓名,爱好,姓别和技能评分,学生的功能是负责上课; 当学生们选完课之后呢,因为每个课程都有学费,所以呢,当老师完整了他任务的时候,可以有收入,相反学生便有同等的支出,程序运行之后可以打印老师X 在该学期的收入和学生X 在该学期的支出。
管理员:
创建老师:姓名、性别、年龄、资产
创建课程:课程名称、上课时间、课时费、关联老师
学生:用户名、密码、性别、年龄、选课列表[]、上课记录{课程1:【di,a,】}
- 管理员设置课程信息和老师信息
- 老师上课获得课时费
- 学生上课,学到“上课内容”
- 学生可自选课程
- 学生可查看已选课程和上课记录
- 学生可评价老师,差评老师要扣款
- 使用pickle
pickle 模块将对象转化为文件保存在磁盘上,在需要的时候再读取并还原,pickle 介绍和操作可以参考这里
思路
管理员
- 创建老师 (名字、爱好、资产)
![]() class Teacher
class Teacherclass Teacher: def __init__(self,favor,name,age): self.favor = favour self.name = name self.age = age self.asset = 0 def teaching_event(self): self.asset = asset - 1 def gain(self,value): self.asset += value obj1 = Teacher() # Teacher类型 obj2 = Teacher() # Teacher类型 obj3 = Teacher() # Teacher类型 obj4 = Teacher() # Teacher类型 lst = [obj1,obj2,obj3,obj4] pickle.dump(lst)
- 创建课程
- 课時类
- 课時名
- 课时费
- 负责老师 = li[0]
- 功能
- 上課
- 返回给学生学习的内容
- 负责老师掙錢li[0].gain(课时费)
- 课程对象
- 上課
学生
- 類
- 功能: 選課
- 上課:生物課
- 课程对象.对象
[知识点:pickle 模块、类的封装]
Username >> janice Password >> janice123 Login Successfully. Welcome to the IT Academy HI JANICE [Student], PLEASE SELECT ONE ACTION [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 4 -------------YOUR COURSE INFORMATION-------------- Class Name: English Date: Sat Total hours: 10 Price: 1000 -------------YOUR ACCOUNT INFORMATION------------- Total Course taken: 1 Name: Janice Gender: Female Balance: 1000 [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 3 --------------ALL COURSE INFORMATION-------------- Class Name: Programming Date: Fri Total hours: 8 Price: 800 Class Name: English Date: Sat Total hours: 10 Price: 1000 Class Name: Sales and Marketing Date: Sat Total hours: 15 Price: 1500 Class Name: Arts and Design Date: Sat Total hours: 20 Price: 2000 [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 1 ------------------Pick a course------------------- c1. Programming c4. English c2. Sales and Marketing c3. Arts and Design Which class do you want to try? Please pick one >> c1 You have selected c1 [c=confirmed][q=quit] Confirmed to take the course? >> c Programming A new course added to your account [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 4 -------------YOUR COURSE INFORMATION-------------- Class Name: English Date: Sat Total hours: 10 Price: 1000 Class Name: Programming Date: Fri Total hours: 8 Price: 800 -------------YOUR ACCOUNT INFORMATION------------- Total Course taken: 2 Name: Janice Gender: Female Balance: 1800 [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 2 Attendng a class..... [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 2 Attendng a class..... [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 2 Attendng a class..... [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >> 4 -------------YOUR COURSE INFORMATION-------------- Class Name: English Date: Sat Total hours: 10 Price: 1000 Class Name: Programming Date: Fri Total hours: 8 Price: 800 -------------YOUR ACCOUNT INFORMATION------------- Total Course taken: 2 Name: Janice Gender: Female Balance: 1500 [q=quit] 1.选课; 2.上课; 3.查看课程信息; 4.查看个人课程信息 >>
參考資料
银角大王:Python开发【第六篇】:模块
银角大王:Python 面向对象(初级篇)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号