
斯坦福机器学习实现与分析之三(逻辑回归)
前一节讲线性回归已提过,回归问题的根本目的在于预测。直观上看,线性回归训练与预测的值域都为实数域R,而逻辑回归训练样本值域为{0,1},预测的值域则是(0,1),也就是说逻辑回归用于分类,其结果能给出样本属于某个类的概率。逻辑回归逻辑回归作为机器学习中的一个简单而有效的算法,其应用之广泛已超出我们的想象。
逻辑回归算法推导
首先,确定逻辑回归函数模型,如下:
\(\begin{aligned} h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}} \end{aligned}\)
可以看出该函数定义域为实数域R,值域为(0,1)。这里关于选择该函数的原因暂不讨论,待后面广义线性模型一节再讲。先看看该函数的一个特性,令
\(\begin{aligned} g(z)=\frac{1}{1+e^{-z}} \end{aligned}\)
则
\( \begin{aligned} g^{'}(z)&=\frac{1}{(1+e^{-z})^2}{e^{-z}}\\&={\frac{1}{1+e^{-z}}}{\frac{e^{-z}}{1+e^{-z}}}\\&=g(z)(1-g(z)) \end{aligned} \)
此函数应用甚广,神经网络的激励函数,独立成分分析中源信号分布都是使用该函数的。
假设2个类分别为0和1,回归结果\( h_\theta(x) \)表示样本属于类1的概率,因此样本属于类0的概率则为\( 1- h_\theta(x) \),则有
\( P(y=1|x,\theta)=h_\theta(x) \)
\( P(y=0|x,\theta)=1-h_\theta(x) \)
实际上就是一个两点分布,可写为
\( P(y|x,\theta)=h_\theta(x)^y(1-h_\theta(x))^{1-y} \)
从而给定样本集,其对数似然函数为:
\(\begin{aligned} l(\theta)&=log(L(\theta))\\&=log(\prod_{i=1}^m{h_\theta(x^{(i)})^{y^{(i)}}(1-h_\theta(x^{(i)}))^{1-y^{(i)}}})\\&=\sum_{i=1}^m{(y^{(i)}log(h_\theta(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)})))} \end{aligned}\)
最大化该对数似然函数,也采用梯度下降法,下面对其求导。
首先有
\(\begin{aligned} \frac{\partial logh_\theta(x^{(i)})}{\partial\theta_j}&=\frac{\partial log(g(\theta^T x^{(i)}))}{\partial\theta_j}\\&=\frac{1}{g(\theta^T x^{(i)})}{ g(\theta^T x^{(i)})) (1-g(\theta^T x^{(i)}))x_j^{(i)}}\\&=(1- g(\theta^T x^{(i)}))) x_j^{(i)}\\&=(1-h_\theta(x^{(i)}))x_j^{(i)} \end{aligned}\)
类似可得
\(\begin{aligned} \frac{\partial(1-logh_\theta(x^{(i)}))}{\partial\theta_j}=-h_\theta(x^{(i)})x_j^{(i)} \end{aligned}\)
因此有:
\(\begin{aligned} \frac{\partial l(\theta)}{\partial\theta_j}&=\sum_{i=1}^m{(y^{(i)}(1-h_\theta(x^{(i)}))x_j^{(i)}+(1-y^{(i)})(-h_\theta(x^{(i)})x_j^{(i)}))}\\&=\sum_{i=1}^m{(y^{(i)}-h_\theta(x^{(i)}))x_j^{(i)}} \end{aligned}\)
由于这里是最大化对数似然函数,故迭代规则为:
\(\begin{aligned} \theta_j=\theta_j+\alpha\frac{\partial l(\theta)}{\partial\theta_j} \end{aligned}\)
同样地,这里也有批量梯度下降和随机梯度下降两种实现方法。
算法实现
仔细对比,该迭代公式与线性回归是一样的,但其中的区别在于\(h_\theta(x^{(i)}) \)这个函数是不同的。因此,二者的算法实现可重用代码,只需更改\(h_\theta(x^{(i)}) \)的实现即可。
顺便提一下,在线性回归和逻辑回归的推导中, \(\theta^Tx\)中的常数项为\(\theta_0\),但由于matlab数组下标从1开始,因此程序中常数项\(\theta_{n}\)其中\(x\)为\(n-1\)维的。
具体代码如下,可兼容线性回归与逻辑回归,通过参数传入切换即可:


1 %返回值Theta为回归结果 2 %IterInfo为迭代的中间过程信息,用于调试,查看 3 %Sample为训练样本,每一行为一个样本,每个样本最后一个为Label值 4 %Type为回归算法类型,'Linear'--线性回归, 'Logistic'--逻辑回归 5 %BatchSize为每次批量迭代的样本数 6 function [Theta, IterInfo]=Regression(Sample, Type, BatchSize) 7 if strcmpi(Type, 'Linear') 8 fun = @Linear; 9 elseif strcmpi(Type, 'Logistic') 10 fun = @Sigmod; 11 else 12 return; 13 end 14 [m, n] = size(Sample); %m个样本,每个n维 15 Y = Sample(:, end); %label 16 X = [Sample(:,1:end-1), ones(m,1)]';%x加入常数项1,并转换为每列表示1个样本 17 18 %将样本顺序随机打乱 19 ord = randperm(m); 20 X = X(:, ord); 21 Y = Y(ord); 22 23 BatchSize = min(m, BatchSize); 24 Theta = zeros(n, 1); 25 Theta0= Theta; 26 Alpha = 1e-2 * ones(n, 1); 27 StartID = 1; 28 29 IterInfo.Grad = []; 30 IterInfo.Theta = [Theta]; 31 32 %梯度下降,迭代求解 33 MaxIterTime = 5000; 34 for i = 1:MaxIterTime 35 EndID = StartID + BatchSize; 36 if(EndID > m) 37 TX = [X(:, StartID:m) X(:, 1:EndID-m)]; 38 TY = [Y(StartID:m); Y(1:EndID-m)]; 39 else 40 TX = X(:, StartID:EndID); 41 TY = Y(StartID:EndID); 42 end 43 44 Grad = CalcGrad(TX, TY, Theta, fun); 45 46 Theta = Theta + Alpha .* Grad; 47 48 %记录中间结果 49 IterInfo.Grad = [IterInfo.Grad Grad]; 50 IterInfo.Theta = [IterInfo.Theta Theta]; 51 52 %迭代收敛检验 53 Delta = Theta - Theta0; 54 if(Delta' * Delta < 1e-10) 55 break; 56 end 57 58 Theta0 = Theta; 59 StartID = EndID + 1; 60 StartID = mod(StartID, m) + 1; 61 end 62 63 IterInfo.Time = i; 64 end 65 66 %梯度计算 67 function Grad = CalcGrad(X, Y, Theta, fun) 68 D = 0; 69 for i = 1:size(X,2) 70 h = fun(Theta, X(:,i)); 71 G = (Y(i) - h) * X(:,i); 72 D = D + G; 73 end 74 Grad = D / size(X,2); 75 end 76 77 %线性函数 78 function y = Linear(Theta, x) 79 y = Theta' * x; 80 end 81 82 %逻辑回归函数 83 function y = Sigmod(Theta, x) 84 t = Theta' * x; 85 y = 1 / (1 + exp(-t)); 86 end
测试代码中绘制结果部分会有所不同,首先生成测试样本数据的代码如下:
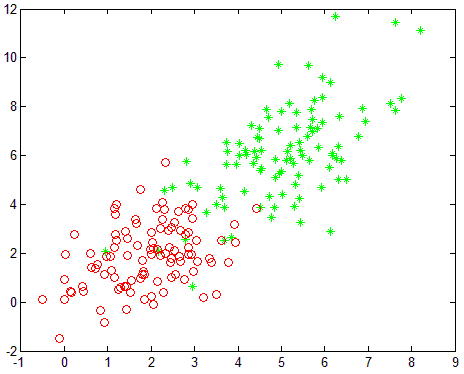
1 N = 100; 2 %生成第0类数据 3 mu = [2 2]; 4 Sigma = [1 .5; .5 2]; R = chol(Sigma); 5 x = repmat(mu,N,1) + randn(N,2)*R; 6 y = zeros(N,1); 7 Sample = [x y]; 8 figure, plot(x(:,1),x(:,2),'ro'); hold on 9 %生成第1类数据 10 mu = [5 6]; 11 Sigma = [2 1.5; 1.5 3]; R = chol(Sigma); 12 x = repmat(mu,N,1) + randn(N,2)*R; 13 y = ones(N,1); 14 Sample = [Sample;x y]; 15 plot(x(:,1),x(:,2),'g*'); 16 save('log_data.mat', 'Sample')
生成的两类数据为二维平面上服从不同高斯分布的点,如图:
测试代码调用比较简单,后面部分为绘制训练结果。
1 function test 2 %回归 3 load('log_data.mat'); 4 5 BatchSize = 20; 6 [Theta, IterInfo] = Regression(Sample, 'Logistic', BatchSize) 7 8 %显示结果,以下代码不通用,样本维数增加时显示不可用 9 figure, 10 idx = find(Sample(:,3)==1); 11 plot(Sample(idx,1), Sample(idx,2), 'g*');hold on 12 idx = find(Sample(:,3)==0); 13 plot(Sample(idx,1), Sample(idx,2), 'ro');hold on 14 15 %显示回归训练的分割线 16 x = min(Sample(:,1)):1:max(Sample(:,1)); 17 y = -(Theta(1) * x + Theta(3))/Theta(2); 18 plot(x,y,'b'); 19 20 %显示对数似然函数的变化 21 for i = 1:size(IterInfo.Theta,2) 22 l(i) = L(Sample, IterInfo.Theta(:,i)); 23 end 24 figure,plot(l,'b'); 25 end 26 27 %似然函数计算 28 function l = L(Sample, Theta) 29 [m, n] = size(Sample); %m个样本,每个n维 30 Y = Sample(:, end); %label 31 X = [Sample(:,1:end-1), ones(m,1)]';%x加入常数项1,并转换为每列表示1个样本 32 l = 0; 33 for k = 1:m 34 h = 1 / (1 + eps(-Theta' * X(:,k))); 35 z = Y(k) * log(h + eps) + (1 - Y(k)) * log(1 - h + eps); 36 l = l + z; 37 end 38 end
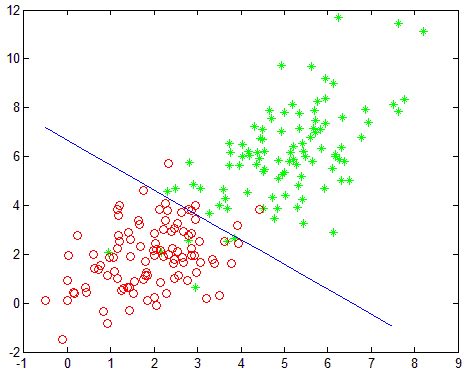
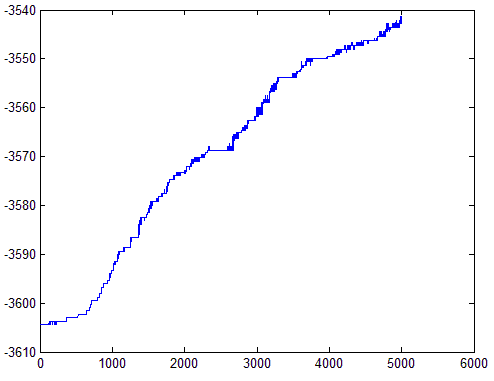
实验结果如下,左红绿点分别为两类的训练样本点,图中蓝色直线即是逻辑回归训练处出的分割线。右图为对数似然函数随着迭代过程的变化。
算法分析
1.关于BatchSize的影响与线性回归相同。但在此段代码中,增加了将样本顺序打乱的操作,在逻辑回归中,若正负样本未交叉排列,则使用随机梯度下降时可能导致快速收敛到非最佳解。
2.从逻辑回归公式以及上面实验结果可以看到,逻辑回归只能处理线性可分的分类,对于非线性可分问题,需自行转换为线性可分问题来处理。
3.上述逻辑回归算法推导与线性回归推导似乎完全不同,但实质上线性回归也可使用类似的最大似然估计来推导,不过对于其值y的假设为高斯分布而已。另外最大似然估计在ML的很多算法中都在使用,需要特别关注下。

