C++U5-11-特殊二叉树
学习目标

完全二叉树:二又树拥有的性质,在完全二叉树中都拥有

性质

练习1

练习2
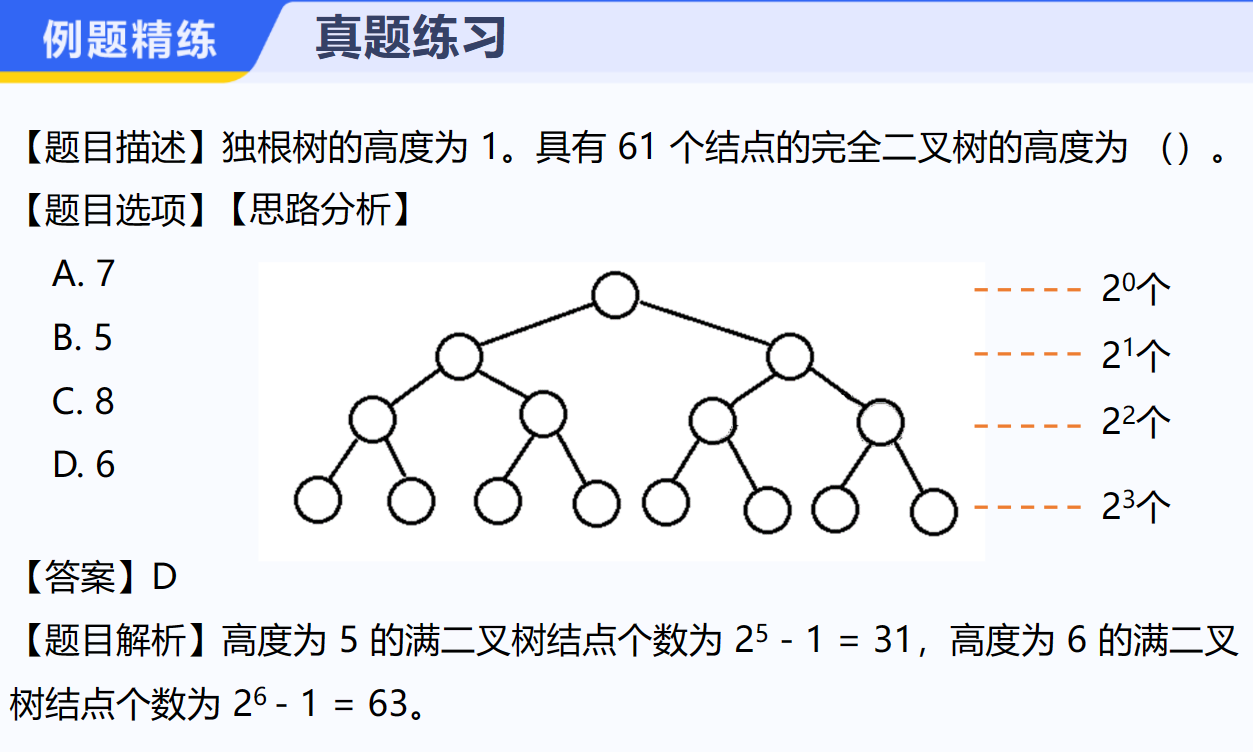
练习3


编程题:[完全二叉树的叶子结点]




【算法分析】 递归,前序遍历输出。 【参考代码】 #include <iostream> using namespace std; const int SIZE = 1010; struct node { int left, right, value; }; node a[SIZE]; // 定义一个数组用于存储树的结点信息 int n; // 结点数量 // 递归函数,用于遍历树并输出叶子结点的值 void is_tree(int root) { // 当左孩子和右孩子都不存在时,说明是叶子结点,直接输出其值并返回 if (a[root].left == 0 && a[root].right == 0) { cout << a[root].value << " "; return; } // 依次递归遍历左子树和右子树 is_tree(a[root].left); is_tree(a[root].right); } int main() { cin >> n; // 输入结点数量 for (int i = 1; i <= n; i++) { cin >> a[i].value >> a[i].left >> a[i].right; // 输入每个结点的值以及左右孩子的索引 } is_tree(1); // 从根结点开始遍历树 return 0; } 这段代码定义了一个结构体 node 来表示树的结点。每个结点有一个值(value)以及左孩子(left)和右孩子(right)的索引。 在 is_tree 函数中,通过递归的方式遍历树。如果当前结点的左孩子和右孩子都不存在,即为叶子结点,则直接输出该结点的值。否则,继续递归遍历左子树和右子树。 在 main 函数中,首先输入结点数量(n),然后使用一个循环输入每个结点的值及其左右孩子的索引。最后,调用 is_tree 函数从根结点开始遍历树,并输出叶子结点的值。 希望这些注释能够帮助理解代码的功能和执行流程!
二叉搜索树








程序阅读题







二叉搜索树总结

哈夫曼树
哈夫曼树(Huffman Tree)是一种数据压缩算法,它的应用场景广泛,包括以下几个方面:
-
数据压缩:哈夫曼树被广泛应用于数据压缩领域。通过构建哈夫曼树并生成相应的哈夫曼编码,可以将原始数据中出现频率较高的字符用较短的编码表示,从而实现对数据的有效压缩。这种压缩方式在文本、图像、音频等数据文件的存储和传输中都得到了广泛应用。
-
网络传输:由于哈夫曼编码能够将数据进行高效压缩,它在网络传输中也有重要应用。通过将数据使用哈夫曼编码进行压缩,可以减少数据的传输量,提高传输效率,节省带宽。特别是在低带宽网络环境下,如移动通信网络和互联网传输中,哈夫曼编码能够显著提升传输速度。
-
文件存储:哈夫曼树的应用不仅局限于数据传输,还可以用于文件的存储。在存储大量文本文件时,使用哈夫曼编码进行压缩可以大大减少存储空间的占用。这在对大规模文本数据进行备份、归档或者存储容量受限的场景下非常有用。
-
数据通信:哈夫曼树的高效压缩特性使得它在数据通信领域也有广泛应用。例如,通过在传感器网络中使用哈夫曼编码对传感器数据进行压缩,可以减少数据的传输和存储需求,从而延长传感器网络的寿命。
总之,哈夫曼树的应用范围非常广泛,适用于需要对数据进行高效压缩和解压缩的场景,包括数据压缩、网络传输、文件存储和数据通信等领域。
哈夫曼树(Huffman Tree)是一种用于数据压缩的二叉树结构,它具有以下重要概念:
-
频率:指字符(或符号)在待编码文本中出现的次数。在哈夫曼编码中,频率决定了字符被赋予的编码长度。
-
权值:与频率类似,表示字符在哈夫曼树中的权重。通常使用字符的频率作为其权值。
-
叶子节点(Leaf Node):表示原始字符的节点,在哈夫曼树中没有子节点。
-
内部节点(Internal Node):位于哈夫曼树内部的节点,它们没有对应的字符,仅用于构造树结构。
-
根节点(Root Node):哈夫曼树的顶部节点,没有父节点。
-
编码(Code):将字符映射到二进制序列的过程。在哈夫曼树中,每个字符都有独特的编码,该编码由从根节点到叶子节点的路径上的左右分支决定。
-
哈夫曼编码(Huffman Code):是通过哈夫曼树生成的用于数据压缩的编码方式。它是一种变长编码,即不同字符可能拥有不同长度的二进制编码。
-
最优编码:哈夫曼树生成的编码具有最小平均编码长度,从而实现了最高的压缩效率。
-
压缩比(Compression Ratio):用来衡量数据压缩效果的指标。压缩比等于未压缩数据大小与压缩后数据大小的比值。
哈夫曼树通过根据字符频率构建最优二叉树,使得出现频率较高的字符具有较短的编码,而出现频率较低的字符具有较长的编码。这种变长编码可以有效地减少整体编码的长度,从而实现数据的压缩和解压缩。
使用哈夫曼树和哈夫曼编码,可以实现对文本、图像、音频等数据的高效压缩和传输。






构建哈夫曼树的流程可以用以下直白的话术来解释:
-
首先,我们需要统计待编码文本中每个字符出现的次数或频率。这样我们就知道哪些字符出现得更频繁。
-
接下来,我们把每个字符都看作是一个独立的叶子节点,并赋予它们对应的权重,即字符的频率。
-
然后,我们开始构建哈夫曼树。我们会使用一个优先队列,里面存放着所有的叶子节点。我们每次从队列中选取权重最小的两个节点,并创建一个新的父节点,将它们作为左右孩子,同时设置新节点的权重为左右孩子权重之和。
-
接着,我们将新创建的父节点放回优先队列,并继续选择权重最小的两个节点进行合并。我们不断重复这个过程,直到队列中只剩下一个节点,即根节点。
-
在构建哈夫曼树的同时,我们记录下每个叶子节点到根节点的路径。如果向左走,我们记为0;如果向右走,我们记为1。这样,我们就可以得到每个字符的对应二进制编码。
-
最后,我们将原始文本中的每个字符都替换为对应的哈夫曼编码。这样,我们就完成了对原始数据的压缩。
通过构建哈夫曼树,我们可以实现最优的编码方式,让出现频率较高的字符获得较短的编码,从而有效地减小了数据的存储空间和传输带宽。在解压时,我们使用哈夫曼树将二进制编码逐个映射回原始字符,恢复出原始的数据。
如果两个字符的权重非常接近,构建哈夫曼树时可能会有多种不同的选择。在这种情况下,可以采取以下策略之一:
-
随机选择:当权重接近时,可以随机选择其中一个字符作为左子节点,另一个字符作为右子节点,以减少树的偏倚。
-
固定规则:可以制定一些固定的规则来处理权重接近的情况。例如,可以根据字符的字母顺序或者其他特定规则来决定它们的位置。
-
结合频率和顺序:除了考虑权重外,还可以考虑字符出现的顺序。如果两个字符权重相等且紧邻出现,可以将它们放在同一层级或次级别。
无论选择哪种策略,最终生成的哈夫曼编码会在压缩效率上产生微小的差异。然而,在实际应用中,即使权重接近,哈夫曼编码仍然能够提供较高的压缩效果。这是因为哈夫曼编码的主要优势在于对频率较高的字符进行较短的编码,而不完全依赖于权重的差异。
本节课作业讲解:
链接:https://pan.baidu.com/s/1N23Td-qUo-cqQtyJJjYajQ?pwd=ob7u
提取码:ob7u
