一文了解Nordic边缘AI方案
本文以手势识别遥控器为例,介绍如何使用 Nordic Edge AI 方案,从零开始完成数据采集、模型训练到 MCU 部署的完整流程。
1. Nordic Edge AI 简介
什么是 AI 和机器学习?
AI(人工智能) 是一个很大的概念,泛指让计算机完成需要人类智能才能完成的任务。而机器学习(Machine Learning) 是 AI 的一个重要子集,它的核心思想是:不给计算机编写明确的规则,而是让它从数据中自动学习规律。
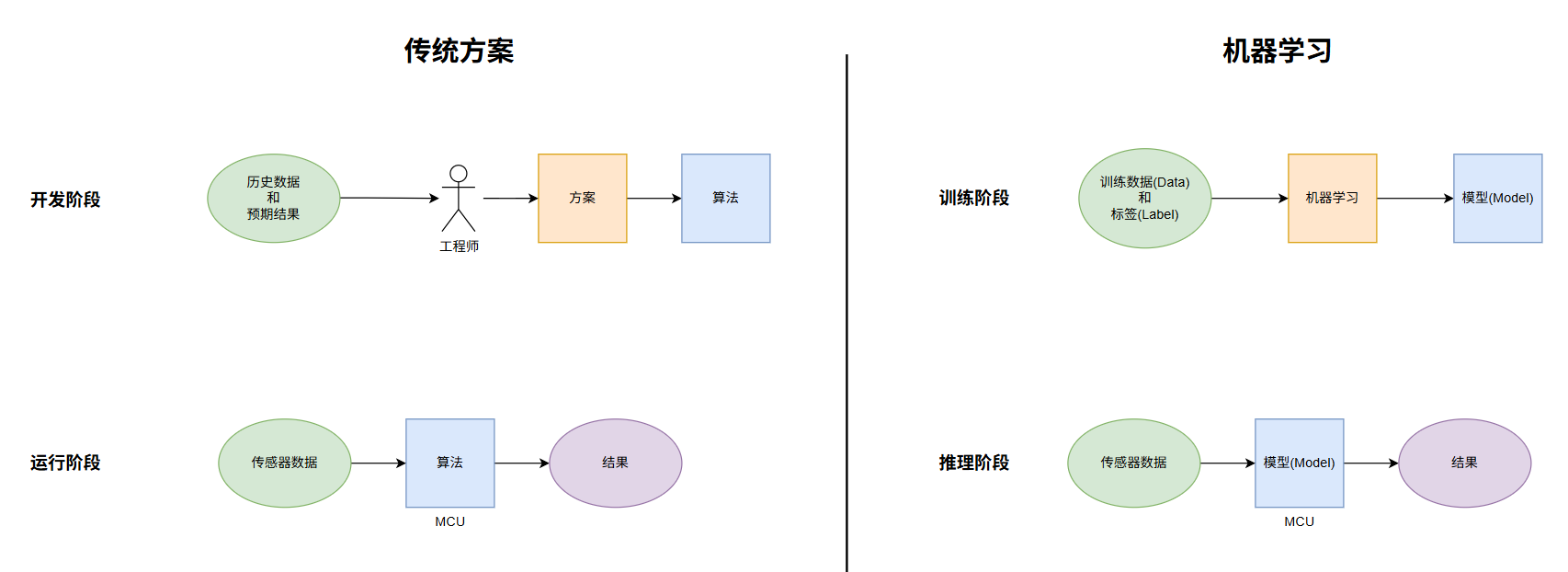
以手势识别为例:
- 传统方法:工程师手动设计规则,例如"当 X 轴速度先增大再减小时,判断为向右滑动"。这种方法需要大量人工调参,且很难覆盖所有情况。
- 机器学习方法:收集大量带标签的传感器数据("这段数据是向右滑动"),让算法自动从中学习特征,训练出一个可以识别手势的模型(Model)。
机器学习中最常见的一类是神经网络(Neural Network),它由多层"神经元"组成,能够学习复杂的非线性特征。
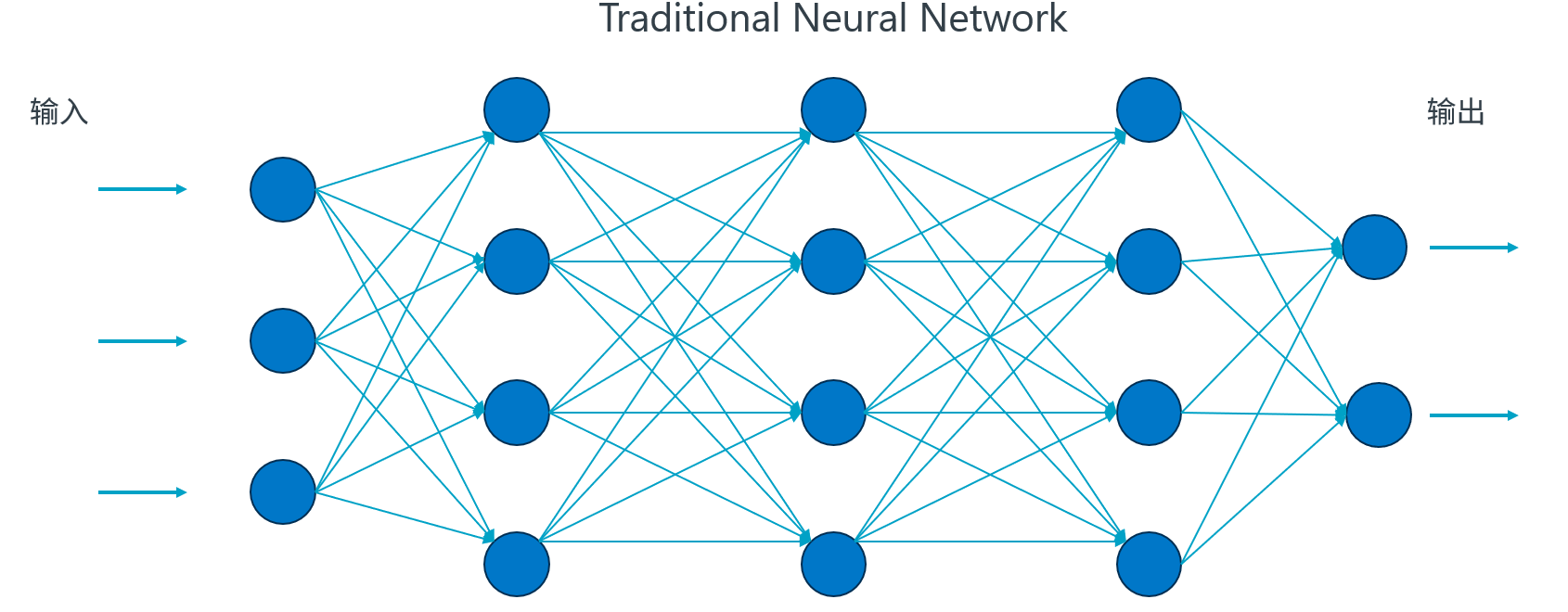
机器学习模型的运行
在推理阶段,神经网络的输入就是传感器数据(视为一组向量),通过线性运算(矩阵乘法、偏置)与非线性变换(激活函数)得到下一层的神经元数值。
以上示意图为神经网络中线性代数运算部分的可视化:
每一层神经元都是一组中间变量,暂时存储运算结果。图中相邻神经元之间的连线代表权重(Weight),相邻两层之间所有的连线数值构成了权重矩阵。
实际上,每一层神经元向量(x)到下一层神经元向量(y)之间不只是线性计算:
W:上文介绍的权重矩阵,代表上一层对下一层的影响力。
b:偏置向量,代表神经元的固有偏好,确保模型在无输入或低输入时也能灵活调整。
σ:激活函数,常见的如ReLU,tanh等。如果没有激活函数,再多层权重矩阵和偏置向量都只会等价成一次线性计算。有了激活函数,才能让模型拟合现实中复杂的非线性问题。
权重和偏置构成了模型的核心参数,存放在固件的只读数据区。
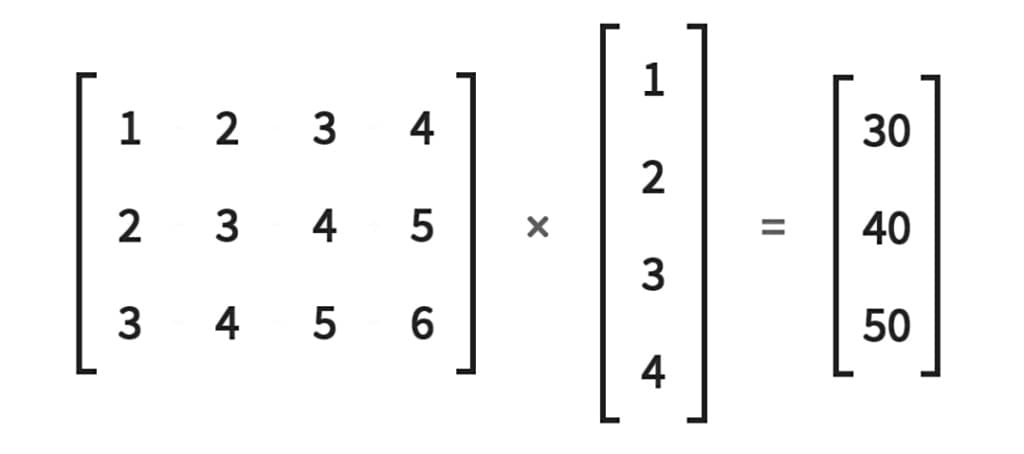
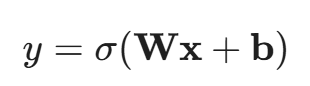
如果你在训练时要识别的手势有8种,那么输出就是一个长度为8的向量,经过归一化处理后,对应这8种手势的概率值(0到1之间),数值最高的即为识别结果。
机器学习模型的训练
所谓模型的训练,就是在选择好模型的层数、精度、激活函数等超参数(Hyperparameters)之后,从零开始迭代出整个模型中所有的权重矩阵和偏置。
一般称工程师选择的参数为“超参数”,用于区分模型自己的参数。
因此,我们需要预先准备好大量的已经标注的数据(Labeled data)。数据(Data)和标签(Label)就像作业的题目和答案:模型在训练过程中不断尝试给出预测,并根据与标准答案的偏差来微调内部权重,直到输入数据能高概率地指向正确标签。
训练数据的量级和多样性直接决定了模型的“见识”和准确度。
实际上,我们不会把所有数据都投入训练。我们会预留一部分数据作为测试集,不参与训练过程。训练结束后,用测试集来检验模型的真实水平。这能有效发现模型是否出现了过拟合(Overfitting)——即模型只是死记硬背住了训练题目的答案,却并没有真正学会解题的逻辑(泛化能力差)。
在嵌入式端,我们往往在训练完成后还会进行量化(Quantization),把普通的 32 位浮点数(FP32)权重压缩成 8 位整数(INT8)。这样模型虽然损失了一点点精度,但在 MCU上的运行速度会大幅提升,功耗也会显著降低。
如果你想更详细地了解机器学习的数学本质,可以参考这个视频:《【3b1b】深度学习之神经网络的结构 Part 1 ver 2.》
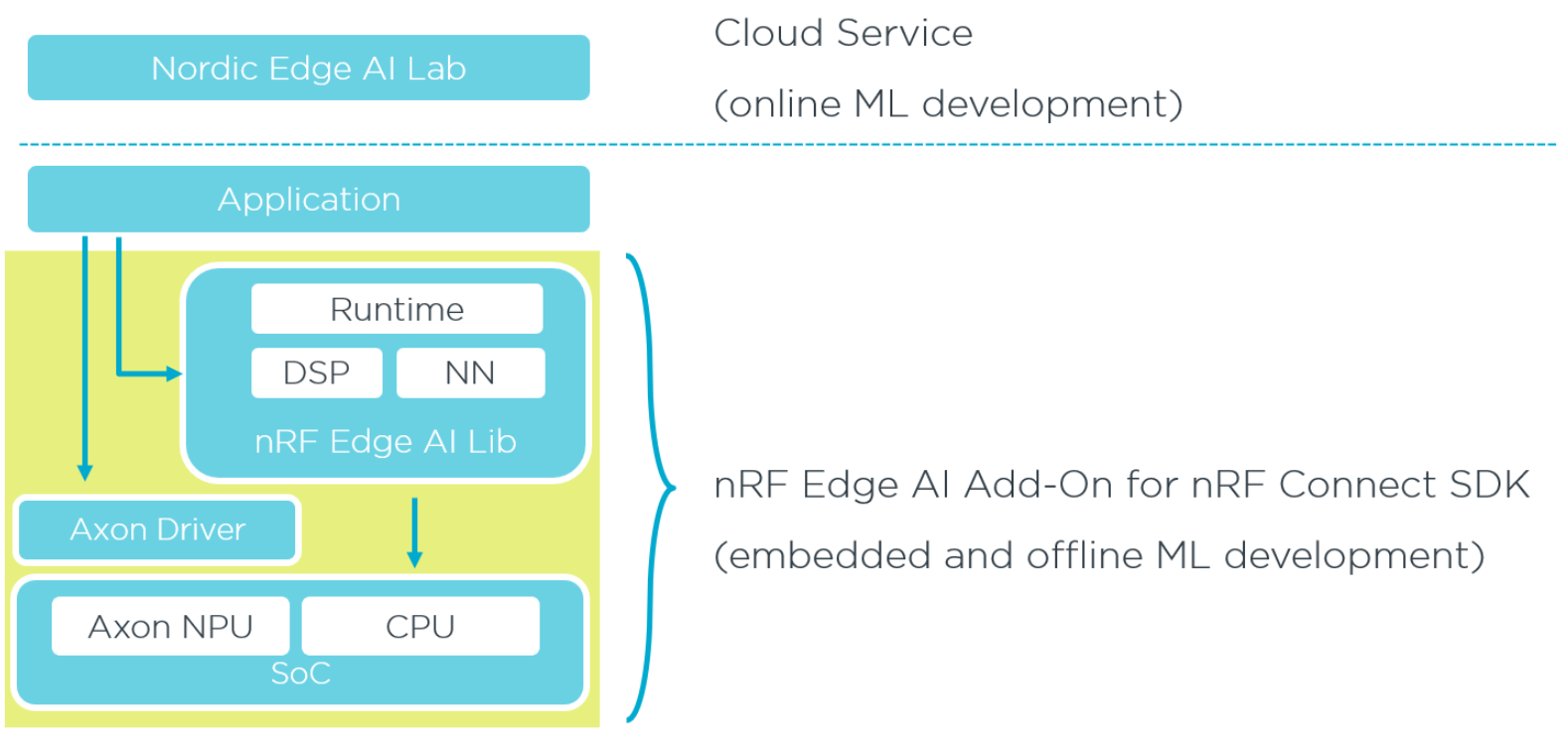
Nordic 提供什么?
Nordic 的 Edge AI 方案专注于机器学习在嵌入式设备(MCU)上的部署,也就是所谓的边缘 AI(Edge AI),主要有两大方案:
- Neuton 神经网络框架:让模型高效率地运行在Arm Cortex-M 系列CPU上。适合处理运动传感器、光电传感器等时间序列数据。
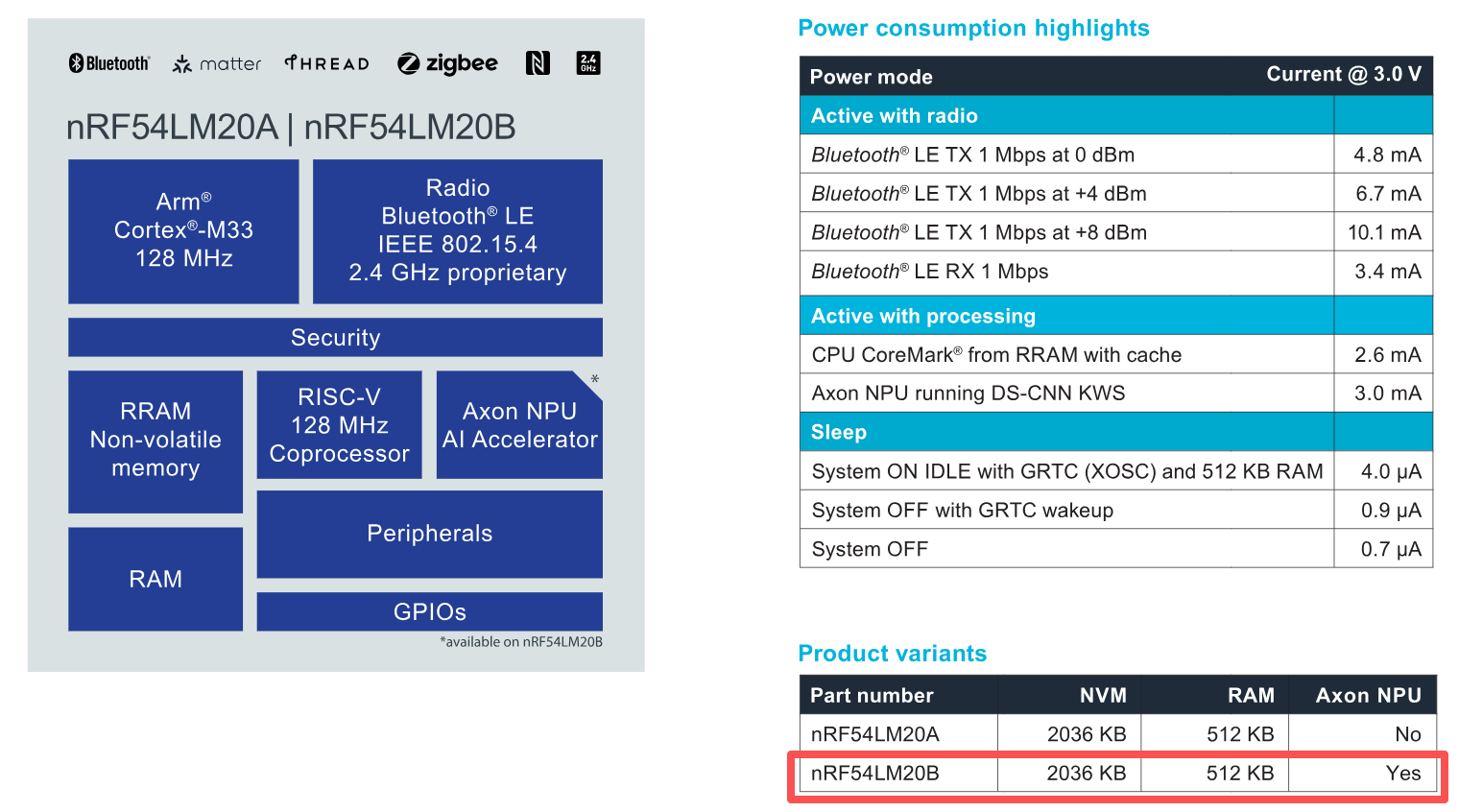
- Axon NPU:Nordic 部分芯片(如 nRF54LM20B)内置了 Axon NPU 硬件加速器,可进一步提升模型推理速度和能效。适合处理音频流、小型视频流等较高数据量的时间序列数据。
CPU方案:Neuton神经网络框架
与传统的全连接神经网络不同,Neuton 会从零开始逐个神经元地生长网络结构,自动找到最紧凑的模型,无需手动调节网络层数、学习率等超参数。训练后的模型可以非常小,适合在 Cortex-M 系列 MCU 上部署。
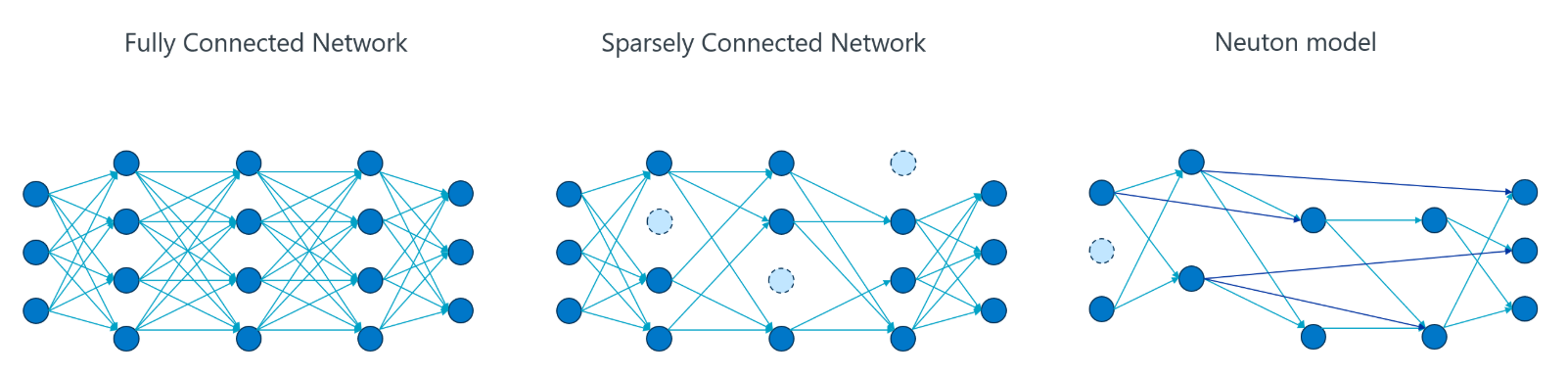
相比于结构冗余的传统全连接网络,Neuton 神经网络有极高的效率:它在生长过程中会自动剔除不重要的神经元与权重,并支持跨层连接。这种特性使得模型不再是死板的层级堆叠,而是一个高度精简、按需连接的稀疏拓扑结构。
Neuton神经网络体积小,功耗低,直接在CPU上运行,支持Nordic目前所有的SoC平台。

NPU方案:Axon NPU
Nordic 部分 SoC,如 nRF54LM20B 支持 Axon NPU 硬件加速单元,可以运行更大的TensorFlow Lite(LiteRT)模型。相比于CPU能提升15倍的速度和10倍的能效。
Axon NPU框图:

- 硬件提供常见的神经网络运算单元(卷积、全连接、加法、池化等),支持8bit量化模型,支持32bit输出。也支持int24 DSP矢量运算,平方根,自然对数和FFT。
- Nordic提供配套编译器和驱动,可以将TensorFlow Lite模型转换为Axon可以运行的模型。
- CPU只需负责初始化NPU,提交推理任务,处理完成中断。NPU有自己的DMA在内存中搬运数据。CPU可在推理期间休眠或处理其他任务。
- 相比于同频率的Cortex-M33,推理速度提升15-17倍,且单次推理功耗极低。
3 V 供电、128 MHz 下:
- KWS(DS‑CNN):4.5 ms,约 3.0 mA,能量约 40.5 µJ
- 视觉唤醒(VWW):14.4 ms,约 2.8 mA,能量约 121 µJ
Axon NPU非常适合做”需要持续听,但不常触发“的功能。如语音关键词唤醒。相关文档请参考:Wake Word Detection
Nordic Edge AI Lab

Nordic Edge AI 是一个在线的模型训练平台(ai.lab.nordicsemi.com),无需本地 GPU 环境,上传 CSV 表格数据集即可自动完成特征提取、模型训练和导出。支持Neuton模型和Axon模型。
文档:Welcome to the Nordic Edge AI Lab
Edge AI Add-on
NCS(nRF Connect SDK)的插件(Add-On),提供完整的手势识别、异常检测等参考应用,以及将训练好的模型集成进固件的工程框架,包含推理引擎,数据预处理等。
文档:Welcome to the Edge AI Add-on for nRF Connect SDK
2. 环境准备
硬件准备
本教程使用 Nordic Thingy:53(基于 nRF5340 SoC)。Thingy:53 内置了加速度计和陀螺仪,非常适合用于手势识别。

例程也支持:
- nRF54L15 TAG
- nRF54LM20DK + nRF Sensor EB


软件环境
每次安装一个nRF Connect SDK Add-on都需要从GitHub拉取一个完整的SDK,对于国内网络不太友好。如果你的网络能稳定访问GitHub,你可以按照Edge AI Add-on的文档 来安装。
标准全量安装方式
拉取Edge AI Add-on 和对应的SDK:
你也可以通过命令行的方式安装:
## 首先通过VS Code打开 nRF Connect命令行,或者通过以下 nrfutil 命令打开nRF Connect 命令行 # Windows nrfutil toolchain-manager launch --ncs-version v3.2.0 --terminal # Linux nrfutil toolchain-manager launch --ncs-version v3.2.0 --shell ## 在合适的目录下创建west工作区并拉取 west init -m "https://github.com/nrfconnect/sdk-edge-ai" --mr v2.0.0

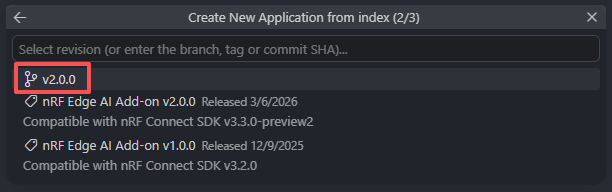

本文在这里提供一个方案,可以直接在本地已经安装的NCS的基础上,增量拉取Nordic Edge AI Add-on,成功率会大大提高:
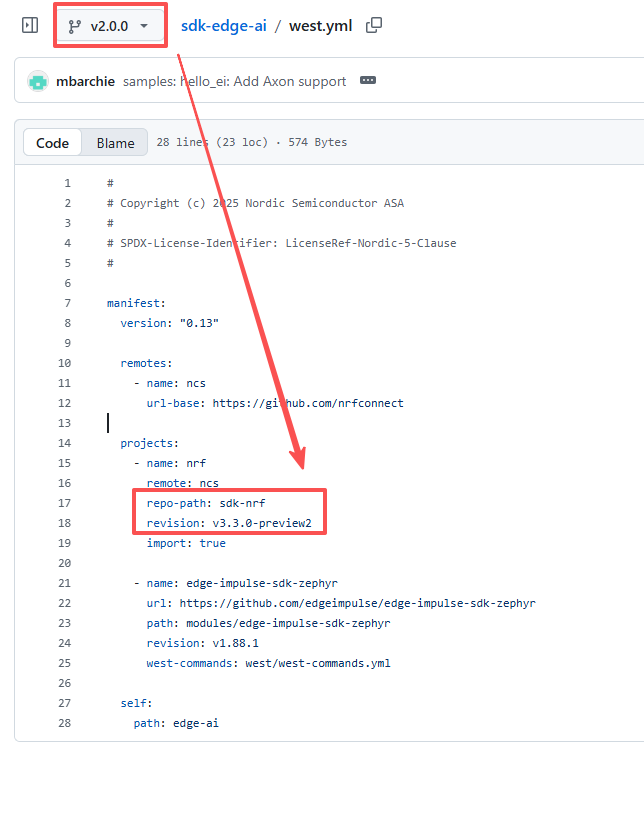
根据 Nordic Edge AI的west配置,我们目前需要NCS v3.3.0-preview2:
以下博客介绍了国内镜像服务器加速下载NCS的方法,我们去下载目前和v3.3.0-preview2最接近的正式版 v3.2.4:
根据NCS根目录下.west/config文件下的配置,我们可以看到NCS原本的manifest是nrf仓库:
[manifest]
path = nrf
file = west.yml
[zephyr]
base = zephyr
我们只需要把 manifest 切换成https://github.com/nrfconnect/sdk-edge-ai",再更新west工作区,即可增量拉取:
## 首先通过VS Code打开 nRF Connect命令行,或者通过以下nrfutil命令打开nRF Connect 命令行
# Windows
nrfutil toolchain-manager launch --ncs-version v3.2.4 -- powershell
# Linux
nrfutil toolchain-manager launch --ncs-version v3.2.4 --shell
## 拉取Nordic Edge AI SDK仓库
cd D:/ncs/v3.2.4
git clone -b v2.0.0 https://github.com/nrfconnect/sdk-edge-ai edge-ai
# 把manifest切换成Nordic Edge AI Add-on
west config manifest.path edge-ai
# 拉取完整工作区,如果由于网络问题拉取失败,重复执行此命令直到不报错
west update
## 拉取完毕后,可以把v3.2.4文件夹重命名为其他名称,例如edge-ai-sdk,以和标准的NCS v3.2.4做区分
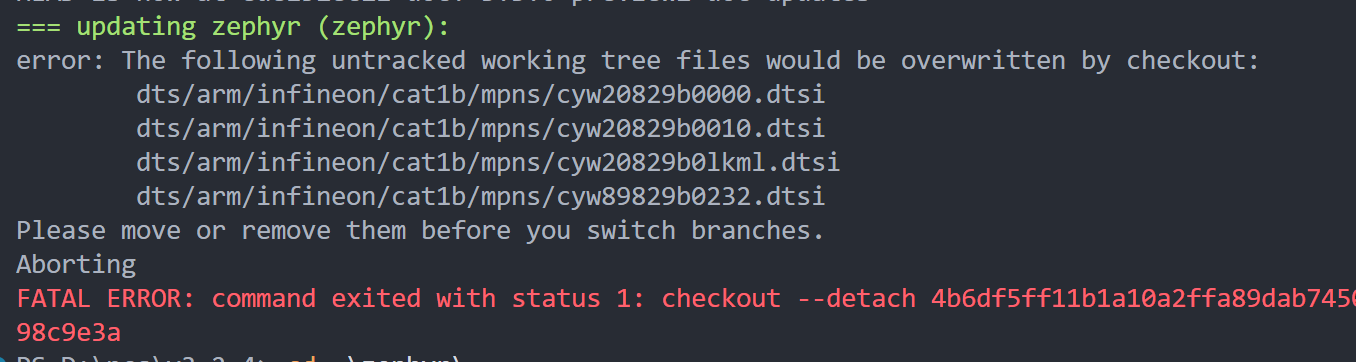
可能你在west update时会遇到一些其他报错:
这是因为Windows的NTFS文件系统是不区分大小写的。这些文件名在windows里是大写,但是git仓库中只记录了小写的,于是认为大写的文件是新的文件,在git checkout的时候报警不让更新。
可以在zephyr仓库目录下单独执行
git config core.ignorecase true来忽略。如果其他仓库也有这个问题,单独执行这个命令即可。
3.数据采集与标记
这一步需要用户手动完成,目标是得到一个格式规范的 CSV 数据集,用于后续的模型训练。
如果你没有这个硬件,或者不想花时间自己采集数据。Nordic也提供了测试用的数据集,可以跳过这一章节,参考后续内容。
编译并烧录数据采集固件
Edge AI Add-on 中提供了 edge-ai/applications/gesture_recognition 参考工程。在烧录之前,需要开启数据采集模式。
你可以在edge-ai\applications\gesture_recognition\configuration\thingy53_nrf5340_cpuapp\中,拷贝一份prj.conf,命名为prj_dc.conf,增加以下内容:
CONFIG_DATA_COLLECTION_MODE=y
CONFIG_BLE_MODE_NONE=y
然后编译:
cd edge-ai\applications\gesture_recognition
west build -d build_dc --pristine --board thingy53/nrf5340/cpuapp -- -DCONF_FILE="prj_dc.conf"
Nordic 的其他开发板支持J-link对外输出,使用标准10pin JTAG接口:

west flash -d build_dc/
使用 nRF Connect for Desktop 中的 Serial Terminal 工具连接设备串口(波特率 115200)。

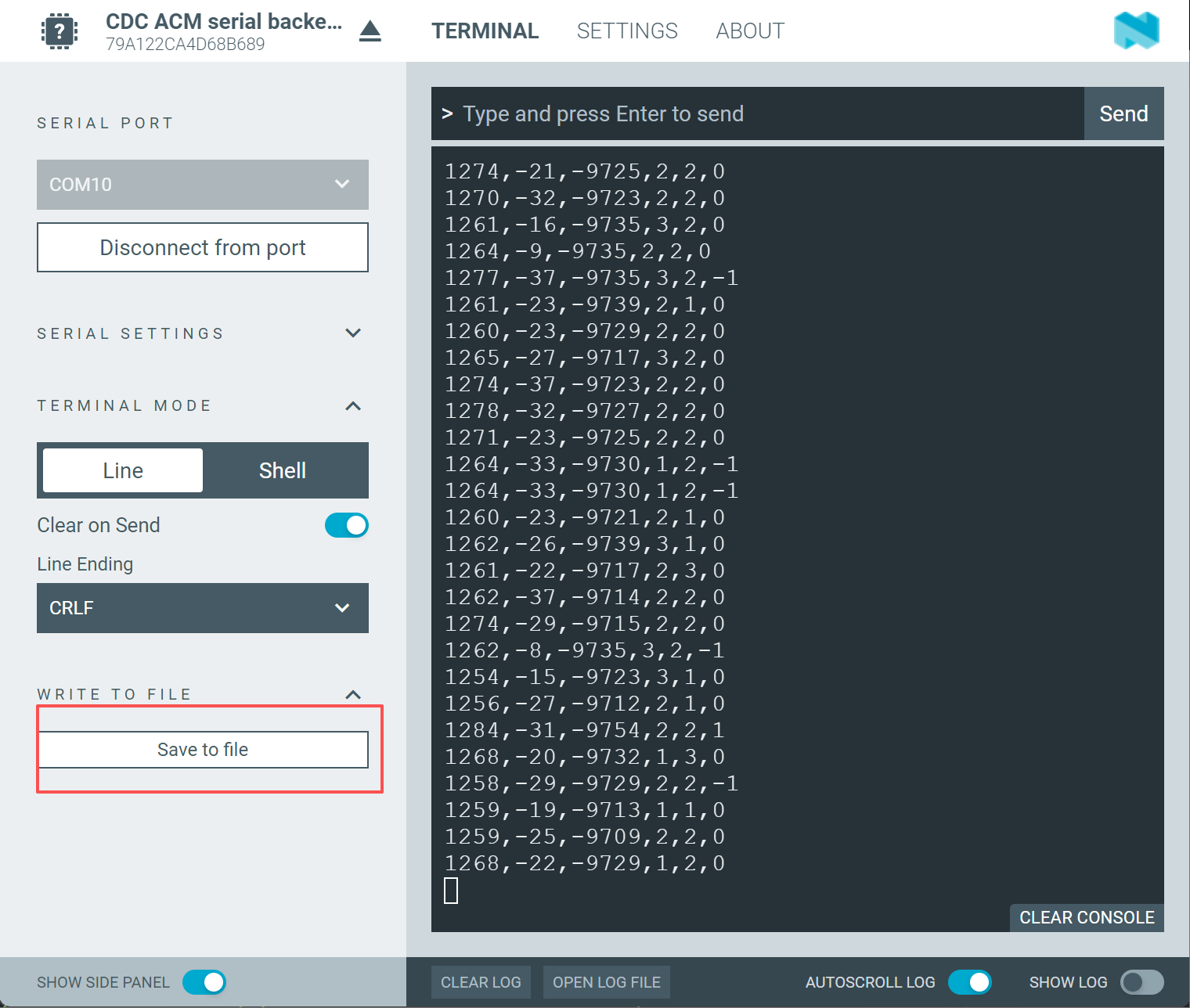
设备会通过串口以 100 Hz 的频率持续输出传感器原始数据,格式如下:
<acc_x>,<acc_y>,<acc_z>,<gyro_x>,<gyro_y>,<gyro_z>
数据为 16 位整数,每行代表一个采样点,采样率默认 100 Hz(即每秒 100 行)。
决定目标动作
在采集数据之前,要决定自己要识别哪些动作。默认动作有6种。
| 动作 | 示意 |
|---|---|
| 右滑 |  |
| 左滑 |  |
| 双击 |  |
| 拇指双击 |  |
| 顺时针旋转 |  |
| 逆时针旋转 |  |
除此之外,还要确保一个初始位置,并将其定义为静止(idle):

再加上其他动作(UNKNOWN),总共有6+1+1=8种动作。
你可以自己设计其他6种动作,来替换原本的动作。因为应用层代码就只定义了6种动作+静止+未知动作。只需要修改模型,就能改为识别你自己定义的其他6种动作。
采集数据
每个手势类别单独保存一个文件。
采集建议:
- 每次采集一个动作前先静止 3-5 秒,保证数据头部干净
- 如果是离散的手势(左右滑动,双击),每个手势持续做 1-2 秒,手势之间停顿约 1 秒
- 如果是连续的手势(旋转),可以持续不同的时间
- 适当变换速度、方向和力度,增强模型泛化能力
- 每个手势类别采集约 5 分钟的数据
采集完成后,在串口助手中点击 Write to File,将数据保存为 CSV表格 文件。
idle(静止)和unknown(未知手势)这两类数据非常重要!它们可以防止模型在用户做其他动作时产生误触发。
数据标注
每个 CSV 文件只包含传感器数值,没有列名和标签。需要手动为每个文件添加列头和类别标签:
- 用 Excel、VS Code 或 Python 打开 CSV 文件
- 在第一行插入列名:
acc_x,acc_y,acc_z,gyro_x,gyro_y,gyro_z,class - 在
class列填入对应的整数标签 - 由于我们最后要合并数据集表格,在合并之前记得先把每个动作数据表格第一行的列名删除。全部合并后,再重新添加表头。
注意:数据集csv文件有严格的格式要求,如UTF-8 or ISO-8859-1编码,换行符保持一致等等。详见:Dataset requirements
各类别的标签编码如下(类别编号必须从 0 开始):
| 类别 | 整数标签 |
|---|---|
| IDLE | 0 |
| UNKNOWN | 1 |
| Swipe Right | 2 |
| Swipe Left | 3 |
| Double Knock | 4 |
| Double Thumb Tap | 5 |
| Rotation Clockwise | 6 |
| Rotation Counter-Clockwise | 7 |
标注后的文件示例(IDLE 类别):
acc_x,acc_y,acc_z,gyro_x,gyro_y,gyro_z,class
-10,5,980,2,1,0,0
-20,50,970,4,5,2,0
-30,60,970,5,6,3,0
数据窗口与数据分割(Segmentation)
如果你的数据,表格中的每一行就是一个完整的带标签的训练样本,则没有数据窗口的概念。
但是,传感器数据是连续的,连续很多行才代表1个训练样本,模型的输入是一段窗口内的数据。
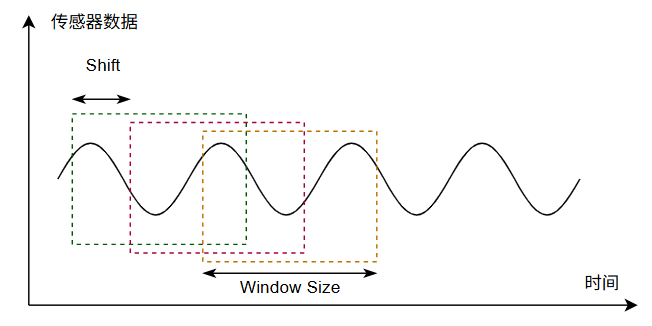
随着时间推移,把传感器数据分割为一个个窗口输入给模型,模型在一个计算周期(Shift)内给出这段数据对应的结果。窗口之间可以有重叠(Overlap),也可以没有。
但是我们要识别的动作本身是有连续和非连续的区别:
- 连续的,如顺/逆时针旋转、跑步、游泳。
- 非连续的,有明确的起止点。如左滑、右滑、双击。
对于连续的动作,我们可以直接用连续的原始数据去训练。Nordic Edge AI平台上可以设置滑动窗口的大小和偏移,自动生成训练数据。
对于非连续的动作,我们需要进行剪裁,必须把波形放到每个窗口的中间:
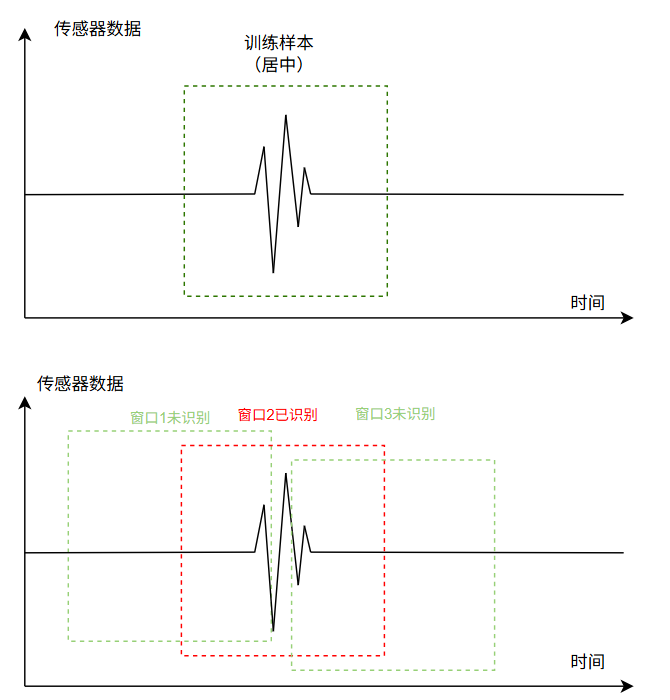
注意,训练时的滑动窗口设置和推理时的滑动窗口设置是可以不一样的。上图展示了推理时的滑动窗口:我们可以用较长的窗口(1-2秒)来确保动作的完整性;用较短(0.3s)的滑动偏移来确保动作识别的响应速度。
而在训练时,如果你的训练数据包含非连续动作,我们必须设置窗口大小(Window Size)等于滑动偏移(Shift),确保窗口之间没有重叠(Overlap)。
最终所有的训练数据合并在一起,应该类似这样:
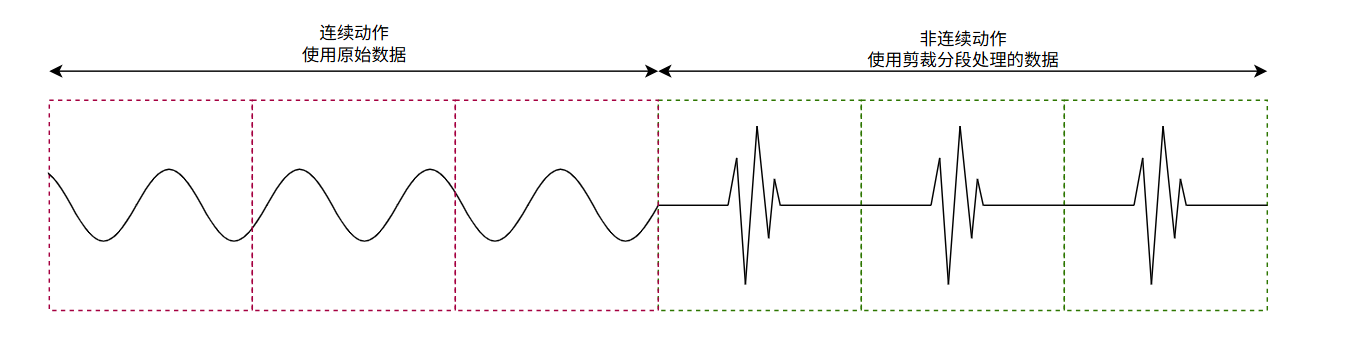
这样一来,训练服务器在读取数据时才能正确把每个非连续动作置于窗口中心。
以本例来说:最长手势约 1 秒,采样率 100 Hz,因此窗口大小(Window Size)为 100 个采样点。分割的目标是让每段窗口的中心对应手势的最大幅值处。
注意,如果你后续需要频域特征,必须选择2的幂作为窗口大小,且位于128和2048之间。
Nordic 提供了一个开源的自动分割脚本,来帮你分割非连续动作的数据。只需指定最长手势的时长(秒),脚本会自动完成分割和数据清洗(删除头尾噪声数据)。
你可以单独对非连续动作的CSV表格来执行这个脚本:
# 安装依赖 pip install -r requirements.txt # 处理数据(读取同目录下的名称为"sample_data.csv"的文件) python segment_data_around_peaks.py这个脚本比较粗糙,很多内容是硬编码的,你需要修改脚本内容来符合你的要求:
输入文件:
sample_data.csv:输入数据文件名# read data with one non-continuous gesture samples df = pd.read_csv('sample_data.csv', on_bad_lines='skip')数据处理参数:
TRAINING_WINDOW_SIZE:窗口大小gesture:输出文件名nrows_to_remove:忽略输入数据的前多少行# Define the desired training window size TRAINING_WINDOW_SIZE = 100 gesture = 'swipe_right' nrows_to_remove = 400数据集结构定义:
- 输入数据有6列+1列标签。每一列的名称就是输出数据的表头。
df.columns = ['aX', 'aY', 'aZ', 'gX', 'gY', 'gZ', 'target']峰值检测算法参数:
work_axis:选择要基于哪个轴做峰值检测threshold_coef:阈值系数config = { 'work_axis' : 'aY', # tunable parameter 'work_wind_size': int(TRAINING_WINDOW_SIZE * 0.95), # tunable parameter 'total_wind_size': TRAINING_WINDOW_SIZE, 'threshold_coef': 0.5, # tunable parameter 'step': 1 }算法解释:
- 创建滑动窗口,设定窗口大小为
TRAINING_WINDOW_SIZE,滑动步长为1。- 计算阈值,为这个轴的所有数据的均值乘以
threshold_coef- 计算每一步的窗口内的最大值和最小值的均方根,可以大致表征这个窗口内的平均振幅大小
- 窗口平均振幅上穿阈值时,记为波形的上升沿;下穿阈值时,记为波形的下降沿。
- 相邻的一个上升沿和下降沿之间的部分就捕捉到了一个波峰。把这个波峰放置在一个窗口中心,剪裁并记录到输出数据中。
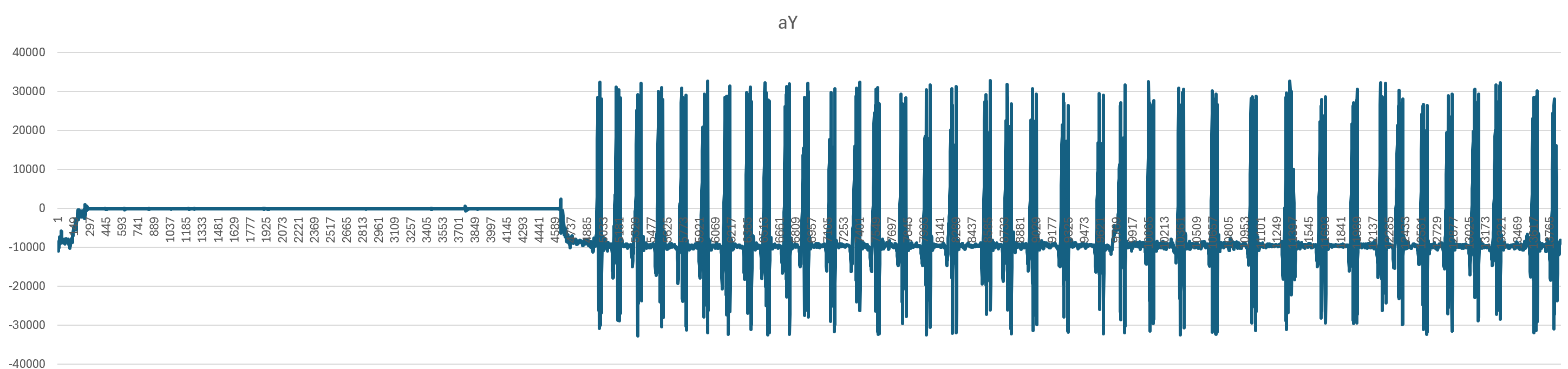
原始示例数据,用Excel绘制图像,开头有一段时间静止,13873行(138秒):
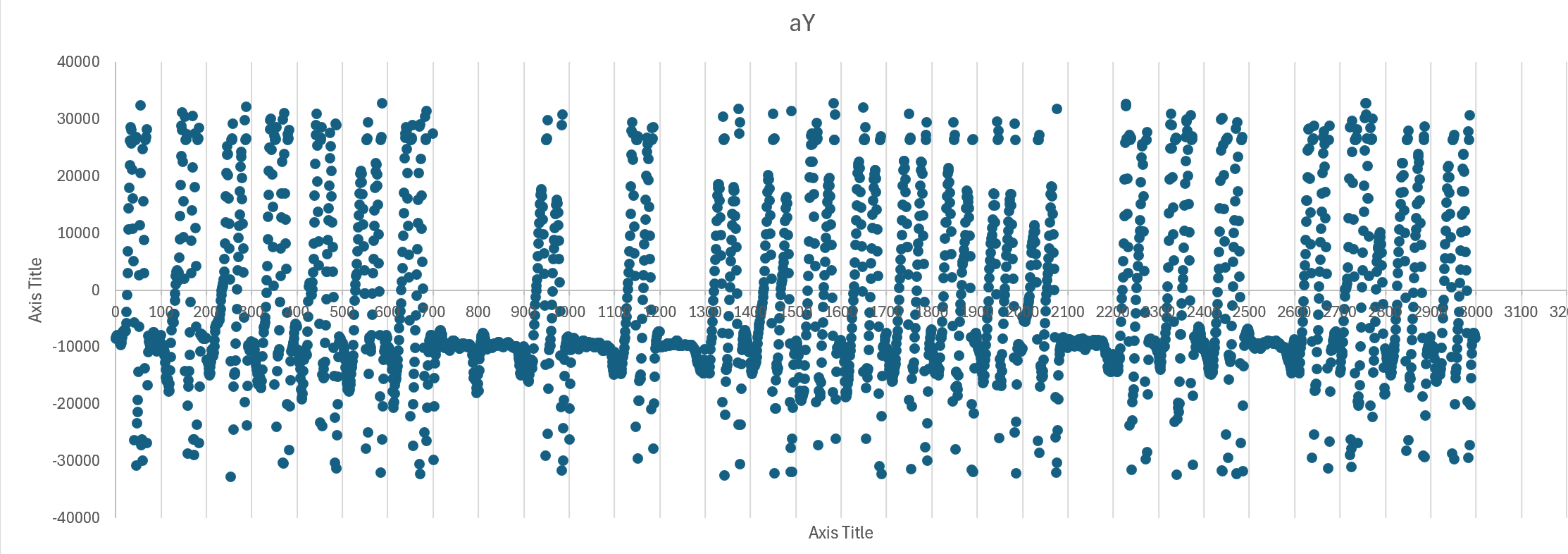
处理后的示例数据,只截取3000条(对应30秒),可以看到波峰是对齐大小为100的窗口的:
其中有一些误识别的,可能是阈值设置的太低了,将
threshold_coef改为1.2再测试一下:
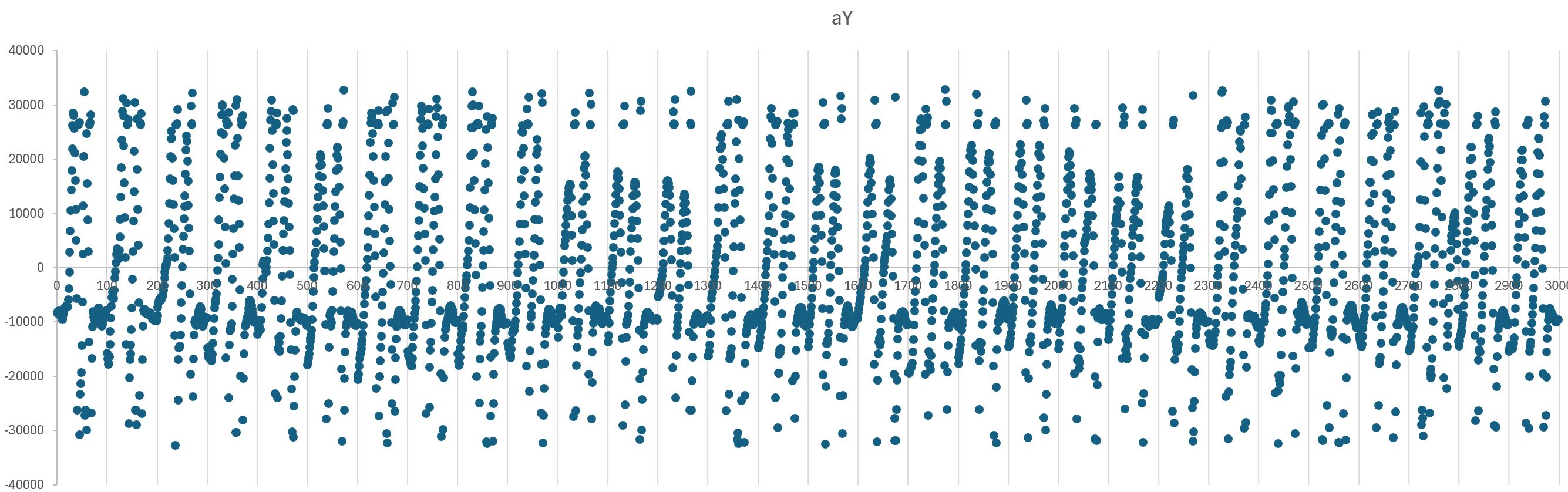
基本上就符合我们的需求了
合并数据集
注意:
- 在合并之前,确保所有的连续数据、非连续数据的长度都是窗口大小的整数倍
- 要记得确认每个表格都没有表头,否则会导致表头变成数据
将所有标注并分割好的 CSV 文件合并为一个总数据集:
# Windows PowerShell
Get-Content idle.csv, swipe_right.csv, swipe_left.csv, rotation_clockwise.csv, rotation_counterclockwise.csv, double_knock.csv, double_thumb_tap.csv, unknown_gestures.csv | Set-Content dataset.csv
最终得到一个包含所有手势类别数据的 dataset.csv,即可用于训练。
最终合并完成之后,再添加表头。
4. 在 Nordic Edge AI Lab 上训练模型
Nordic Edge AI Lab 是一个基于浏览器的在线机器学习平台,无需本地 GPU 即可完成模型训练。
注册并创建 Solution
- 在 Edge AI Lab 注册账户并登录
- 点击 Add New Solution 创建新项目
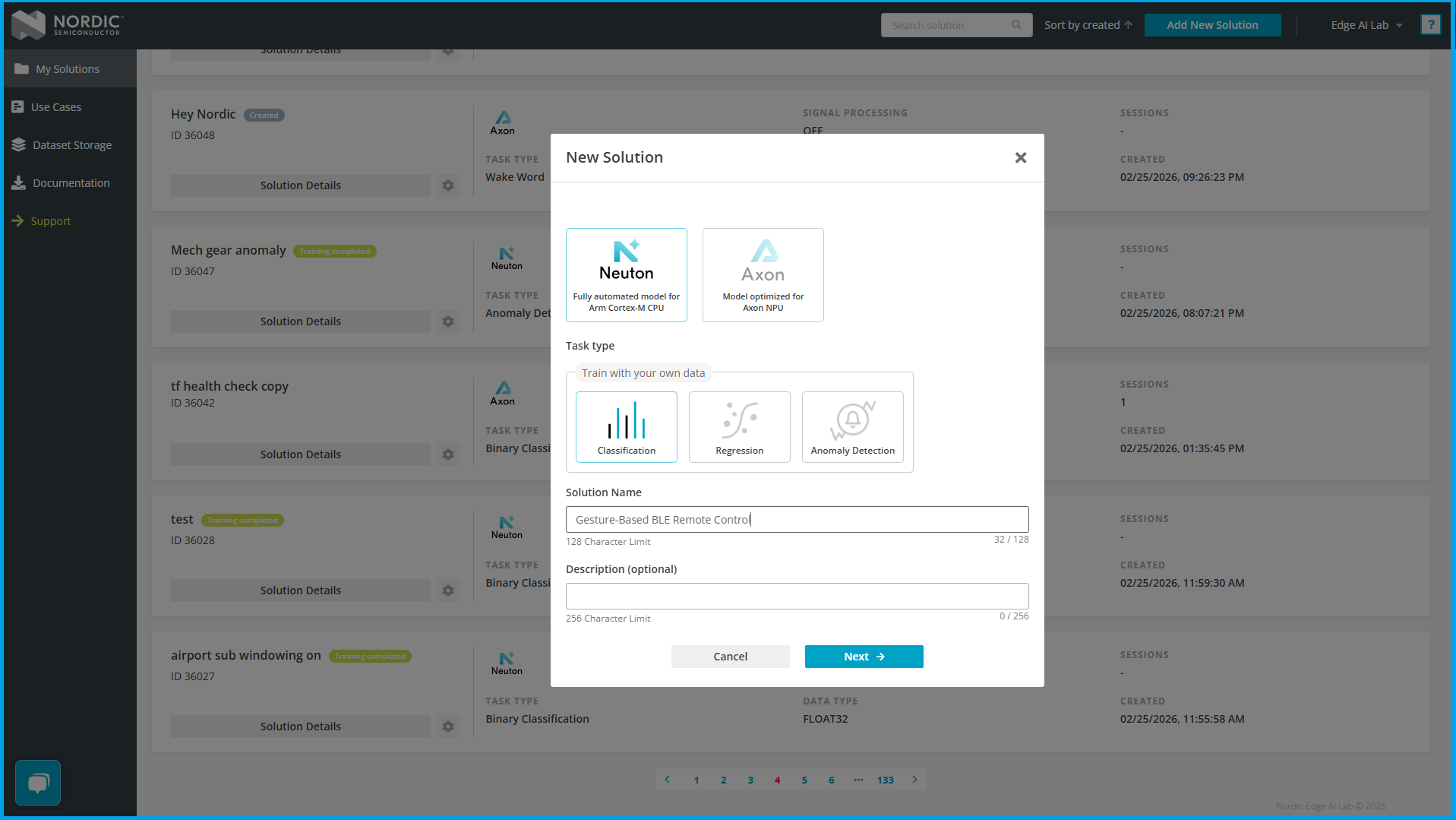
这里有三个选项:
- 分类任务(Classification):属于监督学习。就是前面介绍的,输入数据参数,输出每个分类的概率。如唤醒词检测、手势检测、二元分类等。
- 回归任务(Regression):属于监督学习。通过训练数据,拟合输入和输出的函数,输出的是连续数值。例如,输入传感器数据,输出温度、心率、血压值。
- 异常检测任务(Anomaly Detection):属于无监督学习模型,训练时不需要标签,只需提供正常运行状态下的数据。模型学习正常模式,并在推理时识别偏离正常行为的异常数据。典型应用场景是预测性维护(例如检测即将故障的机器)。
- 选择框架为 Neuton,任务类型为 Classification
- 填写项目名称,点击 Next
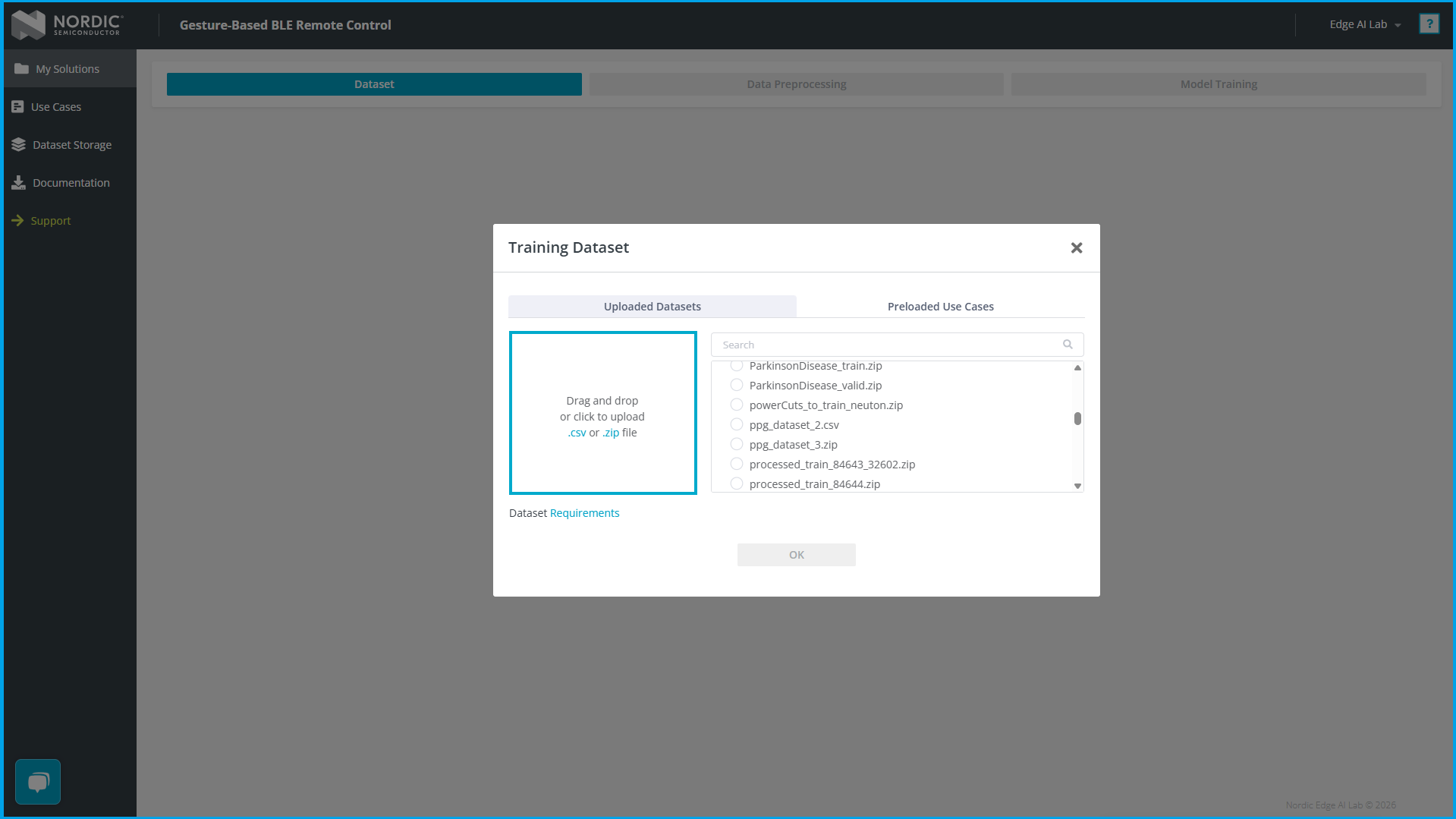
- 上传
dataset.csv,点击 OK
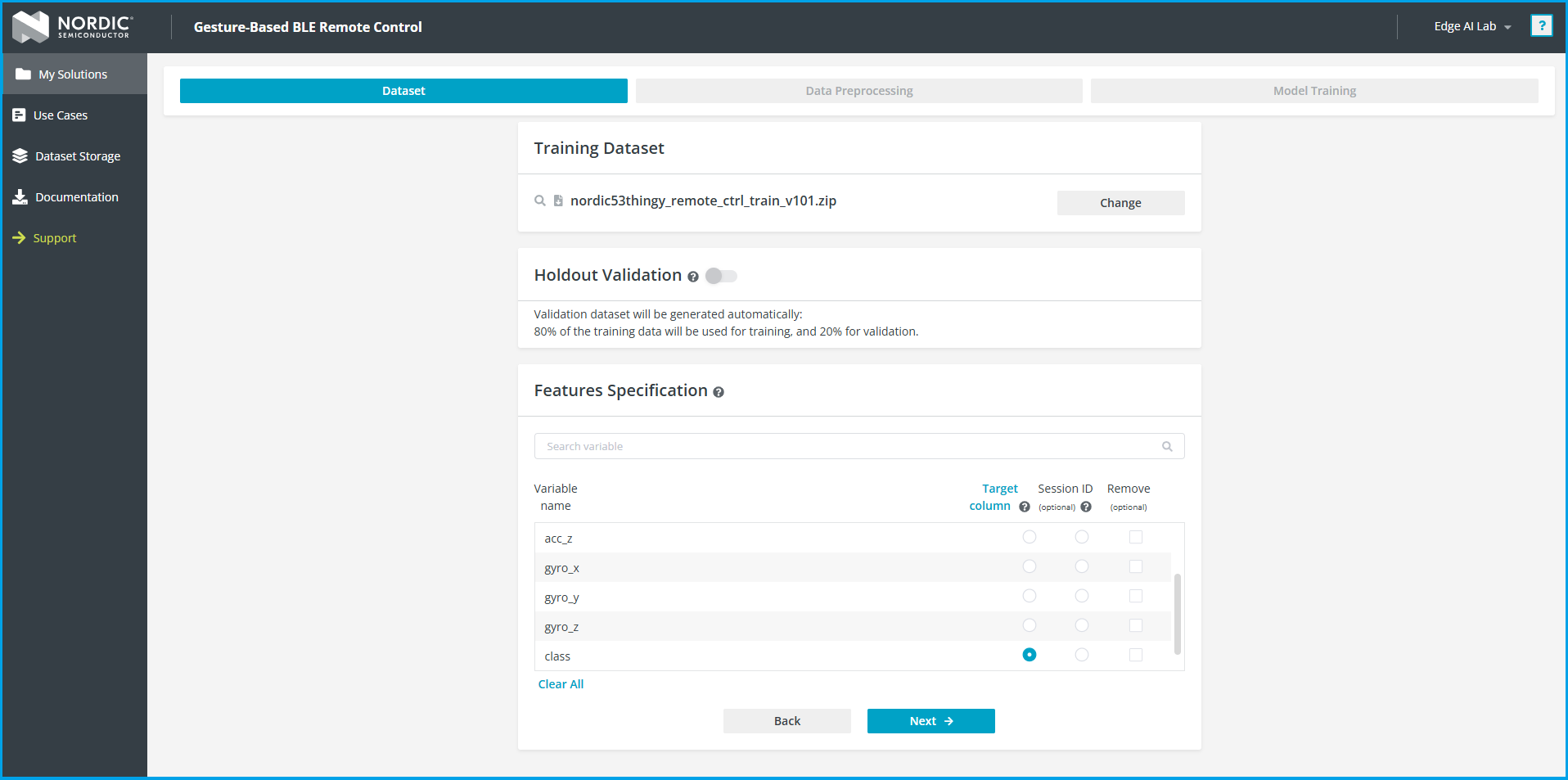
- 将 Target Column 设置为
class,点击 Next
数据预处理配置
窗口选择
刚刚进入页面时,会看到一个"Signal Processing"页面。
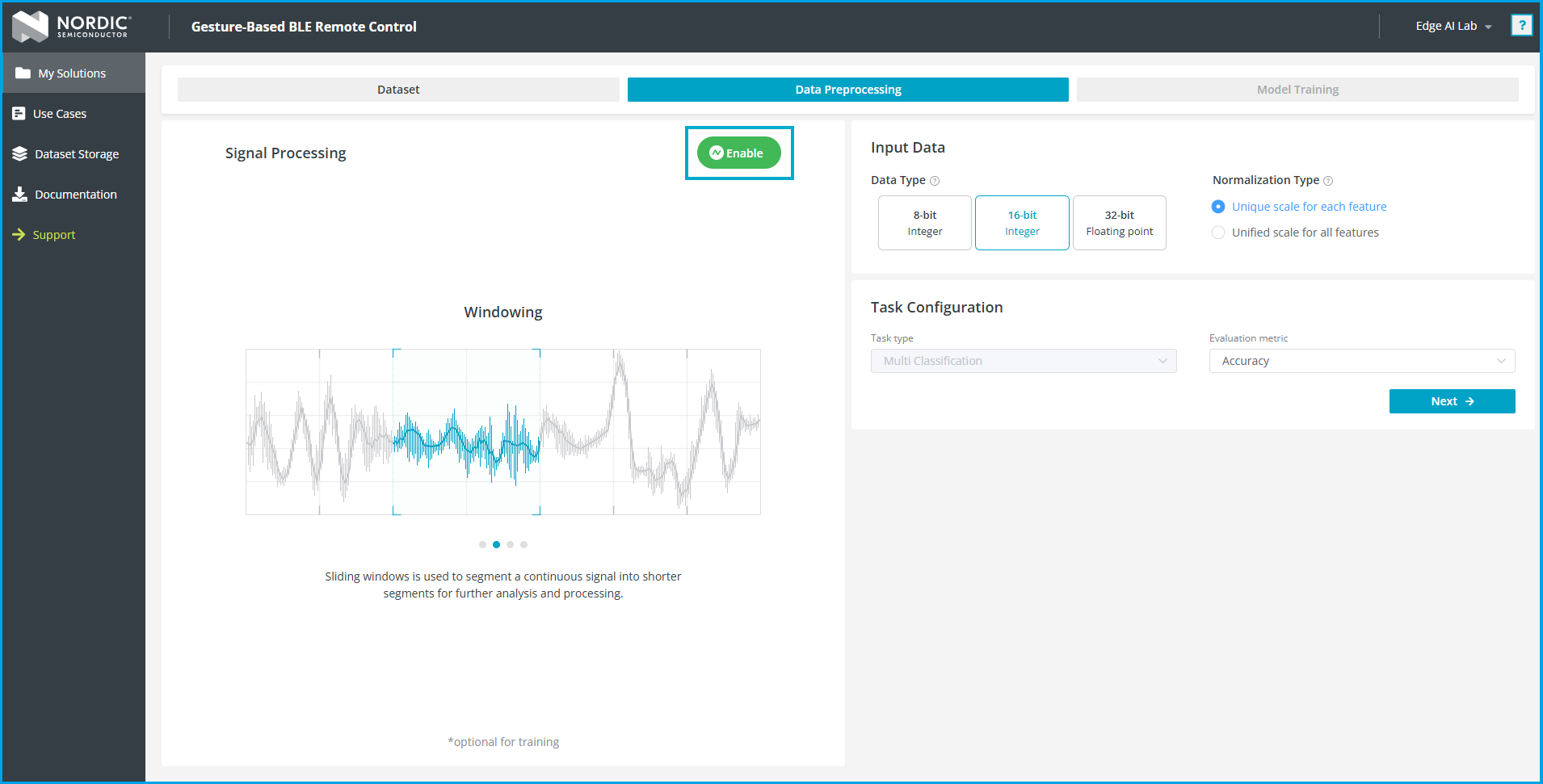
这里如果直接开始训练,模型会把每一行数据当成一个单独的训练样本,不会进行窗口化、特征提取等操作。由于我们每一行只是一条加速度计数据,需要连续100行才是1秒的数据,因此我们必须开启Signal Processing。
开启后,就可以进行数据预处理的配置:
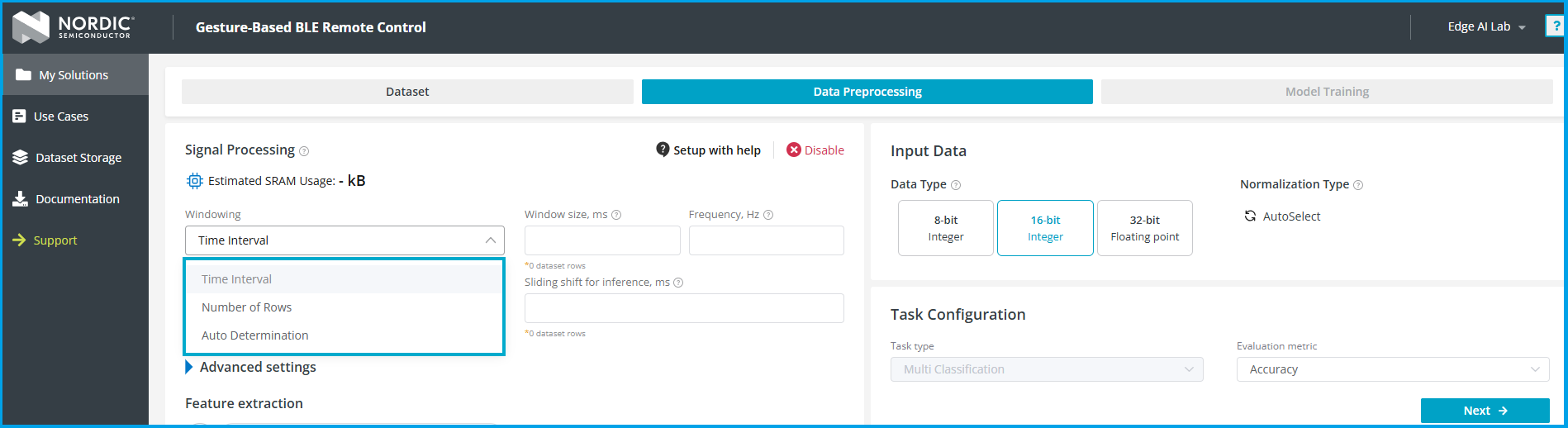
首先选择窗口大小,该平台的数据窗口大小范围为10到1000个。
- Time Interval:输入窗口时间和采样频率,平台自动计算一个窗口有多少行数据
- Number of Rows:直接填写有多少行数据
- Auto Determination:平台自动选择
由于我们前面已经把数据分割好,因此直接选择窗口大小为100行:

- "Window Size" 和 "Sliding shift for training" 必须相等,这样训练数据的窗口之间没有重叠也没有缝隙。因为我们前面分割好的数据就是这样准备的。
- "Sliding shift for inference"是模型在运行时的输入滑动步长。 在运行时,让窗口之间有重叠,可以防止部分动作数据被截断到前后两个窗口,导致丢失。Sliding Shift 越小,推理时生成的样本越密集,响应越快,但 CPU 占用越高。
特征提取(Feature Extraction)
如果我们直接把一个窗口内的所有数据当作一个训练样本向量,它的维度将是(6轴 × 100行 = 600)。要把一个600维的向量输入一个神经网络,结合前面介绍的神经网络的结构,可想而知,最终模型将会非常大。
我们可以用一些统计学的方法,先从传感器数据中提取一些统计特征,将原始的600维向量数据降低到每个轴十几维。
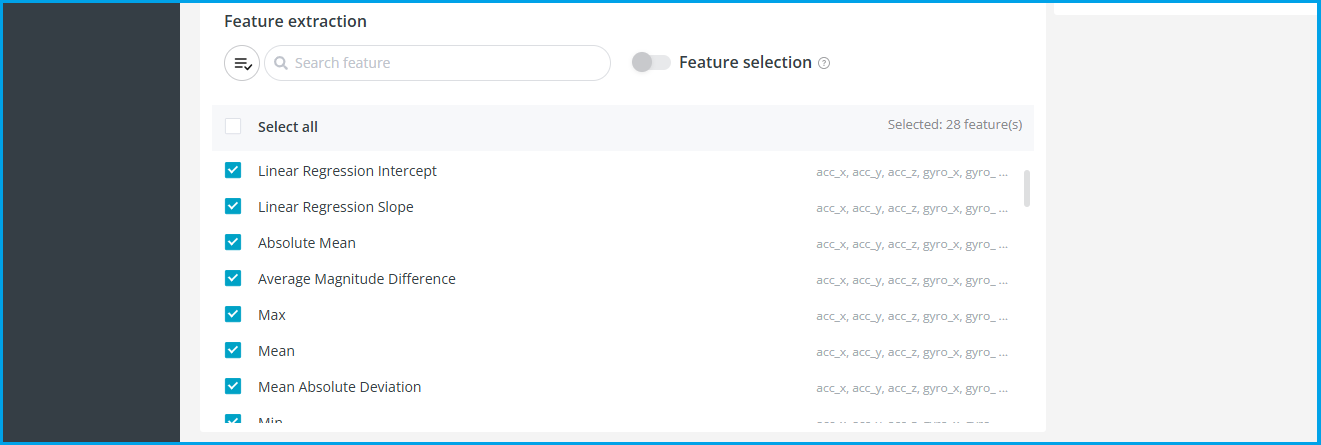
可选的特征有:
| 时域统计特征 | 说明 |
|---|---|
| Max/Min/Range/Mean | 最大值/最小值/极差/平均值 |
| Standard Deviation | 标准差,是方差的算术平方根。反映这组数据距离平均值有多么分散,适合做运动识别、异常检测等 |
| Mean Absolute Deviation (AAD) | 平均绝对偏差,所有数据点到平均值的距离的均值,和标准差类似。但是由于不包含平方运算,AAD对于异常值(离群值)的敏感度没有标准差那么高。 |
| Root Mean Square (RMS) | 均方根。常代表信号的”有效值“,如交流电的能量、传感器的噪声水平。 |
| Absolute Mean | 平均值的绝对值。和均方根类似,但是由于不包含平方运算,对于异常值不敏感。 |
| Kurtosis | 峰度,衡量数据的统计分布有多”陡峭“。大于0则为尖峰,小于0则平缓,等于0是标准正态分布图像。注意,这里看的不是时域波形,而是统计分布形态。 |
| Skewness | 偏度,衡量信号的对称性。大于0则有更多大极端值,尾巴右偏;小于0则有更多小极端值,尾巴左偏;等于0是标准正态分布图像。注意,这里看的不是时域波形,而是统计分布形态。 |
| 时域回归特征 | 说明 |
|---|---|
| Linear Regression Intercept | 线性回归截距 |
| Linear Regression Slope | 线性回归斜率 |
| 时域穿越率特征 | 说明 |
|---|---|
| Zero-crossing Rate | 信号在时域越过时间轴(零点)的频率 |
| Mean-crossing Rate | 信号在时域越过平均值的频率 |
| Threshold-crossing Rate | 信号在时域越过预定义阈值的频率 |
| Positive Sigma Crossing Rate | 信号在时域越过 平均值 + n个标准差 的频率 |
| Negative Sigma Crossing Rate | 信号在时域越过 平均值 - n个标准差 的频率 |
| 时域信号形状特征 | 说明 |
|---|---|
| Crest Factor | 波峰因数。是峰值振幅和RMS的比值 |
| Root Difference Square | RMSSD(Root Mean Square of Successive Differences),即相邻项差值的均方根。衡量的是序列内部的波动剧烈程度。常见于生物医学中心电信号的分析。 |
| Average Magnitude Difference | AMDF (Average Magnitude Difference Function),平均幅差函数。平移一段时间后再和自己相减,查看偏差有多大。是一种判断函数本身是否有周期性的简单算法,但容易受到噪声干扰。 |
| Autocorrelation | 自相关算法。平移一段时间后再和自己相乘,看相关性有多高。能判断出周期性,且抗噪声。但计算量比AMDF更大。 |
| Percentage of Signal over Mean | 信号超过平均值的百分比 |
| Percentage of Signal over Zero | 信号超过零的百分比 |
| Percentage of Signal over Sigma | 信号超过平均值 + n个标准差 的百分比 |
| Hjorth Mobility | 瑞典科学家 Bo Hjorth提出的参数,为分析脑电图设计的。是信号导数的方差和信号方差之比的平方根。反映平均陡峭程度。 |
| Hjorth Complexity | 瑞典科学家 Bo Hjorth提出的参数,为分析脑电图设计的。是信号的Mobility的导数与原始信号的Mobility比值。反映信号的不可预测性。 |
| 时域 峰-峰值 特征 | 说明 |
|---|---|
| Global Peak to Peak of High Frequencies | 全局高频峰-峰值。衡量信号细节或噪声的剧烈程度。 |
| Global Peak to Peak of Low Frequencies | 全局低频峰-峰值。衡量信号主趋势的剧烈程度。 |
注意:后续介绍的频域特征都要经过快速傅里叶变换(FFT)来获得。如果要使用频域特征,前面选择的窗口大小必须是2的幂,且介于128到2048之间。
| 频谱特征 | 说明 |
|---|---|
| Amplitude Spectrum | 信号频域的幅值(Magnitude) |
| Spectral Centroid | 频谱重心。频率分量的加权平均值。反映信号的平均频率成分。 |
| Spectral Spread | 频谱扩展度。频谱的分布范围,衡量频率范围有多宽。 |
| Spectral Crest | 谱峰比。最大幅值与平均幅值的比值,衡量信号中是否有明显的主导频率。 |
| Spectral RMS | 频谱均方根。时域的 RMS 和频域的 RMS 是等价的(只是单位或缩放比例可能不同)。 |
| 主频特征 | 说明 |
|---|---|
| Dominant Frequencies | 主频率,信号中能量最大的频点 |
| Dominant Frequency Amplitudes | 主频率信号的振幅 |
| Dominant Frequency Mean Distance | 最大的几个频点之间的平均距离。如果该值很乱,说明信号包含多个互不相关的振动源,而不是一个大振动源和它的谐波。 |
| Dominant Frequency SNR | 主频信噪比。衡量信号是否干净,周期性强。如果 SNR 突然下降,可能意味着传感器松动或环境干扰变大。 |
| Dominant Frequency THD | 主频总谐波失真。除了主频之外,其谐波成分占总能量的比例。衡量信号相比于标准正弦波有多大的畸变。常见于电力系统和音响设备中。 |
| 频域能量特征 | 说明 |
|---|---|
| Low/High Frequency Energy Ratio | 低频、高频能量比 |
| Low/Mid Frequency Energy Ratio | 低频、中频能量比 |
| Mid/High Frequency Energy Ratio | 中频、高频能量比 |
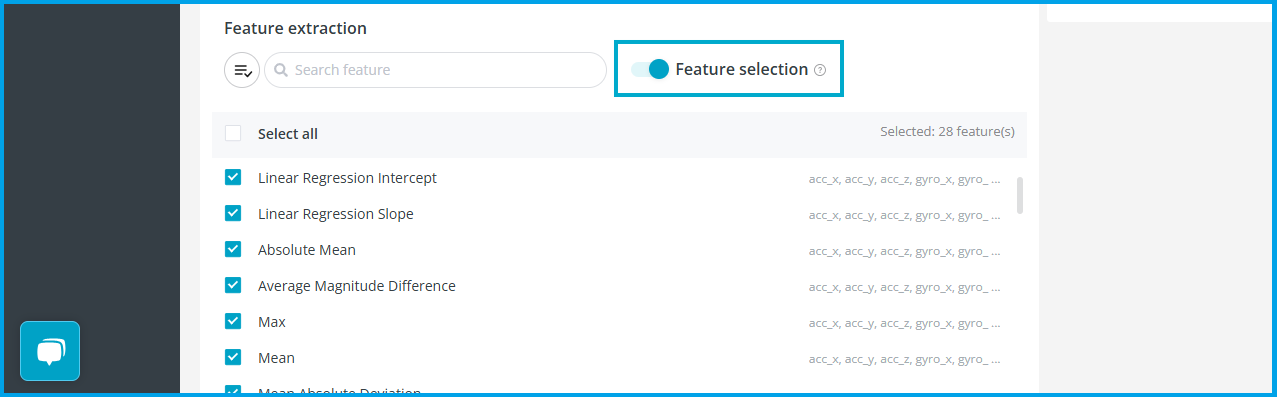
特征选择
勾选特征选择,可以帮你自动剔除一些贡献度小的特征,从而降低模型大小,提升效率。比如符合以下特征的:
- 几乎是常量
- 和其他特征的相关度是1.00
- 特征对模型最终的贡献重要性小于0.875%
原始数据训练(Raw Data)
如果你有特殊的需求,可以不使用特征值,而是全部使用原始数据:
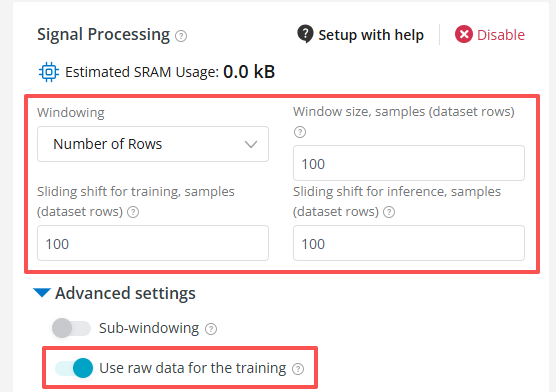
这种情况下,正如前面所说,会把6维×100条数据全部当作模型的一条训练数据,作为输入向量。
使用原始数据训练时:
- 滑动窗口步长必须等于窗口大小,即窗口之间没有重叠和缝隙
- 无法使用自动窗口大小
- 不能开启频域特征
子窗口
子窗口将信号分割成更小的片段,以更好地捕捉局部峰值、凹陷和模式。该平台不是将整个信号分析为一个长序列,而是将其处理成更小的块,并从每个块中提取更详细的特征。这对于手势和活动识别特别有用。
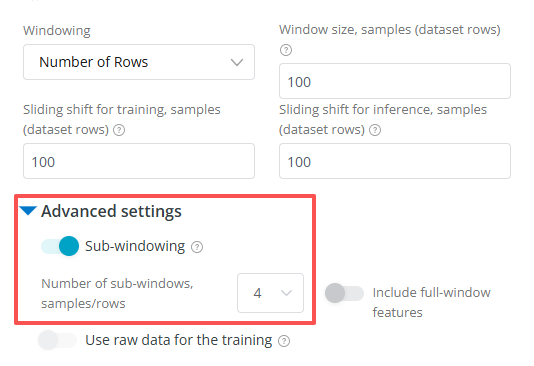
可以分割2到10个子窗口,每个子窗口至少要有10个样本数据。
使用子窗口时:
- 仍可以开启完整窗口的特征
- 不能使用频域特征
- 特征选择会自动启用,但也可以手动关闭
- 不能开启原始数据功能
输入数据类型
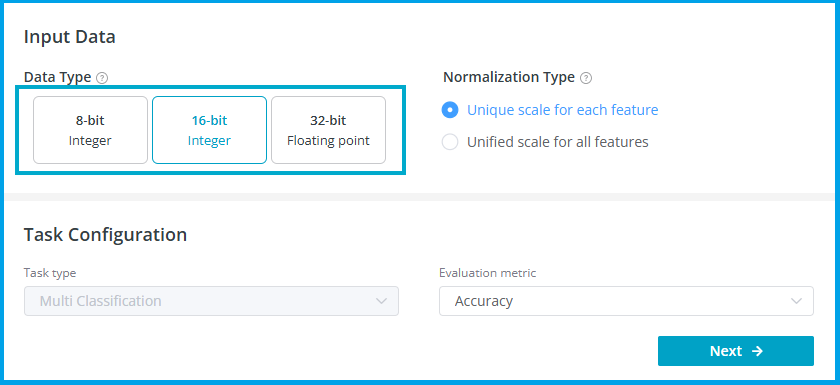
数据类型代表的是神经网络参数的类型。位数越多则模型精度越高,但运算会更困难。
- 8-bit Integer: -128 to 127
- 16-bit Integer: -32768 to 32767.
- 32-bit Floating point: 要求数据集里至少有一个数据为浮点数类型
所有的特征值的量纲肯定是不一样的,但是他们要放在同一个神经网络中去计算。归一化(Normalization)选项是看你如何处理这些特征:
- Unique scale for each feature:每个特征有自己的取值范围,会提高精度,但也可能导致模型变大
- Unified scale for all features:把所有特征值都统一缩放到同样的取值范围,可能降低模型精度和大小
评价指标
选择在训练过程中,该使用什么指标来判断模型输出质量的好坏。详细说明见 文档。
模型训练
- 点击 New Session 开始一个新的训练会话
- 选择训练框架为 Neuton,目标硬件为 Cortex-M33(对应 Thingy:53 的 nRF5340)
- 配置以下模型设置:
| 参数 | 设置值 | 说明 |
|---|---|---|
| Weights & Coefficients | Quantization-Aware 16-bit Integer | 量化感知训练,减小模型体积,加速推理 |
| Output Format | Floating-point 32-bit | 输出每个手势类别的概率(0~1) |
| Early Stopping | 目标精度 0.99 | 达到目标精度后自动停止,节省训练时间 |
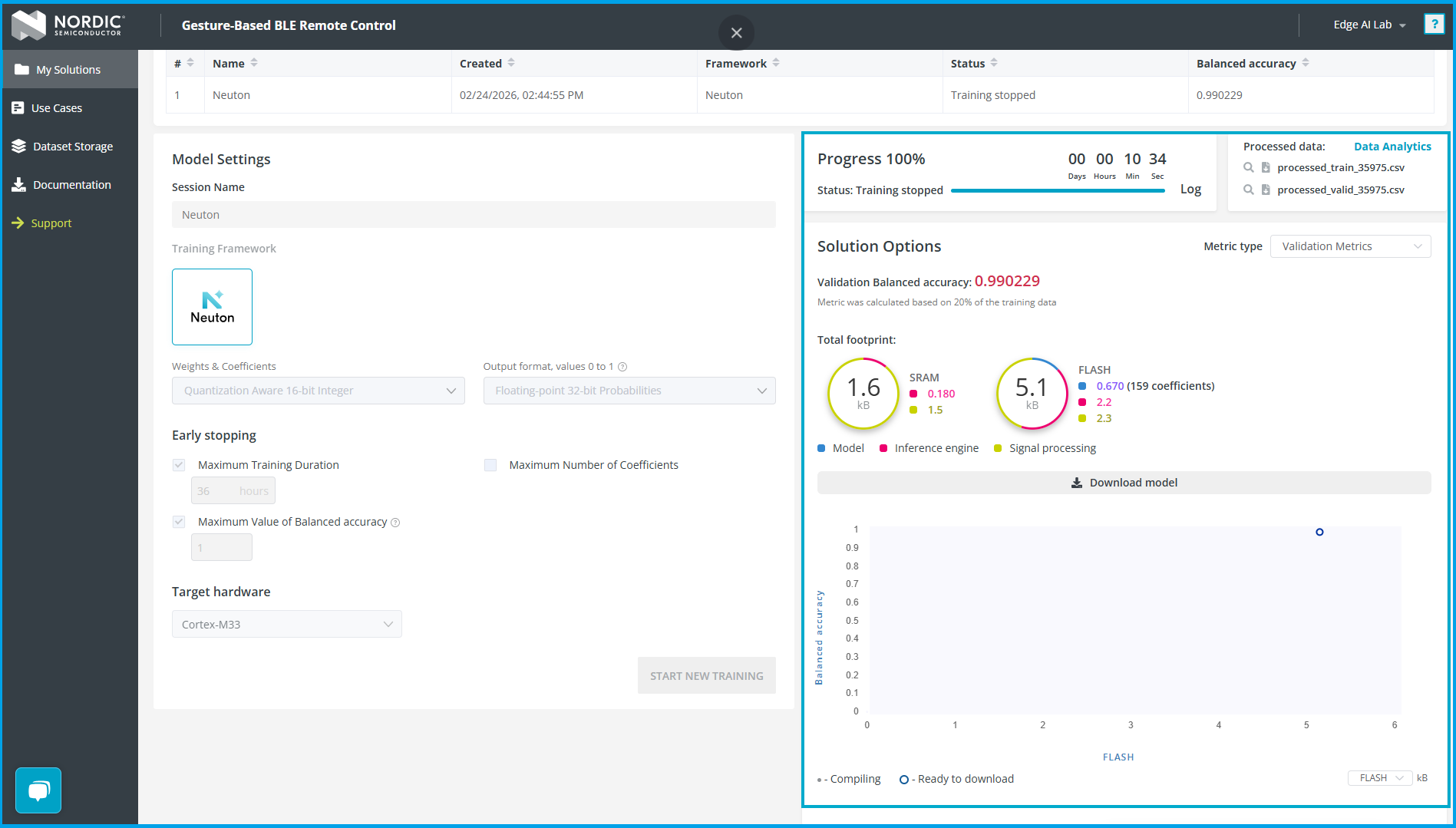
- 点击 Start New Training,等待训练完成。训练完成后平台会发送邮件通知
Neuton模型只能创建一个Session。Axon模型可以创建多个Session,方便你对比效果。
查看训练结果
训练完成后,平台提供以下分析工具:
- 训练精度曲线:显示各迭代的精度和模型体积,可以手动选择更小的模型(以轻微降低精度为代价)
- 模型资源占用:RAM 和 Flash 的使用量,可按目标硬件切换查看
- 混淆矩阵(Confusion Matrix):直观显示各手势类别的识别正确率和混淆情况(仅用于分类任务)
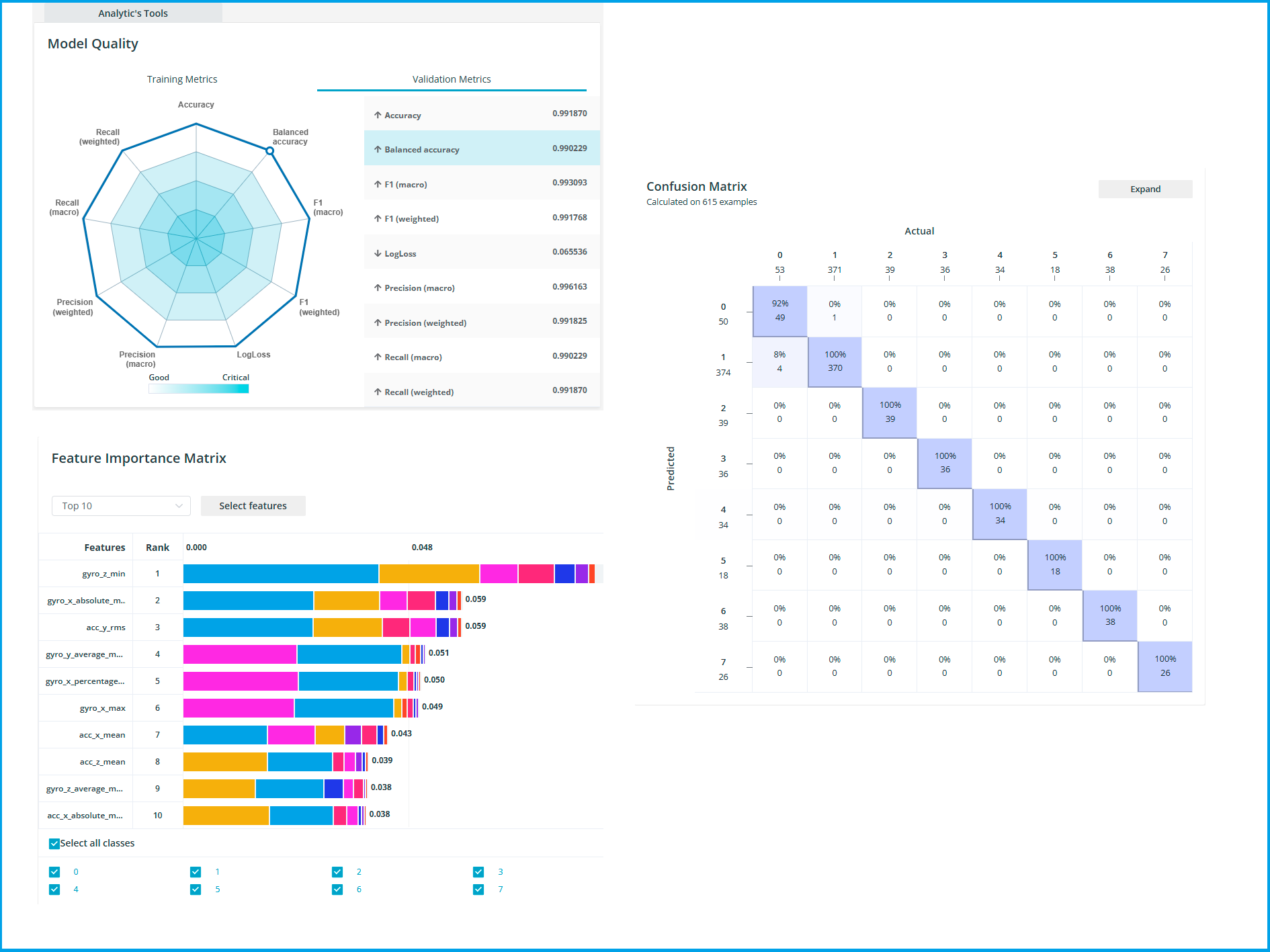
- 特征重要性矩阵(FIM):显示各特征对模型预测的贡献度
确认结果满意后,点击下载按钮,获得一个包含模型文件和推理代码的压缩包。
5. 将模型部署到 MCU
压缩包内容
下载的压缩包中主要包含以下内容:
nrf_edgeai_generated/:自动生成的模型推理代码目录- 模型权重文件(C 数组格式)
- 特征提取代码
- 推理接口头文件
集成到 NCS 工程
以 edge-ai/applications/gesture_recognition 为基础工程,将下载的 nrf_edgeai_generated/ 目录替换工程中 src/nrf_edgeai_generated/ 目录:
gesture_recognition/
└── src/
├── nrf_edgeai_generated/ ← 用下载包中的文件替换此目录
├── main.c
├── inference_postprocessing.c
└── inference_postprocessing.h
如果你训练的手势类别与示例工程不同,还需要同步修改
main.c和inference_postprocessing.c/h中的类别定义和后处理逻辑。
替换完成后,重新编译并烧录固件即可。
运行效果
烧录推理固件后,设备通过 BLE 广播为 HID 设备,可直接与 PC 配对。配对成功后,设备会根据识别到的手势发送对应的键盘快捷键:
串口日志示例:
Predicted class: SWIPE RIGHT, with probability 99 %
BLE HID Key 32 sent successfully
Predicted class: ROTATION RIGHT, with probability 93 %
BLE HID Key 1 sent successfully
迭代优化
第一版模型通常不够完善,最常见的问题是误触发(做其他动作时模型错误地识别为某个手势)。优化流程如下:
- 在设备上实际测试模型
- 记录哪些无关动作导致了误触发
- 对这些动作采集数据,添加到
unknown类别中 - 重新上传数据集,在 Edge AI Lab 上重新训练
- 重新部署并测试
通常经过 2-3 轮迭代,就能得到一个误触发率低、泛化能力强的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号