Java的HashMap实现原理整理总结
通过Debug 探寻Java-HashMap 实现原理:
一个简单的例子,代码如下,
测试方法 main:
1 public static void main(String[] args) { 2 3 KeyObj obj1 = new KeyObj("AAAA"); 4 KeyObj obj2 = new KeyObj("BBBB"); 5 KeyObj obj3 = new KeyObj("CCCCC"); 6 KeyObj obj4 = new KeyObj("DDDDD"); 7 8 HashMap<KeyObj, String> hashMap = new HashMap<KeyObj, String>(); 9 hashMap.put(obj1, "aaaa"); 10 hashMap.put(obj2, "bbbb"); 11 hashMap.put(obj3, "ccccc"); 12 hashMap.put(obj4, "ddddd"); 13 14 System.out.println(hashMap.values()); 15 16 }
KeyObj.java
1 public class KeyObj { 2 3 String keyStr; 4 5 public KeyObj(String keyStr) { 6 super(); 7 this.keyStr = keyStr; 8 } 9 10 public String getKeyStr() { 11 return keyStr; 12 } 13 14 public void setKeyStr(String keyStr) { 15 this.keyStr = keyStr; 16 } 17 18 @Override
// 覆盖hashCode方法,使得key的单双数分别获得一致的hash值,方便测试 19 public int hashCode() { 20 if (keyStr.length() % 2 == 0) { 21 return 31; 22 } 23 return 95; 24 } 25 26 @Override 27 public boolean equals(Object obj) { 28 KeyObj obj1 = (KeyObj) obj; 29 if (this.keyStr.equalsIgnoreCase(obj1.keyStr)) 30 return true; 31 return false; 32 } 33 34 }
运行测试方法main,Debug查看HashMap:
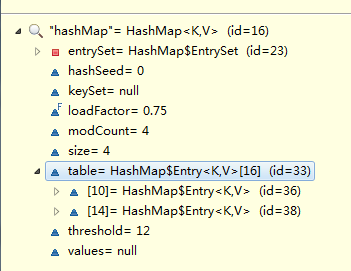
1.可以看到HashMap其实是有一个名称为table的Entry数组,我们使用HashMap的put方法,本质是把我们的Key-Value作为Entry对象放入到HashMap中。
2.HashMap的table数组初始大小为16.
3.为何我们put了4个对象却只使用了table[10] 与 table[14]?
查看put方法JDK代码:
1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); // 3.1 table若为空创建table,16大小 4 } 5 if (key == null) 6 return putForNullKey(value); // 3.2 key若为空放入table[0] 7 int hash = hash(key); // 3.3 计算放入key的hash,值为调用KeyObj的hashcode方法,再hash 8 int i = indexFor(hash, table.length);
// 3.4 计算当前put的Enrty在table数组中精确位置(int i),跟踪代码可以很容易看出:
// 3.4.1 精确位置i是由key的hash值与table.length取模 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 3.5 遍历table[i]的Entry 10 Object k; 11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 3.6 若put相同key的KeyObj,则替换旧值 12 V oldValue = e.value; 13 e.value = value; 14 e.recordAccess(this); 15 return oldValue; 16 } 17 } 18 19 modCount++; 20 addEntry(hash, key, value, i);// 3.7 创建Entry,当前table[i]的首节点变为当前put节点Entry对象的next节点,注:JDK8之前每一个table[i]上的Entry使用单链表存储的 21 return null; 22 }
理解了put,查看HashMap的get方法就很简单了:
1 public V get(Object key) { 2 if (key == null) 3 return getForNullKey(); 4 Entry<K,V> entry = getEntry(key); 5 6 return null == entry ? null : entry.getValue(); 7 }
继续查看第四行getEntry方法:
1 final Entry<K,V> getEntry(Object key) { 2 if (size == 0) { 3 return null; 4 } 5 6 int hash = (key == null) ? 0 : hash(key); 7 for (Entry<K,V> e = table[indexFor(hash, table.length)]; // 找到table[i],并便利该位置节点 8 e != null; 9 e = e.next) { 10 Object k; 11 if (e.hash == hash && 12 ((k = e.key) == key || (key != null && key.equals(k)))) // 找到,返回 13 return e; 14 } 15 return null; 16 }
其他:
在put函数代码中有一个注释:
JDK8之前每一个table[i]上的Entry使用单链表存储的
一直到JDK7为止,HashMap的结构都是这么简单,基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
这样子的HashMap性能上就抱有一定疑问,如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK8中得到了解决。再最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
所以在JDK8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号