

Spark-内核运行原理说明
spark 运行原理图如下
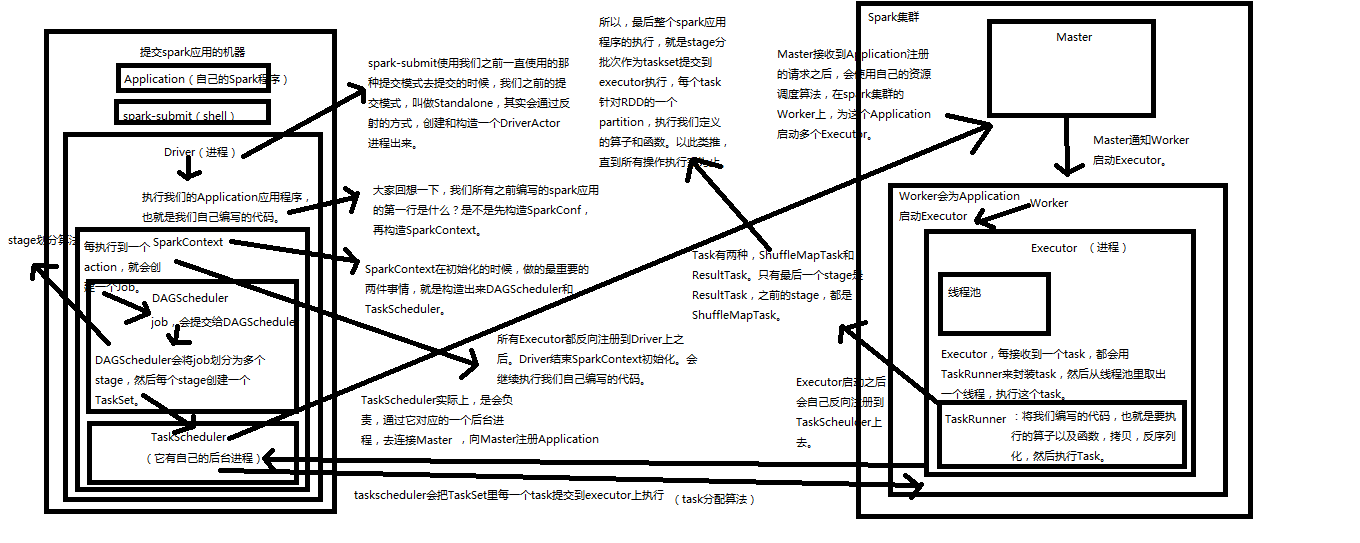
说明:spark从job通过driver提交,到job运行,大致过程如下,jobt提交,启动driver进程,drver首先构建sparkContex,sqlContext里面3个重要组件,DAGscheduler,TaskScheduler,SparkUI,sparkContext
构建完成后,通过taskScheduler 向spark集群Masker进行Application应用注册,Master寻找可用的work,并再work上启动executor进程,Executor反向注册到driver的TaskScheduler.
具体如下
1) 通过sparksubmit(shell)提交应用程序application
2) 在应用提交的机器上创建driverActior进程,创建driver
3) Driver进程读取代码,首先创建sparkContext上下文
4) SparkContext上下文包括两个重要组件:
TaskScheduler:
(a) 与master通信,注册应用
(b) 接收executro的反向注册,让driver获取到executor列表
(c) 接收DAGScheduler分解的task,将task按批次发放到executor上进行执行
DAGScheduler:
(a) 解析代码,每执行到一个action,就会产生一个job,job传递给DAGSchedule
(b) 将job 分解为多个stage(stage根据遇到聚合如reduce算子进行划分),每个stage生成一个taskset集合
(c) 将taskset集合发送给TaskScheduler进行分发到executor上执行
5) Master注册(注册机制见后面的master注册机制原理)
Maste注册包括下面几个:
(a) 应用程序的注册
(b) Driver的注册
(c) Work节点注册
6) Master接收到application 申请后,通过资源调度算法,为应用分配资源
work节点启动executor进程,executor回反向注册到driver的taskScheduler上。
Executor每接收到一个task,就会重线程池中,获取一个线程,执行task任务
如下图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号