04
添加分页器
需求:
跳转页面如何保留条件

思路:找到要跳转的额地方在修改

form action=http://127.0.0.1:8000/stark/app01/book/?a=1&b=2 method="get" GET请求: request.GET {"a":1,"b":2} request.POST {} form action=http://127.0.0.1:8000/stark/app01/book/?a=1&b=2 method="post" <input type="text" name="user" value="123"> POST请求: request.GET {"a":1,"b":2} request.POST {"user":"123"}

问题:但用户挂的东西与前面冲突

思路:将过滤条件放到一个键里
渲染编辑标签 带有过滤条件并解决过滤条件有可能冲突的问题
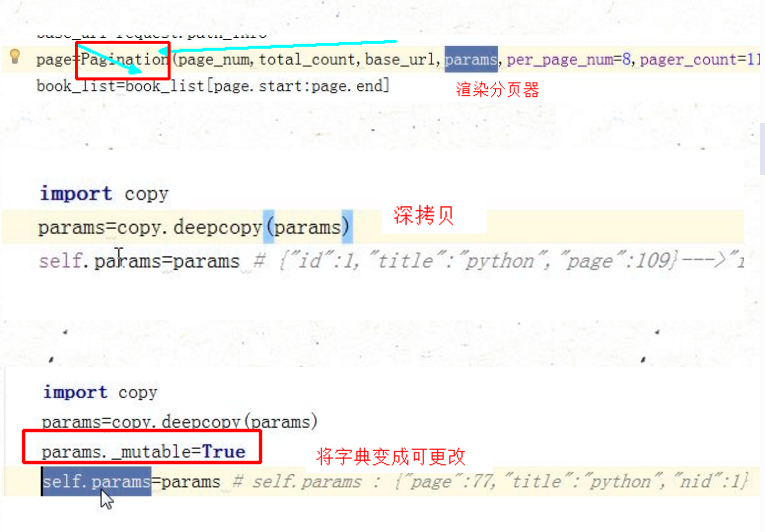
# url保留搜索信息 渲染编辑标签 def get_link_tag(self,obj,val): params = self.request.GET import copy params = copy.deepcopy(params) # 深拷贝 params._mutable=True # 修改成可修改状态 # 给条件放到一个键里 from django.http import QueryDict qb=QueryDict(mutable=True) qb["list_filter"] = params.urlencode() # qb:{"list_filter":"a=1&b=2"}---->字典(下面不能直接放) # href=?list_filter s=mark_safe("<a href='%s?%s'>%s</a>"%(self.get_edit_url(obj),qb.urlencode(),val)) return s
提交后返回的url也需要保存搜索条件
# 编辑视图 def change_view(self,request,id): edit_book = self.model.objects.filter(pk=id).first() # 取到要修改的数据对象 ModelFormClass = self.model_form_class if request.method=="GET": form=ModelFormClass(instance=edit_book) # 需要编辑的内容 return render(request,"stark/change_view.html",{"form":form}) else: # 提交数据走的流程 form=ModelFormClass(data=request.POST,instance=edit_book) if form.is_valid(): form.save() params = request.GET.get("list_filter") # 取后缀http://127.0.0.1:8000/stark/app01/book/1/change/?list_filter=page%3D1%26a%3D2 print("--------------",params) url="%s?%s"%(self.get_list_url(),params) return redirect(url) # return redirect(self.get_list_url()) else: return render(request,"stark/change_view.html",{"form":form})
优化代码:将展示数据部分代码封转到一个类里面

当前的self.config都是之前self
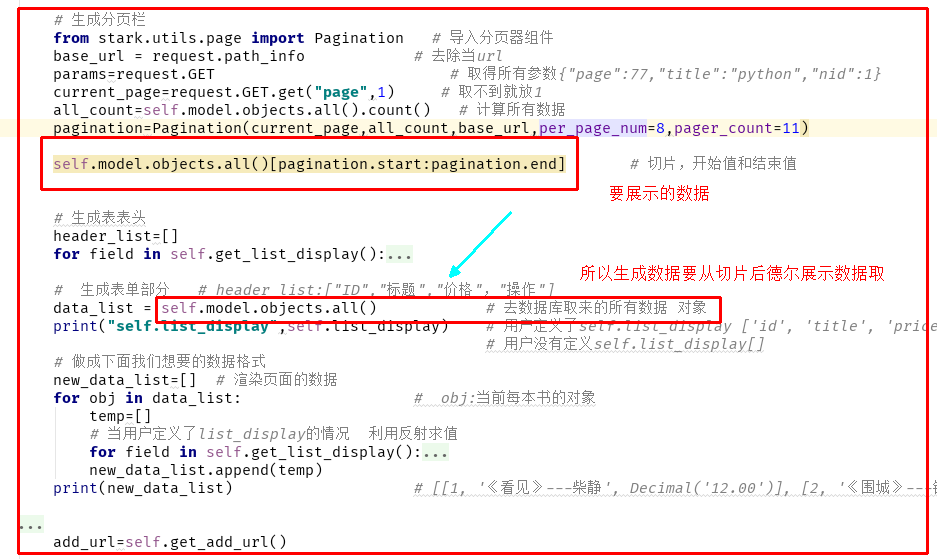
# ShowList服务与show_list_view class ShowList(object): def __init__(self,config,request): self.request=request # 封装成自己的实例变量 self.config=config from stark.utils.page import Pagination # 导入分页器组件 base_url = request.path_info # 去除当url params = request.GET # 取得所有参数{"page":77,"title":"python","nid":1} current_page = request.GET.get("page", 1) # 取不到就放1 all_count = self.config.model.objects.all().count() # 计算所有数据 pagination = Pagination(current_page, all_count, base_url, params, per_page_num=2, pager_count=11) self.pagination = pagination # 封装成自己的实例变量 data_list = self.config.model.objects.all()[pagination.start:pagination.end] # 切片,开始值和结束值 self.date_list=data_list # 封装成自己的实例变量 def get_header(self): # 生成表表头 header_list=[] for field in self.config.get_list_display(): # ["id","title","price","edit"] if callable(field): # header_list.append(field.__name__) val = field(self,is_header=True) # 定义了一个is_header=True变量 header_list.append(val) else: if field=="__str__": # 默认样式 header_list.append(self.config.model._meta.model_name.upper()) else: field_obj=self.config.model._meta.get_field(field) header_list.append(field_obj.verbose_name) # verbose_name 显示描述字段 return header_list def get_body(self): header_list = [] for field in self.config.get_list_display(): # ["id","title","price","edit"] if callable(field): # header_list.append(field.__name__) val = field(self, is_header=True) # 定义了一个is_header=True变量 header_list.append(val) else: if field == "__str__": # 默认样式 header_list.append(self.config.model._meta.model_name.upper()) else: field_obj = self.config.model._meta.get_field(field) header_list.append(field_obj.verbose_name) # verbose_name 显示描述字段 # 生成表单部分 # header_list:["ID","标题","价格","操作"] # data_list = self.model.objects.all() # 去数据库取来的所有数据 对象 print("self.list_display", self.config.list_display) # 用户定义了self.list_display ['id', 'title', 'price'] # 用户没有定义self.list_display[] # 做成下面我们想要的数据格式 new_data_list = [] # 渲染页面的数据 for obj in self.date_list: # obj:当前每本书的对象 temp = [] # 当用户定义了list_display的情况 利用反射求值 for field in self.config.get_list_display(): # ['id', 'title', 'price',delete,edit] , if callable(field): # 当遇到delete,edit函数 val = field(self.config, obj) # 执行函数返回的返回值 else: # 'id', 'title', 'price' val = getattr(obj, field) # 利用反射getattr取值 当用户没定义list_display用“__str__” # 选择指定字段添加a标签跳转到edit页面 if field in self.config.list_display_links: val = self.config.get_link_tag(obj, val) temp.append(val) # 当走默认的话,也会把__str__传到val new_data_list.append(temp) print(new_data_list) # [[1, '《看见》---柴静', Decimal('12.00')], [2, '《围城》---钱钟书', Decimal('12.00')]] return new_data_list


# 展示数据 def show_list_view(self,request): # print("self.model",self.model) # 打印当前表 self.request=request # 生成request属性给get_link_tag调用 # 生成分页栏 # from stark.utils.page import Pagination # 导入分页器组件 # base_url = request.path_info # 去除当url # params=request.GET # 取得所有参数{"page":77,"title":"python","nid":1} # current_page=request.GET.get("page",1) # 取不到就放1 # all_count=self.model.objects.all().count() # 计算所有数据 # pagination=Pagination(current_page,all_count,base_url,params,per_page_num=2,pager_count=11) # # data_list = self.model.objects.all()[pagination.start:pagination.end] # 切片,开始值和结束值 # # 生成表表头 # header_list=[] # for field in self.get_list_display(): # ["id","title","price","edit"] # if callable(field): # # header_list.append(field.__name__) # val = field(self,is_header=True) # 定义了一个is_header=True变量 # header_list.append(val) # else: # if field=="__str__": # 默认样式 # header_list.append(self.model._meta.model_name.upper()) # else: # field_obj=self.model._meta.get_field(field) # header_list.append(field_obj.verbose_name) # verbose_name 显示描述字段 # # # 生成表单部分 # header_list:["ID","标题","价格","操作"] # # data_list = self.model.objects.all() # 去数据库取来的所有数据 对象 # print("self.list_display",self.list_display) # 用户定义了self.list_display ['id', 'title', 'price'] # # 用户没有定义self.list_display[] # # 做成下面我们想要的数据格式 # new_data_list=[] # 渲染页面的数据 # for obj in data_list: # obj:当前每本书的对象 # temp=[] # # 当用户定义了list_display的情况 利用反射求值 # for field in self.get_list_display(): # ['id', 'title', 'price',delete,edit] , # if callable(field): # 当遇到delete,edit函数 # val=field(self,obj) # 执行函数返回的返回值 # else: # 'id', 'title', 'price' # val=getattr(obj,field) # 利用反射getattr取值 当用户没定义list_display用“__str__” # # 选择指定字段添加a标签跳转到edit页面 # if field in self.list_display_links: # val=self.get_link_tag(obj,val) # # temp.append(val) # 当走默认的话,也会把__str__传到val # new_data_list.append(temp) # print(new_data_list) # [[1, '《看见》---柴静', Decimal('12.00')], [2, '《围城》---钱钟书', Decimal('12.00')]] # 添加新的标签: # [ # [1, '《看见》---柴静', Decimal('12.00'), "<a href='/stark/app01/book/3/change/'>编辑</a>", "<a href='/stark/app01/book/3/delete/'>删除</a>"], # [2, '《围城》---钱钟书', Decimal('12.00'), "<a href='/stark/app01/book/3/change/'>编辑</a>", "<a href='/stark/app01/book/3/delete/'>删除</a>"] # ] # ''' # [ # [1,"xxx"], # [2,"xxxxx"], # [3,"xxxxxxx'], # ] # ''' add_url=self.get_add_url() sl = ShowList(self,request) # 把当前的self和request传给类ShowList return render(request,"stark/show_list.html",locals())
search模糊查询
知识点:关于Q查询
from .models import * # Q用来描述且 或的情况 from django.db.models import Q # 取反,名字为lishi且邮箱不能为123@qq.com # 当前的name只能为字段名称,才能这样写 UserInfo.objects.filter(Q(name="lishi")&~Q(email="123@qq.com")) # 当我们需要处理字符串时,如下就可以为字符串,q,默认为且关系 q=Q() q.connector="or" # 修改默认的且为或 q.children.append("name","lishi") q.children.append("email","123@qq.com") UserInfo.objects.filter(q)
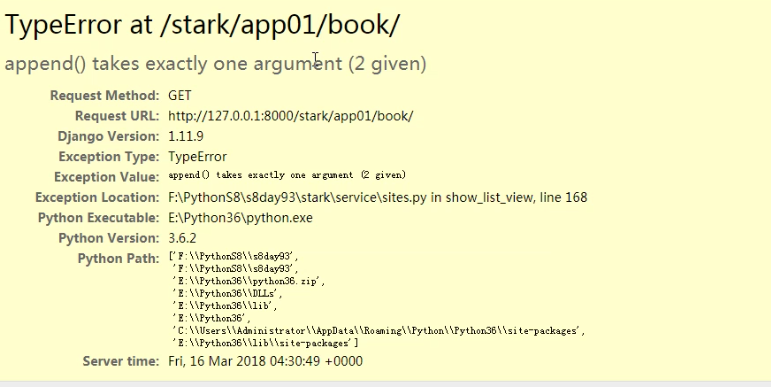

# 获取search的查询条件Q对象 def get_search_condition(self): # 搞模糊查询 from django.db.models import Q search_condition=Q() # 要搜索的条件--->Q对象 search_condition.connector="or" # 将条件改为或 if self.search_fields: # 用户配置了搜索字段 ["title",""price} key_word = self.request.GET.get("q") if key_word: # 配置了走这里,没有直接显示查询页面(正常查询) for search_field in self.search_fields: search_condition.children.append((search_field+"__contains",key_word)) # append这里需要放元组,添加到搜索条件 # __contains 为模糊查询 return search_condition

 浙公网安备 33010602011771号
浙公网安备 33010602011771号