cs231n学习笔记——Lecture9 CNN Architecture
该博客主要用于个人学习记录,部分内容参考自:[Lecture 9 ] CNN Architectures(CNN架构)、CNN Architecture
1、LeNet
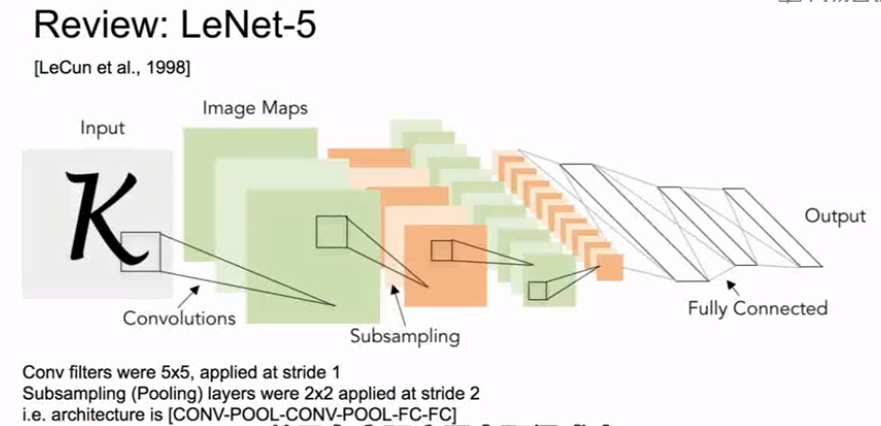
LeNet在数字识别领域的应用方面取得了成功
1、AlexNet(第一个基于深度学习的网络架构)(2012)
AlexNet的基础架构是:
CONV1 ->MAX POOL1 ->NORM1 ->CONV2 ->MAX POOL2 ->NORM2 ->CONV3->CONV4->CONV5->Max POOL3->FC6 ->FC7->FC8
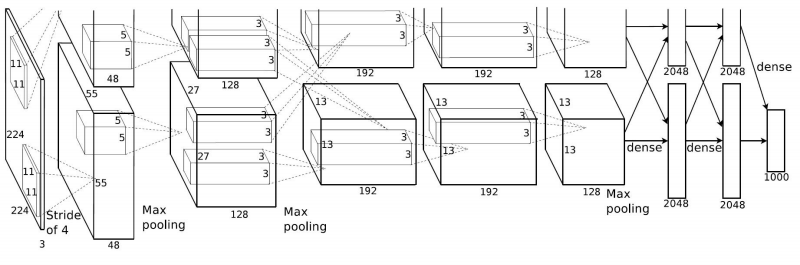
例题:假设输入:227×227×3的图像矩阵
CONV1:有96个步长为4的大小为11×11的卷积核
问:第一层输出数据的体积大小是多少?
答:利用公式\((N−F)/stride+1\),(227-11)/4+1=55,所以对每个卷积核,我们的输出都是55×55,总共有96个卷积核,则输出图像的尺寸为55×55×96.
问:在这一层中参数的数量是多少?
答:每个卷积核有11×11×3=363个参数,共有96个卷积核,所以这一层共有363×96=35848个参数。
POOL1:步长为2的大小为3×3的卷积核
问:输出数据的体积大小是多少?
答:利用公式,(55-3)/2+1=27,输出图像大小为27×27×96.
问:在这一层中参数的数量是多少?
答:0,对于池化层来说,我们只需要观察池化区域并取最大值,所以没有需要训练的参数。

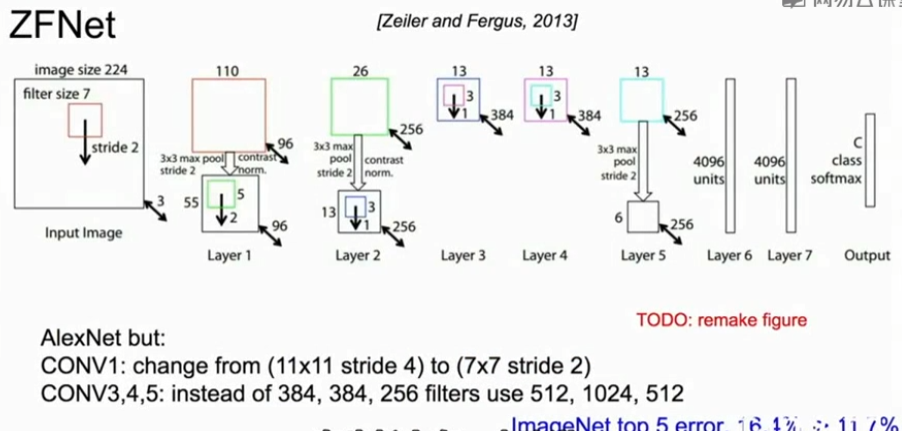
3、ZFNet(2013)
在超参数上对AlexNet进行了改进,ZFNet与AlexNet有相同的层数,相同的基本结构,在步长上有一点改进,卷积核数量略有不同,通过超参数的改进使错误率有所提高
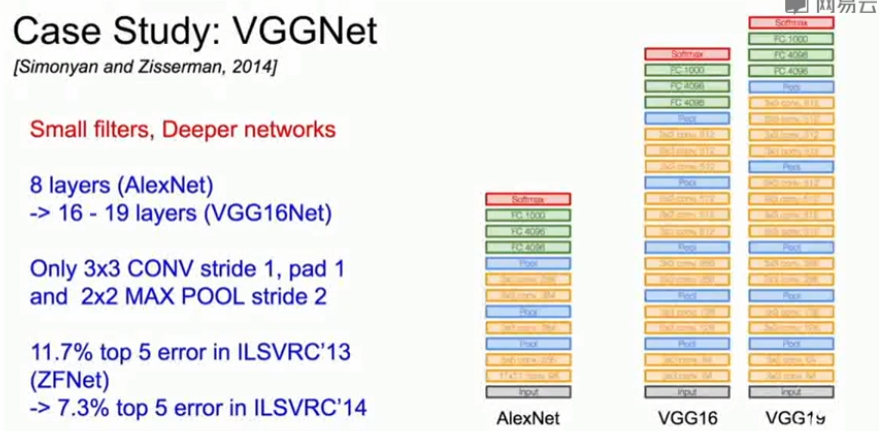
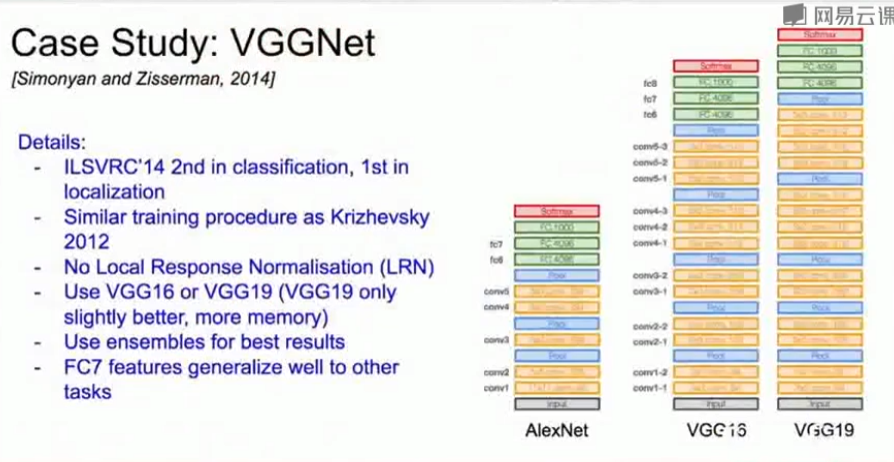
4、VGGNet(2014)
- VGGNet是一个层数很深的网络,VGGNet从AlexNet的8层扩展到了16-19层。
- 包含非常小的卷积核。关键是固定使用了3×3的小卷积核和2×2的池化核。
- 通过堆叠多个3×3的卷积核来代替大尺度的卷积核(减少所需参数)
- VGG的设计规则
- 所有的卷积层都是大小为3×3,步长(stride)为1,边界扩充(pad)为1的。
- 所有池化层都是大小为2×2,步长为2的。
- 有5个卷积阶段
- conv-conv-pool
- conv-conv-pool
- conv-conv-pool
- conv-conv-conv-[conv]-pool
- conv-conv-conv-[conv]-pool (VGG19 have 4 conv in stage 4 and 5)
- 通过插入ReLU,两个3x3卷积层可以具有更多的非线性
问:为什么要用更小的flters?
答:3×3的 conv(步长为1),堆叠起来感受野(receptive field)与一个7×7的卷积核相同。但是,其参数量更小,计算量更少,而且能够组成更深的网络,更多的非线性激活,形成的特征更丰富。
问:三个3×3卷积层(步长为1)的有效感受野(receptive field)是多少
答:7×7。可以通过堆叠2个3×3的卷积核替代5×5的卷积核,堆叠3个3×3的卷积核替代7×7的卷积核,拥有相同的感受野。

- 存储量主要是在前面的卷积层中,所以,对于后面的卷积层我们可以适当的增加通道数来丰富特征表达;
- 参数量主要集中在全连接层,因为全连接层是密集连接。
5、GoogleNet(2014)
- GoogleNet是一个更深的网络结构,有22层
- 它设计了一个高效的 inception 模块来进行组合卷积。然后再每一层中叠加该模块。
- 顶层没有使用全连接层,减少了大量的参数。
- GoogleNet只有500 0000个参数,比AlexNet少了12倍,AlexNet中有6000 0000个参数。
Inception模块
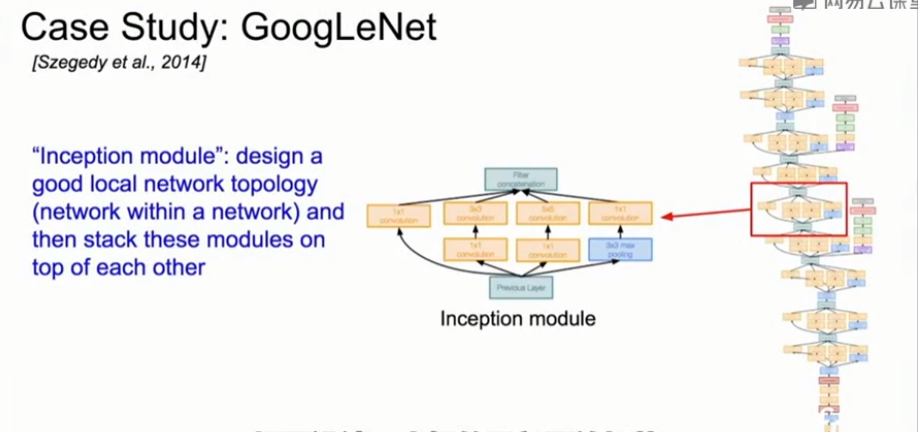
-
调用Inception模块,对进入相同层的相同输入并行应用几种不同的卷积操作。对于来自前面层的输入,进行不同的卷积,像1×1卷积,3×3卷积,5×5卷积,以及池化操作,这样就可以在不同层中得到不同的输出,这些层要做的就是把所有filter输出并在深度层面上串联起来,然后在最后得到一个张量输出,这个输出将进入下一层。
-
Inception module原始的设计如下图所示:
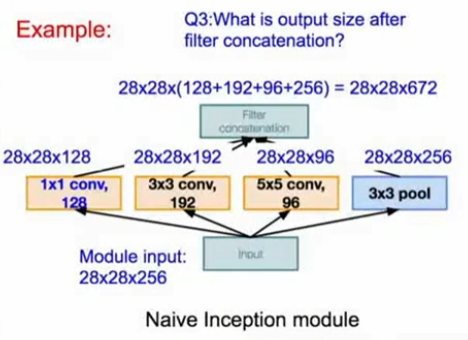
- 保留了相同尺寸,又扩充了深度
- 通过零填充(zero padding)保持卷积尺度不变
- 低层特征经过inception module提取,又把特征混合在一起,空间大小不变,得到一个更深的输出。
-
原始的Inception module存在的问题
- 计算量很大

- 池化层保留了原始输入的深度,所以每一层的深度只能增加。你将会从池化层得到全特征的深度,同时从卷积层得到额外的特征图,把他们加在一起,所以上图中输入是256的深度,但输出却是672的深度,随着继续执行,深度会增加。
- 计算量很大
-
针对原始Inception module的解决方案
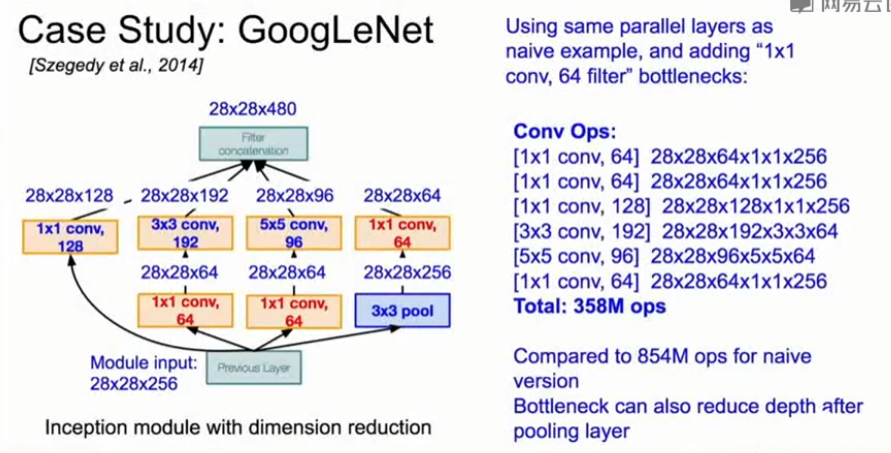
在3×3和5×5卷积层之前使用1×1先通过1×1卷积的Bottleneck层,在池化层之后也会通过1×1卷积的Bottleneck层,以减少深度,降低计算量。
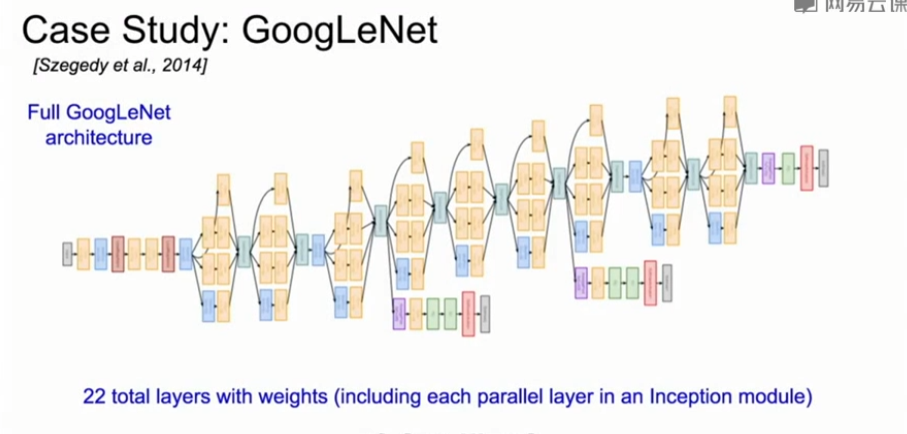
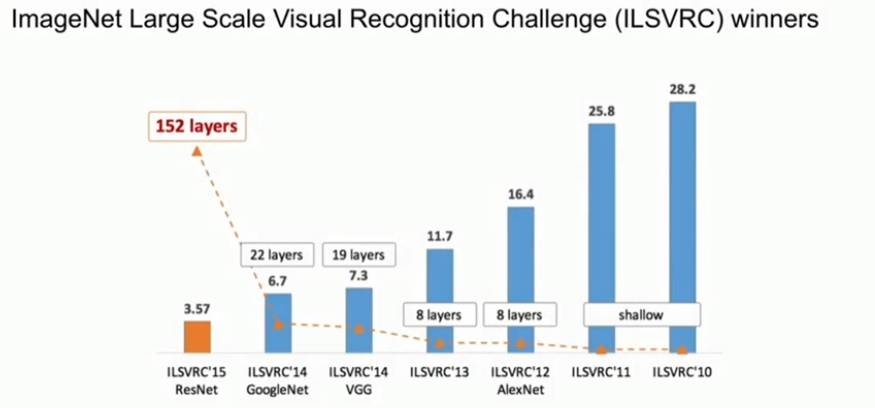
6、ResNet(2015)
ImageNet比赛中用了152层的模型,是使用残差连接的深度网络。
引入
问题:深层网络比浅层网络表现得差,但这不是由过拟合引起的
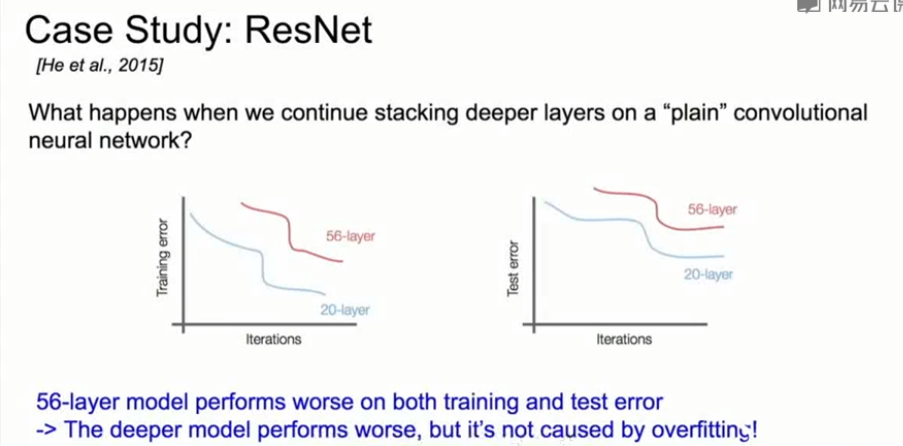
假设:这个问题是一个优化问题,越深的网络越难优化。所以深层网络应该至少和浅层网络表现得一样好。一个解决方法是,可以尝试通过设置额外层把浅层模型恒等映射到更深的模型中。
解决方法:使用网络层来匹配一个残差映射,而不是直接尝试匹配所需的底层映射。如下图所示。
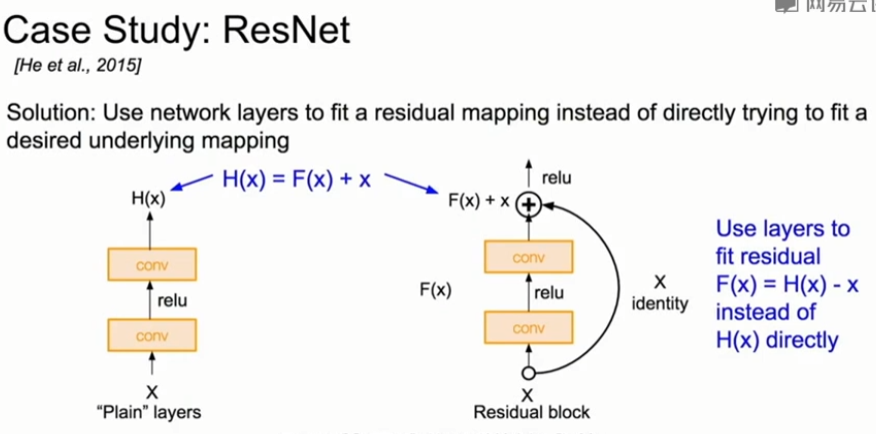
未加残差结构时,学习映射为H(x),但是H(x)不容易学;加上残差结构后,学习映射为F(x)=H(x)-x,学习F(x)比学习H(x)容易,那么通过学习F(x)来得到H(x)=F(x)+x,这就是残差结构。F(x)就是指残差。
完整的ResNet结构
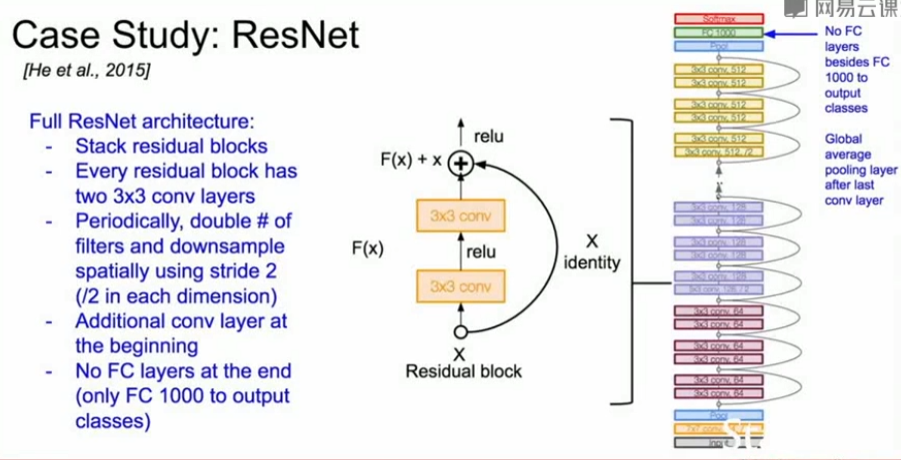
- 堆叠残差块
- 每个残差块都有两个3×3的卷积层
- 周期性使用尺寸大小为3x3,步长为2的卷积核进行下采样
- 网络最开始增加卷积层
- 在网络最后一层没有使用全连接
对于更深的网络(超过50层),ResNet使用“bottleneck”层减少计算量(和GoogLeNet相似)。

在实践中的训练细节
- 在每个卷积层后加上了Batch Normalization
- 使用Xavier/2来初始化参数
- 使用SGD+Momentum(momentum=0.9)
- 初始学习率设为0.1,每到验证误差高原期(validation error plateaus)的时候就下降10倍
- Mini-batch size 256
- 权重衰减weight decay 设为1e-5
- 没有使用dropout,因为BN已经减少了过拟合,而且效果很好
7、比较
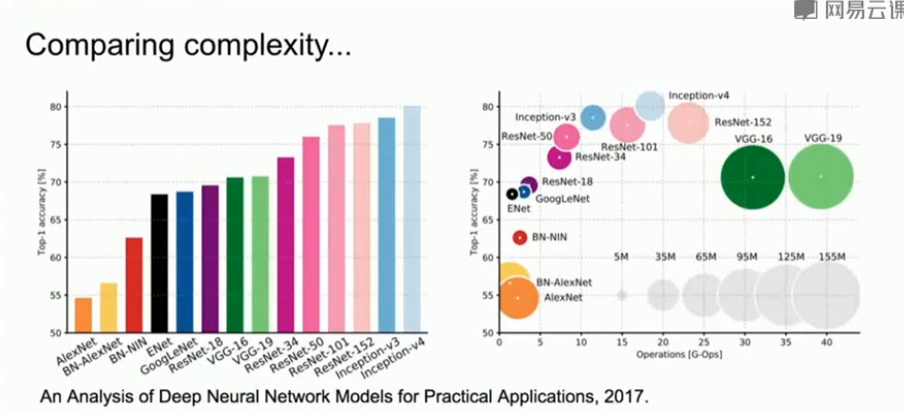
- VGG:效率最低,使用最多内存,但表现得确实好
- GoogleNet:最高效
- AlexNet:精确度最低,计算量很小,但占用内存很大。
- ResNet:在内存使用和操作复杂度之间平衡,但精确度最高
- GoogleNet和ResNet没有使用大型的全连接层,而是在神经网络末端使用全局平均池化global average pooling,大幅降低参数数量。

8、其他架构
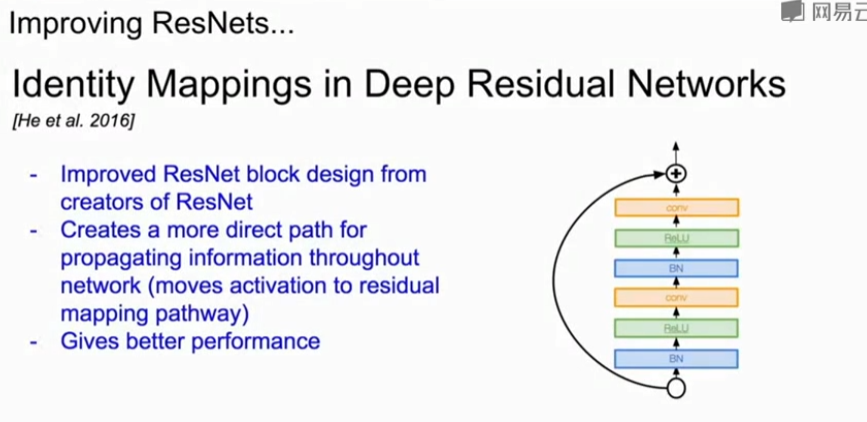
(1)基于ResNet
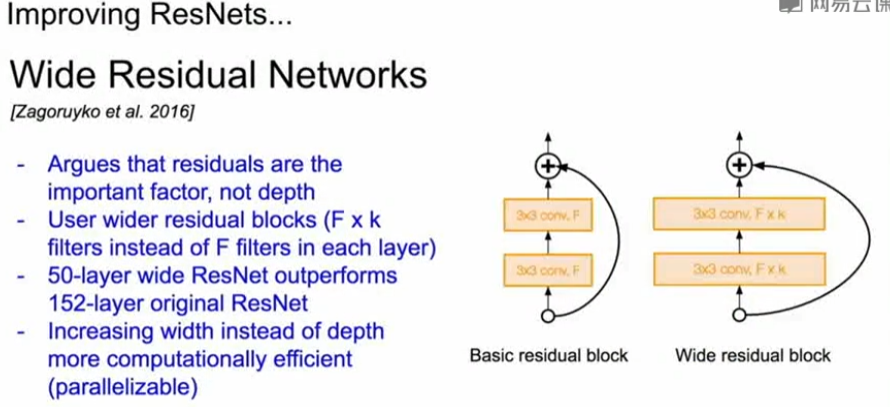
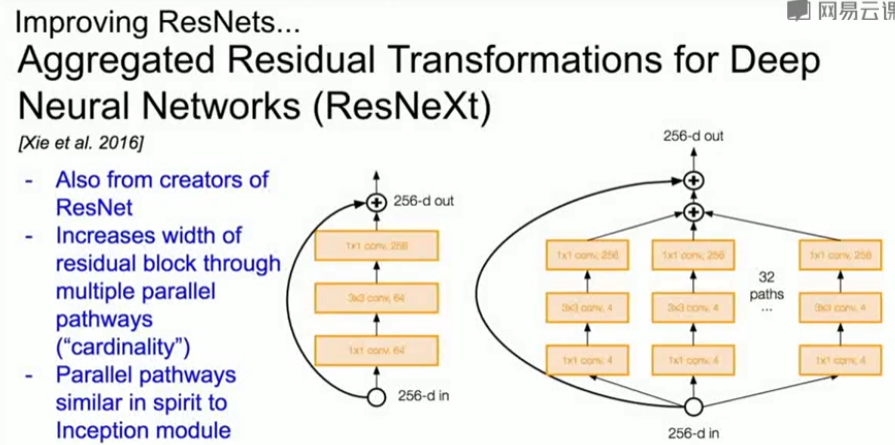

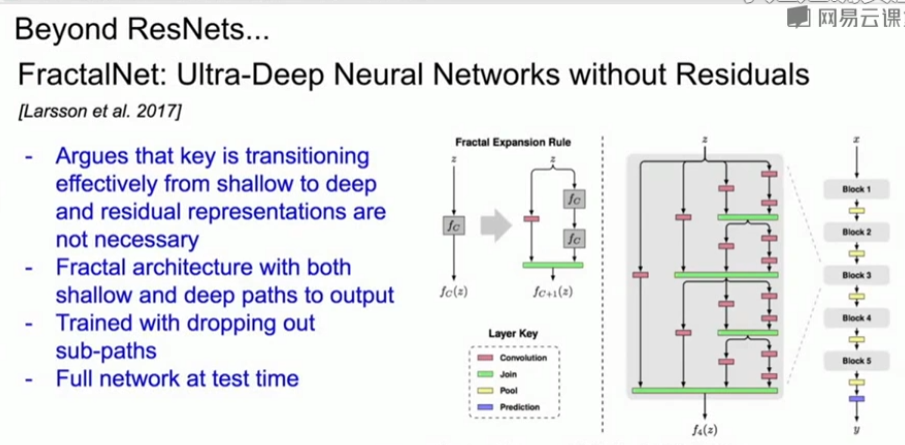
(2)非ResNet的网络,但可以与ResNet媲美的网络
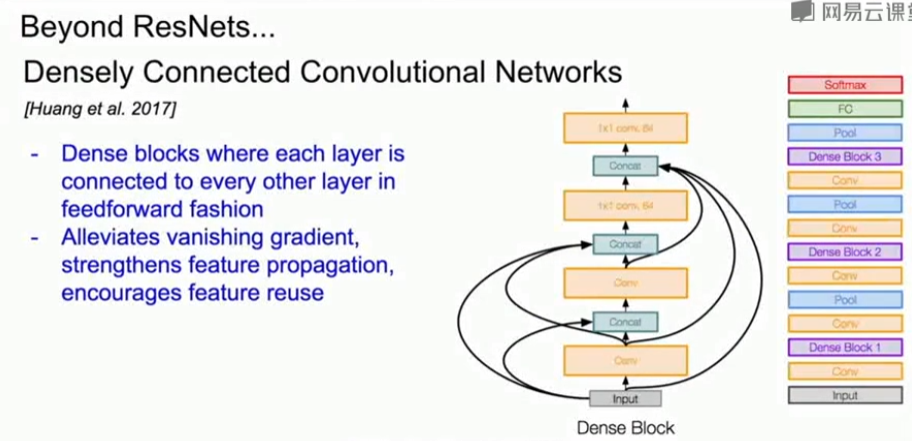

总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号