cs231n学习笔记——Lecture7 Training Neural Networks
该博客主要用于个人学习记录,部分内容参考自:CS231n笔记七:训练神经网络3(优化方法)、局部最小值(local minima)和鞍点(saddle point)
一、更好地优化Fancier Optimization
1、随机梯度下降(Stochastic Gradient Descent)
(1)SGD的问题
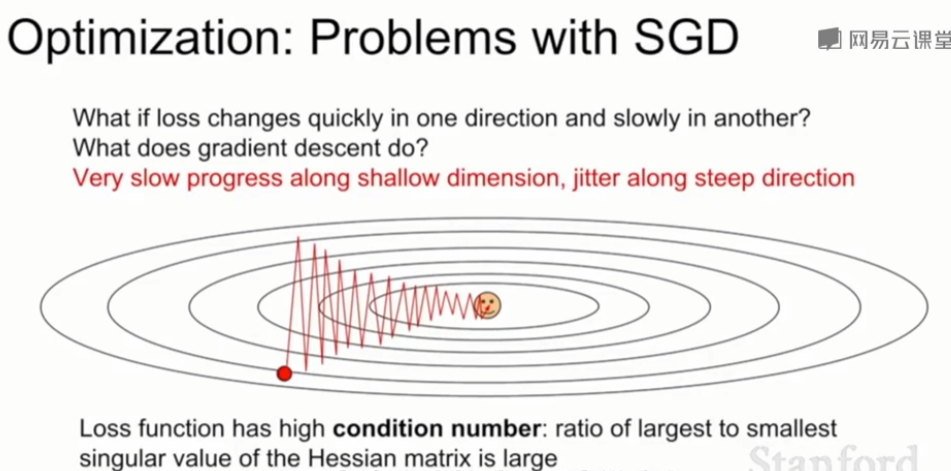
①损失函数对一个参数很敏感(在该维度变化很快),对其它参数很不敏感
以二维为例,在水平方向变化很小,竖直方向变化很大,呈现之字形。这个问题在高维空间更加普遍,高位空间中包含了大量参数,将会沿着上亿方向运动,在这上亿个不同运动方向上,介于最大值和最小值的方向上的比例可能很高,SGD表现得不好
②局部极小值或鞍点(local minima or saddle points)
-
局部极小值local minima:当前所在的位置是损失最低的点,四周都比这个位置高,卡在局部极小值,可能没有路可以走。
-
鞍点 saddle points:图中可见红点处左右比红点高,前后比红点低,卡在鞍点时,鞍点旁是存在使损失更低的路的,只要逃离鞍点,就可以让损失更低。

-
这两点处的梯度均为0,统称为critical point。在一维空间中似乎局部极小值的问题比较大,鞍点不太需要担心。但在高维问题中,问题更多出现在鞍点,鞍点意味着在当前点上,某些方向上损失会增加,某些方向损失会减小,这基本会在任何点上发生。

- 有时候可能不会恰好发生在鞍点上,可能会在鞍点附近,上图中的的第二个例子可以看见在鞍点附近,梯度并不是0,但斜率非常小,这意味着如果我们向梯度方向前进但梯度非常小,任何时候当当前参数值在目标等高线上接近鞍点时前进都会非常缓慢。
③梯度来自于minibatch,因而可能有噪声
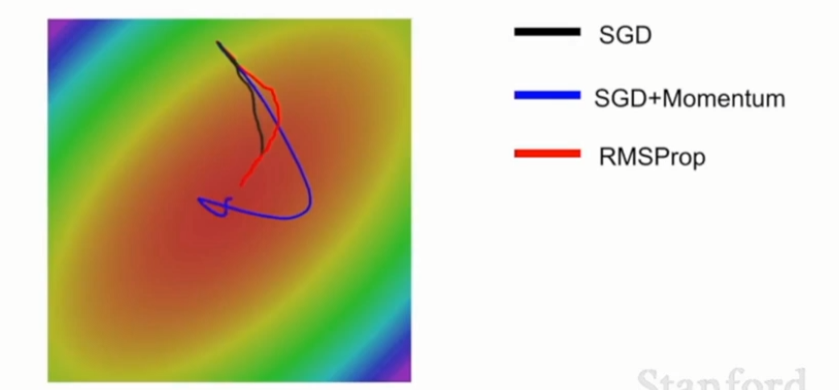
由于整个训练集大小很大,计算梯度的代价很高,所以通常只会在mini batches上计算损失和梯度,从而估计真实梯度,这样的估计可能会产生噪声,导致优化路径曲线拐弯,耗时。下图中对每一点加入随机均匀噪声,在这样的噪声条件下运行SGD,搞乱了梯度,传统的SGD在这种噪声大的环境下可能耗时比较长才能得到极小值。

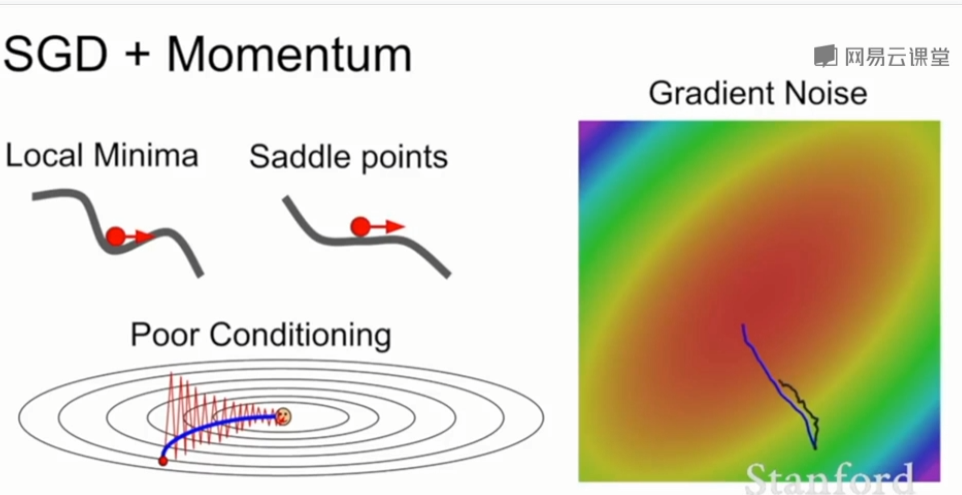
(2)SGD + Momentum

- 新增一个速度变量vx,每次参数不再在梯度的方向上更新,而是在速度的方向上更新
- 速度就像梯度的运行平均值,ρ表示“摩擦系数”
- 速度和梯度做矢量加权和。
- SGD + Momentum可以完美解决SGD的所有问题
- 想象一个球滚下山,它的速度越滚越大,那么即使我在局部极小值点或者鞍点处没有梯度,它仍然有很大的速度可以继续滚下去,不会轻易被卡住。
- 有了速度之后,zigzag的梯度可能在计算速度时就被抵消掉了,这样实际上可以减小在敏感参数上的速度分量,反而增加在不敏感参数上的速度,就不会出现zigzag的现象了。
- 同时由于加上了动量,噪声会被抵消掉一些,从而使优化过程更加平滑的接近到最优值位置。
(3)SGD + Nesterov Momentum
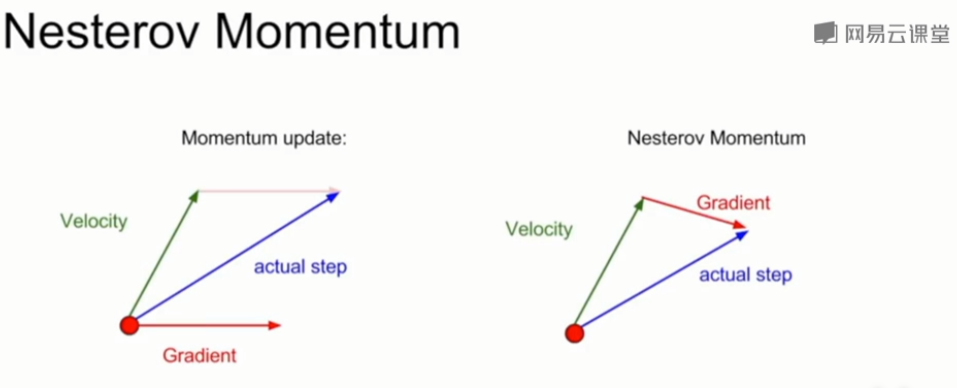
- 在传统的动量优化中,我们首先计算该点的梯度,然后用梯度去修正当前的速度,得到二者的复合值作为实际前件的步长方向。
- 在Nesterov中,我们首先按照现有的速度方向前进,然后计算前进后的点的梯度,再回到初始位置将这两者复合起来,得到最终正确的位置

(4)对比
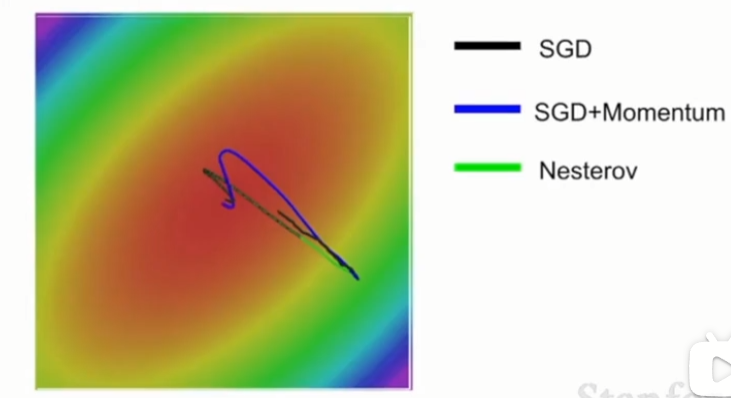
从下图中看出,SGD会被困在这个局部极小值点处,SGD+Momentum和Nesterov会借助他们构建的速度越过这个局部极小值点,所以这两个方法可以自我修正达到真正的极小值点。SGD+Momentum和Nesterov的不同点在于,Nesterov有摩擦因子,所以它不会那么剧烈地越过局部极小值点。
2、AdaGrad(通常不用)
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared += dx * dx #❗❗❗
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
-
累加梯度的平方,然后把步长除以平方。
-
假设我们有两个坐标轴,沿其中一个轴梯度很高,沿另一个轴梯度很小。在小梯度维度上,随着我们累加小梯度的平方,在最后更新参数向量时除以一个很小的数字以加快在小梯度维度上的学习速度。在另一个维度方向,由于梯度很大,所以我们除以一个非常大的数,以降低大梯度维度方向上的训练进度。
-
在训练过程中使用AdaGrad,步长会变得越来越小,因为我们一直在更新梯度平方的估计值,所以这个估计值一直在随时间单调增加,这会导致我们的步长随时间越来越小。
- 对于凸函数来说,这个特征很不错,这使得我们在接近最优值时找的很慢,也就是很细致,最终达到收敛。
- 但是对于非凸函数来说,就会变得很复杂了,因为你可能会在局部最优点附近移动得越来越慢,最终卡在局部最优值的位置。
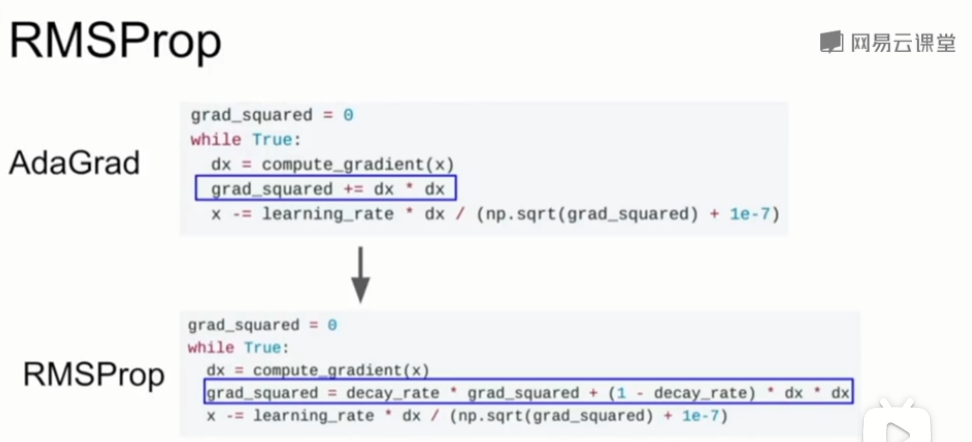
3、RMSProp(AdaGrad的变体)
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx * dx #❗❗❗
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
-
在RMSProp中,我们还是会计算梯度平方的和,但是在累加时会让梯度平方按照一定比例衰减,防止累加和无限制的增大。
-
在RMSProp中,我们还是会计算梯度平方的和,但是在累加时会让梯度平方按照一定比例衰减,防止累加和无限制的增大。
4、Adam
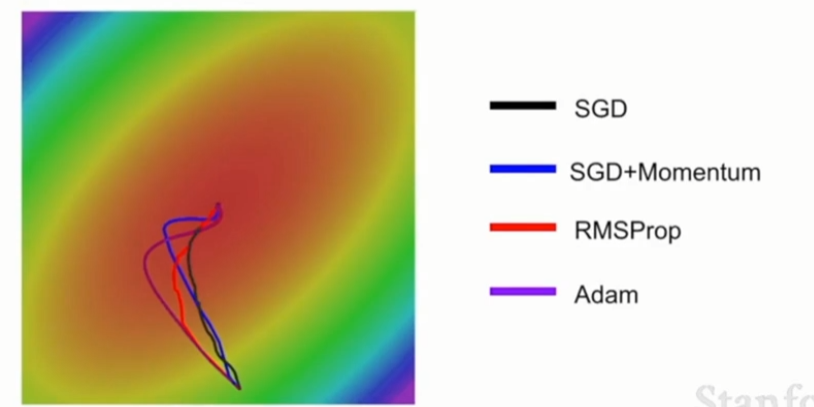
(1)Adam版本一:类似Momentum+RMSProp
我们人为的把第二动量初始化为0了,那么在第一次移动时,最后一个式子中除以第二动量(+1e-7是用来保证我们不会除以0的)也是一个非常接近0的数(因为beta2一般很大,所以dx*dx在第一步时不会有什么贡献),那么这就导致我们在第一次移动时会以一个很大的步长移动,那我的初始化工作就全毁了。

(2)Adam版本二(首选)

- 构造了第一第二动量的无偏估计,让它们除以(1 - beta ** t),这样可以防止一开始的动量特别小导致步长很大。在 t 很小时,(1 - beta ** t)会很接近于0,这样一除之后两个unbias值都会比较大,可以防止最后一行算出来步长很大的情况出现。
- beta1 = 0.9, beta2 = 0.999,learning_rate = 1e-3 or 5e-4 的Adam对于很多模型来说是一个很好的起点(首选)
- Adam实际上结合了SGD + Momentum和RMSProp
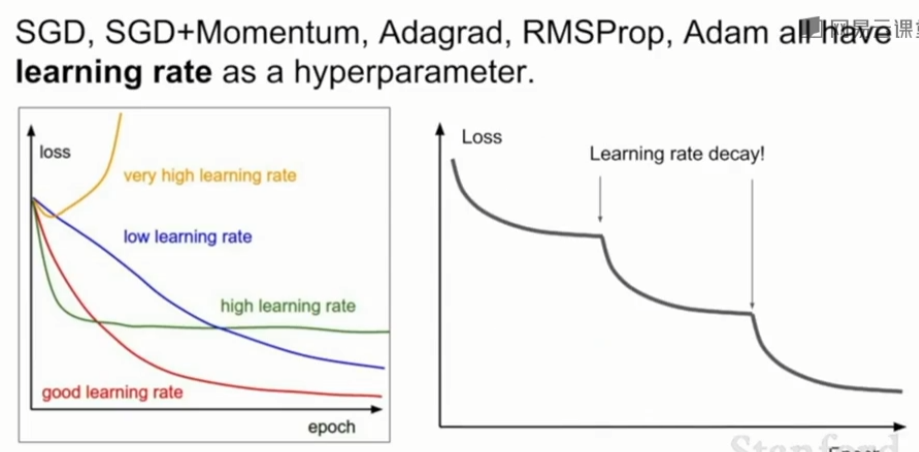
5、学习率
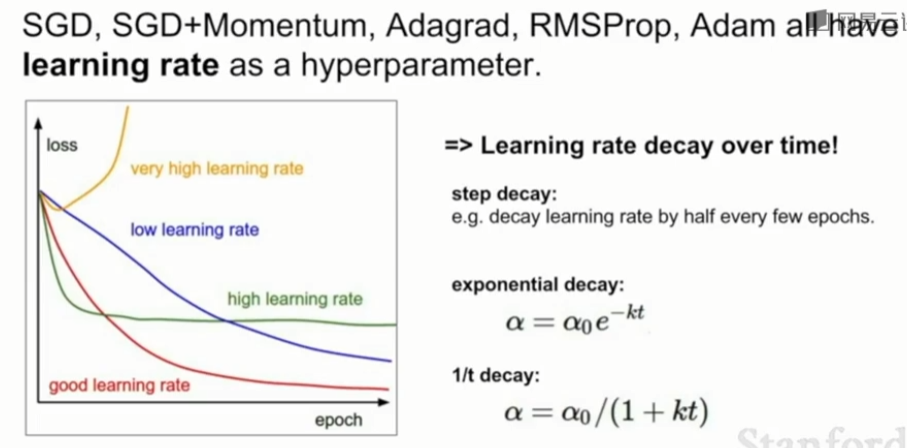
-
学习率太高,损失函数会爆炸增长,如黄线。
-
学习率太低,要花很长的时间才收敛,如蓝线。
-
learning rate decay
学习率的设置技巧是,我们不必在整个训练过程中一直固定使用同一个学习率,有时人们会将学习率沿着时间衰减。一开始用比较大的学习率,训练到达一定程度后,逐渐降低学习率。实践中的一般做法是先尝试不用衰减,仔细观察损失曲线,看看希望在哪个位置开始衰减。 -
学习率连续衰减的做法
- step decay
每过几个epochs将学习率减小一定程度。 一个启发式方法是在使用固定学习率进行训练时监测验证误差,每当验证错误不再提高时就将学习率减小一个常数(比如0.5)。 - 指数衰减Exponential decay
\(\alpha=\alpha_0e^{-kt}\),其中\(\alpha_0\),\(k\)是超参数,\(t\)是时间(可以是以iteration为单位也可以以epoch为单位) - 1/t decay
\(\alpha = \alpha_0/(1+kt)\),其中\(\alpha_0\),\(k\)是超参数,\(t\)是时间,以iteration为单位
- step decay
-
用步长衰减的学习率
曲线出现骤降的地方是在迭代时把学习率乘上了一个因子
6、一阶优化、二阶优化
(1)一阶优化
我们之前提到的算法都是一阶优化算法,我们在当前的红点上求一个梯度,用梯度信息来计算这个函数的线性逼近,相当于对曲线做一阶泰勒逼近.这要求我们的步长不能太长,因为实际上我们用梯度算出来的方向只是一个切线方向,沿这个方向走得太多可能会导致我们偏离实际方向。

(2)二阶优化
-
同时利用一阶偏导和二阶偏导的信息,对loss函数做一个二阶泰勒逼近,也就是用一个二阶函数来逼近loss。这样的逼近通常更加准确,这样我们可以直接跳到二阶函数的最小值处,也不会偏离真实方向多远。也就是说在传统二阶优化方法(牛顿法)中是没有学习率的。
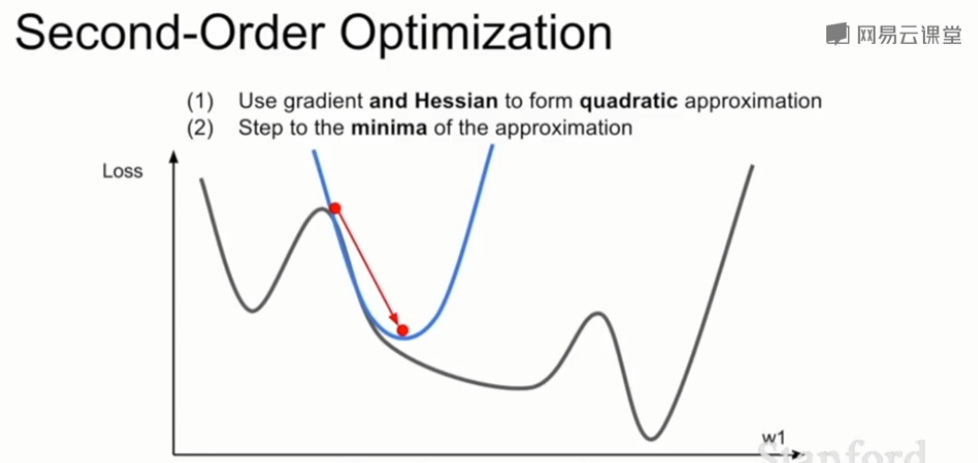
-
海森矩阵是N*N的,N表示网络中参数的数量,如果N太大,内存装不下,所以无法求矩阵的逆

-
事实上,常用拟牛顿法来代替牛顿法,不需要直接求完整的海森矩阵的逆,而是逼近这个矩阵的逆,常见的是低秩近似

-
L-BFGS
- 通常在全批量、确定性模式下表现得很好
- 没有完整储存整个海森矩阵的逆
- 对随机情况的处理不好。L-BFGS是一个二阶优化器,它是二阶逼近,用海森矩阵来逼近,实际上很多深度学习算法并不适应这个算法,因为这些近似对随机情况的处理不多,而且在非凸问题上表现得不是很好。
训练误差和测试误差相差很大意味着过拟合,如何才能减少训练和测试之间的误差差距使得我们在未知数据上表现得更好?
6、模型集成Model Ensembles
- 训练多个独立模型,并在测试时对其结果进行平均
- 相同的模型,不同的初始化
- 交叉验证期间发现的顶级模型
- 如果在训练过程中收集模型的快照snap,用这个快照作为备选模型,会减少训练的次数从而提高效率。一种方法是在训练过程中疯狂调整学习率,一会大一会小,这样模型的参数就可能会收敛到目标函数的不同区域里,给它们记录下来,这样就可以通过一次训练得到多个不同的模型,最后看哪个更好即可。
- 使用测试时参数向量的移动平均值
二、正则化Regularization
前面提到的模型集成告诉我们如何从众多模型中选出一个最好的,但我们更关注如何提高一个特定模型的性能。我们可以在模型里加一些正则化项,这样可以有效防止过拟合,从而在测试集上得到更好的正确率。
1、Dropout
在每次正向传播的过程中,会在每一层随机选择一些神经元置0(即把这一个神经元的激活函数的输出值置为0),每次正向传播中被随机置0的神经元都不是完全相同的。
如下图,左边是正常的全连接网络,右边是经过dropout的网络。置0后的网络中相当于只有一部分神经元起效,且每次正向传递时被置0的神经元都不同,也就是每轮迭代时有效的神经元都是随机选取的。
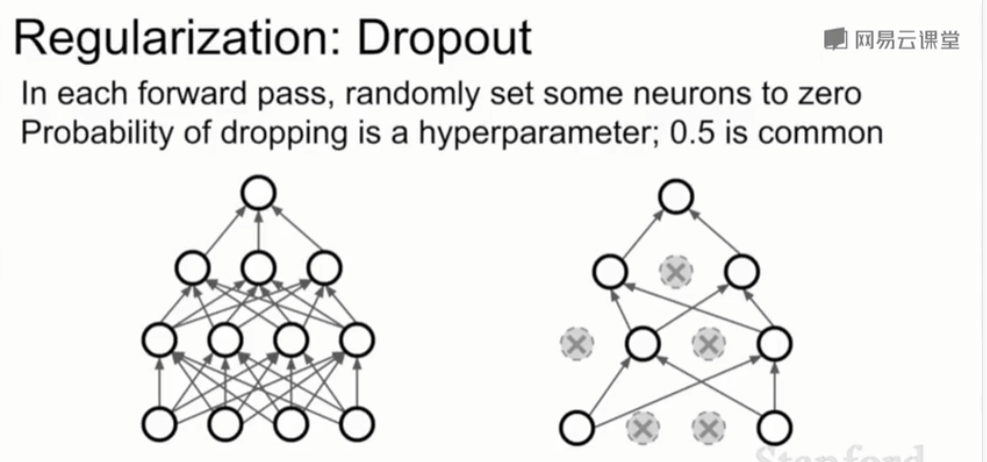
一般是在全连接层使用dropout,有时在卷积层也有。当使用卷积层时,可能不是随机把某个神经元上的激活函数的结果置零,而是随机把整个特征映射置零, 在卷积神经网络中有一个维度表示通道,可能要把整个通道置零。
dropout把神经网络的基本运算做了改变,之前只需要把x和W做点乘作为输出即可,dropout额外增加了一个随机输入z表示dropout中被置零的项,用来决定哪些神经元会被置为0。\(y=f_W(x,z)\)
但这会引入随机性,也就是我们的输出output是不确定的,它取决于z的取值。这在训练的时候还是可以接受的,但在测试的时候是不可接受的。所以想要对测试结果做平均化“arange out the randomness”,来消除这种随机性。
假设通过积分来边缘化随机性,但实际上这个积分很难求解.\(y=f(x)=E_z[f(x,z)]=\int p(z)f(x,z)dz\)
还可以通过采样来近似这个积分,对z多次采样,在测试时把它们平均化,但这仍会引入随机性。

✅一种好的办法是:
考虑单个神经元,在没有随机掩码z时,它的输出应该是\(w_1x + w_2y\);而在有随机掩码的训练过程中,假设将一个神经元置0的概率为0.5,那么我们对总共4种掩码z做加权求和,得到输出应为\(1/2(w_1x + w_2y)\),这个是训练时的平均输出结果。我们会发现这个结果和之前假设没有掩码时的结果有一个很明显的倍数关系,而倍数就是将一个神经元置0的概率0.5。因此在测试时,我们可以按照无掩码的情况正常计算输出值,最后在输出值前乘一个将神经元置0的概率p,即可得到平均化的输出结果。(注意是给每个神经元的输出值都乘p!!)

"""
Inverted Dropout: Recommended implementation example.
We drop and scale at train time and don't do anything at test time.
"""
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
2、Inverted dropout
在测试的时候我们希望有更高的效率,所以消除乘以概率p这一额外的乘法。那么我们可以选择inverted dropout,也就是不在测试时乘p,而在计算训练时神经元的输出结果时除以一个p,因为训练通常在GPU上进行,它很快。

p = 0.5
def train_step(X):
# forward pass for 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # first dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
def predict(X):
# ensembke forward pass
H1 = np.maximum(0, no.dot(W1, X) + b1) * p
H2 = np.maximum(0, no.dot(W2, X) + b2) * p # scale at test-time
out = np.dot(W3, H2) + b3
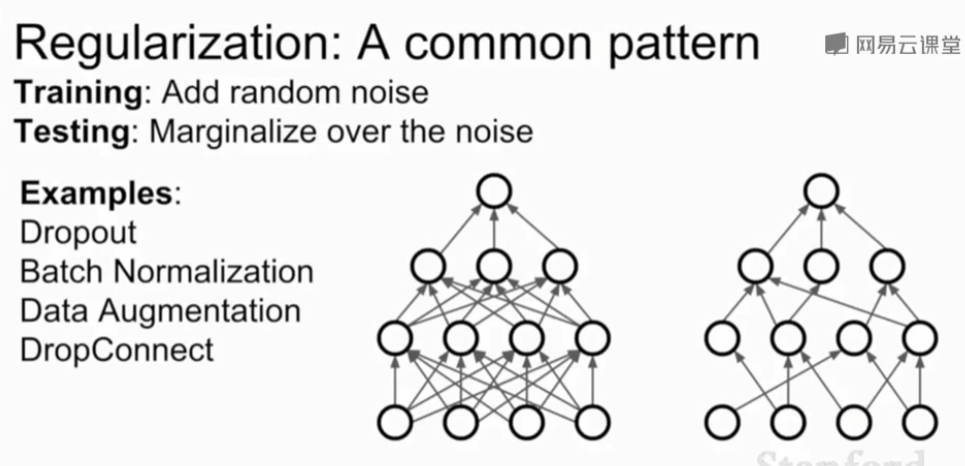
批量归一化也是一种正则化。
批量标准化操作相同:在训练时添加噪声或随机性,并在测试时将其平均
3、数据增强Data Augmentation
- 在训练过程中在不改变标签的情况下以某种方式随机地转换图像来增加随机性
- 如翻转、剪裁、色彩抖动(在训练时随即改变图像的对比度和亮度)
4、DropConnect
DropConnect和dropout类似,区别是它将权重矩阵的一些值置0。
5、部分最大池化Fractional Max Pooling
在池化层中随机池化部分区域。
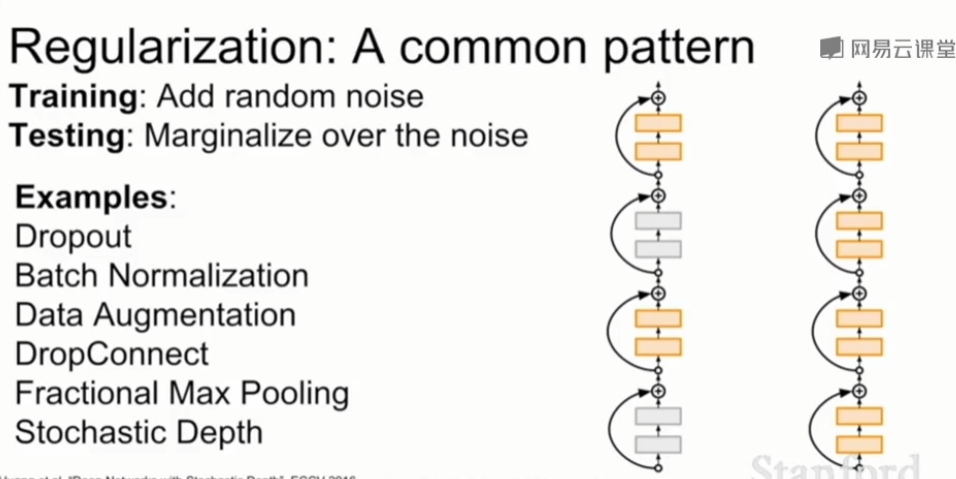
6、随机深度Stochastic Depth
在训练时随机丢弃一些层,只用部分层,在测试时使用全部的网络。
7、小结
大多数情况下单独使用batch normalization就足够了,如果仍存在过拟合的情况,可以尝试dropout或其他方法.
三、迁移学习Transfer Learning
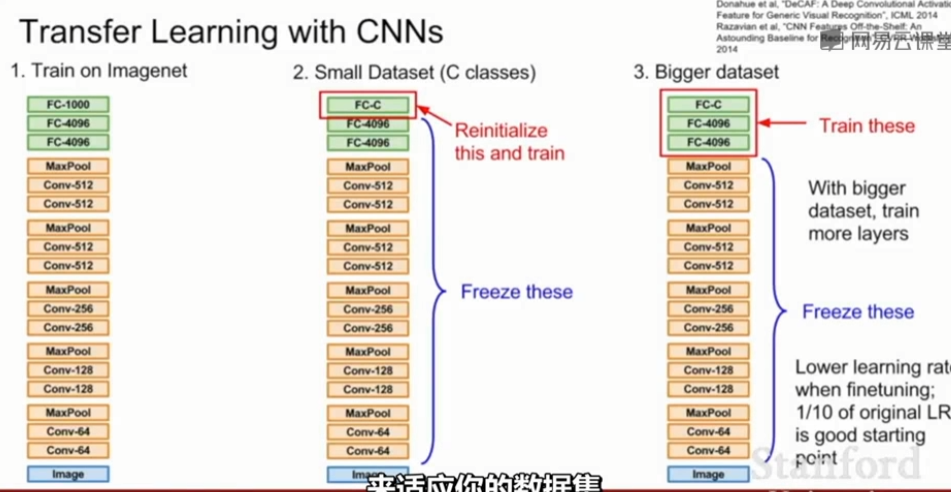
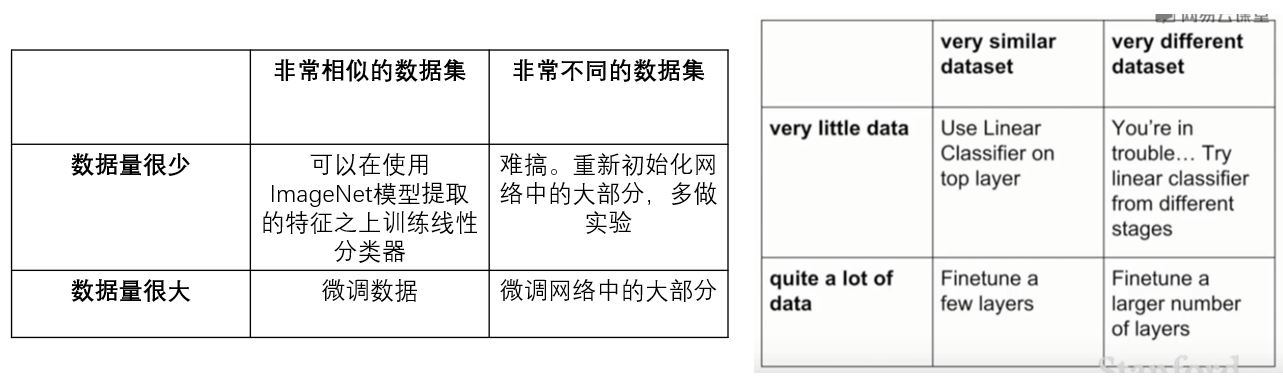
如果想训练一个很复杂的网络,但没有一个足够大的数据集,那么迁移学习可以用来解决这个问题。
例如我想做分类的任务,分出来十种狗的品种,但狗的数据集很小,不足以训练整个网络,那么我可以先用一个大数据集,如imageNet,来训练我的整个神经网络。在整个网络的参数都训练完之后,我只需要修改最后一个全连接层的权值矩阵,比如原来训ImageNet时它是1000*4096的,而训狗是需要10 * 4096的矩阵,那么我就只要换一个矩阵并且求出来这个矩阵里面的参数即可。对于前面的所有矩阵,我都沿用ImageNet训出来的参数即可。
如果你的可用数据集更大一些,那么不光可以训最后一个全连接层,还可以适当的finetune一下之前的权值参数。通常finetuning时的学习率要设小一点,一般设为之前学习率的十分之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号