cs231n学习笔记——Lecture2 Image Classification
该博客主要用于个人学习记录,部分内容参考自 李飞飞笔记、cs231n计算机视觉课程笔记、图像识别算法(一)、cs231n笔记2—线性分类
一、图像识别Image Classification
1、在CV中的一个核心问题
图像识别的任务就是给输入的一张图像一个标签。
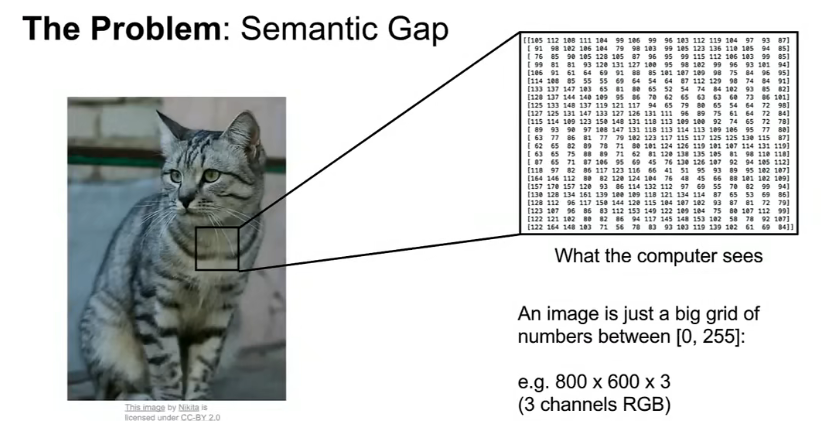
2、问题:语义鸿沟Semantic Gap
-
计算机将图像看作是一个介于[0,255]之间的一个巨大的数字网格(An image is just a big grid of numbers between [0,255]. ) ,图像可能是800*600的像素,每个像素由三个值表示(红、绿、蓝)
-
人类可以轻松地从图像中识别出目标,而计算机看到的图像只是一组0到255之间的整数。
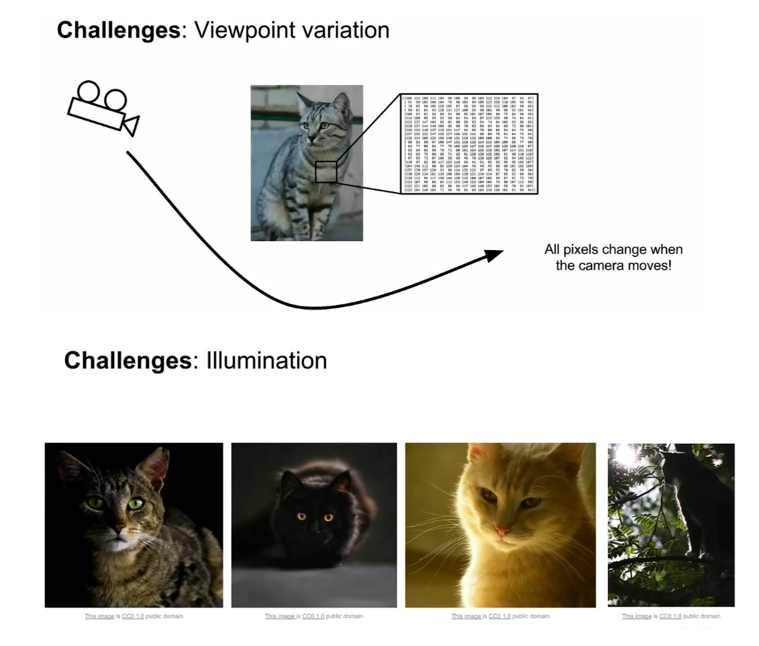
3、挑战
-
视角变化(viewpoint variation)—— 一张物体在不同角度的拍摄下也会有不一样的效果。
-
光照条件(illumination conditions)—— 照明的影响在像素级别上是剧烈的。
-
形变(deformation) —— 猫可以有很多不同的姿势和位置,我们的算法应该对这些不同类型的转换具有鲁棒性。
-
遮挡(occlusion)—— 有时只能看到对象的一小部分(少至几个像素)。
-
背景杂乱(background clutter) —— 感兴趣的对象可能会融入其环境,使其难以识别。如猫在外观上看起来与背景十分相似。
-
类内变化(intraclass variation)—— 对象有许多不同的类型,每种类型都有自己的外观。如猫有不同的形状和大小、颜色和年龄。

4、数据驱动的方法Data driven approach
与其编写一个算法指定每个感兴趣的类别的样子,不如设计一个学习算法。向计算机提供每一个类别的许多例子,然后算法通过对这些例子进行学习得到每一个类别的视觉外观,这种方法被认为是data driven approach,因为它依赖于具有标记的训练数据集。
- 收集图像和标签的数据集
- 用机器学习训练一个分类器
- 在新图像上评价分类器
def train(images, labels):
#输入图片和标签,输出模型
return model
def predict(model, test_images):
#输入一个模型,对图片种类进行预测
return test_labels
二、最近邻分类器(Nearest Neighbor Classifier)
-
在最近邻分类器中,用于比较图像的距离度量是 L1(Manhattan) distance : \(d_1(I_1,I_2)=\sum_p\left|I_1^p-I_2^p\right|\)
其在二维矩阵中的用法如下:
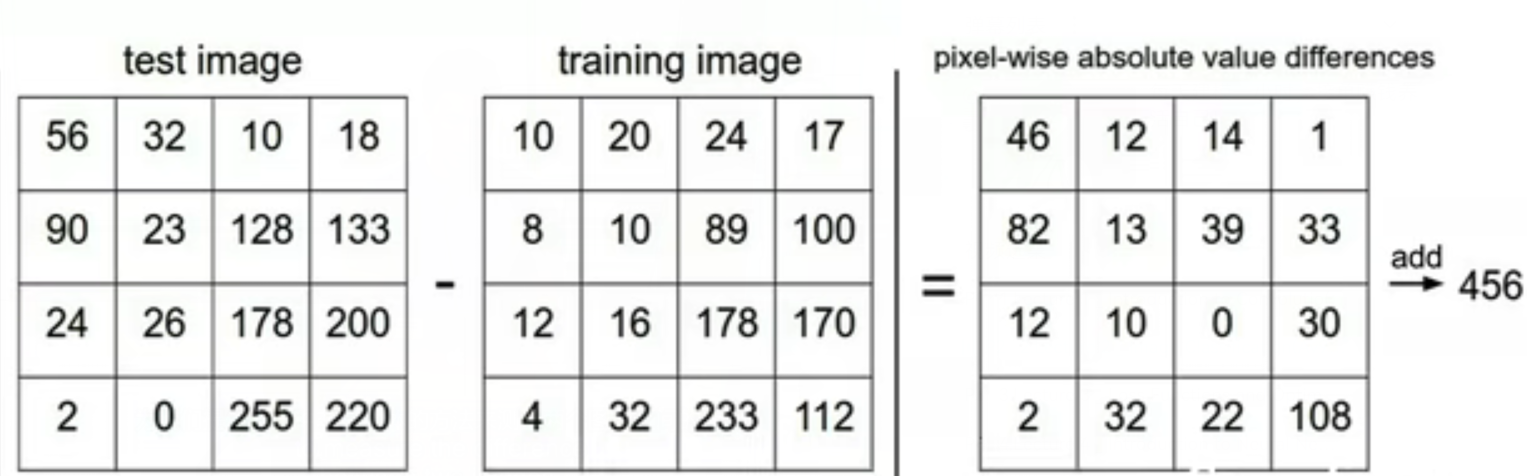
将两个图像元素相减取绝对值,然后将所有差异相加为一个数字。 如果两个图像相同,则结果为零。 但如果图像非常不同,结果会很大。 -
训练阶段train:记住所有数据和标签 —— O(1)
预测阶段predict:拍摄新图像,尝试在训练数据中找到与新图像最相似的图像,预测最相似的图像的标签。 —— O(N)
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
‘’‘ X is N x D where each row is an example. Yis 1-d of size N ’‘’
# the nearest neighbor classifier simply remebers all the tarining data
self.Xtr = X
self.ytr = y
def predict(self X):
’‘’ X is N x D where each row is an example wish to predict label for ‘’‘
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i*th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1) # using broadcast
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
We want fast at prediction; slow for training is ok
三、k-最近邻分类器(k - Nearest Neighbor Classifier)
1、Take majority vote from K closest points
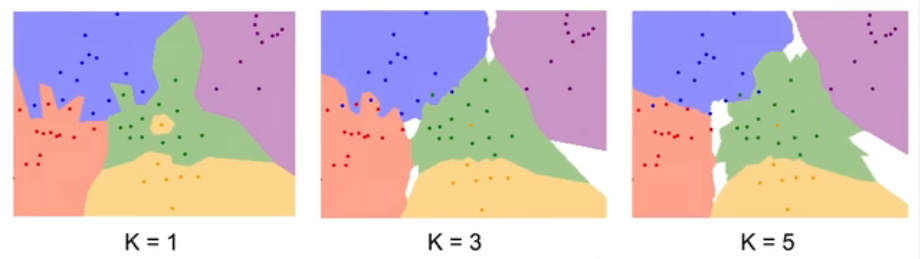
2、Chosing the Distance Metric:
-
L1(Manhattan) distance : \(d_1(I_1,I_2)=\sum_p\left|I_1^p-I_2^p\right|\)
-
L2(Euclidean) distance : \(d_2(I_1,I_2)=\sqrt{\sum_p(I^p_1-I^p_2)^2}\)
- L1距离取决于所选择的坐标轴。对于输入的特征向量,如果向量中的一些值有一些重要意义的情况,最好使用L1距离。
- L2距离不受坐标轴的影响。用于只是某个空间中的一个通用向量的情况。计算矩阵的欧氏距离(作业中会用到)
3、超参数hyperparameters
-
参数不一定是从训练数据中学习到的,相反,这些是你提前做出的关于算法的选择,没有办法直接从数据中学习。有关算法的选择是我们设定的而不是学习的。比如K、Distance Metric。
-
设置超参数:
-
❌ 选择在训练集上表现最好的超参数

-
❌ 将数据分为训练集和测试集,在训练集中设置不同的超参数训练算法,将经过训练的分类器应用于测试集中,选择在测试集上效果最好的超参数

-
✅ 将数据分为训练集train、验证集validation、测试集test,在训练集中用许多不同的超参数选择来训练我们的算法,在验证集上进行评估,选择在验证集上表现最佳的超参数,一切操作完成后将会获得在验证集上表现最佳的分类器,然后仅在测试集上运行一次,结果表示算法在未见的新数据上表现如何。注意验证集和测试集一定要有明显的区分,我们不能将测试集用于调整超参数。每当您设计机器学习算法时,您都应该将测试集视为一种非常宝贵的资源,最好在最后一次之前永远不要接触它。最后只对测试集进行一次评估,但是我们可以通过验证集去选择最合适的超参数。

-
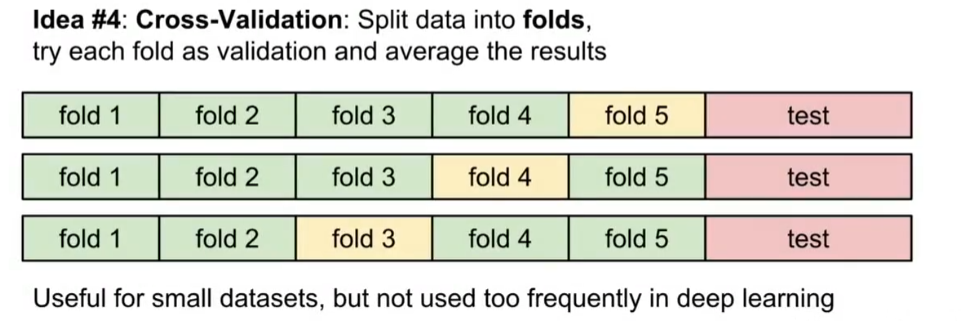
✅ 交叉验证Cross Validation:拿出一部分数据作为测试集在最后使用,剩余部分将训练集分为许多不同折,选择一折作为验证集。常用3折、5折、10折交叉验证。多用于小型数据集,但计算成本高,在深度学习中不常用。
-
人们倾向于将50%-90%的训练数据用于训练,其余的用于验证。
-
如果超参数的数量很大,可能更倾向于使用更大的验证分割。
-
如果验证集中的例子数量很少(可能只有几百个左右),使用交叉验证会更安全
-
-
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
4、KNN存在的问题
在实际中基本不用。
-
测试时间非常慢:我们通常关心的是测试时间的效率,而不是训练时间的效率。
-
像素上的距离度量不提供有效的信息。例如下图中我们视觉上可以感觉到图像之间的差异,但4张图的L2 Distance都相同,说明了L2 Distance在捕捉图像之间的感知距离方面确实做得不好。

-
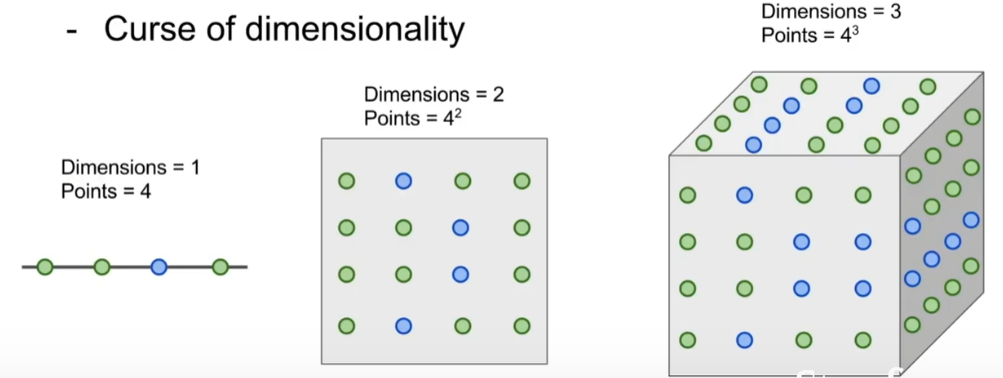
维度灾难
- 图像是高维对象(即它们通常包含许多像素),高维空间上的距离可能非常违反直觉。
- 像素距离根本不对应于感知或语义相似性。
四、线性分类Linear Classification
1、参数化方法Parametric Approach
总结我们训练数据的知识,并将所有这些知识融入到参数W中,在测试阶段不再需要实际的训练数据,只需要这些参数W。这使得我们的模型更有效,并且可以在像手机这样的小型设备上运行
2、函数 f(x,W) = Wx + b
- X: 输入数据
- W:参数或权重,对于输入x属于哪个类的可能性有多大
- b:偏置值,不与训练数据交互,只给一些数据独立的针对一类的偏好值,比如在数据集不平衡时,数量更多的那类偏差元素比其他的高,给一个数据独立缩放比例及每个类的偏移量
- 只需要做一个矩阵乘法和一个矩阵加法就能对一个测试数据分类,这比 k-NN 中将测试图像和所有训练数据做比较的方法快多了。
3、W和b的合并技巧
一个常用的技巧是将W,b两组参数组合成一个单独的矩阵,同时x向量增加一个维度,这个维度的数值为常数1,这就是默认的偏差维度。由此,新的公式将简化为: f(x,W)=Wx
4、线性分类≈模板匹配方法
一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。从这个角度来看,线性分类器就是在利用学习到的模板,针对图像做模板匹配。
5、例子
线性分类器计算图像中3个颜色通道中所有像素的值与权重的矩阵乘,从而得到分类分值。根据我们对权重设置的值,对于图像中的某些位置的某些颜色,函数表现出喜好或者厌恶(根据每个权重的符号而定)。举个例子,可以想象“船”分类就是被大量的蓝色所包围(对应的就是水)。那么“船”分类器在蓝色通道上的权重就有很多的正权重(它们的出现提高了“船”分类的分值),而在绿色和红色通道上的权重为负的就比较多(它们的出现降低了“船”分类的分值)
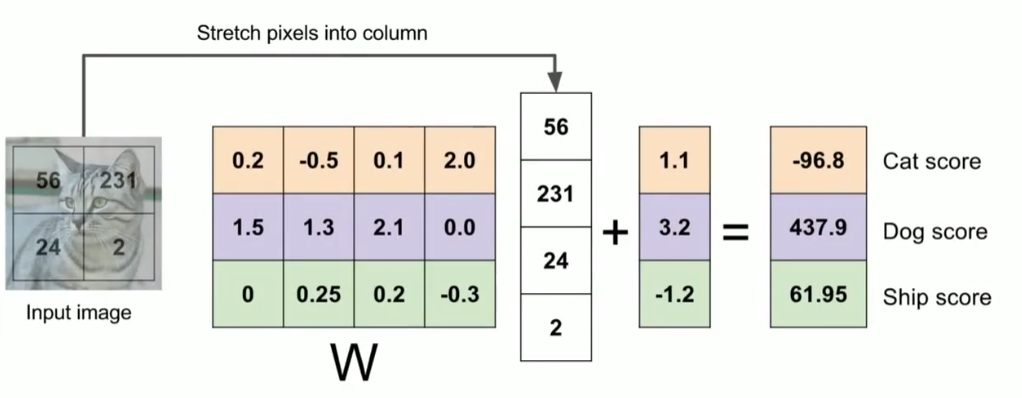
上图是一个将图像映射到分类分值的例子。为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。首先将2×2的图像像素拉伸为一个具有4个元素的列向量,与W进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个W一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
6、图像数据预处理
将原始像素值从[0,255]更改为[-1,1]
7、线性分类器的问题
每个类别只能学习一个模板
8、线性分类器的困境
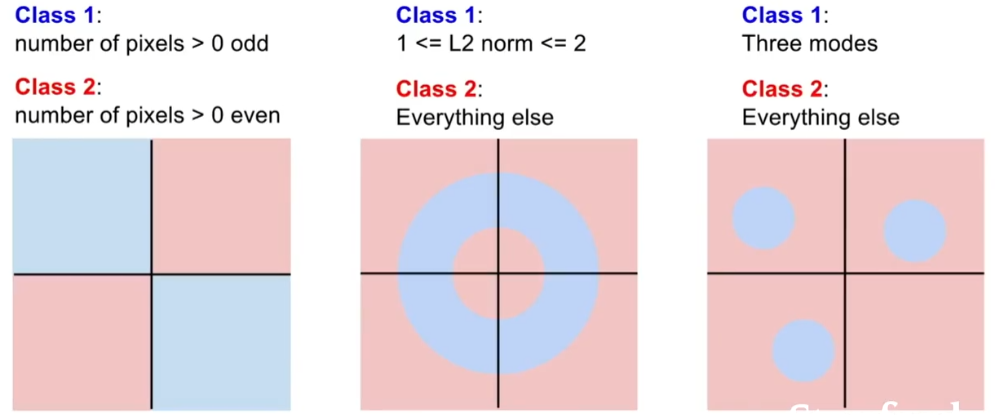
多模态数据、奇偶问题。
蓝色类别是图像中像素的数量,这个数字大于0,并且是奇数,任何像素个数大于0的图像,都归为红色类别,如果你真的去画这些不同的决策出现这些不同的决策取悦,你能看到我们奇数像素点的蓝色类别,在平面上有两个象限,甚至是两个相反的象限,所以我们没有办法能够绘制一条单独的直线,来划分蓝色和红色。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号