TensorFlow瞎几把学Day1--一个简单的拟合例子http://www.tensorfly.cn/tfdoc/get_started/introduction.html
# -*- coding: utf-8 -*- """ Created on Wed Oct 10 08:30:10 2018 @author: jamie """ import tensorflow as tf#tensor是张量的意思 import numpy as np # 使用 NumPy 生成假数据(phony data), 总共 100 个点. x_data=np.float32(np.random.rand(2,100))#生成[0,1]之间的随机数维数为(2,100) y_data=np.dot([0.100,0.200],x_data)+0.300#np.dot矩阵乘法 #构造一个线性模型 b=tf.Variable(tf.zeros([1]))#构造一个矩阵形式作为变量 W=tf.Variable(tf.random_uniform([1,2],-1.0,1.0)) y=tf.matmul(W,x_data)+b#matul:Multiplies matrix a by matrix producing a*b #res=tf.random_uniform((4,4),-3,3)#4x4阶矩阵符合U[-3,3] #with tf.Session() as sess:#tf一定要这样才能显示 # print(sess.run(res)) #最小化方差 loss=tf.reduce_mean(tf.square(y-y_data))#tf.reduce求矩阵的平均值,tf.square求平方 optimizer=tf.train.GradientDescentOptimizer(0.5)#使用梯度下降算法,以0.5的学习效率(learning rate) train=optimizer.minimize(loss) #初始化变量 init=tf.initialize_all_variables() #import tensorflow as tf # ##创造variable.<initial-value>指定这个variable的type和shape #w = tf.Variable(<initial-value>, name=<optional-name>) # ## 接着就可以把这个variable当做tensor运用在graph中. #y = tf.matmul(w, ...another variable or tensor...) # #z = tf.sigmoid(w + y) # ## 通过`assign()`和相关方法给这个w赋值 #w.assign(w + 1.0) #w.assign_add(1.0) # #--------------------- #作者:Panda_Peng #来源:CSDN #原文:https://blog.csdn.net/qq_34484472/article/details/75736036?utm_source=copy #版权声明:本文为博主原创文章,转载请附上博文链接! #启动图(GRAPH) sess=tf.Session() sess.run(init) #拟合平面 for step in range(0,201): sess.run(train) if step % 20==0: print(step,sess.run(W),sess.run(b))
以最典型的Tensorflow为例,一个简单的神经网络:
#机器学习入门是MNIST文字识别,学习编程的入门是打印‘HELLO WORLD’ from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)#下载和安装MNIST数据集 #下载下来的数据集中被分成两部分:60000行训练数据集和10000行的测试数据集 import tensorflow as tf x=tf.placeholder('float',[None,784])#是一个占位符第一维度表示第几张图,第二维度表示每张图的像素 W=tf.Variable(tf.zeros([784,10])) b=tf.Variable(tf.zeros([10])) y=tf.nn.softmax(tf.matmul(x,W)+b)#实现模型 ##训练模型--建立模型 #首先先要定义一个指标来评估这个模型是好的。用‘交叉熵’ y_=tf.placeholder('float',[None,10])#在计算之前要添加新的占位符 cross_entropy=-tf.reduce_sum(y_*tf.log(y))#计算交叉熵,tf.reduce_sum是求和函数 train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) #以上已经设置好了模型 init=tf.initialize_all_variables()#初始化创建的变量 sess=tf.Session() sess.run(init)#在session中启动模型 #之后开始训练模型,在此我们让模型循环1000次 for i in range(1000): batch_xs,batch_ys = mnist.train.next_batch(100) sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) #该循环的每个步骤中,会随机抓取训练数据中的100个批处理数据点。然后我们用这些数据点作为 #参数替换之前的占位符来运行train_step。 ##评估模型 correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))#tf.argmax给出向量中的最大值 #而都是0,1所以可以验证predict和原值是否匹配 accuracy=tf.reduce_mean(tf.cast(correct_prediction,'float')) print(sess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels}))
最终运行结果为
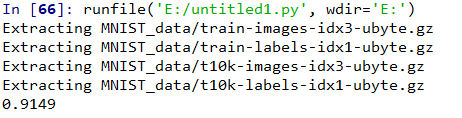
结果不是太好只有91%,因为模型并不好,有更加好的模型可以拟合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号