
Java容器解析系列(5) AbstractSequentialList LinkedList 详解
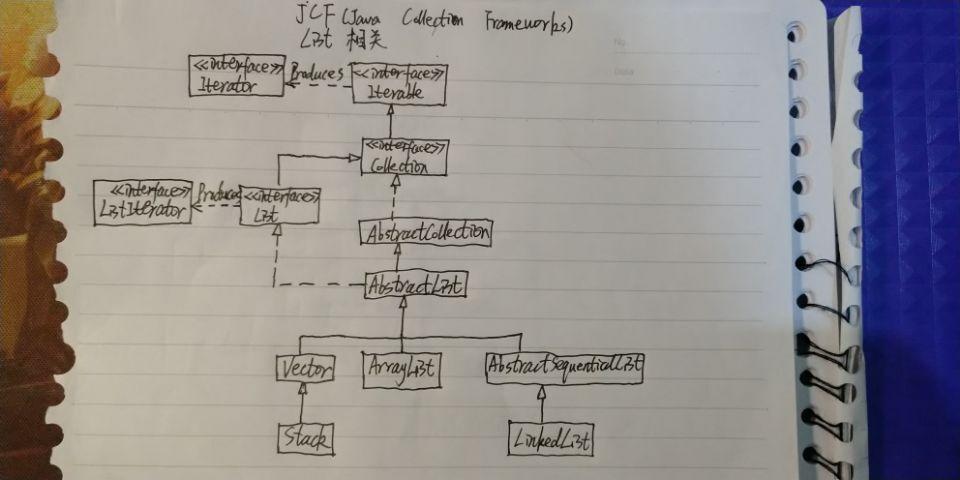
AbstractSequentialList为顺序访问的list提供了一个骨架实现,使实现顺序访问的list变得简单;
我们来看源码:
/**
AbstractSequentialList 继承自 AbstractList,是 List 接口的简化版实现。只支持按顺序访问,而不像 AbstractList 那样支持随机访问。
如果要支持随机访问,应该继承自AbstractList;
想要实现一个支持按次序访问的List的话,只需要继承该类并实现size()和listIterator()方法;
如果要实现的是不可修改的list,和listIterator()方法返回的 ListIterator 需要实现hasNext(), hasPrevious(), next(), previous(), 还有那几个 获取index 的方法;
如果要实现的是可修改的list,ListIterator还需要实现set()方法;
如果要实现的的list大小可变,ListIterator还需要实现add()和remove()方法;
* @since 1.2
*/
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
protected AbstractSequentialList() {}
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E set(int index, E element) {
try {
ListIterator<E> e = listIterator(index);
E oldVal = e.next();
e.set(element);
return oldVal;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public void add(int index, E element) {
try {
listIterator(index).add(element);
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E remove(int index) {
try {
ListIterator<E> e = listIterator(index);
E outCast = e.next();
e.remove();
return outCast;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public boolean addAll(int index, Collection<? extends E> c) {
try {
boolean modified = false;
ListIterator<E> e1 = listIterator(index);
Iterator<? extends E> e2 = c.iterator();
while (e2.hasNext()) {
e1.add(e2.next());
modified = true;
}
return modified;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
// 这里通过调用listIterator()返回ListIterator
public Iterator<E> iterator() {
return listIterator();
}
public abstract ListIterator<E> listIterator(int index);
}
从上面源码可以看出:
- 所有在AbstractSequentialList默认实现的方法,内部都调用了listIterator()来实现(iterator()也是调用listIterator()来实现),并以其返回的ListIterator作为实现基础;
- 与AbstractList不同的是,AbstractSequentialList因为是顺序访问,所以其ListIterator内的方法实现不能像AbstractList那样通过add()/remove()/set()/get()/size()方法来实现(这样会导致效率极其低下),istIterator(int)为一个抽象方法,其子类必须提供其对应的ListIterator;
接下来我们把目光转到AbstractSequentialList的实现类之一-----LinkedList.
翻开原来的笔记,发现有一篇收藏博客对LinkedList讲解非常好( ̄□ ̄||),这里贴一下地址:
从源码角度彻底搞懂LinkedList
这篇博客把整个LinkedList源码都研究了一遍,但是其中有1点需要纠正:
- 插入和删除比较快(O(1)),查询则相对慢一些(O(n))
这里对于插入和删除的算法时间复杂度表述为O(1),这个可以是被广泛认为如此,其实并不正确.我们来看源码:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void addFirst(E e) {
linkFirst(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
在链表的开始或结束位置进行添加或删除节点,其时间复杂度确实为O(1),但是,如果对中间的某个节点进行添加或删除呢?
// 时间复杂度O(n)
// 遍历查找指定位置的数据
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
add(int,E)和remove(int)方法都通过node(int)方法寻找元素,而node(int)方法的时间复杂度为O(n),也即查找指定index位置的元素的时间复杂度. 所以add(int,E)和remove(int)的时间复杂度也应该是O(n);
很多人认为链表插入和删除的算法时间复杂度为O(1),就是忽略了这个查找的过程;
OK,我们就可以得出结论
LinkedList在添加或删除元素时,如果不指定index(开始或结束位置)添加或删除节点,时间复杂度为O(1);如果指定index添加或删除元素,时间复杂度为O(n)
记得我们之前讲过的ArrayList的添加或删除的时间复杂度为O(n),其实和LinkedList的时间复杂度是一致的:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
// 如果在最后添加,那么这里根本不需要移动元素,时间复杂度为O(1)
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
// 如果在最后删除,那么这里根本不需要移动元素,时间复杂度为O(1)
if (numMoved > 0)
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
那么,难道这两者在添加和删除元素的时候就没有什么区别了吗?当然不是:
1. LinkedList添加和删除时间复杂度为O(n),是因为查找指定位置元素的时间复杂度为O(n);
2. ArrayList添加和删除时间复杂度为O(n),是因为移动元素位置的时间复杂度为O(n);
3. 一次移动元素位置比一次元素查看更加耗时;
4. 在LinkedList.ListIterator遍历过程中,因为已经知道了前一个元素和后一个元素,并不需要查询元素位置,此时间复杂度为O(1);
5. 在ArrayList.ListIterator遍历过程中,时间复杂度仍为O(n);
- LinkedList与ArrayList的比较:
ArrayList
1. 基于数组,ArrayList 获取指定位置元素的时间复杂度是O(1);
2. 但是添加、删除元素时,该元素后面的所有元素都要移动,所以添加/删除数据效率不高;
3. 每次达到阈值需要扩容,这个操作比较影响效率。
LinkedList
1. 基于双端链表,添加/删除元素只会影响周围的两个节点,开销比ArrayList低;
2. 只能顺序遍历,无法按照索引获得元素,因此查询效率不高;(get(int)方法内部也是顺序遍历实现)
3. 没有固定容量,不需要扩容;
4. 需要更多的内存,LinkedList 每个节点中需要多存储前后节点的指针,占用空间更多些。
因此,在表需要频繁地添加和删除元素时,还是应该使用LinkedList.如果更多的是按照索引获得元素,应该使用ArrayList
关于按照索引获得元素的效率比较,可以查看博客:
ArrayList遍历方式以及效率比较
建议调试其中的代码,修改LinkedList运行次数和大小,你会为结果感到惊讶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号