
在linux下增加ik分词
一、下载分词器安装包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
二、解压并安装
1.移动elasticsearch-analysis-ik-5.5.1.zip到安装目录的plugins目录
mv elasticsearch-analysis-ik-5.5.1.zip /root/elasticsearch/elasticsearch-5.5.1/plugins/
2.进入安装目录的plugins目录
cd /root/elasticsearch/elasticsearch-5.5.1/plugins/
3.解压
unzip elasticsearch-analysis-ik-5.5.1.zip
4.删除压缩包
rm -rf elasticsearch-analysis-ik-5.5.1.zip
按照官方说明,这时已经成功安装了,重启ElasticSearch即可。
三、测试
使用的是postman工具
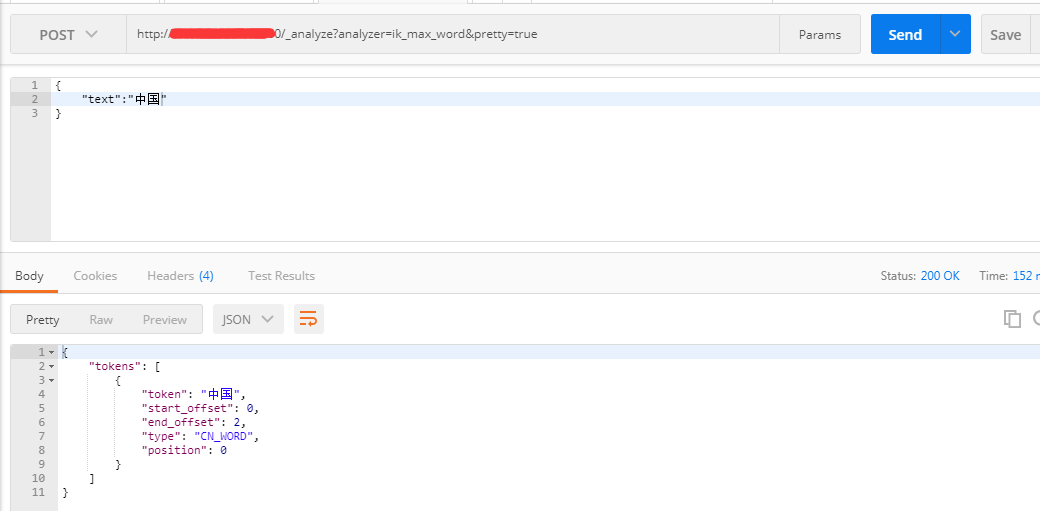
扩展自己的分词:

my.dic
小米手机
华为手机
其他的查询语句:
集群健康
curl -X GET 'http://localhost:9200/_cluster/health?pretty=true'
Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计。它很像SQL中的GROUP BY但是功能更强大。
megacorp/employee的格式:
{ "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests" : [ "sports", "music" ] }
找到所有职员中最大的共同点(兴趣爱好)是什么:
{ "aggs": { "all_interests": { "terms": { "field": "interests.keyword" } } } }
统计每种兴趣下职员的平均年龄:
curl -X GET 'http://localhost:9200/megacorp/employee/_search?pretty=true' -d ' { "aggs" : { "all_interests" : { "terms" : { "field" : "interests.keyword" }, "aggs" : { "avg_age" : { "avg" : { "field" : "age" } } } } } }’
合并多子句
{ "query": { "bool": { "must": { "match": { "first_name": "doublas" } }, "must_not": { "match": { "last_name": "roger" } } } } }
查询语句里面加过滤条件:
{ "query": { "bool": { "filter": { "term": { "first_name": "john" } }, "must": { "match": { "last_name": "smith" } } } } }
查询是高亮:
{ "query":{ "match":{ "about":"rock climbing" } }, "highlight":{ "pre_tags":["<font color='red'>"], "post_tags":["</font>"], "fields":{ "about":{} } } }
multi_match查询
http://localhost:9200/megacorp/employee/_search?pretty=true { "query":{ "multi_match":{ "query":"smith", "fields":["last_name","first_name"] } } } 查询last_name,或first_name有smith的文档 也可以使用通配符 { "query":{ "multi_match":{ "query":"smith", "fields": "*_name" } } }
对结果排序:
{ "query":{ "match":{ "last_name":"smith fir" } }, "sort":{ "age":"desc" } }
多级排序
{ "query":{ "match":{ "about":"I like to collect" } }, "sort":[ {"age":{"order":"desc"}}, {"_score":{"order":"desc"}} ] }
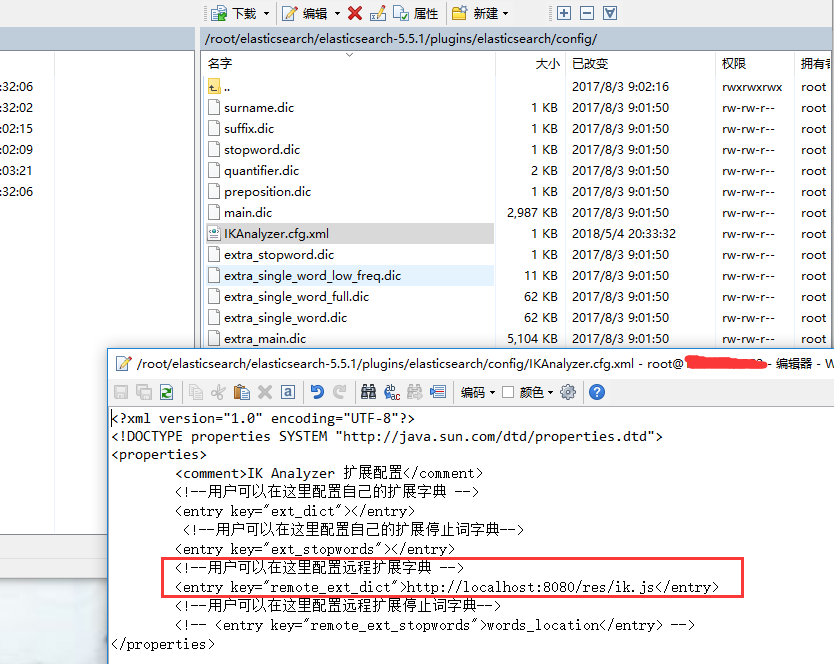
实现分词动态加载:
ik分词的配置中是可以远程加载词库的,此时新建一个web项目代表远程词库,例如我的词库地址为:

配置:
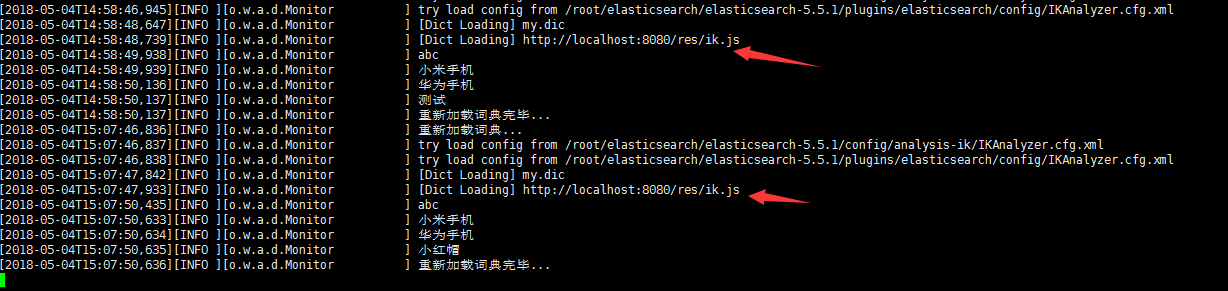
当我们启动ES的时候会看到相应的日志记录,如下:
elasticsearch6.0.0 ik分词器 测试:
curl -H "Content-Type: application/json" -XGET 'http://localhost:9200/_analyze?pretty=true' -d '
> { > "analyzer":"ik_max_word", > "text":"中华人民共和国" > }'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号