Python爬虫基础(四)--Scrapy框架的安装及介绍
Scrapy框架的介绍
框架官方文档:https://docs.scrapy.org/en/latest/
安装:
pip3 install Scrapy
安装测试:
cmd命令行界面,输入:scrapy -h
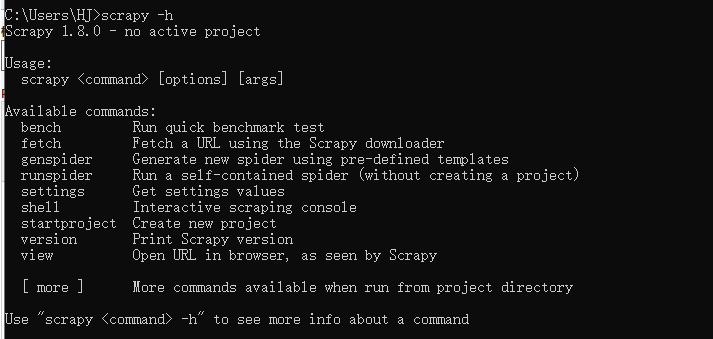
框架安装完成;
scrapy框架:
分为五个模块+两个中间件(5+2结构):
spiders(用户入口,需要配置):
解析download返回的响应
产生爬取项
产生额外的爬取请求
spider middleware中间件(用户配置)--在spider和engine模块之间:
对请求和爬取项的再处理:修改、丢弃、新增请求或爬取项
engine(不需要修改):
控制所有模块之间的数据流
根据条件触发事件
download middleware中间件(用户配置)--在engine和downloader模块之间:
实时engine、scheduler、download之间进行用户可配置的控制,用于修改、丢弃、新增请求或相应
downloader(不需要修改):
根据请求下载网页
scheduler(不需要修改):
对所有爬取请求进行调度管理
item pipelines(出口,需要配置):
以流水线方式处理spiders产生的爬取项
由一组操作顺序组成,类似流水线,每个操作是一个item pipelines类型
可能操作包括:清理、检验和查重爬取项中的html数据,将数据存储到数据库
用户重点编写spider模块和item piplines模块,并且通过编写中间件对数据流进行操作
scrapy爬虫常用命令:
startproject:创建一个项目 scrapy startproject <name> [dir]scrapy startproject pythondemo1
genspider:创建一个爬虫 scrapy genspider [options] <name> <domain>
setting:获得爬虫配置信息 scrapy setting [options]
crawl:运行一个爬虫 scrapy crawl <spider>
list:列出所有的爬虫 scrapy list
shell:启动url调试命令 scrapy shell [url]
scrapy框架爬虫示例:
1、创建一个爬虫工程:scrapy startproject pythondemo123

工程目录下结构:
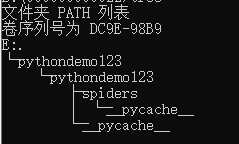
最外层的pythondemo123为外层目录
----pythondemo123/ scrapy框架的用户自定义python代码
--------__init__.py 初始化脚本,不需要修改
--------items.py item代码模板(继承类)一般情况下不需要修改
--------middlewares.py middlewares模板(继承类) 如果需要扩展这个模块的功能,则需要修改
--------pipelines.py pipelines代码模板(继承类)
--------setting.py scrapy爬虫的配置文件 如果优化爬虫功能,需要修改对应的配置项
--------spiders/ spiders代码模板目录(继承类)
------------__init__.py
-----------pycache文件
----scrapy.py 部署scrapy爬虫的配置文件(要执行scrapy服务器的配置信息,在本机执行的话不需要配置)
2、生成一个爬虫:
scrapy genspider demo python123.io #在spiders文件夹下生成demo.py 域名为python123.io
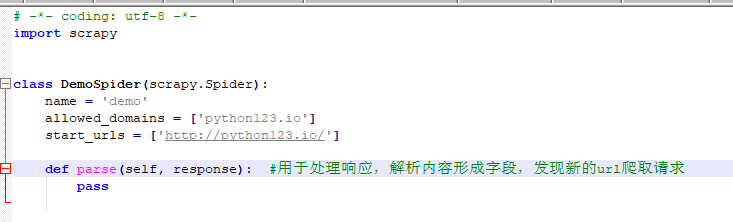
3、配置产生的爬虫
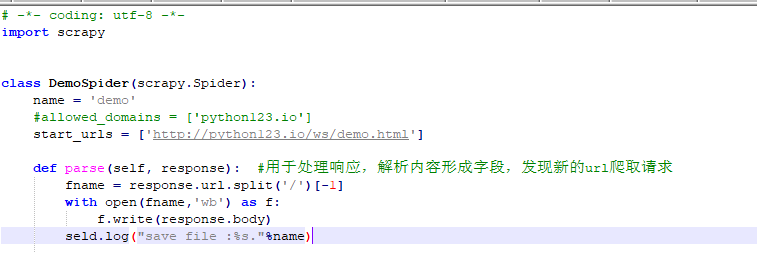
4、运行爬虫,获取网页
scrapy crawl demo
最终获取到demo.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号