数据预处理与特征工程:处理连续型特征--二值化与分段
二值化与分段
思想:将连续变量转换为分类变量
1.sklearn.preprocessing.Binarizer
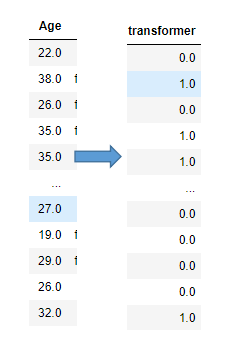
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈
值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员
可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯
设置中的伯努利分布建模)。
1 from sklearn.preprocessing import Binarizer 2 data = pd.read_csv(r'F:\Python\Narrativedata.csv') 3 data.iloc[:,1].fillna(29,inplace = True) 4 X = data.iloc[:,1].values.reshape(-1,1) #转换为二维矩阵 5 6 transformer = Binarizer(threshold=30).fit_transform(X)#threshold=30以30岁为年龄界限来进行划分 7 transformer
2.preprocessing.KBinsDiscretizer

1 from sklearn.preprocessing import KBinsDiscretizer 2 data = pd.read_csv(r'F:\Python\Narrativedata.csv') 3 data.iloc[:,1].fillna(29,inplace = True) 4 X = data.iloc[:,1].values.reshape(-1,1) #转换为二维矩阵 5 est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform') 6 est.fit_transform(X) #查看转换后分的箱:变成了一列中的三箱 7 set(est.fit_transform(X).ravel()) 8 est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') #查看转换后分的箱:变成了哑变量 9 est.fit_transform(X).toarray()
1 array([[1., 0., 0.], 2 [0., 1., 0.], 3 [1., 0., 0.], 4 ..., 5 [0., 1., 0.], 6 [1., 0., 0.], 7 [0., 1., 0.]])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号