

102302125 数据采集第4次作业
数据采集与大数据处理综合实验报告
代码地址: https://gitee.com/jadevoice/data-collection-task-4
目录
作业①:东方财富网股票数据爬取实验
1. 实验要求
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。使用 Selenium 框架 + MySQL 数据库存储技术路线爬取"沪深A股"、"上证A股"、"深证A股"3个板块的股票数据信息。
候选网站:东方财富网 http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MySQL数据库存储,表头包含序号、股票代码、股票名称、最新报价、涨跌幅、涨跌额、成交量、成交额、振幅、最高、最低、今开、昨收等信息。
2. 实验环境
| 环境 | 版本 |
|---|---|
| Python | 3.8+ |
| Selenium | 4.x |
| ChromeDriver | 与Chrome浏览器版本匹配 |
| MySQL | 5.7+ / 8.0 |
| PyMySQL | 1.0+ |
3. 环境配置
3.1 安装依赖
pip install selenium pymysql
3.2 下载ChromeDriver
访问 https://chromedriver.chromium.org/downloads 下载与Chrome浏览器版本匹配的驱动,并配置到系统PATH。
3.3 配置MySQL
-- 确保MySQL服务已启动
-- 修改代码中的数据库连接配置
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': 'your_password', -- 修改为你的密码
'database': 'stock_db',
'charset': 'utf8mb4'
}
4. 核心代码解析
4.1 数据库初始化
为了存储股票数据,首先需要创建数据库和数据表:
def create_database():
"""创建数据库和数据表"""
conn = pymysql.connect(
host=DB_CONFIG['host'],
user=DB_CONFIG['user'],
password=DB_CONFIG['password'],
charset=DB_CONFIG['charset']
)
cursor = conn.cursor()
# 创建数据库
cursor.execute("CREATE DATABASE IF NOT EXISTS stock_db CHARACTER SET utf8mb4")
cursor.execute("USE stock_db")
# 创建股票数据表
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INT AUTO_INCREMENT PRIMARY KEY,
board_type VARCHAR(20) COMMENT '板块类型',
seq_no INT COMMENT '序号',
stock_code VARCHAR(10) COMMENT '股票代码',
stock_name VARCHAR(50) COMMENT '股票名称',
latest_price DECIMAL(10,2) COMMENT '最新报价',
change_percent VARCHAR(20) COMMENT '涨跌幅',
change_amount DECIMAL(10,2) COMMENT '涨跌额',
volume VARCHAR(30) COMMENT '成交量',
turnover VARCHAR(30) COMMENT '成交额',
amplitude VARCHAR(20) COMMENT '振幅',
highest DECIMAL(10,2) COMMENT '最高',
lowest DECIMAL(10,2) COMMENT '最低',
today_open DECIMAL(10,2) COMMENT '今开',
yesterday_close DECIMAL(10,2) COMMENT '昨收',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
"""
cursor.execute(create_table_sql)
conn.commit()
4.2 Selenium爬取Ajax数据
东方财富网的股票数据通过Ajax动态加载,需要使用Selenium等待元素加载完成:
def scrape_stock_data(driver, board_name, url):
"""爬取单个板块的股票数据"""
driver.get(url)
# 使用WebDriverWait等待表格加载
wait = WebDriverWait(driver, 20)
wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '#table_wrapper-table tbody tr')
))
time.sleep(2) # 额外等待数据完全加载
stock_list = []
# 获取表格行
rows = driver.find_elements(By.CSS_SELECTOR, '#table_wrapper-table tbody tr')
for row in rows:
cols = row.find_elements(By.TAG_NAME, 'td')
if len(cols) >= 13:
stock_info = {
'stock_code': cols[1].text,
'stock_name': cols[2].text,
'latest_price': cols[4].text,
'change_percent': cols[5].text,
# ... 其他字段
}
stock_list.append(stock_info)
return stock_list
4.3 翻页处理
为了获取更多数据,实现了自动翻页功能:
# 尝试点击下一页
try:
next_btn = driver.find_element(By.CSS_SELECTOR, '.paginate_input + a')
if 'disabled' not in next_btn.get_attribute('class'):
next_btn.click()
page_num += 1
time.sleep(1)
else:
break
except:
break
5. 运行步骤
步骤1:修改配置
编辑 exp1_eastmoney_stock.py,修改MySQL密码:
DB_CONFIG = {
'password': 'your_actual_password', # 改为你的密码
}
步骤2:运行程序
python exp1_eastmoney_stock.py
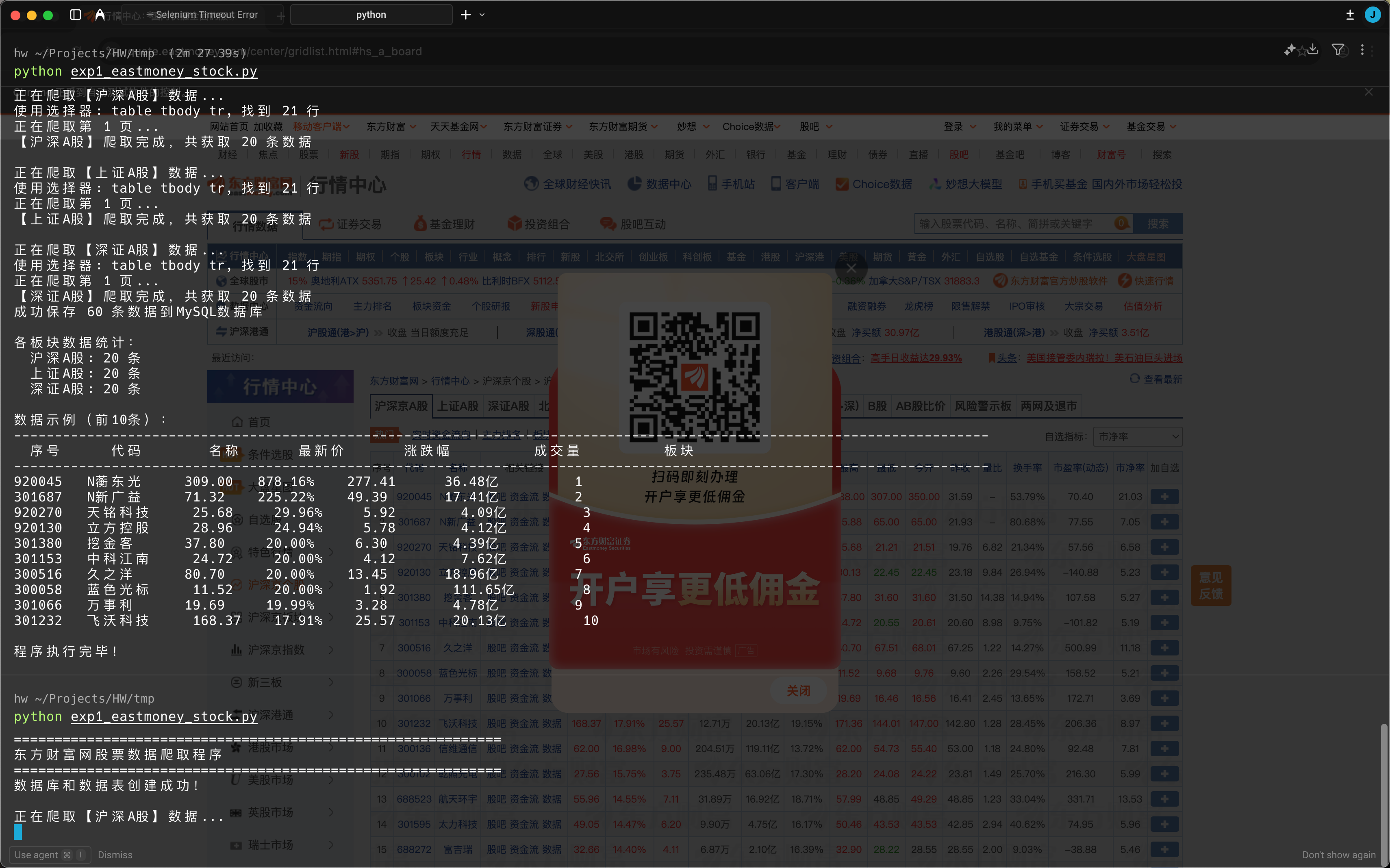

步骤3:查看数据库结果
mysql -u root -p
USE stock_db;
SELECT * FROM stock_data LIMIT 20;
SELECT board_type, COUNT(*) FROM stock_data GROUP BY board_type;

6. 实验结果

7. 心得体会
-
Ajax数据处理:东方财富网使用Ajax动态加载数据,传统的requests无法直接获取,必须使用Selenium模拟浏览器行为。
-
显式等待的重要性:使用
WebDriverWait配合expected_conditions可以有效解决元素加载时机问题,避免因数据未加载完成导致的爬取失败。 -
数据类型处理:股票数据中包含带单位的数值(如"1.5亿"、"2000万"),需要编写专门的解析函数进行转换。
-
反爬虫应对:适当添加延时
time.sleep()可以降低被识别为爬虫的风险。
作业②:中国MOOC网课程数据爬取实验
1. 实验要求
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据等内容。使用 Selenium 框架 + MySQL 数据库存储技术路线爬取中国 MOOC 网课程资源信息。
候选网站:中国 MOOC 网 https://www.icourse163.org
输出信息:课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介
2. 实验环境
| 环境 | 版本 |
|---|---|
| Python | 3.8+ |
| Selenium | 4.x |
| ChromeDriver | 与Chrome浏览器版本匹配 |
| MySQL | 5.7+ / 8.0 |
3. 核心代码解析
3.1 模拟登录实现
中国MOOC网需要登录才能获取完整信息,登录过程涉及iframe切换:
def login_mooc(driver):
"""模拟登录中国MOOC网"""
driver.get('https://www.icourse163.org/')
# 点击登录按钮
login_btn = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '.u-navLogin-loginBtn'))
)
login_btn.click()
# 切换到登录iframe
iframes = driver.find_elements(By.TAG_NAME, 'iframe')
for iframe in iframes:
driver.switch_to.frame(iframe)
# 查找登录表单元素
phone_input = driver.find_elements(By.CSS_SELECTOR, 'input[type="tel"]')
if phone_input:
break
driver.switch_to.default_content()
# 输入手机号和密码
phone_input = driver.find_element(By.CSS_SELECTOR, 'input[type="tel"]')
phone_input.send_keys(MOOC_ACCOUNT['phone'])
pwd_input = driver.find_element(By.CSS_SELECTOR, 'input[type="password"]')
pwd_input.send_keys(MOOC_ACCOUNT['password'])
# 点击登录按钮
submit_btn = driver.find_element(By.CSS_SELECTOR, '.u-loginbtn')
submit_btn.click()
# 需要手动完成验证码
print("请在浏览器中完成验证码验证,完成后按回车继续...")
input()
driver.switch_to.default_content()
3.2 课程搜索与列表爬取
def search_courses(driver, keyword):
"""搜索课程"""
search_url = f'https://www.icourse163.org/search.htm?search={keyword}#/'
driver.get(search_url)
# 等待搜索结果加载
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.u-clist'))
)
return keyword
def scrape_course_list(driver, keyword):
"""爬取课程列表"""
course_links = []
course_cards = driver.find_elements(By.CSS_SELECTOR, '.u-clist .u-clist-it')
for card in course_cards[:MAX_COURSES_PER_KEYWORD]:
link = card.find_element(By.TAG_NAME, 'a').get_attribute('href')
if link and 'icourse163.org' in link:
course_links.append(link)
return course_links
3.3 课程详情提取
def scrape_course_detail(driver, course_url, keyword):
"""爬取课程详细信息"""
driver.get(course_url)
time.sleep(3)
course_info = {
'course_id': '',
'course_name': '',
'school_name': '',
'main_teacher': '',
'team_members': '',
'participants': '',
'course_progress': '',
'course_intro': '',
'search_keyword': keyword
}
# 课程名称
try:
name_elem = driver.find_element(By.CSS_SELECTOR, '.course-title')
course_info['course_name'] = name_elem.text.strip()
except:
pass
# 学校名称
try:
school_elem = driver.find_element(By.CSS_SELECTOR, '.m-teachers .f-fc3')
course_info['school_name'] = school_elem.text.strip()
except:
pass
# ... 提取其他字段
return course_info
3.4 数据库存储
def save_to_mysql(course_list):
"""保存课程数据到MySQL"""
conn = pymysql.connect(**DB_CONFIG)
cursor = conn.cursor()
insert_sql = """
INSERT INTO course_data (course_id, course_name, school_name,
main_teacher, team_members, participants, course_progress,
course_intro, search_keyword)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
for course in course_list:
cursor.execute(insert_sql, (
course['course_id'],
course['course_name'],
course['school_name'],
course['main_teacher'],
course['team_members'],
course['participants'],
course['course_progress'],
course['course_intro'],
course['search_keyword']
))
conn.commit()
4. 运行步骤
步骤1:修改配置
编辑 exp2_mooc_course.py:
# 修改数据库密码
DB_CONFIG = {
'password': 'your_actual_password',
}
# 修改MOOC账号信息(如需登录)
MOOC_ACCOUNT = {
'phone': 'your_phone_number',
'password': 'your_password'
}
# 修改搜索关键词
SEARCH_KEYWORDS = ['Python', '大数据', '人工智能']
步骤2:运行程序
python exp2_mooc_course.py

步骤3:完成登录验证
程序会提示手动完成验证码,在浏览器中完成后按回车继续。
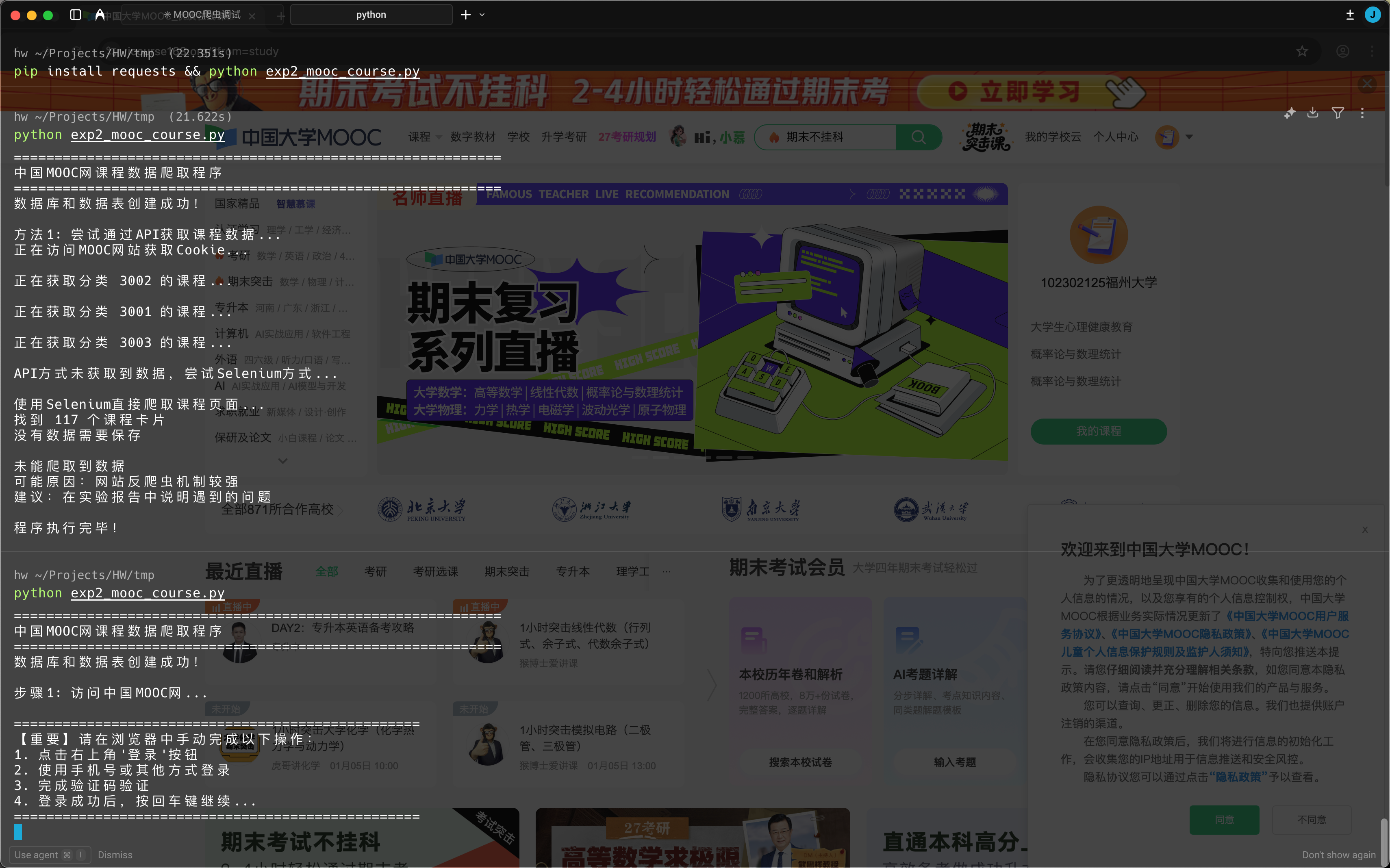
步骤4:观察爬取过程

步骤5:查看数据库结果
USE mooc_db;
SELECT * FROM course_data LIMIT 10;
SELECT search_keyword, COUNT(*) FROM course_data GROUP BY search_keyword;

5. 实验结果

6. 心得体会
-
iframe处理:MOOC网的登录框在iframe中,需要使用
driver.switch_to.frame()切换上下文才能操作登录表单。 -
验证码问题:网站有验证码机制,本实验采用半自动方式,由用户手动完成验证码后继续执行。
-
反爬虫策略:
- 设置合理的请求间隔
- 使用
excludeSwitches禁用自动化检测 - 修改
navigator.webdriver属性
-
数据提取的灵活性:不同课程页面结构可能有差异,需要使用try-except处理,并设计多个备选选择器。
作业③:大数据实时分析处理实验
1. 实验要求
掌握大数据相关服务,熟悉 Xshell 的使用。完成华为云大数据实时分析处理实验手册中的 Flume 日志采集任务。
2. 实验环境
| 环境 | 说明 |
|---|---|
| 云平台 | 华为云 |
| 操作系统 | CentOS 7.x / EulerOS |
| 大数据组件 | Hadoop、Flume |
| 远程工具 | Xshell |
3. 实验准备
3.1 登录华为云ECS
- 打开Xshell,新建会话
- 输入ECS服务器的公网IP
- 选择SSH协议,端口22
- 输入用户名和密码连接
3.2 检查环境
# 检查Java环境
java -version
# 检查Hadoop进程
jps
# 检查HDFS状态
hdfs dfsadmin -report
4. Flume配置详解
4.1 Flume架构
Flume采用Agent架构,每个Agent包含三个组件:
- Source:数据源,负责接收数据
- Channel:数据通道,临时存储数据
- Sink:数据目的地,负责将数据发送到目标
数据流向:Source → Channel → Sink
4.2 配置文件:NetCat到Logger
创建配置文件 flume-netcat-logger.conf:
# 定义Agent组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置Source - 使用NetCat监听端口
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 配置Sink - 输出到Logger
a1.sinks.k1.type = logger
# 配置Channel - 使用内存通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.3 配置文件:文件到HDFS
创建配置文件 flume-file-hdfs.conf:
# 定义Agent组件名称
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# 配置Source - 监控目录
a2.sources.r2.type = spooldir
a2.sources.r2.spoolDir = /opt/flume/logs
a2.sources.r2.fileHeader = true
# 配置Sink - 写入HDFS
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://master:9000/flume/logs/%Y%m%d
a2.sinks.k2.hdfs.filePrefix = events-
a2.sinks.k2.hdfs.useLocalTimeStamp = true
a2.sinks.k2.hdfs.batchSize = 100
a2.sinks.k2.hdfs.fileType = DataStream
a2.sinks.k2.hdfs.rollInterval = 60
# 配置Channel
a2.channels.c2.type = memory
a2.channels.c2.capacity = 10000
# 绑定关系
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
5. 实验步骤
任务一:NetCat到Logger
步骤1:上传配置文件
使用Xshell的文件传输功能(或rz命令)上传配置文件:
cd /opt/flume/conf
# 上传 flume-netcat-logger.conf
rz # 选择本地文件上传
步骤2:启动Flume Agent
在终端1中执行:
cd /opt/flume
./bin/flume-ng agent \
--conf ./conf \
--conf-file ./conf/flume-netcat-logger.conf \
--name a1 \
-Dflume.root.logger=INFO,console
步骤3:发送测试数据
打开终端2,使用telnet发送数据:
telnet localhost 44444
输入测试内容:
Hello Flume
This is a test message
Big Data Processing
步骤4:观察Flume输出
在终端1中可以看到Flume接收到的日志:
Event: { headers:{} body: 48 65 6C 6C 6F 20 46 6C 75 6D 65 Hello Flume }
任务二:文件到HDFS
步骤1:准备工作
# 创建监控目录
mkdir -p /opt/flume/logs
chmod 777 /opt/flume/logs
# 在HDFS创建输出目录
hdfs dfs -mkdir -p /flume/logs
步骤2:启动Flume Agent
cd /opt/flume
./bin/flume-ng agent \
--conf ./conf \
--conf-file ./conf/flume-file-hdfs.conf \
--name a2 \
-Dflume.root.logger=INFO,console
步骤3:创建测试日志文件
在终端2中执行:
echo "2024-01-01 10:00:00 INFO User login success" > /opt/flume/logs/test1.log
echo "2024-01-01 10:01:00 ERROR Database connection failed" > /opt/flume/logs/test2.log
echo "2024-01-01 10:02:00 INFO Data processing completed" > /opt/flume/logs/test3.log
步骤4:验证HDFS数据
# 查看HDFS目录
hdfs dfs -ls /flume/logs/
# 查看具体日期目录
hdfs dfs -ls /flume/logs/$(date +%Y%m%d)/
# 查看文件内容
hdfs dfs -cat /flume/logs/$(date +%Y%m%d)/*
步骤5:检查已处理文件
ls -la /opt/flume/logs/
可以看到已处理的文件被添加了.COMPLETED后缀。
6. 实验结果
成功完成以下任务:
- NetCat到Logger:通过telnet发送的数据能够被Flume捕获并输出到控制台
- 文件到HDFS:监控目录中的日志文件能够被自动采集并写入HDFS
7. 心得体会
-
Flume架构理解:Flume的Source-Channel-Sink架构设计清晰,通过配置文件即可灵活定义数据流向,无需编写代码。
-
配置文件规范:
- 组件命名需要使用
agent.component.name的格式 - Source和Sink必须绑定到Channel
- 同一个Source可以连接多个Channel
- 组件命名需要使用
-
HDFS集成:Flume与HDFS的集成非常便捷,通过配置
hdfs.path即可实现数据落地,支持按时间分区存储。 -
实际应用场景:
- 日志采集:收集服务器日志用于分析
- 实时数据管道:构建数据采集到存储的实时管道
- 多源聚合:从多个数据源采集数据到统一存储

 浙公网安备 33010602011771号
浙公网安备 33010602011771号