ASCII、GB2312、GBK、GB18030、DBCS、UCS(Unicode)、UTF-8、UTF-16
简述:
计算机中存储、处理的都是字节流,而如何用字节去表示字符就需要用到编码规范了。
ASCII 是最早出现的规范,使用1个字节组合出256种不同的状态来描述字符。但是只用到了0-127中状态来描述“控制字符”和“可显示字符”。
128-255被各个国家作为“扩展字符集”。
GB2312 是后来需要描述中文时出现的。规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。GB2312 是对 ASCII 的中文扩展。
GBK 是对GB2312的扩展。虽然有了GB2312,但是还是有很多中文不能用。GBK标准在GB2312的基础上,不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字 符集里的内容。这样,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
GB18030 是对GBK的扩展,加了几千个新的少数民族的字。
GB2312、GBK、GB18030统称为DBCS(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处 理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
Unicode是ISO(国际标谁化组织)为了解决不同地区都按照各自的编码规范编码,导致信息无法交流的问题,提出的“废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码”。
Unicode 编码系统,可分为编码方式和实现方式两个层次。
编码方式:
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
实现方式:UTF(UCS Transfer Format)
1. UTF-8: UTF-8以字节为单位对Unicode进行编码。(因为是以字节为单位对unicode进行编码,所以BOM对其没有意义,虽然unicode运行对utf-8设置BOM)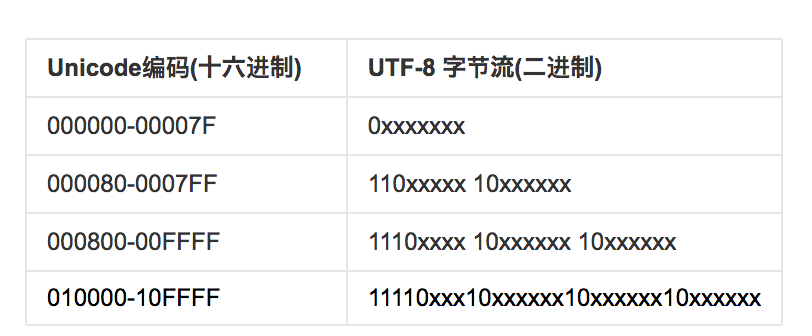
2. UTF-16编码以16位无符号整数为单位。
3. UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。
(附注:
字节序:字节序有两种,分别是“大端”(Big Endian, BE)和“小端”(Little Endian, LE)。
根据字节序的不同,UTF-16可被实现为UTF-16LE或UTF-16BE,UTF-32可被实现为UTF-32LE或UTF-32BE。例如:
|
Unicode编码
|
UTF-16LE
|
UTF-16BE
|
UTF32-LE
|
UTF32-BE
|
|
0x006C49
|
49 6C
|
6C 49
|
49 6C 00 00
|
00 00 6C 49
|
|
0x020C30
|
43 D8 30 DC
|
D8 43 DC 30
|
30 0C 02 00
|
00 02 0C 30
|
|
UTF编码
|
Byte Order Mark (BOM)
|
| UTF-8 without BOM | 无 |
|
UTF-8 with BOM
|
EF BB BF
|
|
UTF-16LE
|
FF FE
|
|
UTF-16BE
|
FE FF
|
|
UTF-32LE
|
FF FE 00 00
|
|
UTF-32BE
|
00 00 FE FF
|
)
参考文献:
[1] 知乎于洋回答:https://www.zhihu.com/question/23374078
[2] 百度百科Unicode词条

 浙公网安备 33010602011771号
浙公网安备 33010602011771号