

.Net Remoting的基本原理
.NET Remoting是.NET平台上允许存在于不同应用程序域中的对象相互知晓对方并进行通讯的基础设施。调用对象被称为客户端,而被调用对象则被称为服务器或者服务器对象。简而言之,它就是.NET平台上实现分布式对象系统的框架。
传统的方法调用是通过栈实现,调用方法前将this指针以及方法参数压入线程栈中,线程执行方法时将栈中的参数取出作为本地变量,经过一番计算后,将方法的返回结果压入栈中。这样我们就完成了一次方法调用。如下图所示:
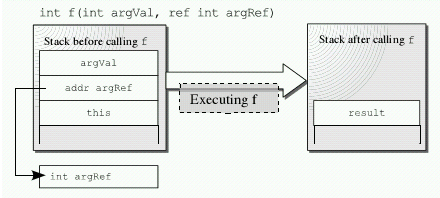
基于栈的方法调用在同一个应用程序域中很容易实现,但是如果要调用的方法所属的对象位于另一个应用程序域或另一个进程甚至是另一个机器,又当如何?应用程序域之间是无法共享同一个线程栈的,此时我们将转而使用另一种方法调用机制——基于消息的方法调用机制。在客户端通过代理对象将原先基于栈的方法调用信息(定位远程对象的信息、方法名、方法参数等)封装到一个消息对象中,再根据需要将这些消息对象转化成某个格式的数据流发送到远程对象所在的的应用程序域中。当经过格式化的消息到达服务器后,首先从中还原出消息对象,之后在远程对象所在的的应用程序域中构建出相应方法调用栈,此时就可以按照传统的基于栈的方法调用机制完成方法的调用,而方法返回结果的过程则按照之前的方法反向重复一遍。如下图所示:
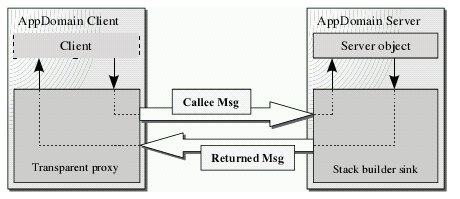
在基于消息的远程方法调用中主要有以下几个重要角色:
Client Proxy: 负责在客户端处理基于栈的参数传递模式和基于消息的参数传递模式之间的转换。
Invoker:与Client Proxy的功能相反。
Requestor: 负责将消息对象转换成可在网络上传输的数据流,并将其发送到服务器。
Marshaller: 负责消息对象的序列化与反序列化。
Client Request Handle:负责以数据流的格式发送客户端的请求消息。
Server Request Handel:负责接收来自客户端的请求消息。
那么在.NET Remoting框架下,这些重要角色又各自对应了哪些对象呢?下图是一个Remoting框架的示意图:
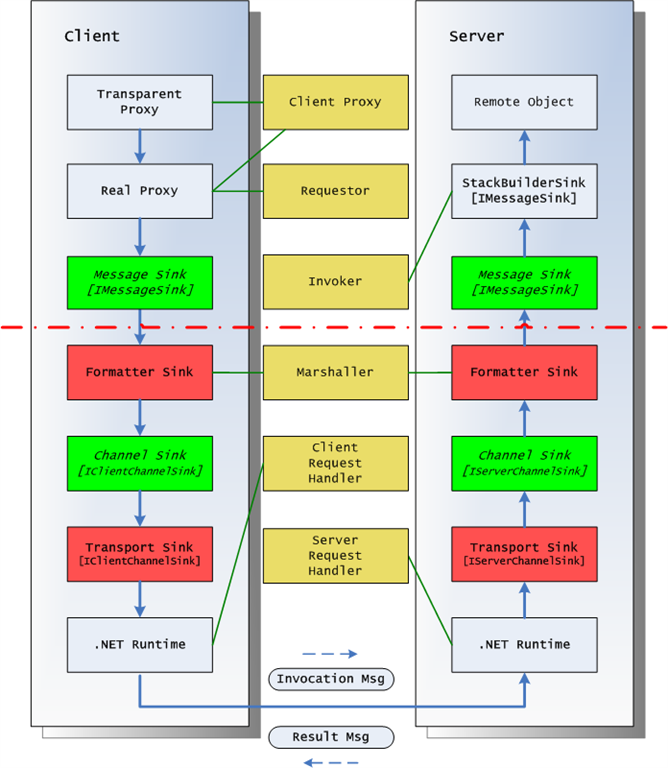
图1
从中我们可以看到客户端的Transparent Proxy与服务器端的StackBuilderSink分别扮演了Client Proxy与Invoker的角色。Remoting依靠这两个对象实现了基于栈的方法调用与基于消息的方法调用的转换,并且这一过程对于开发者是完全隐藏的。
Marshaller的角色由Formmatter Sink完成,在Remoting中默认提供了两种Fommatter:一个实现了消息对象与二进制流的相互转换,另一个实现了消息对象与Soap数据包的相互转换,而支持Soap格式则说明Remoting具有实现Web Service技术的可能。
Client Request Handle与Server Request Handel都是.NET中实现网络底层通讯的对象,如HttpWebRequest、HttpServerSocketHandler等。在Remoting中我们并不直接接触这些对象,而是通过Channel对它们进行管理。在框架中默认提供了三种Channel:HttpChannel、TcpChannel与IpcChannel。但是在上面这副图中,我们并没有看到Channel对象,那么Channel又是如何影响网络底层的通讯协议的呢?
其实在上面这幅图中,真正能对通讯时所采用的网络协议产生影响的元素是Transport Sink,对应不同的协议Remoting框架中提供了三种共计六个Transport Sink:HttpClientTransportSink、HttpServerTransportSink与TcpClientTransportSink、TcpServerTransportSink以及IpcClientTransportSink、IpcServerTransportSink,它们分别放置在客户端与服务器端。既然Transport Sink才是通讯协议的决定元素,那么Channel肯定与它有着某种联系,让我们先暂时搁置此话题,留待后面进一步介绍。
观察上面这副图,我们可以发现其中包含了一系列的Sink,而所谓的Sink就是一个信息接收器,它接受一系列的输入信息,为了达到某种目的对这些信息做一些处理,然后将处理后信息再次输出到另一个Sink中,这样一个个的Sink串联起来就构成了一个Pipeline(管道)。Pipeline模式在分布式框架中经常可以看到,应用该模式可以使框架具有良好的灵活性。当我们需要构建一个系统用于处理并转换一串输入数据时,如果通过一个大的组件按部就班的来实现此功能,那么一旦需求发生变化,比如其中的两个处理步骤需要调换次序,或者需要加入或减去某些处理,系统将很难适应,甚至需要重写。而Pipeline模式则将一个个的处理模块相互分离,各自独立,然后按照需要将它们串联起来即可,此时前者的输出就会作为后者的输入。此时,每个处理模块都可以获得最大限度的复用。当需求发生变化时,我们只需重新组织各个处理模块的链接顺序,或者删除或加入新的处理模块即可。在这些处理模块(Sink)中最重要的两类是Formatter Sink与Transport Sink,也就是图1中的红色部分,当我们需要通过网络访问远程对象时,首先要将消息转化为可在网络上传播的数据流,然后需要通过特定的网络协议完成数据流的发送与接收,这正是这两类Sink所负责的功能。虽然它们本身也可以被自定义的Sink所替换,不过Remoting中提供的现有实现已经可以满足绝大多数的应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号