创建scrapy项目
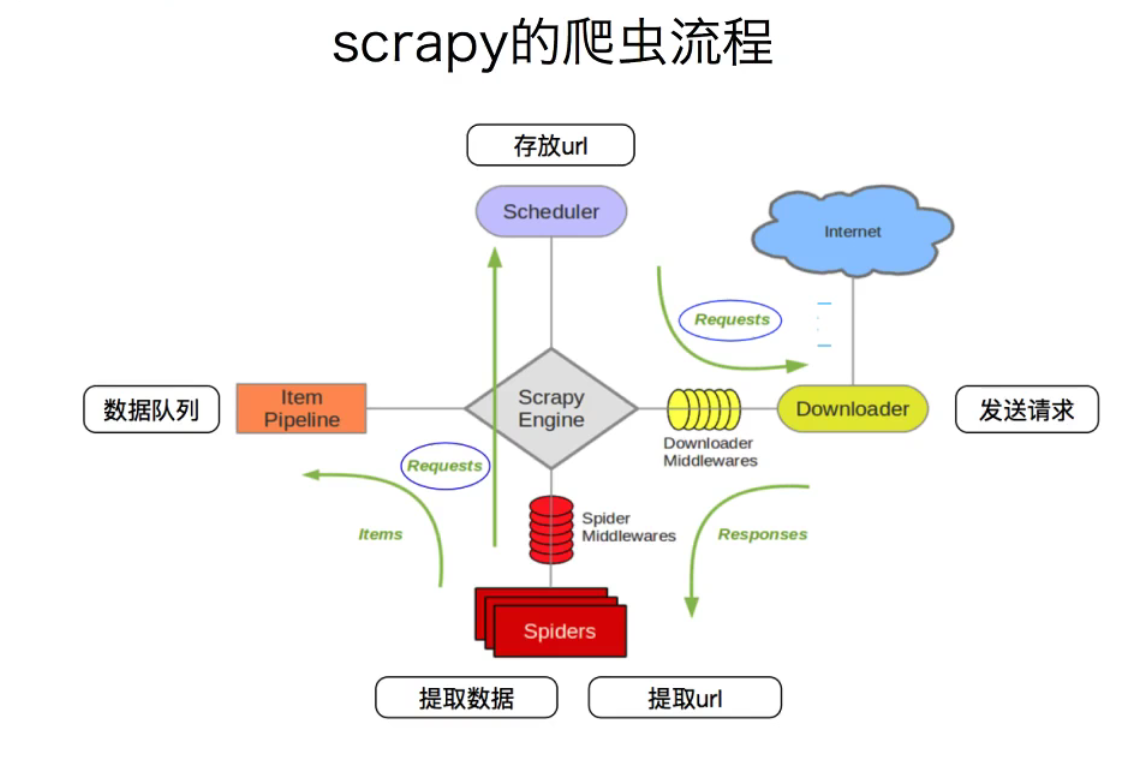
| 模块名 | 职责 | 是否需要实现 |
|---|---|---|
| Scrapy Engine(引擎) | 总指挥: 负债数据和信号在不同的模块之间传递 | scrapy 已经实现 |
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy 已经实现 |
| Downloader(下载器) | 下载引擎发送过来的request请求,并返回给引擎(response) | scrapy 已经实现 |
| Spiders(爬虫) | 处理引擎发送过来的response,提取数据和url,并交给引擎 | 需要手写 |
| Item Pipeline(管道) | 处理引擎传送过来的数据(Item),比如存储到数据库 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider Middlewares(中间件) | 可以自定义request和response的过滤 | 一般不用手写 |
Scrapy 入门
-
创建一个新的爬虫项目
scrapy startproject myspider -
进入爬虫项目文件夹,生成一个新的爬虫文件
scrapy genspider spider_name limited_url -
提取数据
-
完成spider中parse方法, 使用 xpath,正则等方法提取数据,并yield 一个item 到pipeline中
-
这里需要开启pipeline,myspider/setting.py 中启用 ITEM_PIPELINES,这里的pipeline可以定义多个
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# K(启动pipeline的位置):V(优先级,越小优先级越高)
'myspider.pipelines.MyspiderPipeline': 300,
# 'myspider.pipelines.MyspiderPipelineA': 400,
}
-
-
# 以 mongodb 为例
from pymongo import MongoClient
client = MongoClient()
collection = client["db"]["collection"]
class MyspiderPipeline:
def process_item(self, item, spider):
collection.insert(item)
return item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号