分布式一致性raft
学学分布式(一)-- Raft
面试被问到了一致性协议,故来研究一下。
一致性协议还是很有几个的,但是网上都说paxos很难理解,工程实现上复杂,所以本文针对Raft展开讲解。
1. 入门理解
首先要了解一下,分布式一致性是干嘛的?什么是分布式一致性?
在分布式架构中,多节点协同工作时,每个节点有独立的计算和存储,节点之间通过网络通信进行协作,需保证数据在各节点间的同步一致性(如分布式数据库、配置中心、服务注册中心),否则会导致业务逻辑错乱、数据丢失等问题。一致性协议的核心目标是:即使在节点故障、网络延迟/分区等异常场景下,仍能确保系统行为符合预期,实现“最终一致性”或“强一致性”。
简单来说就是指多个节点对某一变量的取值达成一致,一旦达成一致,则变量的本次取值即被确定。当机器宕机、网络出问题时,大家怎么在“数据到底长什么样”这件事上达成一致。Raft 就是让一堆节点在“有机器出问题”的情况下,还能像“一台可靠机器”一样对外工作的协议。
而本文的raft正是为了探索一种更易于理解的一致性算法而产生的。它的首要设计目的就是易于理解,所以在选主的冲突处理等方式上它都选择了非常简单明了的解决方案。
Raft协议规定做的事儿就这几件:
-
选 Leader
-
Leader 负责写日志
-
保证日志顺序在大多数节点上一致
第一件事儿选leader到是很好理解,第二件事这个日志是干嘛的?日志顺序是干嘛的?
这里的日志要与传统的程序产生的日志区分理解开来,可能脑子里是这种日志:
2025-1-27 00:00:00 INFO order created
2025-1-27 00:00:01 ERROR db timeout
而这里说的日志可以理解为操作记录,Command Log,假设我们要做一个分布式的kv db。客户端有如下命令:
SET a = 1
SET b = 2
SET a = 3
这些不是“数据”,而是操作。Raft 干的事是: 把这些操作按顺序复制到每一个节点,那么只要日志顺序一致,集群中的最终状态一定一致的。按照顺序那肯定是必须得,因为顺序不对最终的结果很大可能是不一样的,这是不能忍受的。
还有一个问题,leader写日志呢?假设现在有一个很民主的分布式系统,每个节点都可以写,
Node A:SET a=1
Node B:SET a=2
Node C:SET a=3
问题来了,哪个节点开始向其他两个兄弟发起同步请求呢?这会产生顺序冲突,不好解决。顺序只能有一个源头,leader吧。。
以上就是关于第二、第三件事中的一点点小疑惑解答。
2. Raft角色
2.1 角色基本介绍
Raft 的三种角色,不是身份,而是“节点在某一时刻所处的工作状态”,任何节点,在不同时间,都可能在这三种状态之间切换。Follower ←→ Candidate ←→ Leader
| 角色 | 本质定位 | 核心职责 |
|---|---|---|
| Follower | 被管理者 | 接收命令、服从 Leader |
| Candidate | 竞选者 | 发起选举 |
| Leader | 唯一决策者 | 写日志、发心跳 |
Follower:Follower 是“正常运行时最常见的状态”,系统刚启动 → 全是 Follower;Leader 挂了 → 所有节点先变 Follower;Candidate 选举失败 → 回到 Follower。
这种角色,接收 Leader 的心跳,和leader给的日志复制,当然还有响应投票了。Follower是会篡位的,在Timeout 内,没有收到合法 Leader 的心跳,可能会想:“是不是 Leader 死了?那我试试竞选吧。” 这个角色很安静,不抢写,不制造冲突,不做决定。
Candidate:Candidate 是“Leader 选举过程中的临时状态”,不是常态,也不处理业务只为一件事存在:选出 Leader,Candidate 不允许写日志它只做“竞选”。。上面也说了,Follower尝试篡位时,可能会变成这个。从候选者可以变为其他两种状态,当:
获得 > 半数选票 → 成为 Leader;
发现有leader了→ 立刻退回 Follower;
选举失败了,没有多数(平票 / 超时)→ 再次发起新一轮选举
Leader:Leader 是 Raft 中唯一有“决定权”的节点,所有写操作只能走 Leader,日志顺序由 Leader 决定,Leader负责的事儿:①给追随者发送心跳,告诉大家,“我还活着,别选别人”;②接受客户端发送过来的请求;③日志复制 & 提交,复制日志到 Followers,超过半数确认 → commit(这条日志的状态为已提交)
2.2 日志commit
上面就是三种角色的大致介绍,写到这里,突然想到一个问题,这里的日志commit是什么意思?
在分布式系统中,日志 commit 的意思是: “这个操作已经被系统正式承认,将来任何节点、任何 Leader 都不能否认它的发生。” 关键词只有三个:正式承认,不可回滚,全局有效。日志Commit是集群层面的一致性确认,而非单个节点的本地操作。单个节点将日志写入本地存储(持久化),仅完成“本地确认”,不代表日志已提交;只有当多数派节点均完成本地持久化,日志才会被集群标记为提交状态。
在Raft里面,日志commit顺序大概是这样的:
- 日志已在领导者本地持久化:客户端请求到达领导者后,领导者先将请求封装为日志条目,写入本地日志并完成持久化(避免自身故障导致日志丢失);
- 同步至多数派跟随者并持久化:领导者向集群所有跟随者发送日志同步请求,跟随者验证日志合法性后,将日志持久化到本地,并向领导者返回“确认响应”;
- 领导者收到多数派确认:当领导者收到的确认响应数量超过集群节点总数的一半(如3节点集群需2个确认、5节点集群需3个确认),则判定该日志条目“可提交”,标记其为Commit状态。
2.3 角色转变过程
假设我们有 5 个节点(A, B, C, D, E),它们同时启动。为了防止它们“撞车”(同时发起选举),Raft 有一个关键机制:随机选举超时时间。
情况一:最顺利的选举
这是最常见的情况,
初始状态(全员 Follower)A, B, C, D, E 同时启动,所有节点默认初始化为 Follower。任期:所有节点任期为 0。然后倒计时:每个节点开启一个随机倒计时。假设随机结果如下:
- A: 160ms
- B: 200ms
- C: 230ms
- D: 280ms
- E: 300ms
第一阶段:Follower -> Candidate,时间过了 160ms,节点 A 的倒计时最先结束。A 发现没收到任何 Leader 的消息,决定自己竞选。A 的动作:首先将任期 Term 加 1(变成 Term 1),然后状态转变为 Candidate。先给自己投一票(1/5)。向 B, C, D, E 发送 RequestVote(拉票请求)。
第二阶段:Candidate -> Leader,B, C, D, E 此时还在倒计时中(还是 Follower)。它们收到了 A 的请求,检查发现 A 的任期比自己新(1 > 0),且自己这轮还没投过票。它们回复 A:“同意,我投给你”。A 收到了 B 和 C 的回复(加上自己的一票,共 3 票),达到了 多数派(5 个节点的多数派是 3)。然后A 的动作:
- 状态立刻转变为 Leader。
- 立刻向所有人发送 Heartbeat(心跳包),宣示主权。
第三阶段:Follower 重置,B, C, D, E 收到 A 的心跳包。它们知道当前 Leader 是 A,于是重置自己的选举倒计时,继续安心做 Follower。
情况二:选票瓜分
意外发生(两个节点同时超时):假设 A 和 B 的随机运气很差,倒计时非常接近(比如 A 是 150ms,B 是 152ms)。A 超时,变成 Candidate (Term 1),给自己投票,发起广播。几乎同一瞬间,B 还没收到 A 的广播,也超时了。B 也变成 Candidate (Term 1),给自己投票,发起广播。
然后出现拉票僵局,现在的局面是:A 投给了 A,B 投给了 B,剩下 C, D, E 三个吃瓜群众。
由于网络延迟不同:C 先收到了 A 的请求,投给了 A;D 先收到了 B 的请求,投给了 B;E 先收到了 A 的请求,投给了 A。
计票结果:
- A 得到:A, C, E (3票) -> A 胜出,变成 Leader。
- B 得到:B, D (2票) -> B 落选。
更极端的僵局:假设 C 投给 A,D 投给 B,E 恰好网络卡了或者还没决定。或者 C, D, E 三人刚好把票分摊了,导致 A 有 2 票,B 有 2 票,(假设 E 也刚好变成了 Candidate)E 投给了自己。结果:没有人拿到 3 票(多数派)。
Candidate -> Candidate (重选):如果 A 和 B 在一段时间内(Election Timeout)都没有收到足够的票数,也没有收到对方胜出的消息,它们会认为这次选举失败。任期 Term 再加 1(变成 Term 2),重新随机一个超时时间(这次 A 和 B 很难再撞车了),保持 Candidate 状态,开始新一轮拉票。
情况三:Candidate退让
A 和 B 同时竞选(都是 Term 1),A 运气好,网络快,迅速拿到了 C, D, E 的票,成为了 Leader,A 立刻发送心跳包给所有人。此时 B 还是 Candidate,还在苦苦等待选票,突然,B 收到了来自 A 的心跳包(AppendEntries RPC)。B 检查心跳包中的 Term,发现 A 的 Term 是 1(和自己一样)或者更高。B 的动作:承认 A 的领导地位,状态从 Candidate 退化回 Follower。
情况四:Leader下台
最开始A 是 Leader(Term 1),突然网络分区了,A 被孤立了(只能连接到 B,连不上 C, D, E)。
在A 侧:A 依然觉得自己是 Leader,发心跳给 B,但无法凑齐多数派确认,系统在 A 这边处于半死状态。
在C, D, E 侧:收不到 A 的心跳,超时了,C 发起选举,变成 Leader(Term 2)。
过了一会儿,网络恢复了,A(Term 1)试图给 C(Term 2)发心跳,C 拒绝,并告诉 A:“我的 Term 是 2,你太旧了”;或者 A 收到了 C 的心跳,发现 C 的 Term 是 2。
A 的动作:发现即使自己曾经是王,但现在时代变了(Term 落后),状态立刻从 Leader 变为 Follower,更新自己的 Term 为 2,跟随 C。
上面这些情况出现的名词:任期(Term)是什么意思呢?
raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/distributed-system/protocol/raft-algorithm.html
2.4 动画演示
下面就通过动画演示来看看这个过程。这个网站非常地ok,有动画,看起来很直观,本节里面的图,截图于这个网站里面的。https://raft.github.io/
感兴趣的读者可以尝试自己去跑着尝试一下。
首先,集群启动,里面的结点都是追随者状态的。S5结点时间到了,开始篡位了。
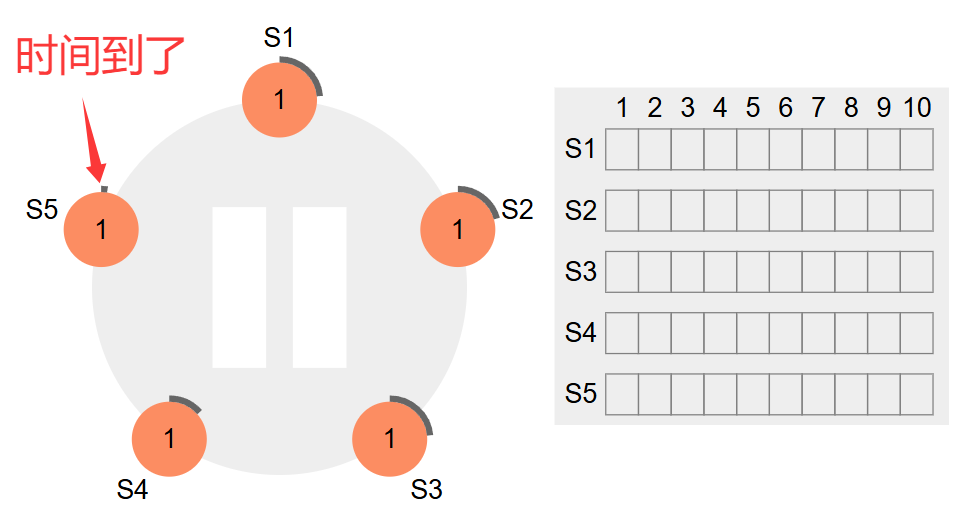
S5变成候选者Candidate,给自己来一票,拉票请求发送给集群中其他人,任期term+1变成2。如下图所示
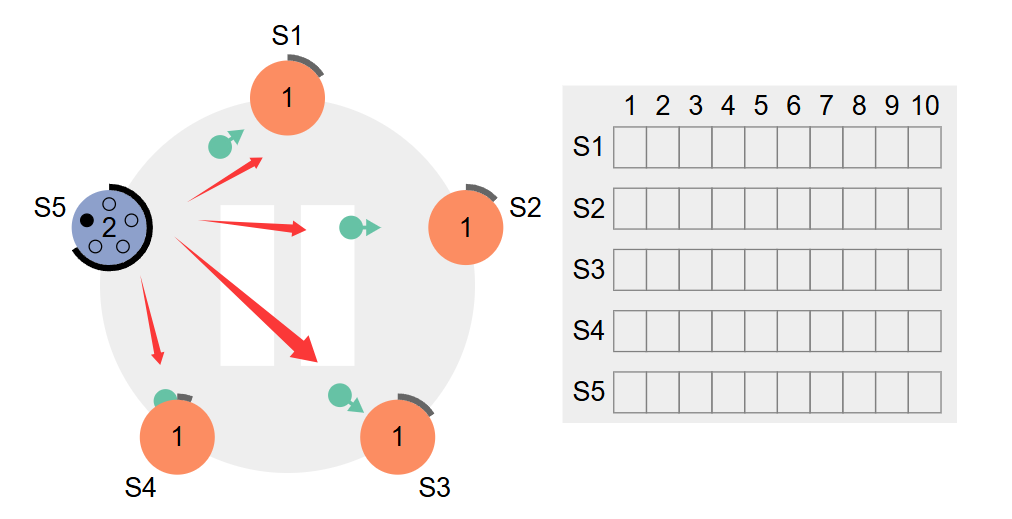
获得超半数的票了,变成leader了,然后给集群中其他人发送心跳,其他人也把term改成2。从下图中可以看出S5已经变成Leader了,然后只有点击S5结点才能进行request写操作,点击其他结点的request没有任何变化,这也就对应了上面说的结论:所有写操作只能走 Leader
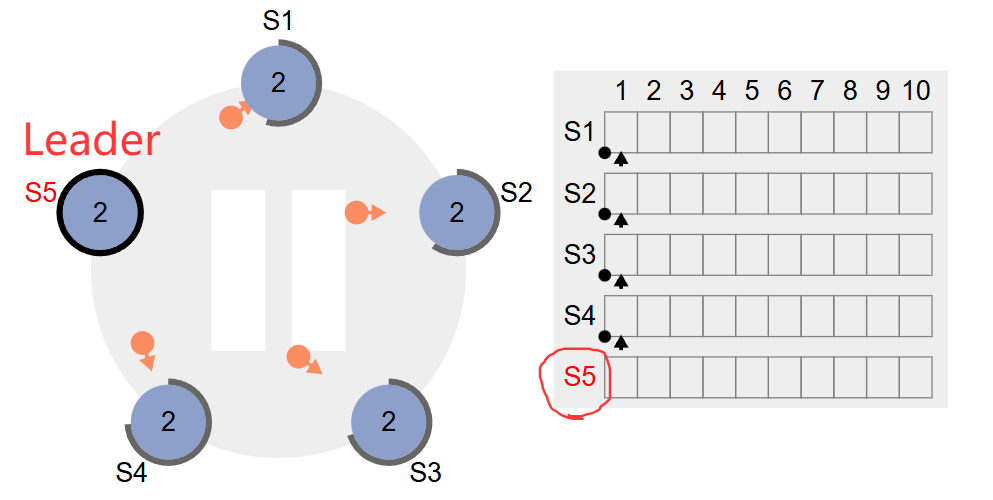
尝试向leader写入数据,首先写入本地,如下图所示,截图的时候暂停了,其他Follower结点发送日志复制还没到,故LeaderS5中的commitIndex还是0。
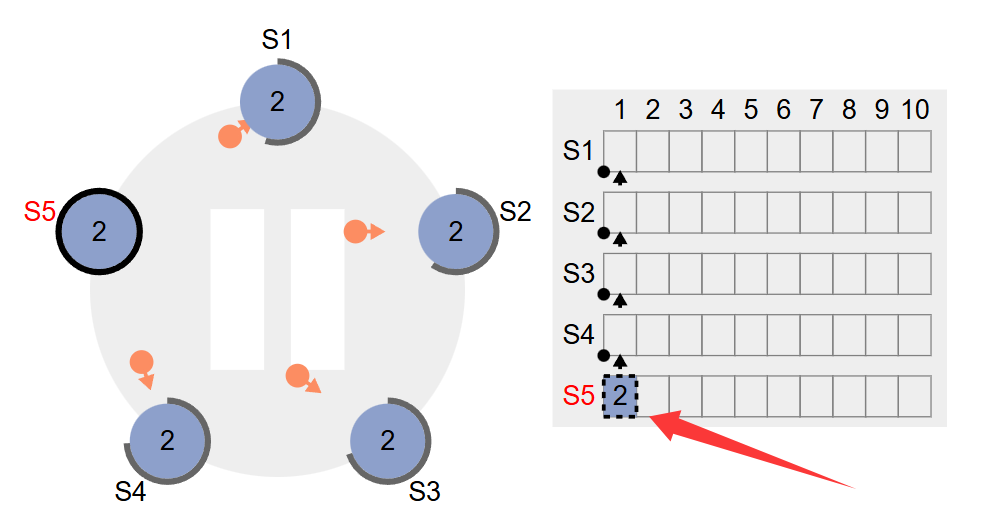
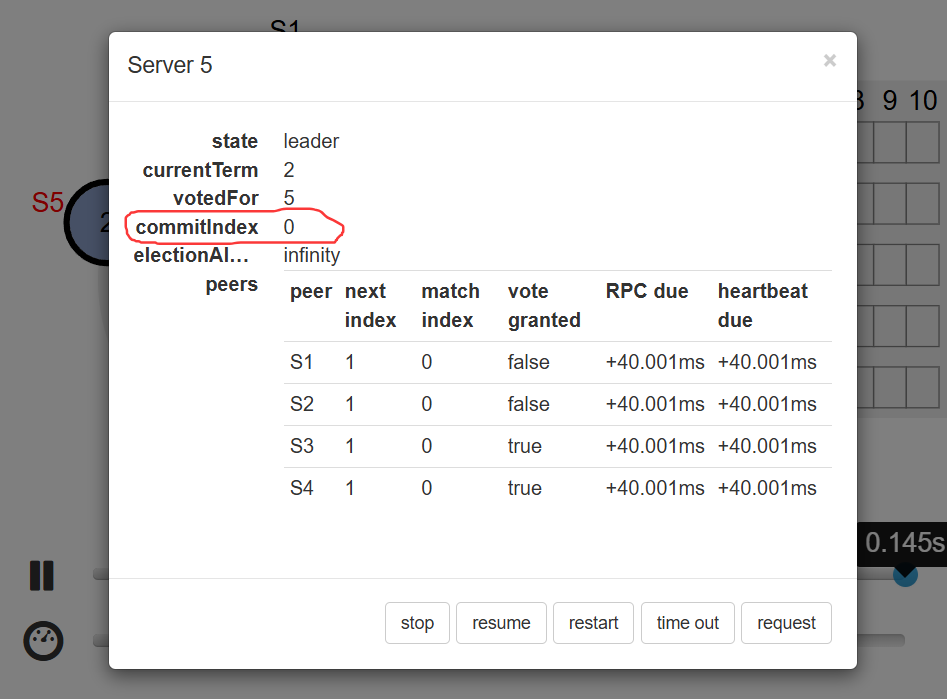
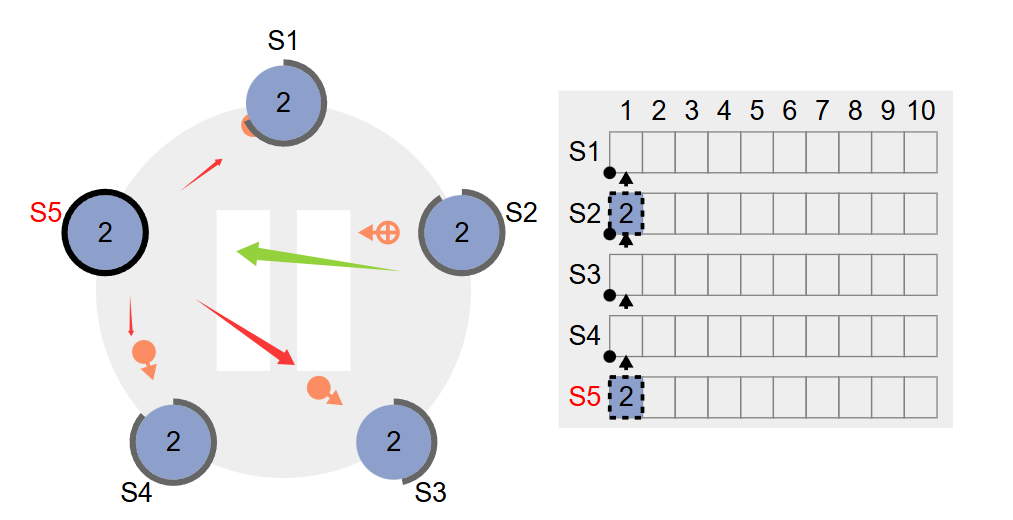
接下来,该到日志复制了,可以看到S2结点先收到的,然后写入本地的日志,正在返回响应,此时s5节点中的commitIndex还是0哦,如下图所示
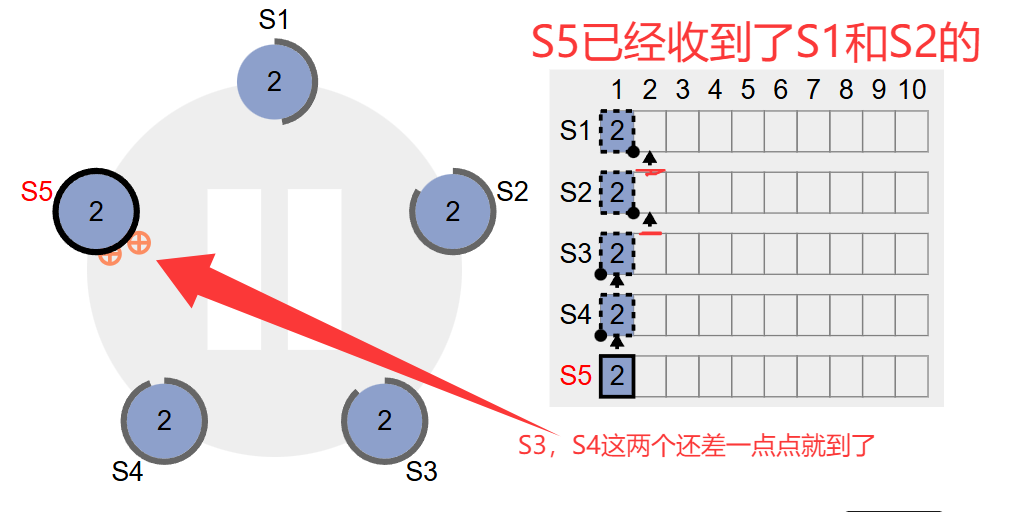
等到收到了大多数响应了,即使是S3和S4的响应还没收到,由于确认的已超过半数,该条日志就会正式commit,commitIndex就变成1了。如下图所示
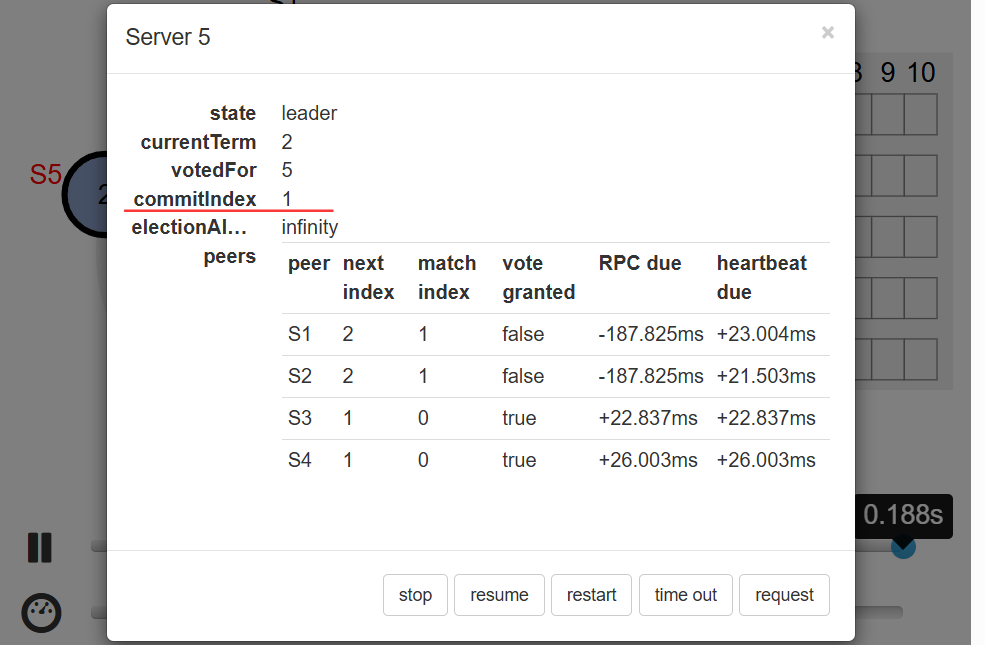
写完之后,然后就是leader向其他人发送心跳包了。
接下来假设S5挂掉了,即Leader没了,按照流程S1234等到超时后,就会重新选主了,此时读者们也可以观察到,S3结点肯定是先变成候选者的,同时S1结点的过期时间也很暧昧,也快要篡位了。如下图所示
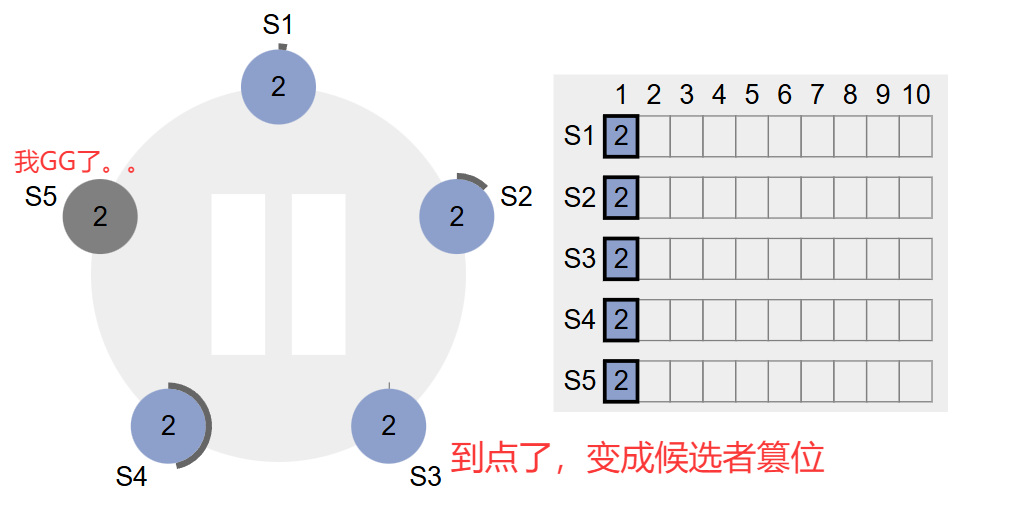
马上就变成下面的情况了:从图中可以看出S3先把term+1变成了3,然后先S1一步发送拉票请求,然后数据包正在路上,随后S1同理,也把term由原来的2加了1变成了3,也发送拉票请求,晚于S3。如下图所示
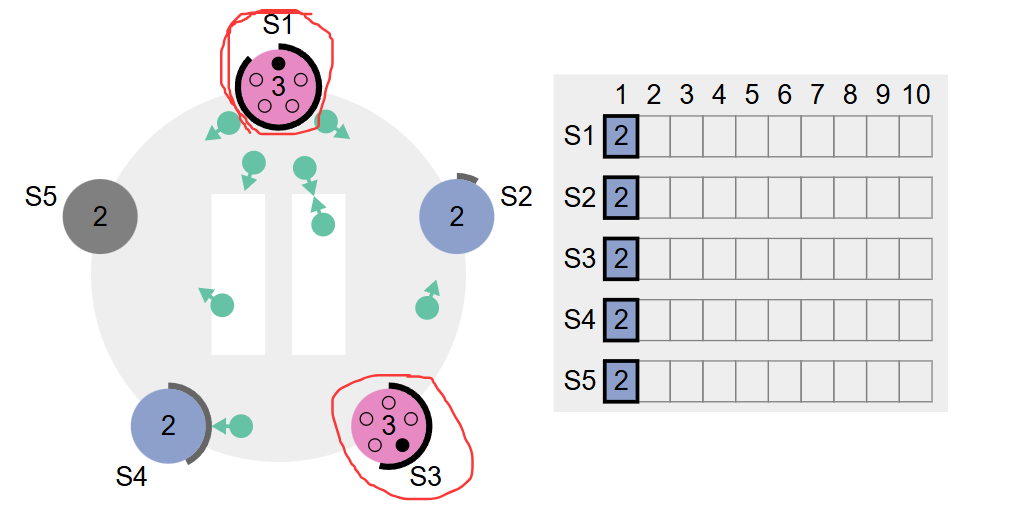
接着下一步:可以看到,S1的拉票请求还没有到其他节点,S2、S4结点收到了S3的拉票请求,返回响应是+号的形式,S1就不一样了喔,是减号的形式。那么到此可以确定的是,S3总共有三票(自己、S2、S4),S1返回的是减号嘛,肯定不可能投给S3的哇。如下图所示
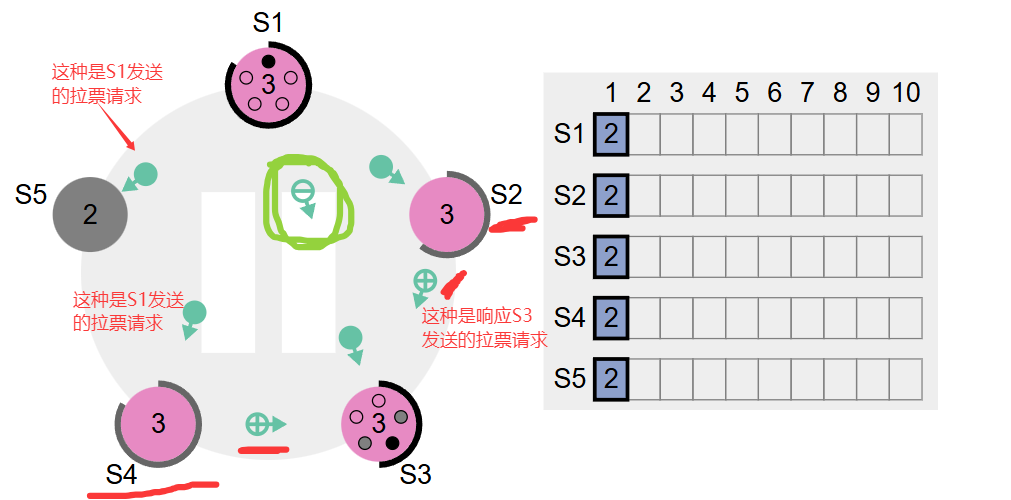
接着往下,S3变成了Leader,发送心跳包给集群其他节点,其他节点收到了S1的拉票请求,投给他减号【因为leader已经选出来了,就可以不理S1的拉票请求了】。如下图所示
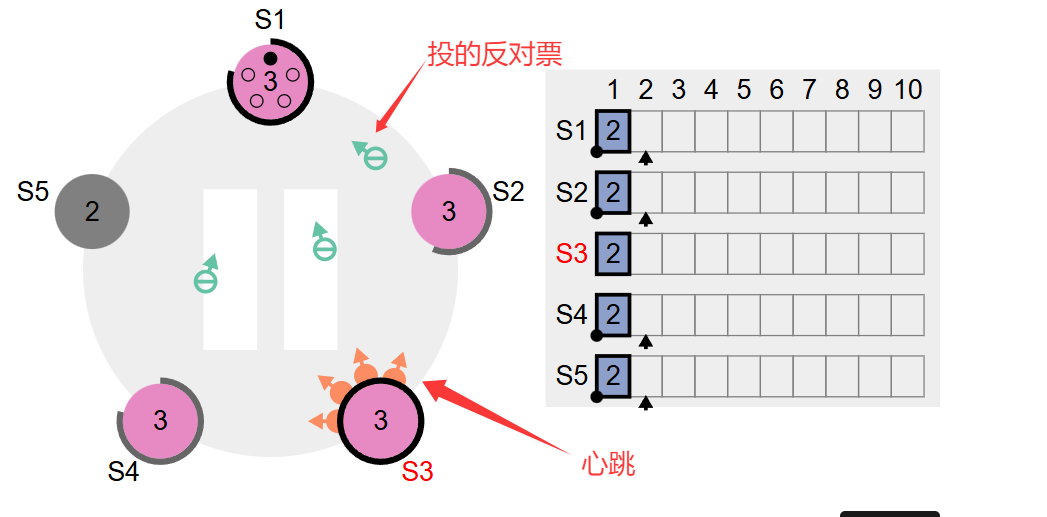
S1收到了三人的反对票,到此为止仅有一票,然后收到了LeaderS3发来的心跳,知道了已经选出来老大了,自己只好退场了:如下图所示
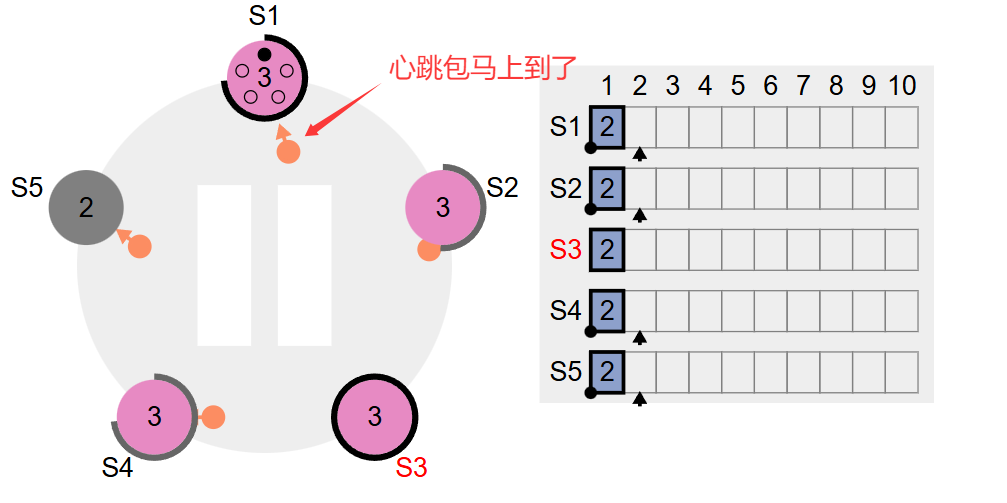
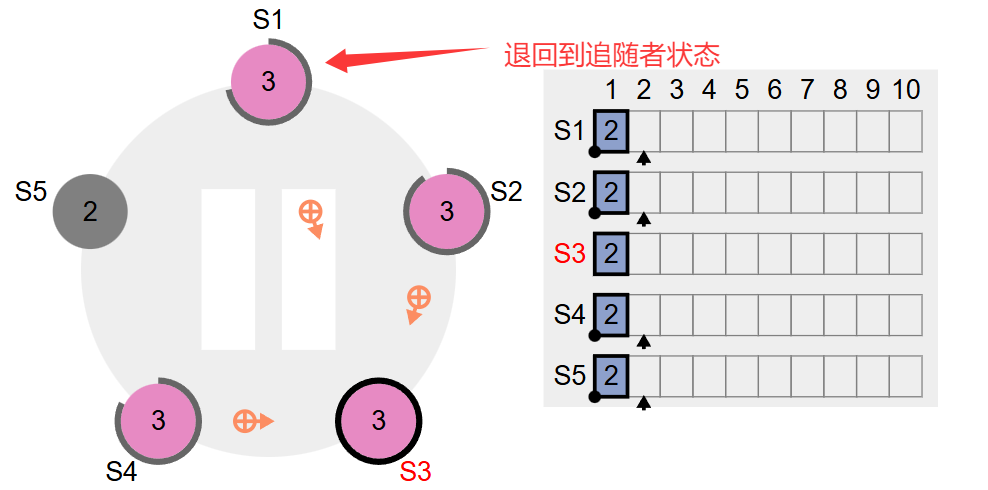
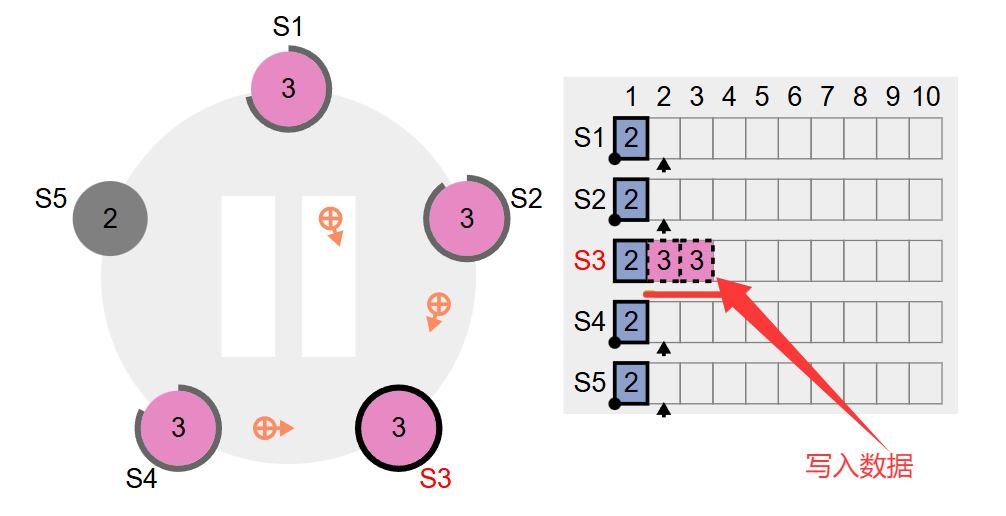
此时,集群终于正常了,然后往S3写两个数据之后,集群中的其他Follower结点肯定会逐渐接收到Leader的日志复制请求。前面我们不是把S5结点停掉了吗,那我们重启一下S5结点看看:如下图所示
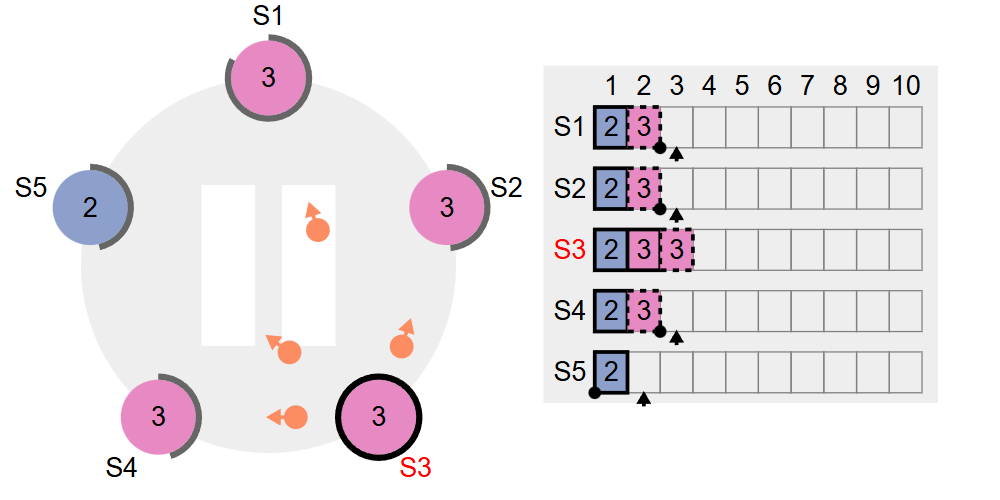
可以看到S124正在慢慢的追上来,leader正在逐渐把日志复制给追随者。如下图所示
S5收到Leader的心跳,会变成Follower,leader也根据每个节点的matchIndex、nextIndex,将对应的日志逐步复制,最终S5结点的日志也会慢慢追上来的。
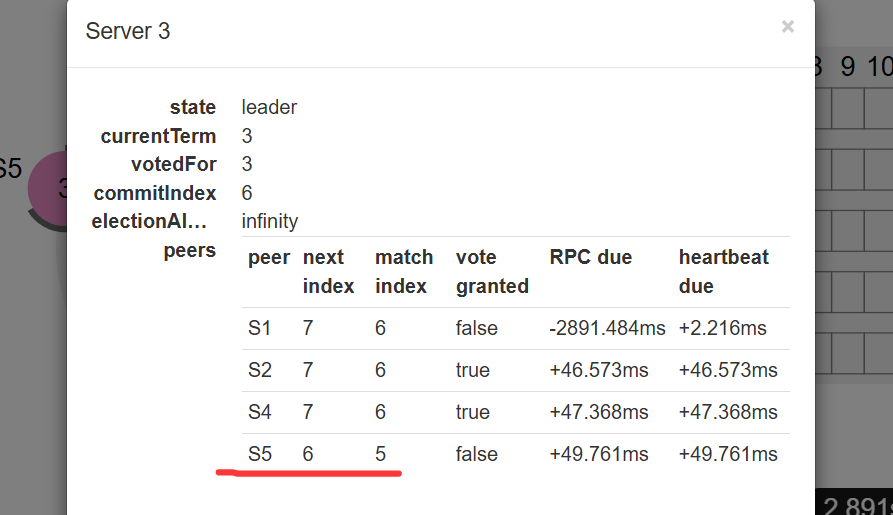
通过上面的图片演示,相比读者们已经大概了解了选主、raft中结点状态的转换是什么样子的了。虽然讲得很简单,但是应该还是能大致理解吧
下一篇文章尝试实现Raft做一个很简单的分布式kv。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号