P4-16 Specifications(v1.2.2)学习笔记
本文是学习2021年5月最新的P416语言规范(P416 Language Specification)时所做的学习笔记,以下将P416语言规范简称为规范。同时,为了避免因翻译而导致的问题,文中用加粗的原英文来表达部分术语,翻译成中文的术语也将加粗标记。
- 术语
- P4简介
- 核心抽象
- BNF范式(巴科斯范式)
- very_simple_switch(VSS)
- VSS程序解析
- 高级主题
- 代码附录
- References
术语
- 体系结构(Architecture):描述一组P4可编程组件以及他们之间的数据平面接口,由厂家提供。可以认为是P4程序跟Target之间的一种“约定”,P4程序员需要针对该“约定”编写程序。
- 数据平面(Data Plane):数据平面实现分组处理和转发逻辑。
- 控制平面(Control Plane):控制平面提供了数据平面处理和转发分组前所必须的各种网络信息和转发查询表项。
- 元数据(Metadata):P4程序的执行过程中生成的中间数据。
- 分组(Packet):分组是数据平面要处理和转发的对象。
- 分组首部(Packet Header): 分组最开始的一段格式化数据。一个给定的分组可能包含一系列代表不同网络协议的首部。
- 分组有效载荷(Packet Payload): 跟在分组首部后面的分组数据。
- 分组处理系统(Packet-processing system):为处理网络分组而设计的一种数据处理系统,分组处理系统实现控制平面和数据平面算法。
- 目标(Target):一种可以执行P4程序的分组处理系统。Target可以是一个交换机、路由器或者其它可编程转发元件,Target是一个总称。
P4简介
P4是一种语言,全称是Programming Protocol-independent Packet Processors(编程协议无关的分组处理器),用于表示可编程转发元件(如硬件或软件交换机、网络接口卡、路由器或网络设备)的数据平面如何处理Packet。P4仅用于指定Target的数据平面功能以及部分控制平面和数据平面通信的接口,但P4不能用来描述Target的控制平面功能。
P4可编程交换机与传统交换机的区别
- 协议无关性:P4交换机是协议无关的,交换机不与任何特定的网络协议绑定,程序员可以通过编程自定义各种数据平面协议和分组的处理转发逻辑。
- 目标无关性:用户不需要关心底层硬件的细节就可对分组的处理方式进行编程。这一特性通过P4前后端编译器实现,前端编译器将P4高级语言程序转换成中间表示,后端编译器将中间表示编译成设备配置,自动配置目标设备。
- 可重构性:在不更换硬件的前提下,允许用户随时改变分组的处理和转发方式 ,并在编译后重新配置交换机。

核心抽象
-
Header:描述在一个分组内的各个协议首部的格式。
-
Parser:描述接收到的分组中允许的首部序列、如何解析这些首部序列、以及要从分组中提取的首部和字段。
-
Tables:将用户定义的key与Action相关联。 Table泛化了传统的交换机表,可用于实现路由表、流表、访问控制列表和其它用户自定义的表。
-
Actions: 描述如何处理首部字段和Metadata。 Actions可以包含控制平面在运行时提供的数据。
-
Match-Action Units:执行以下操作序列:首先,根据分组字段或所计算出的Metadata来构造key;然后,使用构造的key在Table中查找,选择要执行的Action;最后,执行所选的Action。
-
Control Flow:描述分组在Target上的处理流程,包括Match-Action Units调用的数据依赖序列。也可以用来实现Deparser。
-
Extern Object:特定于Architecture的第三方库,可以由P4程序通过定义良好的API进行调用。
-
User-defined Metadata:用户自定义的数据结构,与分组相关联。
-
Intrinsic Metadata:由Architecture提供的元数据,例如,所接收到的分组的输入端口。
用P4编程Target时的一个典型工具工作流如下图所示
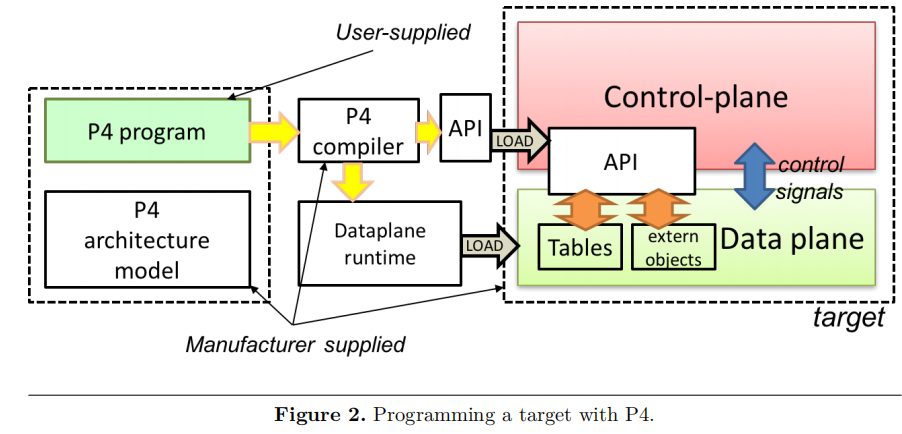
Target制造商为Target提供硬件或软件实现框架、Architecture定义和P4编译器。P4程序员为特定的Architecture编写程序(图中绿色区块),该Architecture定义了Target上的一组P4可编程组件及其外部数据平面接口。
编译一组P4程序会产生两个工件:
- 数据平面配置,用于在数据平面实现由 P4 程序指定的转发逻辑
- API,用于管理数据平面对象状态
BNF范式(巴科斯范式)
规范中使用BNF范式来给出P4的语法,因此,在介绍具体语法之前,先简单描述一下BNF范式。本部分内容不是规范中介绍的内容。
巴科斯范式是以美国人巴科斯(Backus)和丹麦人诺尔(Naur)的名字命名的一种形式化的语法表示方法,用来描述语法的一种形式体系,是一种典型的元语言,又称巴科斯-诺尔形式(Backus-Naur Form,BNF)。它不仅能严格地表示语法规则,而且所描述的语法是与上下文无关的。
BNF表示语法规则的方式为:
- 非终结符用尖括号括起
- 每条规则的左部是一个非终结符,右部是由非终结符和终结符组成的一个符号串,中间一般以“: :=”分开
- 具有相同左部的规则可以共用一个左部,各右部之间以直竖“|”隔开
- 双引号(" ")内包含的字符代表着这些字符本身,而双引号本身用double_quote来代表
- 在双引号外的字(有可能有下划线)代表着语法部分
- 尖括号(< >)内包含的为必选项
- 方括号([ ])内包含的为可选项
- 花括号( { } )内包含的为可重复0至无数次的项
- 竖线( | )表示在其左右两边任选一项,相当于"OR"的意思。
- ::= 是“被定义为”的意思
在规范中,所使用的BNF表示与上述略有不同:
-
字母大写的符号表示终结符,小写字母表示的符号为非终结符
-
“被定义为”用冒号(:)表示,而不是“: : =”
nonTypeName : IDENTIFIER | APPLY | KEY | ACTIONS | STATE | ENTRIES | TYPE ; name : nonTypeName | TYPE_IDENTIFIER ;
如上述例子表示的是,一个name被定义为一个nonTypeName或者一个TYPE_IDENTIFIER,一个nonTypeName被定义为一个IDENTIFIER或者APPLY...或者一个TYPE。全部大写的符号是终结符,无须再定义。
very_simple_switch(VSS)
接下来将介绍规范中给出的very_simple_switch例子,以下称该例子为VSS。
VSS Architecture 概览
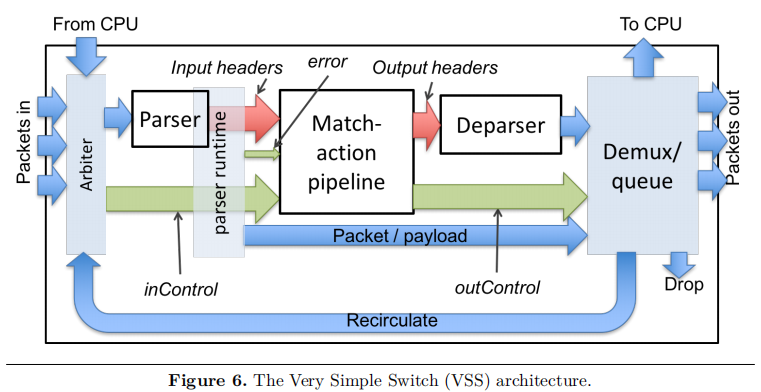
如图所示,这是一个最简单的P4可编程Architecture。VSS可以从8个以太网入端口(最左边的三个蓝色箭头)、再循环通道(最下面的从右到左的蓝色长箭头)或者与CPU(控制平面)直接相连的端口(左上角的蓝色箭头)接收分组。VSS只有唯一的一个Parser,其输出到唯一的一个Match-Action Pipeline。Match-Action Pipeline输出到唯一的一个Deparser,在退出Deparser后,分组被传送到11个出端口(8个以太网出端口+3个特殊端口)中的某一个端口。3个特殊端口分别为:
-
被送到“CPU Port”的分组将被传送到控制平面
-
被送到“Drop Port”的分组将被丢弃
-
被传送到“Recirculate Port”的分组将通过再循环管道回到入端口
图中白色的模块是可编程的部分,用户必须提供对应的P4程序来指定每个白色模块的行为。红色箭头表示用户自定义数据。青色区块是功能固定的组件。绿色箭头是数据平面接口,用来在功能固定的模块和可编程模块之间传递信息——在P4程序中作为Intrinsic Metadata
VSS Architecture 固定功能模块
-
Arbiter Block(仲裁模块)
- 从11个端口(8个以太网入端口+3个特殊端口)中的某一个端口接收分组
- 对于从以太网入端口收到的分组,仲裁模块计算以太网尾部校验和并且进行验证。如果校验和不匹配,该分组将被丢弃。如果校验和匹配,将尾部校验和字段从分组有效荷载中移除。
- 如果有多个分组可用,仲裁模块需要运行仲裁算法来决定哪个分组先处理,其余的分组在等待队列中排队。
- 如果仲裁模块正在处理前一个分组,并且等待队列满了,则输入端口直接丢弃该分组。
- 在收到一个分组后,仲裁模块设置
inCtrl.inputPort的值,该值将作为Match-Action Pipeline的一个输入,以标识该分组的源输入端口。物理以太网端口编号为0~7,再循环通道端口编号为13,CPU端口编号为14。
-
Parser Runtime Block(解析器运行时模块)
解析器运行时模块和Parser协同工作,它基于解析操作给Match-Action Pipeline提供一个错误代码,并且给解复用模块提供分组有效荷载的信息(比如剩余有效荷载的大小等)。从解析器运行时模块到解复用模块的箭头表示从Parser到解复用器的附加信息流:正在处理的分组以及解析结束的分组内的偏移量(即分组有效负载的开始位置)。一旦Parser处理完一个分组,Match-Action Pipeline就会被调用。Match-Action Pipeline以相关的Metadata(Packet Headers和User-defined Metadata)作为输入。
-
Demux Block(解复用模块)
解复用模块的核心功能是接收来自Deparser的新首部和来自Parser的有效荷载,将它们重组成一个新的分组后发送到正确的出端口。出端口由Match-Action Pipeline设置的
outCtrl.outPort值来指定:- 送到Drop端口的分组将被丢弃
- 送到以太网端口(编号为0~7)的分组将会被发送到对应的物理接口。如果该输出接口正在发送另一个分组,则该分组会被放在等待队列里。当要发送该分组时,物理接口会计算一个正确的以太网校验和尾部并追加到分组上。
- 送到CPU端口的分组将会传送到控制平面。如果是这种情况,被传送到CPU的将是原始分组而不是重组后的新分组,重组后的新分组将会被丢弃。
- 送到再循环通道端口的分组将会从再循环通道返回到入端口。当一个分组无法通过单一通道完成处理时,再循环通道就非常有用。
- 如果
outCtrl.outPort制定的出端口号是非法的值(比如端口号为9,前面设置的端口号只有0~7, 13和14),该分组将被丢弃。 - 最后,如果解复用模块正在处理前一个分组并且等待队列已经满了,那么该分组将会被直接丢弃。
VSS程序解析
在此部分将对VSS程序代码进行解析,同时介绍所涉及到的P4语法,完整代码将附在文末。
1. include、typedef 和 type
# include <core.p4>
# include "very_simple_switch_model.p4"
typedef bit<48> EthernetAddress;
typedef bit<32> IPv4Address;
与一个C++程序类似,P4通过# include预处理命令包含一些外部文件。
core.p4是P4的一个核心库,包含对大多数程序有用的声明,例如它包含预定义的packet_in和packet_out外部对象的声明,这些对象在Parser和Deparser中用于访问分组数据。同时,核心库还定义了一些标准数据类型和错误代码。
very_simple_switch_model.p4是VSS Architecture的声明文件,包含了对Parser、Deparser、Package等不可缺少的重要组件的声明。very_simple_switch_model.p4的部分声明(VSS涉及到的)将附在文末。关于Architecture声明的内容将在后面的高级主题部分中介绍。
与C++类似,关键字typedef可以给类型取一个别名:
typedef typeName newName;
上述语句给typeName类型起了一个别名newName。在使用上,newName和typeName完全一样,两者只是名字不一样,实际上是同一个东西。
与typedef有明显区别的是关键字type,它用以引入一个全新的类型。
type typeName newType;
上述语句引入了一种全新的类型,注意newType和typeName是两种不同的类型。如果这两种类型要互相赋值,则需要强制类型转换:
type bit<32> U32;
U32 x = (U32)0;
在描述需要通过通信信道(比如控制平面API或者要被送到控制平面的网络分组)与控制平面进行交换的P4值时,通常使用type关键字。例如:
type bit<9> PortId_t;
上述语句定义了一个全新的类型PortId_t,用以表示长度为 9 比特的端口号。这样可以避免端口号被进行算数运算,因为新引入的类型PortId_t不支持算术运算(尽管bit<9>类型支持算数运算,但他们是不同的两种类型)。
注意,并不是所有类型都支持typedef和type关键字:
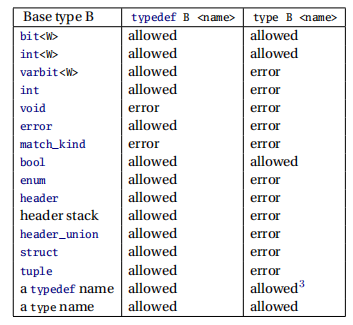
2. header、基础数据类型和操作
header Ethernet_h {
EthernetAddress dstAddr; // 目的地址
EthernetAddress srcAddr; // 源地址
bit<16> etherType; // 上层协议类型
}
header IPv4_h {
bit<4> version; // 版本
bit<4> ihl; // 首部长度
bit<8> diffserv; // 区分服务
bit<16> totalLen; // 总长度
bit<16> identification; // 标识
bit<3> flags; // 标志
bit<13> fragOffset; // 片偏移
bit<8> ttl; // 生存时间
bit<8> protocol; // 协议
bit<16> hdrChecksum; // 首部校验和
IPv4Address srcAddr; // 源地址
IPv4Address dstAddr; // 目的地址
}
分组首部用关键字header定义。header是P4的派生类型,跟c++中的struct关键字类似。header定义了一个特定首部的所有字段。注意,header类型除了显示定义的字段外,还有一个bool类型的隐藏字段validity,表示该首部是否有效,初始值为false。可以使用以下 3 个方法来对validity字段进行操作:
isValid()方法: 返回validity字段的值.setValid()方法:将validity字段值设为truesetInvalid()方法:将validity字段值设为false
如上面的代码所示,VSS定义了两个首部的格式:以太帧首部和IPv4协议首部。bit<n>是基本数据类型中的Integer类型。Integer是整数类型的统称,不是一个标准的基本数据类型,根据有符号和无符号,定长和不定长,分为以下几种形式:
| 基础类型符号 | 说明 |
|---|---|
| bit<w> | 表示长度为 w 比特的无符号整数,也叫bit-string |
| int<w> | 表示长度为 w 比特的有符号整数 |
| varbit<n> | 长度最多为 w 比特的不定长无符号整数 |
| int | 无限精度有符号整数 |
Integer的字面值
一个整数值可能包含某些表示整数类型的前缀:
-
表示数值进制的前缀:
- 0x 或者 0X 表示 16 进制
- 0o 或 0O 表示 8 进制,注意与C++区分,必须是数字0+字母o/O,而不是单独一个数字0。C++中 8 进制用单一数字 0 作为前缀
- 0d 或 0D 表示 10 进制
- 0b 或 0B 表示 2 进制
- 不加以上任何前缀,默认为 10 进制
-
表示长度和有符号无符号属性的前缀:
-
长度用一个数字表示,后面紧跟着字母s/w,表示有/无符号属性
-
nw 表示长度为 n 比特的无符号整数,等价于bit<n>类型
-
ns 表示长度为 n 比特的有符号整数,等价于int<n>类型
-
不带以上任何前缀的等价于int类型
-
-
在数值中间可能出现下划线( _ ),这在P4中也是合法的,计算具体数值时直接忽略下划线
-
长度为n比特的数字,每个比特从0~n-1编号。比特位0是最低有效位(最右边),比特位n-1是最高有效位(最左边)
Integer的操作符
P4中的所有二元操作符(除了移位操作)都要求两个操作数的类型和长度一样。通常来说,对于w比特的整数,若其值超出可表示范围,P4仅保留其低w位。此外,P4支持可选的饱和算术,与传统的取模算术不同。具体体现在溢出时采取的方式不同:假设一个长度为8比特的有符号运算结果的真实值为130,。我们都知道8比特长度能表示的有符号数值范围为-128~127,显然130不在范围内。对于饱和算术,该结果将会尽可能的接近真实数值,即该结果将被设为127;而对于取模算术,将130对128取模后得到-126(不同的取模运算实现方式得到的值不一样,这里是采用向上取整的方式,采用截断方式和向下取整结果是2)。同样的,对于8比特无符号数258,P4的结果为255,而不是2。
无符号整数bit<w>类型
| 操作符 | 举例 | 功能描述 |
|---|---|---|
| 负号(-) | -X | 与C++一样,其结果为2W-X |
| 正号(+) | +X | 等价于X |
| 减号(-) | a-b | 与C++一样,结果为无符号数,等价于a+(-b) |
| 加号(+)、乘号(*) | a+b、a*b | 与C++一样,溢出则只取低w位 |
| 饱和算术减 | |-| | 采用饱和算术进行减法 |
| 饱和算术加 | |+| | 采用饱和算术进行加法 |
| 按位与、或、异或、取反 | &、|、^、~ | 与C++一样 |
| 比较运算符 | ==、!=、>、<、>=、<= | 与C++一样 |
| 逻辑左移、右移 | X<<n、X>>n | 左操作数是无符号整数,右操作数必须是bit<w>类型或者一个非负整数,如果 n 大于 X 的长度,则 X 所有位都变为 0 |
| 提取 | X=E[L:R]、e[L:R]=x | w>L>=R>=0,将 E 的R~L(包括R和L)比特位提取出来赋值给X。X 结果是一个长度为L-R+1的无符号整数;做左值时表示将e的R~L(包括R和L)比特位设置为x,其他位不变。若x是有符号整数,则视为无符号整数。注意P4比特位编号是从右往左,从0到w-1。 |
| 拼接 | a++b | 将b拼接在a的后面,结果的总长度为a的长度和b的长度和,类型和符号取决于a |
有符号整数int<w>类型
| 操作符 | 举例 | 功能描述 |
|---|---|---|
| 负号(-) | -X | 与C++一样 |
| 正号(+) | +X | 等价于X |
| 加号(+)、减号(-)、乘号(*) | a+b、a-b、a*b | 与C++一样,溢出则只取低w位 |
| 饱和算术减 | |-| | 采用饱和算术进行减法 |
| 饱和算术加 | |+| | 采用饱和算术进行加法 |
| 按位与、或、异或、取反 | &、|、^、~ | 与C++一样 |
| 比较运算符 | ==、!=、>、<、>=、<= | 与C++一样 |
| 左移、右移 | X<<n、X>>n | 左操作数是有符号整数,右操作数必须是bit<w>类型或者非负整数,左移操作,与无符号移位操作一样;右移操作,高位补符号位 |
| 提取 | X=E[L:R]、e[L:R]=x | w>L>=R>=0,将 E 的R~L(包括R和L)比特位提取出来赋值给X。X 结果是一个长度为L-R+1的无符号整数;做左值时表示将e的R~L(包括R和L)比特位设置为x,其他位不变。若x是有符号整数,则视为无符号整数。注意P4比特位编号是从右往左,从0到w-1。 |
| 拼接 | a++b | 将b拼接在a的后面,结果的总长度为a的长度和b的长度和,类型和符号取决于a |
任意精度整数int类型
| 操作符 | 举例 | 功能描述 |
|---|---|---|
| 负号(-) | -X | 与C++一样 |
| 正号(+) | +X | 等价于X |
| 加号(+)、减号(-)、乘号(*) | a+b、a-b、a*b | 与C++一样,因为是无限精度,不会溢出,所以也不存在饱和算术 |
| 除号 | a/b | 正整数间的截断除法 |
| 取模 | a%b | 正整数间的取模运算 |
| 饱和运算操作和按位操作 | |+|、|-|、&、|、^、~ | 未定义 |
| 比较运算符 | ==、!=、>、<、>=、<= | 与C++一样 |
| 左移、右移 | X<<n、X>>n | 左操作数是有符号整数,右操作数必须是正整数,左移等价于X*2n,右移等价于X/2n |
| 提取 | X=E[L:R]、e[L:R]=x | w>L>=R>=0,将 E 的R~L(包括R和L)比特位提取出来赋值给X。X 结果是一个长度为L-R+1的无符号整数;做左值时表示将e的R~L(包括R和L)比特位设置为x,其他位不变。若x是有符号整数,则视为无符号整数。注意P4比特位编号是从右往左,从0到w-1。 |
| 拼接 | a++b | 将b拼接在a的后面,结果的总长度为a的长度和b的长度和,类型和符号取决于a |
不定长整数varbit<n>类型
varbit只支持以下操作:
- 赋值操作。a=b,a和b必须有一样的静态长度。在执行赋值的时候,a的动态长度会被设置为b的动态宽度。
- 比较是否相等。当且仅当a和b的长度和每一位的值都一样时,两者才相等。
P4的其他基础类型
| 基础类型 | 类型值(core.p4中定义的) |
|---|---|
| void | —— |
| error | ParseError,PacketTooShort等 |
| string | 仅允许用于表示编译时常量字符串值 |
| match_kind | exact,ternary,lpm |
| bool | true,false |
类型转化
显式转换
| 类型转换 | 说明 |
|---|---|
| bit<1> <-> bool | 0是false,1为true,反之亦然 |
| int -> bool | 只有当int的值为 0 或 1 时,对应的bool值为false或true |
| int<w> -> bit<w> | 所有比特位不变,把负数当做正数 |
| bit<w> -> int<w> | 所有比特位不变,如果最高位为1,则视为负数 |
| bit<w> -> bit<x> | 如果 w>x,保留低 x 位;如果 w<x,高位补 0 |
| int<w> -> int<x> | 如果 w>x,保留低 x 位;如果 w<x,高位补符号位 |
| bit<w> -> int | 所有比特位不变,结果永远为正 |
| int<w> -> int | 所有比特位不变,结果可能为负 |
| int -> bit<w> | 转为补码后,保留低 w 位 |
| int -> int<w> | 转为补码后,保留低 w 位 |
隐式转化
为了保持语言简单并避免引入隐藏代价,P4只隐式地将int类型转换为固定宽度类型,并将具有基础类型的enum转换为基础类型。特别是,对int类型的表达式和具有固定宽度类型的表达式使用二目操作,会将int类型的操作数隐式转换为另一个操作数的类型。
Mask(&&&) 操作和 Range(..) 操作
&&&:Mask操作,接受两个bit<w>类型的操作数,得到一个集合,集合中的元素类型为bit<w>
a &&& b={c | bit<w> c, c 满足a&b==c&b}
..:Range操作,接受两个类型为int<w>或bit<w>的操作数,得到一个集合,集合中的元素包括两个操作数之间的所有连续整数。
4w5..4w8 // 得到集合{4w5, 4w6, 4w7, 4w8}
3. struct、header stack 和 header union
struct Parsed_packet {
Ethernet_h ethernet;
IPv4_h ip;
}
struct
与header类似,struct也是一个派生类型,具体用法跟C++的结构体一样。没有任何字段的空结构体也是合法的。这里主要介绍另外两个跟header密切相关的派生类型header stack和header_unions。
header stack
header stack类似C++中的数组,该数组元素是header类型的,例如:
header Mpls_h {
bit<20> label;
bit<3> tc;
bit bos;
bit<8> ttl;
}
Mpls_h[10] mpls;
上例中,定义了一个名为mpls的header stack,它包含10个元素,每个元素都是Mpls_h类型的。
header stack的操作
假设有一个名为 hs,大小为 n 的header stack,则 hs 有如下操作
hs[index]:下标为index的元素的引用,0<=index<nhs.size:返回hs的大小hs.nextIndex:计数器,hs.next初始值为 0,每当成功调用一次extract,计数器会自动加 1。hs.next:返回下标为hs.nextIndex的元素的引用,只能在Parser中使用。hs.next初始指向 hs 的第一个元素,每当成功调用一次extract,指针会自动往前推进。当hs.nextIndex大于等于 n 时,访问hs.next会出现error.StackOutOfBounds的错误hs.lastIndex:返回hs.nextIndex-1,只能在Parser中使用。hs.last:返回下标为hs.nextIndex-1的元素的引用,只能在Parser中使用。当hs.nextIndex等于 0 时,访问hs.last会出现error.StackOutOfBounds的错误hs.push_front(int count):将hs的元素依次右移count个位置,原hs的前count个元素无效,后count个元素被消除hs.pop_front(int count):将hs的元素依次左移count个位置,原hs的前count个元素被消除,后count个元素无效
header union
header_union是多个header类型元素的共同体,所有元素共用存储资源,并且最多只能选择其中的一个元素。例如:
header_union IP_h {
IPv4_h v4;
IPv6_h v6;
}
上例定义了一个名为IP_h的共同体,包含两个协议首部IPv4和IPv6,但是在任何时刻,只有其中的一个协议生效。即,任何时刻,header_union里面的Header,只有一个Header的validity字段是true,其余所有Header的validity字段都是false。
4. error
error {
IPv4OptionsNotSupported,
IPv4IncorrectVersion,
IPv4ChecksumError
}
自定义了三个错误代码,在core.p4中也预定义了一些错误代码:
error {
NoError, // No error.
PacketTooShort, // Not enough bits in packet for 'extract'.
NoMatch, // 'select' expression has no matches.
StackOutOfBounds, // Reference to invalid element of a header stack.
HeaderTooShort, // Extracting too many bits into a varbit field.
ParserTimeout, // Parser execution time limit exceeded.
ParserInvalidArgument // Parser operation was called with a value
// not supported by the implementation.
}
除了上述用户自定义的数据结构外,通常一个P4程序还需要实现Parser、Match-Action管道和Deparser三个关键模块。在VSS中,这三个模块的功能如下:
-
Parser:需要识别的Header为Ethernet Header,其后跟着IPv4 Header。如果这两个Header有一个丢失,解析终止同时记录一个错误代码。否则,它会将这些Header中的信息提取到数据结构
Parsed_packet中。 -
Match-Action管道:它包含四个Match-Action单元(即有四个Table),如下图所示:
-
如果有任何解析错误出现,该分组将被丢弃。实现方式为将
outCtrl.outPort的值设置为DROP_PORT -
第一个Table使用IPv4协议目的地址来决定
outCtrl.outPort和下一跳的IPv4地址。如果查表失败,丢弃分组。此外,该表还减少IPv4的ttl字段值。 -
第二个Table检查ttl的值:如果ttl值为0,从CPU端口将分组发送到控制平面。
-
第三个Table使用下一跳的IPV4地址(第一个表计算的)来决定下一跳的以太网地址。
-
最后一个Table使用
outCtrl.outPort来标识当前交换机的源以太网地址,该地址在输出分组中设置。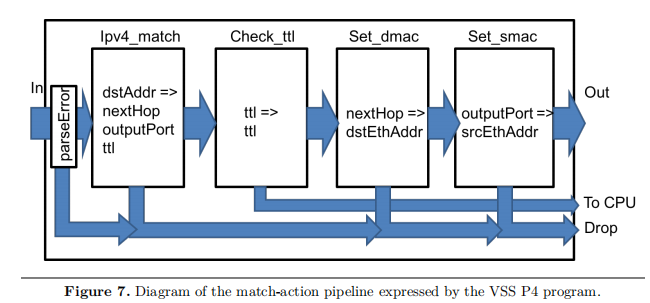
-
-
Deparser:通过重新组装Match-Action管道计算的以太帧Header和IPv4协议Header来构造输出分组
基于上述功能描述,下面将介绍Parser、Match-Action管道和Deparser三个关键模块的代码实现。
5. Parser
// Parser section
parser TopParser(packet_in b, out Parsed_packet p) {
Checksum16() ck; // instantiate checksum unit
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
0x0800: parse_ipv4;
// no default rule: all other packets rejected
}
}
state parse_ipv4 {
b.extract(p.ip);
verify(p.ip.version == 4w4, error.IPv4IncorrectVersion);
verify(p.ip.ihl == 4w5, error.IPv4OptionsNotSupported);
ck.clear();
ck.update(p.ip);
// Verify that packet checksum is zero
verify(ck.get() == 16w0, error.IPv4ChecksumError);
transition accept;
}
}
P4中的Parser实际上是一个有穷状态机(Finite State Machine,FSM),包含一个起始状态(start)和两个终结状态(accept,表示解析成功,和reject,表示解析失败)。注意,start状态是Parser的一部分,是程序员提供的状态,而accept和reject逻辑上实在Parser之外的,与程序员提供的状态不同,如下图所示。一个Parser从一个start状态开始,直到到达一个accept或者reject状态为止。Architecture必须指定到达accept或者reject状态时的具体行为。
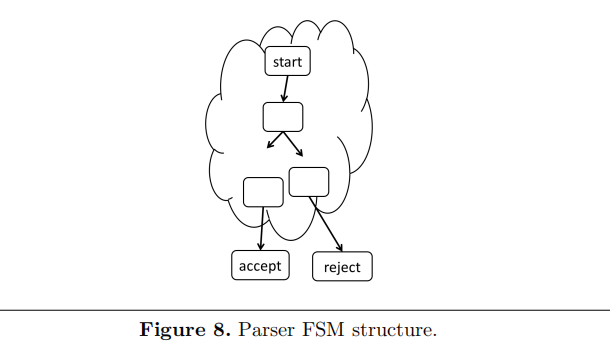
VSS的Parser声明如下:
parser Parser<H>(packet_in b,
out H parsedHeaders);
可以看到,该Parser接收两个参数,一个是packet_in类型的,表示输入分组。另一个是H类型的,表示一个已解析的Header。H是一个泛型,不是一个具体的类型,程序员需要自己用自定义的Header类型替代。注意到在第二个参数的最前面有一个out关键字。P4中有三个方向关键字,用以指定参数的方向属性:
in:输入参数,该参数是只读的,不能作为左值
out:输出参数,该参数通常是未初始化的,并且必须是左值。在执行函数调用后,参数的值被复制到该左值的相应存储位置
inout:既可以是in也可以是out,必须是左值
从代码上可以看到,VSS自定义了两个状态start和parse_ipv4。每个状态以state关键字标识,其后跟着状态名,然后是具体的状态体(用花括号包含)。不难发现,两个状态体中共有的关键字有extract、transition和select,我们将逐一介绍。
extract
extract:前面提到在core.p4中声明了一个内置的外部类型packet_in,表示输入分组:
extern packet_in {
void extract<T>(out T headerLvalue);
void extract<T>(out T variableSizeHeader, in bit<32> varFieldSizeBits);
T lookahead<T>();
bit<32> length(); // This method may be unavailable in some architectures
void advance(bit<32> bits);
}
extract是packet_in中的一个方法。Parser通过调用extract方法来抽取分组数据。可以看到extract有两个变体:
void extract<T>(out T headerLeftValue);
该方法只有一个参数headerLeftValue,用以提取长度固定的header类型首部。如果该方法成功执行,headerLeftValue的值将被从对应分组中提取的数据字段填充,并且validity字段被设置为true。例如,在VSS中的start状态中,如果extract方法执行成功,那么p.ethernet的各个字段将被从分组b中抽取的数据填充,并且p.ethernet的隐含字段validity将被置为true
此外,还有一种包含两个参数的变体:
void extract<T>(out T headerLvalue, in bit<32> variableFieldSize);
该方法中,headerLeftValue必须是恰好包含一个varbit类型的字段。第二个参数variableFieldSize是一个bit<32>类型的整数,表示该首部中唯一的varbit字段的长度。下面介绍完lookahead方法后,会举例说明如何使用具有两个参数的变体。
packet_in 中的其他方法介绍
lookahead
T lookahead<T>();
lookahead方法与extract类似,用以抽取数据,但不同的地方在于:
extract抽取的数据填充在headerLeftValue参数中,而lookahead是返回所抽取的数据extract抽取完数据后,nextBitIndex指针会往前推进,而使用lookahead方法,nextBitIndex指针不推进- T 必须是固定长度的类型,即,T 不能包含
varbit字段
穿插一点补充内容:
关于如何使用extract的第二个变体:
前面提到,“extract第二个变体需要两个参数,headerLeftValue必须是恰好包含一个varbit类型的字段。第二个参数variableFieldSize是一个bit<32>类型的整数,表示该首部中唯一的varbit字段的长度”,那么varbit字段的长度的长度该如何确定呢?换句话说,第二个参数如何确定?事实上,我们可以结合lookahead方法,计算出该varbit字段的长度,考虑一下例子:
header Tcp_option_sack_h {
bit<8> kind;
bit<8> length;
varbit<256> sack;
}
struct Tcp_option_sack_top {
bit<8> kind;
bit<8> length;
}
parser Tcp_option_parser(packet_in b, out Tcp_option_stack vec) {
state start {
. . . . . . .
}
. . . . . . . // 其他的state定义,不具体列出
state parse_tcp_option_sack {
bit<8> n = b.lookahead<Tcp_option_sack_top>().length;
b.extract(vec.next.sack, (bit<32>) (8 * n - 16));
transition start;
}
}
在上面的例子中,我们定义一个包含一个varbit<256> sack字段的首部header Tcp_option_sack_h,该首部还包含另外两个字段:kind(表示类型)和length(表示该首部的总长度,单位是字节)。现在如果能够确定首部Tcp_option_sack_h的总长度 n字节,那么就可以计算出sack的长度是n-2(字节)了。于是,我们可以按照以下步骤来做:
-
先定义一个
struct Tcp_option_sack_top,仅包含Tcp_option_sack_h的两个固定字段,然后用lookahead方法提取分组中的Tcp_option_sack_top数据。Tcp_option_sack_top是固定长度,因此可以使用lookahead方法。从而,我们可以得到length字段的值,这样就得到了首部的总长度:bit<8> n = b.lookahead<Tcp_option_sack_top>().length; -
基于此,再进一步调用
extract方法,就可以提取出整个首部了。由于lookahead方法不会使nextBitIndex指针往前推进,所以对extract方法不会产生影响。b.extract(vec.next.sack, (bit<32>) (8 * n - 16)); // n的单位是字节,第二个参数的单位是比特,因此需要进行转化
本例子讲述了如何通过lookahead方法和extract方法相结合的方式,提取包含varbit字段的首部。
advance
advance方法用以跳过bits个比特的数据。由于上面提到extract抽取完数据后,nextBitIndex指针会往后推进,因此也可以使用extract方法将数据抽取到下划线标识符上使指针往前推进,从而跳过接下来的一些比特:
b.extract<T>(_)
Parser中的 transition 和 select
transition语句用控制状态转移,类似goto语句。select语句类似switch,但是与之不同的是,在P4中,default和_标签后面的case是不可到达的。这意味着,select中的标签可能是可以重复的,如果重复的标签是在default和_标签之后,则后面的重复标签不可到达。
Parser中的 checksum 和 verify
checksum是一个外部函数,用来计算检验和:
extern Checksum16 {
Checksum16(); // constructor
void clear(); // prepare unit for computation
void update<T>(in T data); // add data to checksum
void remove<T>(in T data); // remove data from existing checksum
bit<16> get(); // get the checksum for the data added since last clear
}
verify也是一个外部函数,只能在Parser中调用:
extern void verify(in bool condition, in error err);
如果condition是true,该方法没有任何作用。如果condition是false,则会立即transition到reject状态,设置解析错误代码为err(第二个参数)
6. Match-Action Pipeline
// Match-action pipeline section
control TopPipe(inout Parsed_packet headers,
in error parseError, // parser error
in InControl inCtrl, // input port
out OutControl outCtrl) {
IPv4Address nextHop; // local variable
/***************table 1***************/
action Drop_action() {
. . . . . .
}
action Set_nhop(IPv4Address ipv4_dest, PortId port) {
. . . . . .
}
table ipv4_match {
. . . . . .
}
/***************table 2***************/
action Send_to_cpu() {
. . . . . .
}
table check_ttl {
. . . . . .
}
/***************table 3***************/
action Set_dmac(EthernetAddress dmac) {
. . . . . .
}
table dmac {
. . . . . .
}
/***************table 4***************/
action Set_smac(EthernetAddress smac) {
. . . . . .
}
table smac {
. . . . . .
}
apply {
. . . . . .
}
}
Parser负责从分组中提取首部数据。这些首部(和其他的Metadata)可以在控制模块中进行操作和转换。实现控制模块功能的主体是Match-Action Units,其核心组件是table和action。
action是控制平面可以动态影响数据平面行为的主要结构:
action actionName(parameterList){动作主体}
参数列表中,没有方向属性的参数称为“action data”,这些参数需要放在参数列表的末尾,并且这些参数值来自表项(table entries)(例如,由控制平面指定、默认的default_action属性或者const entries属性)。动作主体用花括号包含,是一些列的语句或者申明,但是不能有switch语句。
table描述了一个Match-Action Unit,执行以下步骤(如下图所示):
-
构造
Key -
查表。表中通过
key来查找表项(match的过程),查找的结果是一个action。lookup table是一个有限映射,其内容由控制平面通过单独的控制平面API进行异步操作(读/写)。 -
执行对应的
action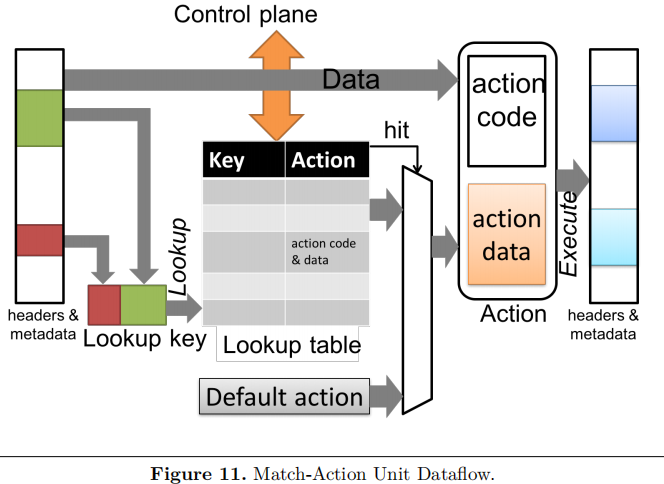
一个标准的table需要包含key和action属性,可选的包含default_action和size属性:
-
key是形如(expression:match_kind)的一对二元组。expression指定key的内容,match_kind指定key的匹配方式。P4核心库定义了三种匹配方式:exact(完全匹配)、lpm(最长前缀匹配)和ternary(三元匹配,即匹配某些指定的比特位,例如用mask操作指定一些比特位,可参见下面例子中的注释)。 -
default_action,当查表失败时,执行default_action指定的动作。如果没有显示的指定default_action,编译器会默认为每个table指定default_action为NoAction。 -
size是一个整数,指定该table所需的大小。 -
const entries。前面提到,table entries可以由const entries指定。我们可以事先定义一些表项,用以在编译时初始化表项,下面这个例子分别使用exact和ternary方式进行两个key匹配,同时用const entries指定了一些常量表项。同时,在常量表项中用注释解释了三元匹配:header hdr { bit<8> e; bit<16> t; bit<8> l; bit<8> r; bit<1> v; } struct Header_t { hdr h; } struct Meta_t {} control ingress(inout Header_t h, inout Meta_t m, inout standard_metadata_t standard_meta) { action a() { standard_meta.egress_spec = 0; } action a_with_control_params(bit<9> x) { standard_meta.egress_spec = x; } table t_exact_ternary { key = { h.h.e : exact; h.h.t : ternary; } actions = { a; a_with_control_params; } default_action = a; const entries = { /** 以0x1111 &&& 0xF为例,解释一下三元匹配 * 0001 0001 0001 0001 & 0000 0000 0000 1111 = 0000 0000 0000 0001 * xxxx xxxx xxxx 0001 & 0000 0000 0000 1111 = 0000 0000 0000 0001 * 这意味着,只要低4位是0001,高12位不管是什么都可以匹配成功 * 这么匹配有可能会匹配到多个结果,用户需要为每个表项定一个优先级, * 当存在多个匹配时,根据用户定义好的优先级进行选择,最终只能匹配一个结果*/ (0x01, 0x1111 &&& 0xF ) : a_with_control_params(1); (0x02, 0x1181 ) : a_with_control_params(2); (0x03, 0x1111 &&& 0xF000) : a_with_control_params(3); (0x04, 0x1211 &&& 0x02F0) : a_with_control_params(4); (0x04, 0x1311 &&& 0x02F0) : a_with_control_params(5); (0x06, _ ) : a_with_control_params(6); _ : a; } } } -
当定义好 Match-action Units后,还需要使用
apply来调用
下面将分别介绍每个table以及所涉及到的action实现
7. the first table in VSS
/***************table 1***************/
action Drop_action() {
outCtrl.outputPort = DROP_PORT;
}
action Set_nhop(IPv4Address ipv4_dest, PortId port) {
nextHop = ipv4_dest;
headers.ip.ttl = headers.ip.ttl - 1;
outCtrl.outputPort = port;
}
table ipv4_match {
key = { headers.ip.dstAddr: lpm; } // longest-prefix match
actions = {
Drop_action;
Set_nhop;
}
size = 1024;
default_action = Drop_action;
}
第一个table使用IPv4协议目的地址来决定outCtrl.outPort和下一跳的IPv4地址。如果查表失败,丢弃分组。此外,该表还减少IPv4的ttl字段值。
为了实现上述功能,首先定义了两个action。Drop_action通过把outCtrl.outPort设为DROP_PORT来指示解复用模块应该丢弃该分组。Set_nhop接收两个参数,通过参数ipv4_dest来获取IPv4协议目的地址,通过参数port来指定输出端口号outCtrl.outPort。Set_nhop用自定义的nexthop局部变量来表示下一跳的IPv4地址。同时,还应该将首部的ttl字段值减 1。ipv4_dest和port没有方向属性,都是“action data”,由表项提供。
table的主体包含了key、actions、size和default_action属性。key指定根据首部的dstAddr字段来查表,匹配方式是lpm(最长前缀匹配)。actions指定匹配的结果有Drop_action和Set_nhop两种。size指定table的大小为1024字节。default_action指定默认动作为Drop_action。
8. the second table in VSS
action Send_to_cpu() {
outCtrl.outputPort = CPU_OUT_PORT;
}
table check_ttl {
key = { headers.ip.ttl: exact; }
actions = {
Send_to_cpu;
NoAction;
}
const default_action = NoAction; // defined in core.p4
}
第二个Table检查ttl字段的值:如果ttl值为0,从CPU端口将分组发送到控制平面。
为了实现上述功能,首先定义了一个Send_to_cpu动作,把outCtrl.outPort设为CPU_OUT_PORT来指示解复用模块应该将该分组发送到控制平面。
table的主体包含了key、actions和default_action属性。key指定根据首部的ttl字段来查表,匹配方式是exact(完全匹配)。actions指定匹配的结果有Send_to_cpu和NoAction两种。NoAction是核心库中定义的一个动作,没有做任何具体的操作。default_action指定默认动作为NoAction。
9. the third table in VSS
action Set_dmac(EthernetAddress dmac) {
headers.ethernet.dstAddr = dmac;
}
table dmac {
key = { nextHop: exact; }
actions = {
Drop_action;
Set_dmac;
}
size = 1024;
default_action = Drop_action;
}
第三个Table使用下一跳的IPV4地址(第一个表计算的)来决定下一跳的以太网地址。
为了实现上述功能,首先定义了一个Set_dmac动作。Set_dmac接收一个参数,通过参数dmac来获取下一跳的以太网地址(ethernet首部的dstAddr字段)。dmac没有方向属性,是“action data”,由表项提供。
table的主体包含了key、actions、size和default_action属性。key指定根据nexthop来查表,匹配方式是exact(完全匹配)。actions指定匹配的结果有Drop_action和Set_dmac两种。size指定table的大小为1024字节。default_action指定默认动作为Drop_action。
10. the last table in VSS
action Set_smac(EthernetAddress smac) {
headers.ethernet.srcAddr = smac;
}
table smac {
key = { outCtrl.outputPort: exact; }
actions = {
Drop_action;
Set_smac;
}
size = 16;
default_action = Drop_action;
}
最后一个Table使用outCtrl.outPort来标识当前交换机的源以太网地址,该地址在输出分组中设置。
为了实现上述功能,首先定义了一个Set_smac动作。Set_smac接收一个参数,通过参数smac来获取源以太网地址(ethernet首部的srcAddr字段)。smac没有方向属性,是“action data”,由表项提供。
table的主体包含了key、actions、size和default_action属性。key指定根据outCtrl.outPort来查表,匹配方式是exact(完全匹配)。actions指定匹配的结果有Drop_action和Set_smac两种。size指定table的大小为16字节。default_action指定默认动作为Drop_action。
11. apply
apply {
if (parseError != error.NoError) {
Drop_action(); // invoke drop directly
return;
}
ipv4_match.apply(); // Match result will go into nextHop
if (outCtrl.outputPort == DROP_PORT)
return;
check_ttl.apply();
if (outCtrl.outputPort == CPU_OUT_PORT)
return;
dmac.apply();
if (outCtrl.outputPort == DROP_PORT)
return;
smac.apply();
}
在实现了上述Match-Action Units后,还需要使用apply来调用。实现方式是通过apply关键字和一个大括号包含的主体。在主体中,每个table各自调用apply方法。
在VSS的apply主体中,首先,如果有任何解析错误出现,该分组将被丢弃。实现方式为将outCtrl.outPort的值设置为DROP_PORT。然后,如果没有出现解析错误,则依次调用上述四个table。通过if语句和return语句来控制是否继续调用接下来的table。
12. Deparser
// deparser section
control TopDeparser(inout Parsed_packet p, packet_out b) {
Checksum16() ck;
apply {
b.emit(p.ethernet);
if (p.ip.isValid()) {
ck.clear(); // prepare checksum unit
p.ip.hdrChecksum = 16w0; // clear checksum
ck.update(p.ip); // compute new checksum.
p.ip.hdrChecksum = ck.get();
}
b.emit(p.ip);
}
}
Deparser是Parser的逆过程,Deparser也是一个control块,至少包含一个packet_out参数,表示输出分组。Deparser主体包含一个apply块,在apply中调用emit方法来构造分组。emit是packet_out的一个方法:
- 当
emit应用于一个首部时,如果首部是有效的,则把首部数据加到分组里。否则,不进行任何操作。 - 当
emit应用于一个header stack时,emit对header stack内的每个元素递归地调用自身。 - 当应用于一个
struct或者header union时,emit对每个字段递归调用自身。注意struct不能包含error或enum字段。
13. package
// Instantiate the top-level VSS package
VSS(TopParser(),
TopPipe(),
TopDeparser()) main;
最后,实例化一个package,在顶层命名空间中创建一个名为main的变量。VSS的package声明如下:
package VSS<H> (Parser<H> p,
Pipe<H> map,
Deparser<H> d);
高级主题
Architecture 声明
Target 厂商必须以P4源文件的形式提供一个Architecture 声明,改声明至少需要包含一个Package申明。用户必须实例化这个Package才能为Target构造程序。
Architecture 声明可能预定义一些数据类型、Package实现助手和错误代码等。同时,也需要声明所有出现在Target中的可编程模块的类型:Parser和Control模块。以下是一个Architecture 声明的例子:
parser Parser<IH>(packet_in b, out IH parsedHeaders);
// ingress match-action pipeline
control IPipe<T, IH, OH>(in IH inputHeaders,
in InControl inCtrl,
out OH outputHeaders,
out T toEgress,
out OutControl outCtrl);
// egress match-action pipeline
control EPipe<T, IH, OH>(in IH inputHeaders,
in InControl inCtrl,
in T fromIngress,
out OH outputHeaders,
out OutControl outCtrl);
control Deparser<OH>(in OH outputHeaders, packet_out b);
package Ingress<T, IH, OH>(Parser<IH> p,
IPipe<T, IH, OH> map,
Deparser<OH> d);
package Egress<T, IH, OH>(Parser<IH> p,
EPipe<T, IH, OH> map,
Deparser<OH> d);
package Switch<T>(Ingress<T, _, _> ingress, Egress<T, _, _> egress);
仅从上面的声明我们就可以得到很多有用的信息(如下图所示):
-
该交换机包含两个独立的Package:
Ingress和Egress -
在
Ingress中,Parser、IPipe和Deparser是按顺序串联在一起的,Parser的输出out IH parsedHeaders是IPipe的一个输入in IH inputHeaders。IPipe的输出out OH outputHeaders是Deparser的一个输入in OH outputHeaders。在Egress中类似。 -
Ingress和Egress之间有连接,这是因为IPipe的第一个输出out T toEgress,是EPipe的一个输入参数in T fromIngress。注意到,在Package switch中,package Ingress和package Egress中的类型T必须是同一种类型,而两者中的类型IH可以是不同的。如果要指定package Ingress和package Egress中的类型IH也必须是同一种类型,则可以声明如下:package Switch<T,IH,_>(Ingress<T, IH, _> ingress, Egress<T, IH, _> egress).两者中的类型
OH同理。

因此,该Architecture建立了一个交换机模型,该模型的Ingress和**Egress **流水线之间包含两个独立的通道:
- 通过 T 类型参数直接传递数据的通道。
- 一种可以使用Parser和Deparser间接地传递数据的通道,该Parser和Deparser将数据序列化成分组并返回。
在实例化Package时,参数之间的类型必须互相匹配。考虑以下例子:
-
Architecture声明如下:
parser Prs<T>(packet_in b, out T result); control Pipe<T>(in T data); package Switch<T>(Prs<T> p, Pipe<T> map); -
程序员编程声明如下:
parser P(packet_in b, out bit<32> index) { /* body omitted */ } control Pipe1(in bit<32> data) { /* body omitted */ } control Pipe2(in bit<8> data) { /* body omitted */ } -
以下Package实例化是正确的,
Parser p的参数类型和Pipe2的参数类型均为bit<32>,类型匹配:Switch(P(), Pipe1()) main; -
以下Package实例化是错误的,因为
Parser p的参数类型是bit<32>,而Pipe2的参数类型是bit<8>,二者不匹配:Switch(P(), Pipe2()) main;
在上面例子中,实例化时没有显示的指明类型,编译器需要自己推断。程序员也可以在实例化Package时显示的指明类型:
Switch<bit<32>>(P(), Pipe1()) main;
P4抽象机
编译时已知值
以下是编译时已知值:
-
Integer字面值,bool字面值和string字面值 -
在
error、enum或者match_kind声明中声明的标识符 -
默认的(
default)标识符 -
header stack的size字段 -
在
select表达式中用作标签的下划线标识符(“_”) -
表示声明类型的标识符、actions、tables、parsers、controls或者packages
-
所有元素都是编译时已知值的
list表达式 -
所有字段都是编译时已知值的结构体初始化表达式
-
实例声明和构造函数调用所创建的实例
-
操作数均为编译时已知值的操作表达式
-
const关键字声明的常量标识符 -
形如
e.minSizeInBits()和e.minSizeInBytes()的表达式
编译时求值
一个程序的求值从顶层命名空间开始,按照声明的顺序处理:
-
所有的声明(例如Parsers、controls、类型、常量)对自身进行求值
-
每个
table求值结果为一个table实例 -
构造函数调用求值结果是对应类型的有状态对象。为此,所有构造函数参数都被递归求值并绑定到构造函数参数。构造函数参数必须是编译时已知值。构造函数参数的求值结果应该与顺序无关,即所有求值顺序都应该产生相同的结果
-
实例化对象求值结果是命名的有状态对象
-
Parser或control的实例化递归地对模块中声明的所有有状态实例化对象进行求值。 -
程序的求值结果是顶层
main变量的值。
所有有状态值都在编译时初始化。考虑以下例子:
// architecture declaration
parser P(/* parameters omitted */);
control C(/* parameters omitted */);
control D(/* parameters omitted */);
package Switch(P prs, C ctrl, D dep);
extern Checksum16 { /* body omitted */}
// user code
Checksum16() ck16; // checksum unit instance
parser TopParser(/* parameters omitted */)(Checksum16 unit) { /* body omitted */}
control Pipe(/* parameters omitted */) { /* body omitted */}
control TopDeparser(/* parameters omitted */)(Checksum16 unit) { /* body omitted */}
Switch(TopParser(ck16),
Pipe(),
TopDeparser(ck16)) main;
上述程序的求值过程如下:
P、C、D、switch和checksum16的声明对自身进行求值- 对
Checksunm16() ck16实例进行求值,并产生一个名为ck16类型为Checksum16的对象 TopParser、Pipe和TopDeparser的声明对自身求值- 对
main变量进行求值:- 递归地对构造函数的参数进行求值
控制平面名字
P4 程序中每个可控制实体都必须分配一个唯一的、完全限定的名字,控制平面可以使用该名称与该实体进行交互。可控制实体有:tables、keys、actions和外部实例。
完全限定名称由可控实体的本地名字和其封闭命名空间的完全限定名名字组成。因此,包含可控实体的程序结构(比如 control 实例和 Parser 实例)本身必须具有唯一的、完全限定的名字。
一个结构的完全限定名字是由它的封闭命名空间和它的本地名字拼接而成的。如果一个结构没有封闭的命名空间,比如定义在全局的结构,那么它的完全限定名字和本地名字一样。
本地名字的确定
- table:对于table结构,它的句法名称即为本地名字:
control c(/* parameters omitted */)() {
table t { /* body omitted */ }
}
上述例子中,table的本地名字为t
-
keys:在句法上,key是一个表达式,对于简单的表达式,key的本地名字可以直接从表达式中派生出来。比如下面例子中的两个key的本地名字分别为
data.f1和hdrs[3].f2:table t { keys = { data.f1 : exact; hdrs[3].f2 : exact; } actions = { /* body omitted */ } }比较复杂的表达式(比如包含运算的表达式)就必须通过@name annotation(关于annotation将在下一个部分说明)来指定本地名字。比如下面例子通过@name("f1_mask") annotation给key分配本地名字
"f1_mask"table t { keys = { data.f1 + 1 : exact @name("f1_mask"); } actions = { /* body omitted */ } } -
actions:对于action结构,其句法名字就是本地名字。比如下面例子中,action的本地名字为
a:control c(/* parameters omitted */)() { action a(...) { /* body omitted */ } } -
实例:
extern、parser和control实例的本地名字取决于它们是如何使用的:-
如果实例被绑定了一个名字,那么该名字即为它的本地控制平面名字。比如下面例子中,
control C实例的本地名字为c_inst:control C(/* parameters omitted */)() { /* body omitted */ } C() c_inst; -
如果实例是作为实参被创建,那么它的本地名字是它将要绑定的形参的名字。比如下面例子中,
extern E实例的本地名字为e_in:extern E { /* body omitted */ } control C( /* parameters omitted */ )(E e_in) { /* body omitted */ } C(E()) c_inst; -
如果正在被实例化的结构作为参数被传递到一个Package,则实例名字将从用户提供的类型定义中派生:
extern E { /* body omitted */ } control ArchC(E e1); package Arch(ArchC c); control MyC(E e2)() { /* body omitted */ } Arch(MyC()) main;在上面例子中,从
package Arch的声明来看,其参数应该是ArchC类型的。但在实际的实例化过程中,package Arch使用了用户自定义的类型MyC,该实例将被绑定到MyC的形参。因此extern E的实例应该从用户自定义的类型MyC中派生。所以,extern E的实例的本地名字是e2,而不是e1。该extern E实例的完全限定名字为main.c.e2 -
举个有多个实例的的例子来再次说明本地名字的生成:
control Callee() { table t { /* body omitted */ } apply { t.apply(); } } control Caller() { Callee() c1; Callee() c2; apply { c1.apply(); c2.apply(); } } control Simple(); package Top(Simple s); Top(Caller()) main;该程序在运行时求值中会产生如图所示的层次结构。注意到
table t有两个实例。这两个实例都需要暴露给控制平面。要命名此层次结构中的对象,可以使用路径(该路径由所包含的实例的名字组成)。在本例中,这两个表的本地名字分别为s.c1.t和s.c2.t,其中s是package Top的形参名字,作为实参的Caller实例将绑定到该形参。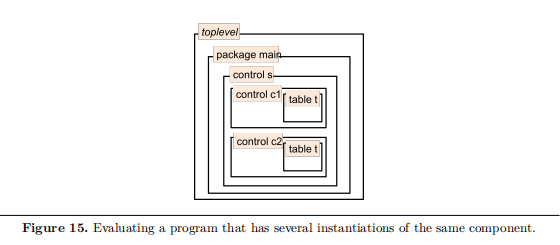
-
使用Annotations控制名字
-
@hidden annotation对控制平面隐藏一个控制实体,这是一个可控制实体不需要完全限定名字的唯一情况。
-
@name annotation可以修改可控制实体的本地名字。
并发模型
一个典型的分组处理系统需要同时执行多个逻辑“线程”,至少有一个线程执行控制平面,它可以修改table的内容。Architecture应该详细描述控制平面和数据平面之间的交互。数据平面可以通过外部函数和方法调用与控制平面交换信息。此外,高通量分组处理系统可以同时处理多个分组,例如,以流水线的形式,或者在对第二分组执行Match-Action操作的同时解析第一个分组。
当Architecture调用时,每个顶层Parser或Control模块都作为一个独立的线程执行。模块的所有参数和所有局部变量都是thread-local的,即每个线程都有这些资源的私有副本。这适用于parser和deparser的packet_in和packet_out参数。
只要P4模块只使用thread-local的存储数据(例如Metadata、Packet Header、本地变量),它在并发状态下的行为与隔离状态下的行为就是相同的,因为任何来自不同线程的语句交错都必须产生相同的输出。
相反,P4程序实例化的extern模块是全局的,在所有线程之间共享。如果extern模块访问state(例如计数器、寄存器),即extern模块对state 进行读和写操作,这些操作会受到数据竞争的影响。P4命令执行对外部实例方法的调用是原子的。可以通过@atomic annotation来指定代码块是原子执行的(将在Annotation部分说明)
Annotations(注解)
Annotations是在不改变语法的情况下将 P4 语言扩展到一定程度的简单机制。 使用 @ 语法将Annotations附加到类型、字段、变量等。 Annotations的BNF如下所示:
optAnnotations
: /* empty */
| annotations
;
annotations
: annotation
| annotations annotation
;
annotation
: '@' name // 非结构化
| '@' name '(' annotationBody ')' // 非结构化
| '@' name '[' structuredAnnotationBody ']' //结构化
;
任何一个元素上的结构化Annotations和非结构化Annotations不得使用相同的name。例如以下的例子是非法的:
@my_anno(1)
@my_anno[2] table U { /* body omitted */ }
// U上同时使用了结构化和非结构化的Annotation,并且它们的name一样
一个元素上使用的Annotations不会影响另一个元素上的Annotations,因为它们的作用域不同。比如以下的例子是合法的:
@my_anno(1) table T { /* body omitted */ }
@my_anno[2] table U { /* body omitted */ }
// @my_anno(1)作用在T上,@my_anno[2]作用在U上,二者互不影响
使用相同name的多个非结构化Annotations可以出现在同一个元素上,它们是累积的。 每个Annotations都将绑定到该元素。 比如以下的例子是合法的:
@my_anno(1)
@my_anno(2) table U { /* body omitted */ }
// 多个非结构化Annotations可以出现在同一个元素上
然而,一个元素上只能出现一个使用给定name的结构化Annotation。比如以下的例子是不合法的:
@my_anno[1]
@my_anno[2] table U { /* body omitted */ }
// 错误-同一个元素上使用了多个结构化Annotations,它们的name相同
非结构化Annotations的主体(annotationBody)
非结构化Annotations有一个可选的主体。非结构化Annotations主体可以包含任何非终结符序列,但是要保证括号是平衡的。annotationBody的BNF如下所示:
annotationBody
: /* empty */
| annotationBody '(' annotationBody ')'
| annotationBody annotationToken
其中,annotationToken 是一个非终结符,它可以表示词法分析器生成的任何终结符,包括关键字、标识符、字符串和整数字面值以及符号,但不包括括号。非结构化Annotations的例子:
@name // 只有一个名字,没有主体(非结构化的主体是可选的)
@name () // 主体是空的
@name ((1)(("2")(true))) // 可以层层嵌套,只要括号是平衡的
结构化Annotations的主体(structuredAnnotationBody)
结构化Annotations有一个强制主体,至少包含一对方括号 [ ]。与非结构化Annotations不同,结构化Annotations使用方括号 [...] 而且有严格的格式。它们通常用于声明自定义Metadeta,由表达式列表(expressionList)或键值列表(kvList)组成,但不能同时包含两者。 expressionList 可能为空或包含以逗号分隔的成员表达式(expression)列表。一个 kvList 由一个或多个 kvPairs 组成,每个 kvPairs 由一个key和一个value表达式组成。
structuredAnnotationBody 中的所有expression都必须是编译时已知值,要么是字面值,要么是需要编译时求值的表达式(求值结果类型为:字符串字面值、无限精度整数或布尔值之一)。expression不允许包含expressionList或者kvList 。在 kvList 中不能有重复的key。
structuredAnnotationBody的BNF如下:
structuredAnnotationBody
: expressionList
| kvList
;
...
expressionList
: /* empty */
| expression
| expressionList ',' expression
;
...
kvList
: kvPair
| kvList ',' kvPair
;
kvPair
: name '=' expression
;
下面举一些结构化Annotations的例子
// 主体为空
@Empty[] table t {/* body omitted */} //要注意至少要有一对[ ],结构化Annotations不能只有一个名字
// 主体是expressionList
#define TEXT_CONST "hello"
#define NUM_CONST 6
@MixedExprList[1,TEXT_CONST,true,1==2,5+NUM_CONST]
table t {/* body omitted */}
// 主体是kvList,只包含String字面值的kvList
@Labels[short="Short Label", hover="My Longer Table Label to appear in hover-help"]
table t {/* body omitted */}
// String、bool和int混合混合的kvList
@MixedKV[label="text", my_bool=true, int_val=2*3]
table t {/* body omitted */}
/*********************以下是不合法例子*******************/
// 不合法例子,kvPair和expression混合
// 结构化annotations主体要么是expressionList,要么是kvList,不能混合使用
@IllegalMixing[key=4, 5] // illegal mixing
table t {/* body omitted */}
// 不合法例子,kvList的key不能重复
@DupKey[k1=4,k1=5] table t {/* body omitted */}
// 非法例子,同一个元素上的结构化annotations的名字不能重复
@DupAnno[k1=4]
@DupAnno[k2=5]
table t {/* body omitted */}
// 非法例子,同一个元素上的结构化annotations和非结构化annotations名字不能重复
@MixAnno("Anything")
@MixAnno[k2=5]
table t {/* body omitted */}
预定义的Annotations
P4预定义了一些标准Annotations:
- @optional:可以附加在package、外部方法、外部函数或外部对象构造函数的参数前面,说明该参数是可选的,以指示用户不需要为该参数提供相应的参数值。 没有提供值的参数的含义取决于Target
- @tableonly:附加这个Annotation的action只能出现在table里面,并且不能作为default_action
- @defaultonly:附加这个Annotation的action只能出现在default_action里,不能出现在table里
table t {
actions = {
a, // 可以出现在任何位置
@tableonly b, // 只能出现在table里
@defaultonly c, // 只能出现在default action里
}
/* body omitted */
}
-
@name:修改可控制实体的本地名字。它可以为可控制实体的本地名称指定一个别名,指示编译器在为可控制实体生成完全限定名时,使用该别名作为本地名称。 在以下示例中,table的完全限定名称是 c_inst.t1,原本应该是c_inst.t,但是@name指定了一个别名“t1”作为本地名称,所以完全限定名称应该为 c_inst.t1。
control c( /* parameters omitted */ )() { @name("t1") table t { /* body omitted */ } apply { /* body omitted */ } } c() c_inst; -
@hidden:对控制平面隐藏一个可控制实体,例如,
table、key、action或者extern。附加 @hidden Annotation的可控制实体没有完全限定名称。 每个元素最多可以使用一个@name 或@hidden Annotation,并且每个控制平面完全限定名最多指向一个可控实体。 如果一个类型被实例化不止一次,并且该类型带有一个包含绝对路径名的@name Annotation,将导致一个完全限定名称指向两个可控实体,这是不合法的:control noargs(); package top(noargs c1, noargs c2); control c() { @name(".foo.bar") table t { /* body omitted */ } apply { /* body omitted */ } } top(c(), c()) main;在上例中,如果没有@name Annotation,程序会产生两个可控制实体,完全限定名分别为
main.c1.t和main.c2.t。但是@name(".foo.bar") Annotation将两个实例的本地名称都重命名为.foo.bar,就导致一个完全限定名称指向两个可控实体,这是不合法的。 -
@atomic:指定某个代码块是原子执行的,可以应用于块语句、Parser 状态、控制模块或者着整个Parser:
extern Register { /* body omitted */ } control Ingress() { Register() r; table flowlet { /* read state of r in an action */ } table new_flowlet { /* write state of r in an action */ } apply { @atomic { flowlet.apply(); if (ingress_metadata.flow_ipg > FLOWLET_INACTIVE_TIMEOUT) new_flowlet.apply(); }}}该程序在table
flowlet(读取)和new_flowlet(写入)所调用的actions中访问类型为Register的外部对象r。 如果没有@atomic Annotation,这两个操作将不会以原子方式执行,即第二个分组可能会在第一个分组有更新它之前读取r的状态。注意,在action定义中,如果action执行诸如读寄存器、修改寄存器值并将其写回之类的操作,则下一个分组应该只看到修改后的值。为了保证在所有情况下都正确执行,动作定义的那部分应该封装在一个@atomic Annotation的代码块中。
如果编译器后端无法实现指令序列的原子执行,则它必须拒绝包含@atomic 块的程序。 在这种情况下,编译器应该提供合理的诊断。
-
@pure:描述一个函数,它只依赖于它的
in参数值,除了返回一个值之外没有任何影响,并在其out和inout参数上复制输出行为。函数调用之间没有记录隐藏状态,返回值不依赖于任何可能被其他调用更改的隐藏状态。比如计算其参数的确定性散列的hash函数,其返回值不依赖于任何控制平面可写的参数或初始化向量值。可以安全地消除一个返回值未被使用的@pure 函数而不会产生任何不利影响,并且可以将具有相同参数的多个调用合并为一个调用。 -
@noSideEffects:比 @pure 弱,描述了一个不改变任何隐藏状态但可能依赖于隐藏状态的函数。比如读取外部寄存器数组对象的一个元素。这样的函数可能会被当做无用代码删除,并且可能会被重新排序或与其他@noSideEffects 或 @pure 调用组合,但不能与其他可能具有副作用的函数调用组合。
-
@deprecated:@deprecated annotation 有一个必需的字符串参数,作为一条提示消息。当程序使用已弃用的结构时,编译器将打印该消息。 例如:
// checker已经被弃用(被check替代),如果程序使用该外部对象, //编译器将会提示"Please use the 'check' function instead" @deprecated("Please use the 'check' function instead") extern Checker { /* body omitted */ } -
@noWarn:@noWarn annotation有一个必需的字符串参数,指示一个编译器警告。编译器将被禁止发出该警告。 例如,在一个声明上附加@noWarn("unused") ,尽管该声明未被使用,编译器也不会发出警告,因为该声明未使用的警告被禁止了。
代码附录
1. VSS Architecture的声明
very_simple_switch_model.p4
// File "very_simple_switch_model.p4"
// Very Simple Switch P4 declaration
// core library needed for packet_in and packet_out definitions
# include <core.p4>
/* Various constants and structure declarations */
/* ports are represented using 4-bit values */
typedef bit<4> PortId;
/* only 8 ports are "real" */
const PortId REAL_PORT_COUNT = 4w8; // 4w8 is the number 8 in 4 bits
/* metadata accompanying an input packet */
struct InControl {
PortId inputPort;
}
/* special input port values */
const PortId RECIRCULATE_IN_PORT = 0xD;
const PortId CPU_IN_PORT = 0xE;
/* metadata that must be computed for outgoing packets */
struct OutControl {
PortId outputPort;
}
/* special output port values for outgoing packet */
const PortId DROP_PORT = 0xF;
const PortId CPU_OUT_PORT = 0xE;
const PortId RECIRCULATE_OUT_PORT = 0xD;
/* Prototypes for all programmable blocks */
/*** Programmable parser.
* @param <H> type of headers; defined by user
* @param b input packet
* @param parsedHeaders headers constructed by parser
*/
parser Parser<H>(packet_in b,
out H parsedHeaders);
/*** Match-action pipeline
* @param <H> type of input and output headers
* @param headers headers received from the parser and sent to the deparser
* @param parseError error that may have surfaced during parsing
* @param inCtrl information from architecture, accompanying input packet
* @param outCtrl information for architecture, accompanying output packet
*/
control Pipe<H>(inout H headers,
in error parseError,// parser error
in InControl inCtrl,// input port
out OutControl outCtrl); // output port
/*** VSS deparser.
* @param <H> type of headers; defined by user
* @param b output packet
* @param outputHeaders headers for output packet
*/
control Deparser<H>(inout H outputHeaders,
packet_out b);
/*** Top-level package declaration - must be instantiated by user.
* The arguments to the package indicate blocks that
* must be instantiated by the user.
* @param <H> user-defined type of the headers processed.
*/
package VSS<H>(Parser<H> p,
Pipe<H> map,
Deparser<H> d);
// Architecture-specific objects that can be instantiated
// Checksum unit
extern Checksum16 {
Checksum16(); // constructor
void clear(); // prepare unit for computation
void update<T>(in T data); // add data to checksum
void remove<T>(in T data); // remove data from existing checksum
bit<16> get(); // get the checksum for the data added since last clear
}
2. 完整的 VSS 代码
complete VSS program
// Include P4 core library
# include <core.p4>
// Include very simple switch architecture declarations
# include "very_simple_switch_model.p4"
// This program processes packets comprising an Ethernet and an IPv4
// header, and it forwards packets using the destination IP address
typedef bit<48> EthernetAddress;
typedef bit<32> IPv4Address;
// Standard Ethernet header
header Ethernet_h {
EthernetAddress dstAddr;
EthernetAddress srcAddr;
bit<16> etherType;
}
// IPv4 header (without options)
header IPv4_h {
bit<4> version;
bit<4> ihl;
bit<8> diffserv;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
IPv4Address srcAddr;
IPv4Address dstAddr;
}
// Structure of parsed headers
struct Parsed_packet {
Ethernet_h ethernet;
IPv4_h ip;
}
// User-defined errors that may be signaled during parsing
error {
IPv4OptionsNotSupported,
IPv4IncorrectVersion,
IPv4ChecksumError
}
// Parser section
parser TopParser(packet_in b, out Parsed_packet p) {
Checksum16() ck; // instantiate checksum unit
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
0x0800: parse_ipv4;
// no default rule: all other packets rejected
}
}
state parse_ipv4 {
b.extract(p.ip);
verify(p.ip.version == 4w4, error.IPv4IncorrectVersion);
verify(p.ip.ihl == 4w5, error.IPv4OptionsNotSupported);
ck.clear();
ck.update(p.ip);
// Verify that packet checksum is zero
verify(ck.get() == 16w0, error.IPv4ChecksumError);
transition accept;
}
}
// Match-action pipeline section
control TopPipe(inout Parsed_packet headers,
in error parseError, // parser error
in InControl inCtrl, // input port
out OutControl outCtrl) {
IPv4Address nextHop; // local variable
/*** Indicates that a packet is dropped by setting the
* output port to the DROP_PORT
*/
action Drop_action() {
outCtrl.outputPort = DROP_PORT;
}
/*** Set the next hop and the output port.
* Decrements ipv4 ttl field.
* @param ivp4_dest ipv4 address of next hop
* @param port output port
*/
action Set_nhop(IPv4Address ipv4_dest, PortId port) {
nextHop = ipv4_dest;
headers.ip.ttl = headers.ip.ttl - 1;
outCtrl.outputPort = port;
}
/*** Computes address of next IPv4 hop and output port
* based on the IPv4 destination of the current packet.
* Decrements packet IPv4 TTL.
* @param nextHop IPv4 address of next hop
*/
table ipv4_match {
key = { headers.ip.dstAddr: lpm; } // longest-prefix match
actions = {
Drop_action;
Set_nhop;
}
size = 1024;
default_action = Drop_action;
}
/*** Send the packet to the CPU port
*/
action Send_to_cpu() {
outCtrl.outputPort = CPU_OUT_PORT;
}
/*** Check packet TTL and send to CPU if expired.
*/
table check_ttl {
key = { headers.ip.ttl: exact; }
actions = {
Send_to_cpu;
NoAction;
}
const default_action = NoAction; // defined in core.p4
}
/*** Set the destination MAC address of the packet
* @param dmac destination MAC address.
*/
action Set_dmac(EthernetAddress dmac) {
headers.ethernet.dstAddr = dmac;
}
/*** Set the destination Ethernet address of the packet
* based on the next hop IP address.
* @param nextHop IPv4 address of next hop.
*/
table dmac {
key = { nextHop: exact; }
actions = {
Drop_action;
Set_dmac;
}
size = 1024;
default_action = Drop_action;
}
/*** Set the source MAC address.
* @param smac: source MAC address to use
*/
action Set_smac(EthernetAddress smac) {
headers.ethernet.srcAddr = smac;
}
/*** Set the source mac address based on the output port.
*/
table smac {
key = { outCtrl.outputPort: exact; }
actions = {
Drop_action;
Set_smac;
}
size = 16;
default_action = Drop_action;
}
apply {
if (parseError != error.NoError) {
Drop_action(); // invoke drop directly
return;
}
ipv4_match.apply(); // Match result will go into nextHop
if (outCtrl.outputPort == DROP_PORT)
return;
check_ttl.apply();
if (outCtrl.outputPort == CPU_OUT_PORT)
return;
dmac.apply();
if (outCtrl.outputPort == DROP_PORT)
return;
smac.apply();
}
}
// deparser section
control TopDeparser(inout Parsed_packet p, packet_out b) {
Checksum16() ck;
apply {
b.emit(p.ethernet);
if (p.ip.isValid()) {
ck.clear(); // prepare checksum unit
p.ip.hdrChecksum = 16w0; // clear checksum
ck.update(p.ip); // compute new checksum.
p.ip.hdrChecksum = ck.get();
}
b.emit(p.ip);
}
}
// Instantiate the top-level VSS package
VSS(TopParser(),
TopPipe(),
TopDeparser()) main;
References
2、P4语言的特性、P4语言和P4交换机的工作原理和流程简介
Written By: Jackin Hu
Latest Update: July 9, 2021

 浙公网安备 33010602011771号
浙公网安备 33010602011771号