个人项目_查重
| 软件工程 | 19网工34班 |
|---|---|
| 作业要求: 1.在Github仓库中新建一个学号为名的文件夹 2.在开始实现程序之前,在PSP表格记录下在程序开发各个步骤耗费时间,实现程序后,在PSP表格记录各个模块上实际花费时间 3.语言不限,实现程序后将代码发布到Github仓库的realease中 4.提交的代码要求经过Code Quality Analysis工具分析并消除所有警告 5.完成项目首个版本之后,使用性能分析工具StudioProfiling Tools找出代码性能瓶颈 6.使用Github来管理源代码和测试用例,代码有进展即签入Github 7.使用单元测试对项目进行测试,并使用插件查看测试分支覆盖率等指标 |
作业要求链接 |
GitHub链接
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 960 | 1180 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 400 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 250 | 200 |
| · Coding | · 具体编码 | 200 | 200 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 960 | 1180 |
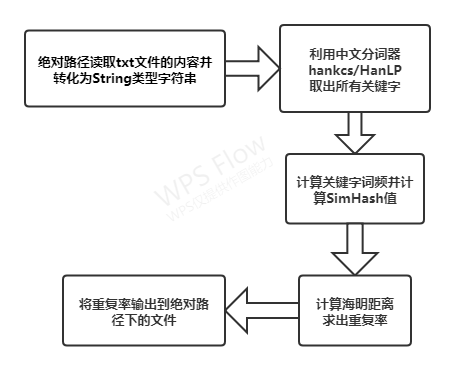
二、整体流程
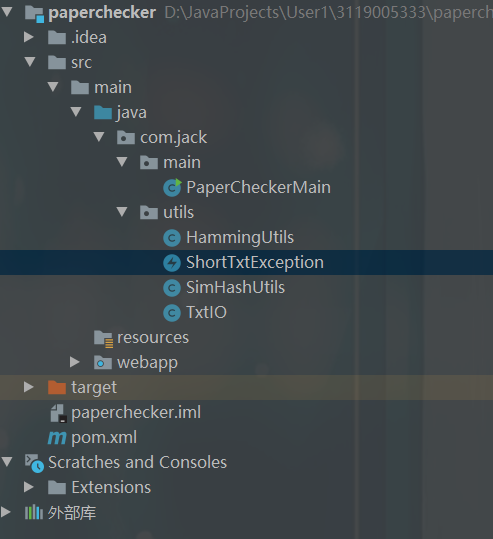
类
PaperCheckerMain:main 方法所在的类
HammingUtils:计算海明距离的工具类
SimHashUtils:计算 SimHash 值的工具类
TxtIO:读写 txt 文件的类
ShortTxtException:处理短文本的异常类
核心算法
simhash+海明距离
具体可参考:
通过查阅资料,得到论文查重可以运用simhash和海明距离来判断,得到学习路径博客。使用simhash以及海明距离判断内容相似程度
要把文章变为数字计算才能提高相似度计算性能。中文分词器hankcs/HanLP.github
三、接口的设计和实现
读写 txt 文件的模块
类:TxtIO
包含了两个静态方法:
1、readTxt:读取txt文件
2、writeTxt:写入txt文件
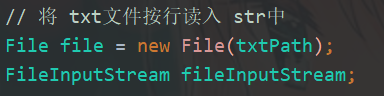
实现:都是调用 Java.io 包提供的接口。
SimHash 模块(核心模块)
类:SimHashUtils
包含了两个静态方法:
1、getHash:传入String,计算出它的hash值,并以字符串形式输出,(使用了MD5获得hash值)
2、getSimHash:传入String,计算出它的simHash值,并以字符串形式输出,(需要调用 getHash 方法)
getSimHash 是核心算法,主要流程如下:
1、分词(使用了外部依赖 hankcs 包提供的接口)

2、获取 hash 值
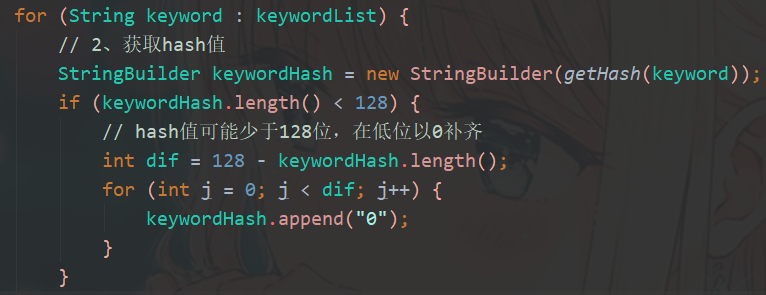
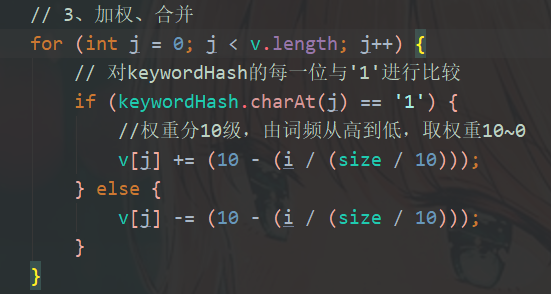
3、加权、合并
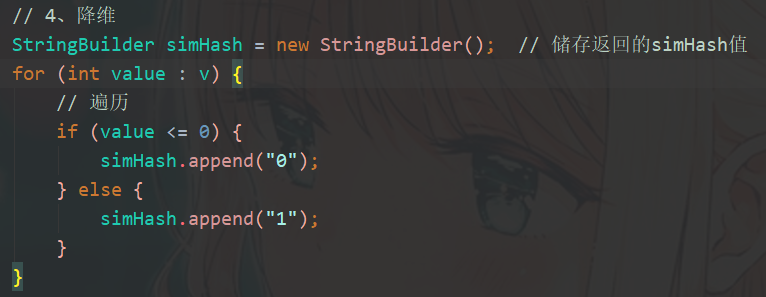
4、降维
海明距离模块
类:HammingUtils
包含了两个静态方法:
1、getHammingDistance:输入两个 simHash 值,计算出它们的海明距离 distance
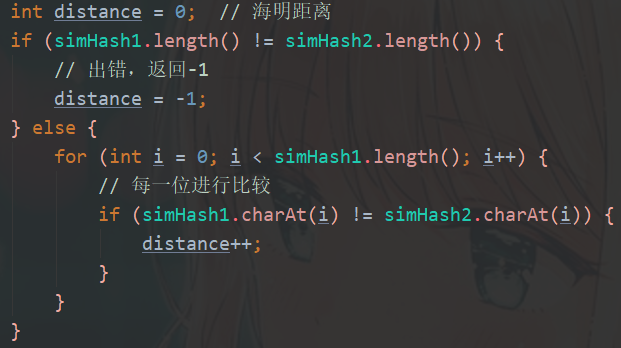
2、getSimilarity:输入两个 simHash 值,调用 getHammingDistance 方法得出海明距离 distance,在由 distance 计算出相似度。

main 主模块

四、性能分析
Overview
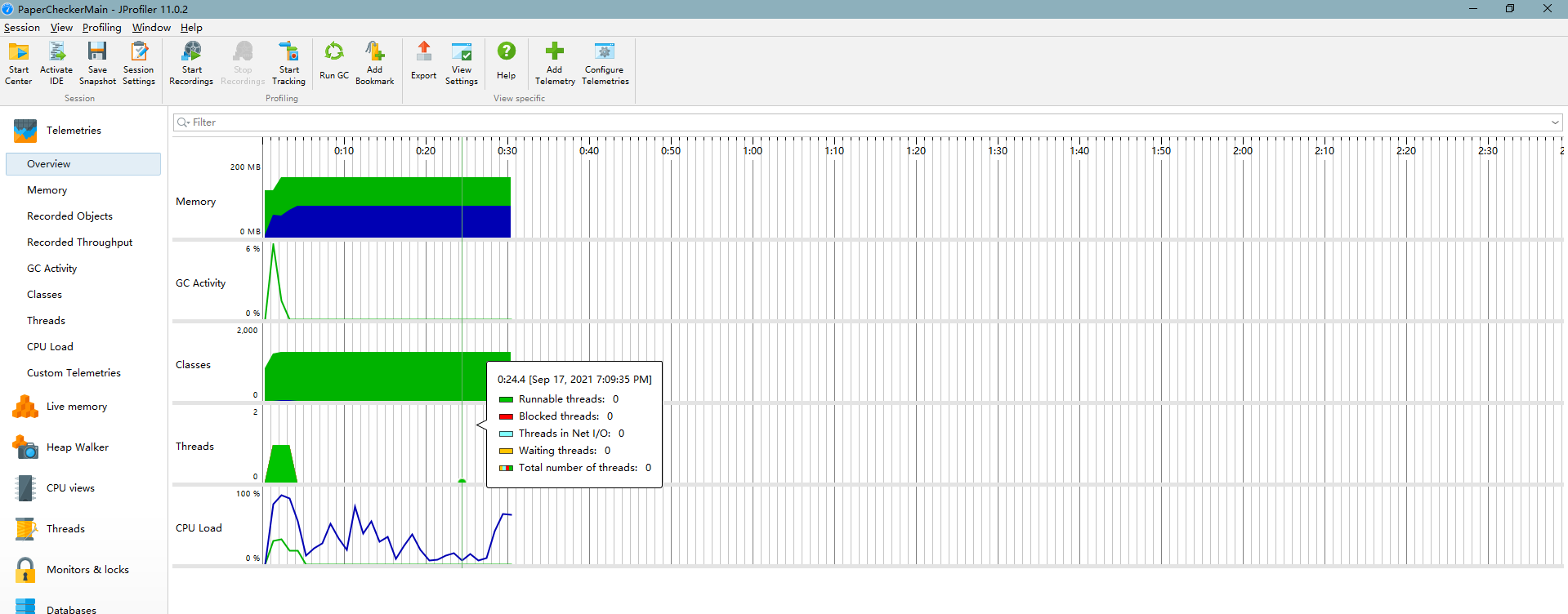
方法调用情况
首次测试
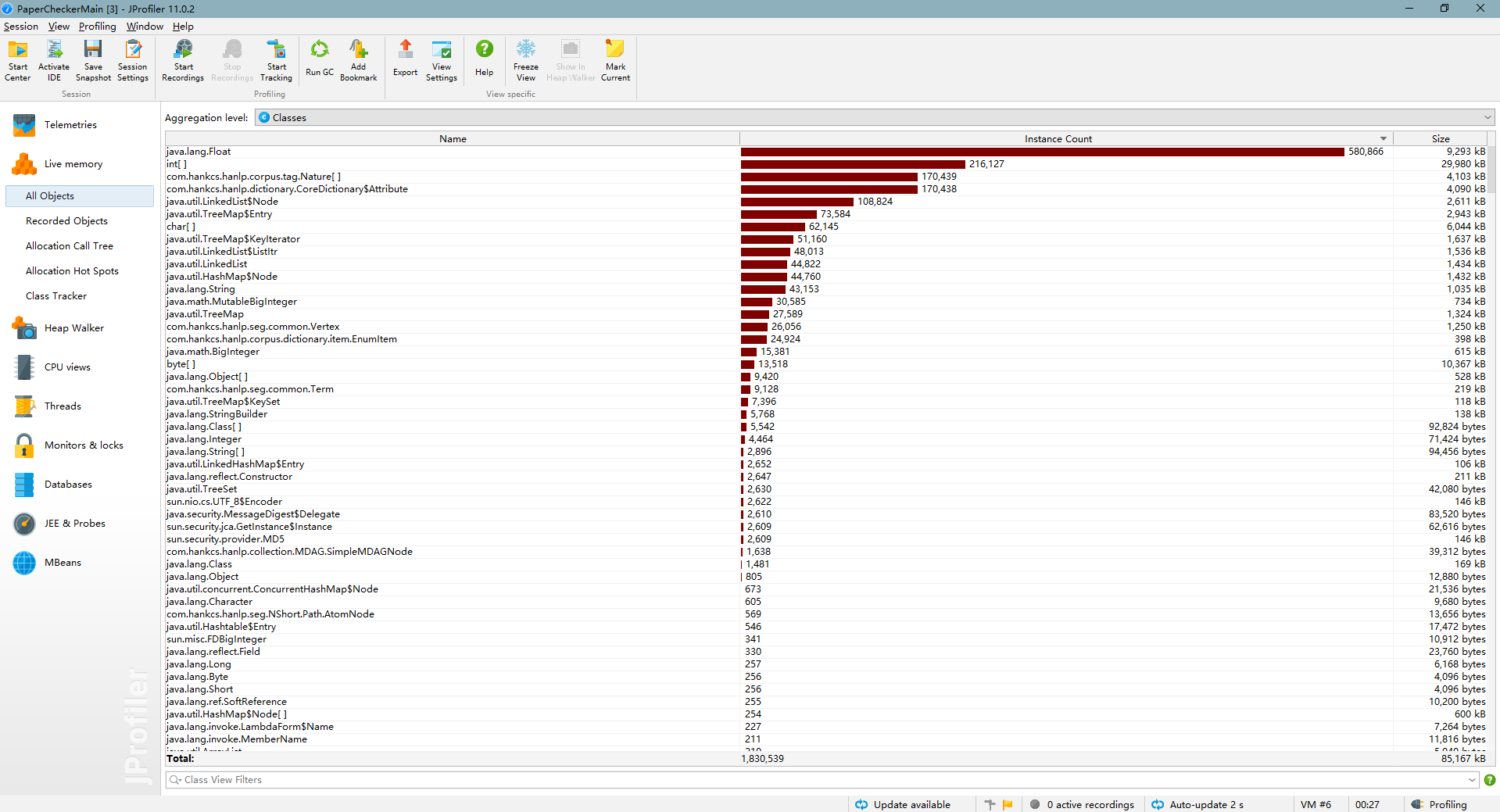
明显看到float占用运算太多,修改一下算法,用int代替
修改后测试
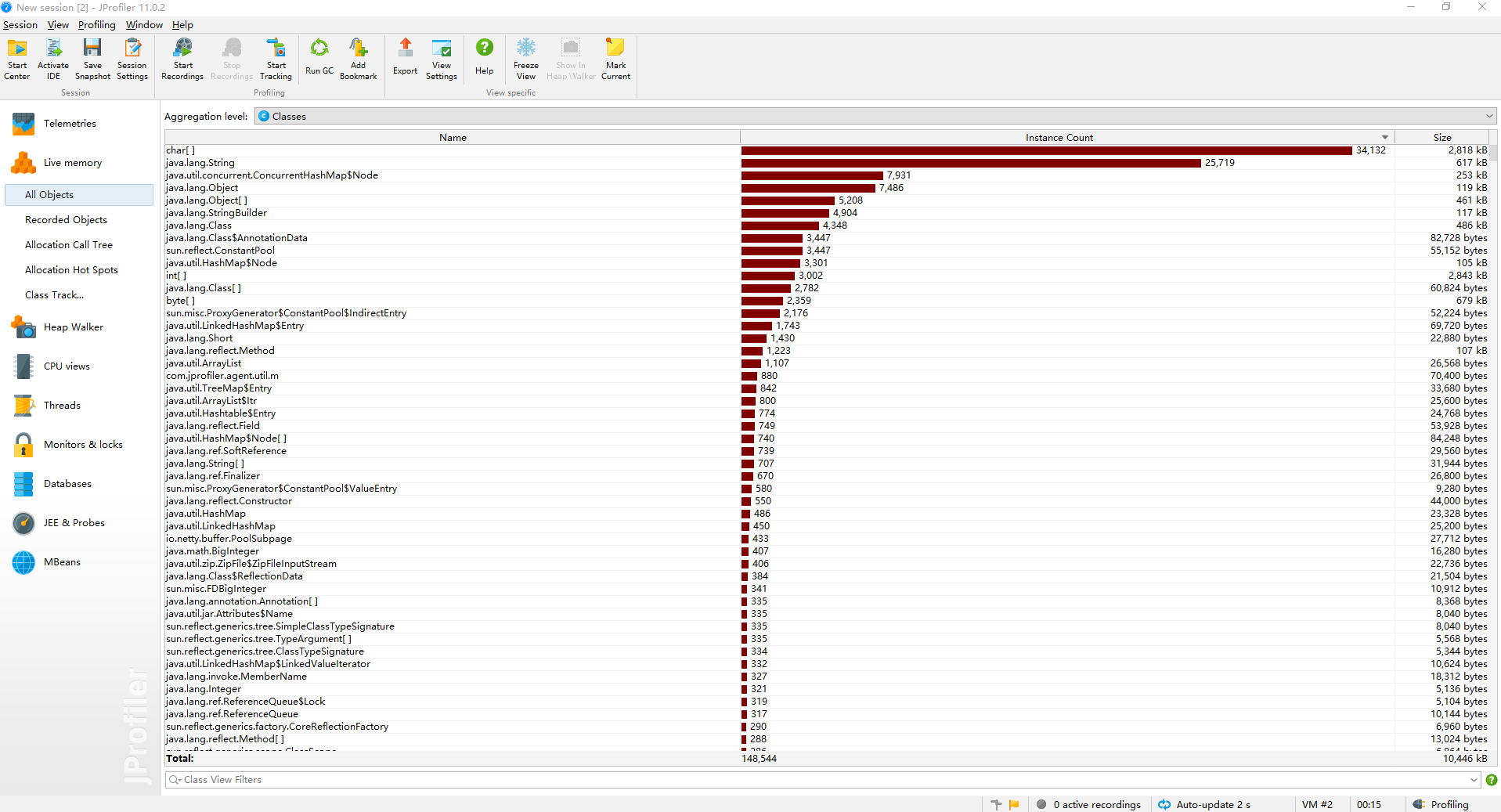
修改后性能上基本没有需要提升的
五、测试

在IDEA上即可传参:
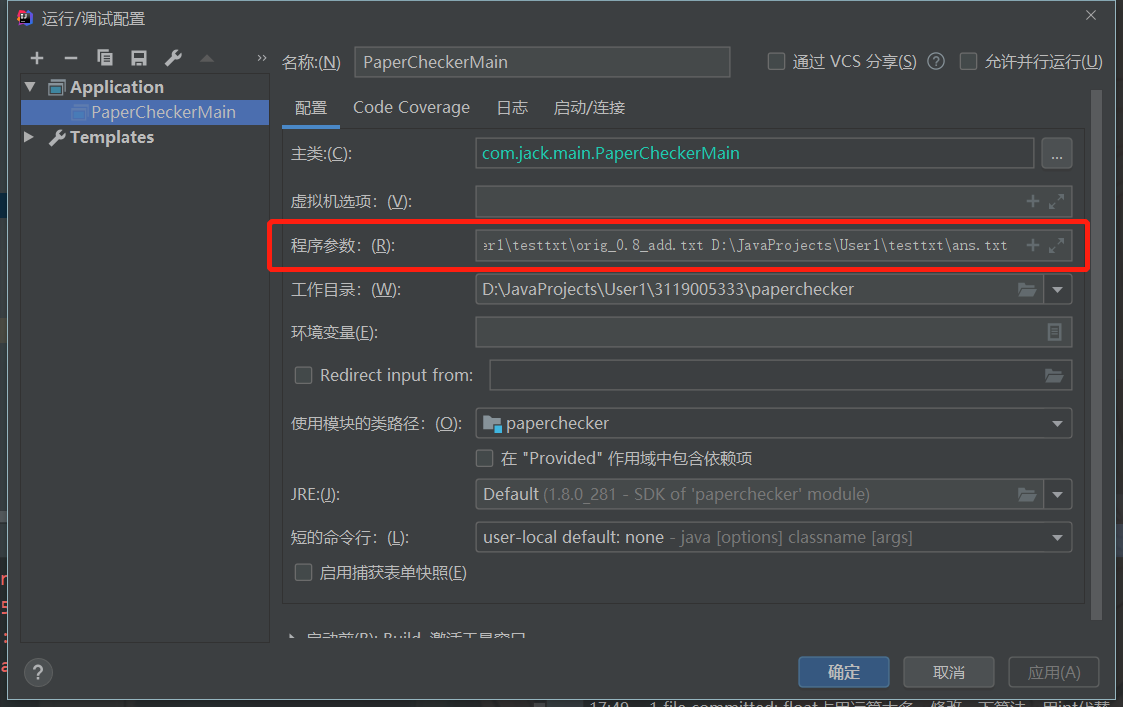
正常文本测试:
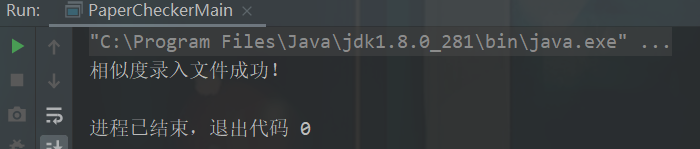
短文本测试:
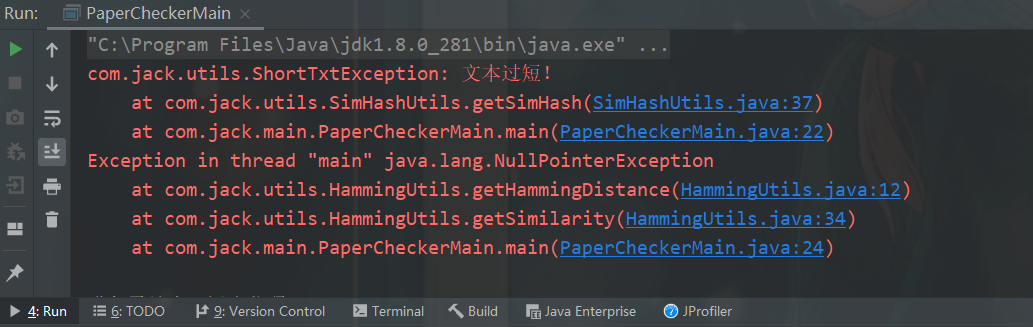
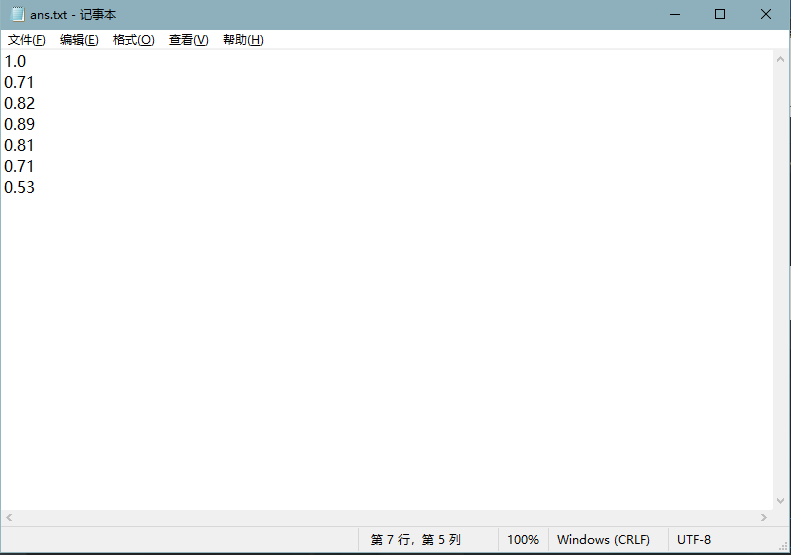
结果输出文件:

总结
在命令行传参总是编译不成功,后来才直接在IDEA里面传参,也挺方便的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号