
mysql
MySQL(一)
1、命令行连接
mysql -uroot -p123456 --连接数据库
flush privileges;--刷新权限
mysql中“--”表示表示注释 ,多行注释使用“-**-”。其所有的语句使用‘;’结尾
show databases; --查看所有的数据库
mysql> use school --切换数据库 use 数据库名
Database changed
show tables; -- 查看数据库中所有的表
describe student; --显示数据库中所有的表的信息
create database westos;--创建一个数据库
exit;--退出连接
数据库xxx语言 CRUD 增删改查
DDL 定义
DML 操作
DQL 查询
DCL 控制
2、操作数据库
操作数据库>操作数据库中的表>操作数据库中表的数据
mysql关键字不区分大小写
2.1、操作数据库(了解)
1.创建数据库
CREATE DATABASES [IF NOT EXISTS] westos;--大括号必选 中括号可选
2.删除数据库
DROP DATABASE [IF EXIT] westos;
3.使用数据库
--如果数据库是关键字,那就把数据库加一个飘``(tab键上面的字符)
USE school;
4.查看数据库
SHOW DATABASES --查看所有的数据库
学习思路:
- 对照sqlyog可视化历史记录查看sql
- 固定的语法或关键字必须要强行记住
2.2、数据库的列类型
数值
- tinyint 十分小的数据 1个字节
- smallint 较小的数据 2个字节
- mediumint 中等大小的数据 3个字节
- int 标准的整数 4个字节 (常用)
- bigint 较大的数据 8个字节
- float 浮点数 4个字节
- double 浮点数 8个字节(精度问题)
- decimal 字符串形式的浮点数 金融计算一般是使用decimal
字符串
- char 字符串固定大小 0~255
- varchar 可变字符串 0~65535 常用的string
- tinytext 微型文本 2^8-1
- text 文本串 2^16-1 保存大文本
时间日期
- data YYYY-MM-DD 日期
- time HH;mm;ss 时间格式
- datatime YYYY-MM-DD HH;mm;ss 最常用的时间格式
- timestamp 时间戳 1970.1.1到现在的毫秒数!也较为常用!
- year 年份表示
null
- 没有值,未知
- --注意,使用NULL进行运算,结果为NULL(不要使用,不是不能使用)
2.3、数据库的字段属性(重点)
unsigned
- 无符号的整数
- 声明了该列不能声明为负数,否则报错
zerofill
- 0填充
- 不足的位数,使用0来填充,int(3),5 ---005
自增
- 通常连理解为自增,自动在上一条记录的基础上+1(默认)
- 通常用来设计唯一的主键~index,必须是整数类型
- 可以自定义设计主键自增的起始值和步长
非空 NULL not null
- 假设设置为 not null,如果不给赋值,就会报错!
- NULL,如果不填写值,默认就是null!
默认
- 设置默认的值!
- 例如,sex,默认为男,如果不指定该列的值,则会有默认的值!
每一个表,都必须存在以下五个字段!未来做项目用的表示一个记录存在的意义
- id 主键
- version 乐观锁
- is_delete 伪删除
- gmt_create 创建时间
- gmt_update 修改时间
2.4、创建数据库表(重点)
-- 学号int 登录密码varchar(20),姓名,性别varchar(2),出生日期(datetime)。家庭住址,emali
-- 注意点,使用英文(),表的名称和字段尽量使用``括起来
-- AUTO_INCREMENT 自增
-- 字符串使用单引号括起来!
-- 所有的语句加,(英文的,),最后一个不用加
-- PRIMARY KEY 主键,一般一个表只有一个唯一的主键
CREATE TABLE IF NOT EXISTS `student`(
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名' ,
`pwd` VARCHAR (20) NOT NULL DEFAULT '`student`123456' COMMENT '密码',
`sex` VARCHAR (2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭地址',
`email` VARCHAR (60) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
格式:
CREATE TABLE [IF NOT EXISTS] `表名`(
`字段名` 列表型 [属性] [索引] [注释],
`字段名` 列表型 [属性] [索引] [注释],
......
`字段名` 列表型 [属性] [索引] [注释]
)[表类型] [字符集设置] [注释]
常用命令
SHOW CREATE DATABASES school --查看是黄建数据库的语句
SHOW CREATE TABLE student --查看student数据库的定义语句
DESC student --显示表的结构
2.5、数据库的类型
INNODB 默认使用~
MYISAM 早些年使用
| MYISAM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约为2倍 |
常规使用操作
- MYISAM 节约空间,速度较快
- INNODB 安全性高,实物的处理,多表多用户操作
在物理空间存在的位置
所有的数据文件都粗在data目录下,一个文件夹就对应一个数据库
本质还是文件的存储!
MySQL引擎在物理文件夹的区别:
- INNODB在数据库表中只有一个*.frm文件,以及上级目录下的 ibdata1 文件
- MYISAM对应文件
- *.frm 表结构的定义文件
- *.MYD 数据文件(data)
- *.MYI 索引文件(index)
设置数据库的字符集编码
- CHARSET=utf8
MySQL默认编码是 Latin1,不支持中文
在my.ini中配置默认的编码- character-set-serve=utf8
2.6、修改删除表
修改
-- 修改表名: ALTER TABLE 旧表名 RENAME AS 新表名
ALTER TABLE student RENAME AS stu
-- 增加表的字段: ALTER TABLE 表名 ADD 字段名 INT(11)
ALTER TABLE stu ADD birthday INT(11)
-- 修改标的字段(重命名,修改约束!)
-- change用来字段重命名,不能修改字段类型和约束
-- modify不能用来字段重命名,只能修改字段类型和约束
-- ALTER TABL 表名 MODIFY 字段名 列属性[]
ALTER TABLE stu MODIFY age VARCHAR(11) -- 修改约束
-- ALTER TABLE 旧表名 CHANGE 新表名 列属性[]
ALTER TABLE stu CHANGE age age1 INT(1) -- 字段重命名
-- 删除表的字段:ALTER TABLE 表名 DROP 字段名
ALTER TABLE stu DROP age1
删除
-- 删除表(如果表存在)
DROP TABLE IF EXISTS stu
所有的创建和删除操作尽量加上判断,以免报错
注意点:
- ``字段名使用这个符号包裹!
- 注释/* */
- sql关键字大小写不敏感,建议用小写
- 所有的符号全部用英文
3、MySQL数据管理
3.1、外键(了解即可)
3.2、DML语言(全部记住)
数据库意义:数据存储,数据管理
DML语言:数据操作语言
- insert
- update
- delete
3.3、添加
insert
-- 插入语句(添加)
-- insert into 表名([字段名1,字段2,字段3])values(‘值1’),(‘值2’),(‘值3’)
INSERT INTO `student`
VALUES ('2','小明','123','男','2021-08-16 16:33:37','河南','email')
-- 一般写插入语句,我们一定要数据和字段一一对应!
语法:insert into 表名([字段名1,字段2,字段3])values(‘值1’),(‘值2’),(‘值3’)
注意事项:
- 字段和字段之间使用英文逗号隔开
- 字段是可以省略的,但是后面的值必须一一对应,不能少
- 可以同时插入多条数据VALUES后面的值们需要使用,隔开即可VALUES()|()
3.4、修改
修改
-- 修改学员名字:
UPDATE `student` SET `name`= '长江七号' WHERE id = 1 ;
-- 不指定条件的情况下,会改动所有表
UPDATE `student` SET `name`= '长江七号'
语法:UPDATE 表名 SET colnum_name= value,[colnum_name= value,..] WHERE [条件] ;
条件:where 子句 运算符 id等于某个值,大于某个值,在某个区间修改
--通过多个条件定位数据
UPDATE `student` SET `name`= '狂神',`email`='123@qqcom' WHERE 'name' = '我是超人' AND 'sex'='男' ;
| 操作符 | 含义 | 范围 | 结果 |
|---|---|---|---|
| = | 等于 | 5=6 | false |
| <> 或!= | 不等于 | 5<>6 | true |
| > | 大于 | 1>2 | false |
| < | 小于 | 1<2 | true |
| <= | 小于等于 | 2<=2 | true |
| >= | 大于等于 | 2>= 2 | true |
| BRTWEEN .. AND.. | 在某个范围内 | [2,5] | |
| AND | 我和你&& | 5>1 and 1>2 | false |
| OR | 我或你 | 5>1 or 1>2 | true |
注意
- colnum_name 是数据库的列,尽量带上``
- 条件,筛选的条件,如果没有指定,则会修改所有的列
- value,是一个具体的值,也可以是一个变量
- Data truncated for column 'birthday' at row 1 ;
- 多个设置的属性之间,使用英文逗号隔开
3.5、删除
delete 命令
==语法:delete from 表名 [where 条件] ==
--删除数据(避免这样写,会全部删除)
DELETE FROM `student`
-- 删除指定数据
DELETE FROM `student` WHERE id =1 ;
TRUNCATE 命令
语法:TRUNCATE [表名]
作用:完全清空一个数据库表,表的结构和索引约束不会变!
delete和TRUNCATE 区别
- 相同点:都能删除数据,都不会删除表结构
- 不同
- TRUNCATE重新设置自增列 计数器归零
- TRUNCATE 不会影响事务
了解即可:delete删除的问题,重启数据库,现象
- innodb 自增列会从1开始(存在内存中的,断点即失)
- myisam 继续会从上一个自增量开始(存在文档中,不会丢失)
4、DQL查询数据(最重点)
4.1、DQL
(Data Query Language:数据查询语言)
- 所有的查询操作都用select
- 简单/复杂的查询它都可以~
- 数据库中最核心的语言,最重要的语言
- 使用频率最高的语句
4.2、指定查询字段
-- 查询全部的学号是哪个 select 字段 from 表
SELECT * FROM student
-- 查询指定字段
SELECT `studentno`,`studentname` FROM student
-- 别名:给结果起一个名字 AS 可以个字段/表起别名
SELECT `studentno` AS 学号,`studentname` AS 学生姓名 FROM student AS s
-- 函数 拼接字符串 concat(a,b)
SELECT CONCAT ('姓名:',studentname) AS 新名字 FROM student
语法:SELECT 字段... FORM 表
有时候,列名字不是那么的见名知意。我们起别名 AS 字段名 as 别名
去重 distinct
作用:去除select查询出来的结果中重复的数据,重复的数据只显示一条
-- 查询一下哪个同学参加了考试,成绩
SELECT `studentno` FROM result
-- 发现重复数据,去重
SELECT DISTINCT `studentno` FROM result
数据库的列(表达式)
-- 查询系统版本(函数)
SELECT VERSION()
-- 用来计算(计算表达式)
SELECT CONCAT('计算结果=',100-99) AS 结果
-- 查询自增的步长(变量)
SELECT @@auto_increment_increment
SELECT CURRENT_TIME
-- 学员考试成绩 +1分 查看
SELECT `studentno`,`studentresult` +1 AS '提分后' FROM result
数据库中的表达式:文本值,列,NULL,函数,计算表达式,系统变量...
select 表达式 from 表
4.3、where条件子句
作用:检索操作中符合条件的值
逻辑运算符
尽量使用英文字母
搜索的条件由一个或者多个表达式组成!结果 布尔值
-- 查询考试成绩在66~99之间的
SELECT studentno,`studentresult` FROM result
WHERE studentresult>=66 AND studentresult<=99
-- 模糊查询(区间)
SELECT studentno,`studentresult` FROM result
WHERE studentresult BETWEEN 66 AND 99
-- 除了1000号学生之外同学的成绩
SELECT studentno,`studentresult` FROM result
WHERE studentno<>1000
模糊查询:比较运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为NULL,结果为真 |
| IS NOT NULL | a is not null | 如果操作符不为null,结果为真 |
| BETWEEN | a between a and b | 若a 在 b 和 c 之间,则结果为真 |
| LIKE | a like b | sql匹配 ,如果a匹配b,则结果为真 |
| IN | a in (a1,a2..) | 假设a在a1或者a2...其中某一个值,结果为真 |
-- ========模糊查询=======
-- ====like====
-- 查询姓张的同学
-- like结合 %(代表0到任意个字符) _一个字符
SELECT `studentno`,`studentname` FROM student
WHERE studentname LIKE '张%'
-- 查询姓张的同学,名字后面只有一个字的
SELECT `studentno`,`studentname` FROM student
WHERE studentname LIKE '张_'
-- 查询姓张的同学,名字后面只有两个字的
SELECT `studentno`,`studentname` FROM student
WHERE studentname LIKE '张__'
-- 查询名字中间有 强 字的同学:%强%
SELECT `studentno`,`studentname` FROM student
WHERE studentname LIKE '%强%'
-- ======in(具体的一个或者多个值)=====
SELECT `studentno`,`studentname` FROM student
WHERE `address` IN('北京朝阳')
-- ====null not null====
SELECT `studentno`,`studentname` FROM student
WHERE address='' OR address IS NULL
-- 查询出生日期不为空的学生
SELECT `studentno`,`studentname` FROM student
WHERE `borndate` IS NOT NULL
4.4\联表查询
七种JOIN理论
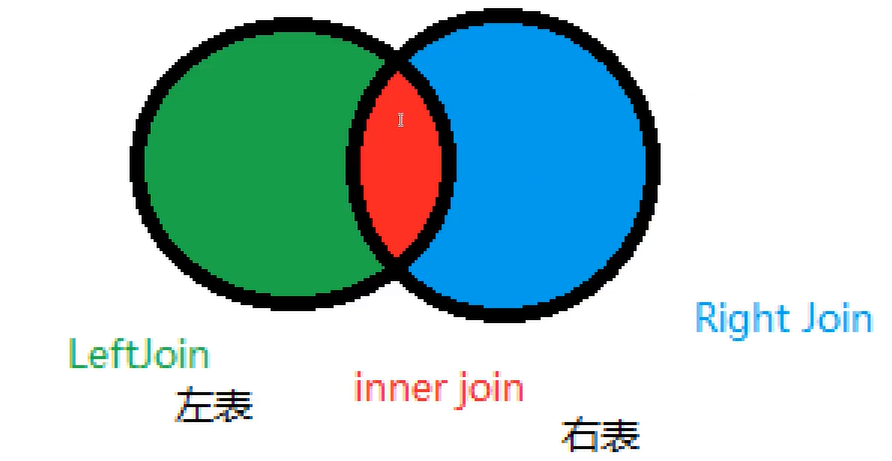
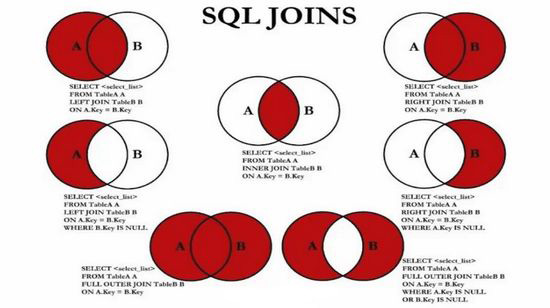
-- =====联表查询 join =====
-- 查询参加了考试同学(学号,姓名,科目编号,分数)
/*思路
1.分析需求,分析查询的字段都来自那些表,(联接查询)
2.确定使用那些联接查询?7中
确定交叉点(这啷个表哪些数据是相同的,没有交叉数据就无法查询)
判断的条件:学生表中的 `studentno`= 成绩表中的 `studentno`
*/
SELECT s.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student AS s
INNER JOIN result AS r
ON s.`studentno` = r.`studentno`
-- right join
SELECT r.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student s
RIGHT JOIN result r
ON s.`studentno`=r.`studentno`
-- left join
SELECT r.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student s
LEFT JOIN result r
ON s.`studentno`=r.`studentno`
-- 查询缺考的同学
SELECT r.`studentno`,`studentname`,`subjectno`,`studentresult`
FROM student s
LEFT JOIN result r
ON s.`studentno`=r.`studentno`
WHERE `studentresult` IS NULL
-- join (联接的表) on(条件判断) 连接查询
-- join where 等值查询
-- 思路题目:查询参加考试的同学信息(学号,学生姓名,科目名,分数)
/*思路:
1.分析需求:student(学号,学生姓名)subject(科目名)result(分数)
2.找出3张表交叉点 res(`studentno`)=stu(`studentno`)、res(`subjectno`)=sub(`subjectno`)
3.开始逐一慢慢连接
*/
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult`
FROM student s
RIGHT JOIN result r
ON s.`studentno`=r.`subjectno`
INNER JOIN `subject` sub
ON r.`studentno`=sub.`subjectno`
自连接(了解)
自己的表和自己的表连接,核心:一张表拆为两张一样的表即可
父类
| category | categoryName |
|---|---|
| 2 | 信息技术 |
| 3 | 软件开发 |
| 5 | 美术设计 |
| 子类 | |
| pid | categoryid |
| ---- | ---- |
| 3 | 4 |
| 2 | 8 |
| 3 | 6 |
| 5 | 7 |
| 操作:查询父类对应的子类关系 | |
| 父类 | 子类 |
| ---- | ---- |
| 信息技术 | 办公信息 |
| 软件开发 | web开发 |
| 软件开发 | 数据库 |
| 美术设计 | ps技术 |
-- 查询父子信息:把一张表拆成两张一模一样的表
SELECT a.`categoryName` AS '父栏目',b.`categoryName` AS '子栏目'
FROM `category` AS a ,`category` AS b
WHERE a.`categoryid`=b.`pid`
4.5、分页和排序
排序
语法:order by 字段 asc/desc
-- 排序:升序 ASC ;降序DESC
-- 语法:ORDER BY 通过哪个字段,怎么排
-- 查询的结果根据 成绩降序排序
SELECT s.`studentno`,`studentname`,`studentresult`
FROM student s
INNER JOIN result r
ON s.`studentno`=r.`studentno`
ORDER BY `studentresult` ASC
分页
语法:limit 查询起始值下标,pagesize
-- 为什么要分页
-- 分页,缓解数据库压力,给人跟好的体验 也有瀑布流
-- 每页显示两条数据
-- 语法:limit 起始值,页面的大小
-- 第一页 limit 0,5 (1-1)*5
-- 第二页 limit 5,5 (2-1)*5
-- 第三页 limit 10,5 (3-1)*5
-- 第N页 limit (n-1)*pagesize,pagesize
-- 【(n-1)*pagesize:起止值】
-- 【pagesize:页面大小】
-- 【 n:当前页】
-- 【数据总数/页面大小=总页数】
SELECT s.`studentno`,`studentname`,`studentresult`
FROM student s
INNER JOIN result r
ON s.`studentno`=r.`studentno`
ORDER BY `studentresult` ASC
LIMIT 0,3
4.6、子查询
where(这个值是计算出来的)
本质:在where语句中嵌套一个子查询语句
-- ========== where ==========
-- 1、查询C语言-1的所有考试结果(学号,科目编号,成绩),降序排列
-- 方式一:使用连接查询
SELECT `studentno`,r.`subjectno`,`studentresult`
FROM result r
INNER JOIN `subject` sub
ON r.`subjectno`= sub. subjectno
WHERE `subjectname`= 'C语言-1'
ORDER BY studentresult DESC
-- 方式二:使用子查询(由里及外)
SELECT `studentno`,`subjectno`,`studentresult`
FROM result
WHERE subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = 'C语言-1'
)
-- 联表查询
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON s.`studentno`=r.`studentno`
INNER JOIN `subject` sub
ON sub.`subjectno`=r.`subjectno`
WHERE `studentresult`>=80 AND `subjectname`='高等数学-2'
-- 分数不小于80分的学生的学号和姓名
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON s.`studentno`=r.`studentno`
WHERE `studentresult`>=80
-- 在这个基础上增加一个科目,高等数学-2
-- 查询 高等数学-2 的编号
SELECT DISTINCT s.`studentno`,`studentname`
FROM student s
INNER JOIN result r
ON s.`studentno`=r.`studentno`
WHERE `studentresult`>=80 AND `subjectno`=(
SELECT `subjectno` FROM SUBJECT
WHERE `subjectname`= '高等数学-2'
)
-- 再改造 嵌套(由里及外)
SELECT `studentno`,`studentname` FROM student WHERE `studentno` IN (
SELECT studentno FROM result WHERE `studentresult`>=80 AND `subjectno`=(
SELECT `subjectno` FROM SUBJECT WHERE `subjectname`= '高等数学-2'
)
)
4.7分组和过滤
-- 查询不同课程的平均分,最低分,最高分,平均分大于80分
-- 核心:(根据不同的课程分组)
SELECT `subjectname`,AVG(`studentresult`) AS 平均分,MAX(`studentresult`) AS 最大值,MIN(`studentresult`)AS 最小值
FROM `result` AS r
INNER JOIN `subject` AS sub
ON r.`subjectno`=sub.`subjectno`
GROUP BY r.`subjectno` -- 通过什么字段来分组
HAVING 平均分 >80
5、MySQL函数
5.1常用函数(其实并不常用)
-- ==============常用函数============
-- 数学运算
SELECT ABS(-8)
SELECT CEILING(9.4) -- 向上取整
SELECT FLOOR(9.4) -- 向下取整
SELECT RAND() -- 返回一个0~1之间的随机数
SELECT SIGN(-10) -- 返回一个数的符号 负数返回-1 正数返回1 0是0
-- 字符串函数
SELECT CHAR_LENGTH('厚积薄发') -- 返回字符串的长度
SELECT CONCAT('我','爱','你') -- 拼接字符串
SELECT INSERT('我爱编 程',3,2,'**') -- 插入字符串
SELECT LOWER('LIBERTY') -- 转小写
SELECT UPPER('liberty') -- 转大写
SELECT INSTR('liberty','e') -- 返回第一次出现的字串的牵引
SELECT REPLACE ('坚持就能成功','坚持','努力') -- 替换出现的指定字符串
SELECT SUBSTR('坚持就能成功',4,1) -- 返回指定的字符串(源字符串,截取的位置,截取的长度)
SELECT REVERSE('ytrebil') -- 翻转字符串
-- 时间和日期函数(记住)
SELECT CURRENT_TIME() -- 获得当前时间
SELECT CURRENT_DATE() -- 获取当前日期
SELECT NOW() -- 获取当前时间
SELECT LOCALTIME() -- 获取本地时间
SELECT SYSDATE() -- 获取系统时间
SELECT YEAR(NOW())
SELECT MONTH(NOW())
SELECT HOUR(NOW())
SELECT MINUTE(NOW())
SELECT SECOND(NOW())
-- 系统
SELECT SYSTEM_USER()
SELECT USER()
SELECT VERSION()
5.2、聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 求平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
-- =============聚合函数==========
--- 都能够统计表中的数据(想查询一个表中有多少记录,就使用这个count())
SELECT COUNT(studentname) FROM student -- count(字段),指定列,会忽略所有的null的值
SELECT COUNT(*) FROM student -- count(*),不会忽略null值,本质:计算行数
SELECT COUNT(1) FROM student -- count(1),不会忽略null值 本质:计算行数
SELECT SUM(`studentresult`) AS 总和 FROM result
SELECT AVG(`studentresult`) AS 平均值 FROM result
SELECT MAX(`studentresult`) AS 最高值 FROM result
SELECT MIN(`studentresult`) AS 最低值 FROM result
5.3、数据库级别的MD5加密(扩展)
什么是MD5?
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm)
主要增强算法复杂度金额不可逆性,具体的值的md5是一样的
MD5破解网站的原理,背后有一个字典
-- ==============测试 MD5 加密=============
CREATE TABLE `testmd5`(
`id` INT(20) NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(200) NOT NULL ,
`pwd` VARCHAR(100) NOT NULL ,
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
-- 明文密码
INSERT INTO testmd5
VALUE(1,'zhangsan','1'),(2,'lsisi','123456'),(3,'wangwu','123456')
-- 加密
UPDATE testmd5 SET `pwd` = MD5(`pwd`) WHERE id =1
UPDATE testmd5 SET `pwd` = MD5(`pwd`) -- 加密全部的密码
-- 插入的时候加密
INSERT INTO testmd5
VALUE(5,'x',MD5('123456'))
-- 如何校验:将用户传递进来的进行md5校验,比对加密后的值
SELECT * FROM `testmd5` WHERE `name` = 'x' AND pwd = MD5('123456')
4.8、select小结
select完整语法:
SELECT [ALL | DISTINCT]
{ * | table.* |[table.field1 [AS a;ias1][,table.field2[AS laias2]][,...]] }
FROM table_name [AS table_alias]
[LEFT | RIGHT | INNER JOIN table_name2 ] --联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照那几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY] -- 指定查询记录按一个或多个条件排序
[LIMIT {[`offset`,]`row_count` | row_countOFFSET `offset`}]; -- 指定查询的记录从哪条到哪条
注意:
- []中括号代表可选,{}大括号代表必选
- 顺序很重要
- select 去重 要查询的字段 from表 (注意:表和字段可以取别名)
- XXX join要连接的表 on 等值判断
- where (具体的值,子查询语句)
- group by (通过哪个字段来分组)
- having (过滤分组后的信息,条件和where一样位置不同)
- order by (通过哪个字段排序)【升序asc/降序/desc】
- limit startindex,pagesize

 浙公网安备 33010602011771号
浙公网安备 33010602011771号