PostgreSQL 中 5 个最容易“踩坑”的锁行为
前言
PostgreSQL 使用 MVCC(多版本并发控制)实现并发控制机制,读写操作互不阻塞。PostgreSQL 提供了 8 种表级锁模式与 4 种行级锁模式,官方文档的锁冲突对照表清晰标注了各类锁的互斥关系。
但在真实生产环境中,锁冲突往往并不会像文档描述得那样直观。很多看似无害的 SQL,会在特定条件下触发意料之外的阻塞链、死锁甚至业务中断。
本文整理了 PostgreSQL 中 5 个最容易被忽略、却又极具破坏性的锁行为。
运行环境
- 数据库版本:PostgreSQL 18
- 事务隔离级别:READ COMMITTED(默认)
一、ACCESS EXCLUSIVE 等待时,会触发“连锁阻塞”
这是 PostgreSQL 中最经典、也最危险的一类锁问题。一个本应瞬间完成的 ALTER TABLE,可能导致整个业务读请求全部阻塞。
假设存在如下场景:
Session 1
SELECT pg_sleep(600) FROM t LIMIT 1; -- a long-running SELECT
Session 2
ALTER TABLE t ADD COLUMN name text;
由于 Session 1 持有 ACCESS SHARE 锁,因此 ALTER TABLE 所需的 ACCESS EXCLUSIVE 锁只能等待。到这里为止,一切都符合预期。真正容易被忽略的是 PostgreSQL 的锁等待机制采用 FIFO 队列。
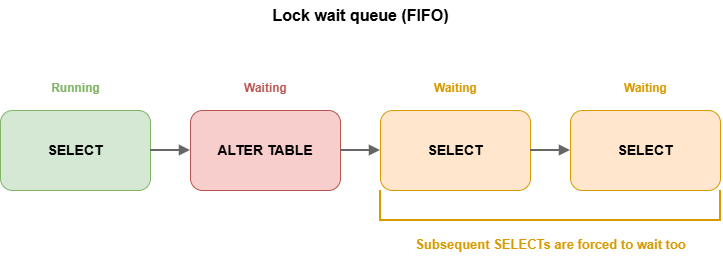
因此,一旦 ACCESS EXCLUSIVE 锁进入等待队列,后续所有访问该表的新 SELECT,也会被排在它后面等待,即使这些 SELECT 与最开始那个长查询本身并不冲突。
最终形成以下阻塞链:
- 数据表上运行长耗时查询;
- 表结构变更等需要排他访问锁的语句,因锁冲突进入等待队列;
- 后续所有查询语句均在队列中排队等待。
链式阻塞会大幅延长查询响应时间,进而引发业务故障。
优化方案
- 执行需申请排他访问锁的语句时,配置
lock_timeout参数,避免锁等待无限持续; - 通过
pg_stat_activity视图提前排查数据库内的长耗时查询。
二、外键约束导致的“隐式死锁”
外键约束会隐式触发锁申请,由此引发非直观的死锁问题。
当 INSERT 写入子表时,PostgreSQL 会自动对父表对应记录加锁FOR KEY SHARE,这是为了保证引用完整性。
以数据表 t 和主表 s 为例,向 t 插入数据时,系统会自动对 s 的关联行添加键共享锁。键共享锁与更新锁存在互斥关系,若两个会话以相反顺序,先对主表不同行加更新锁,再插入外键关联数据,会形成循环等待,最终触发死锁。
Session 1
BEGIN;
SELECT * FROM s WHERE id=1 FOR UPDATE; -- lock row s.id=1 with FOR UPDATE
Session 2
BEGIN;
SELECT * FROM s WHERE id=2 FOR UPDATE; -- lock row s.id=2 with FOR UPDATE
Session 1
INSERT INTO t (s_id) VALUES (2); -- wants FOR KEY SHARE on row s.id=2 (waits for Session 2)
Session 2
INSERT INTO t (s_id) VALUES (1); -- wants FOR KEY SHARE on row s.id=1 (deadlock detected)
该场景的特殊性体现在两方面:纯插入类 SQL 会隐性锁定外键主表数据行;从业务 SQL 表层无法直观识别锁操作。
优化方案
- 规避多会话反向加锁、交叉插入外键数据的设计,从源头杜绝死锁;
- 统一全应用的加锁顺序,例如按照主键升序对主表数据行加锁,固定单向加锁逻辑;
- 死锁会以报错形式抛出,业务代码需增加异常重试逻辑。
三、两个 INSERT 之间也可能发生死锁
很多人认为只有 UPDATE / DELETE 才会死锁。实际上两个纯 INSERT 事务,同样可能死锁。
Session 1
BEGIN;
INSERT INTO t (id) VALUES (1);
Session 2
BEGIN;
INSERT INTO t (id) VALUES (2);
Session 1
INSERT INTO t (id) VALUES (2); -- waits for Session 2 to commit
Session 2
INSERT INTO t (id) VALUES (1); -- deadlock detected
主键与唯一约束会对重复数据进行校验。若目标数据正被其他事务插入,当前插入语句会进入等待状态,等待对方事务执行完毕。若对方事务提交,则判定为唯一约束冲突;若对方事务回滚,则当前插入正常执行。
上述案例中,两个会话互相等待对方事务提交,形成循环等待,最终触发死锁。
优化方案
- 使用
SERIAL/IDENTITY/Sequence生成唯一 ID,从根源避免多会话并发插入相同数据; - 应用层必须支持死锁重试。
四、唯一不会主动让步的 Autovacuum
通常情况下 Autovacuum 获取的是SHARE UPDATE EXCLUSIVE。当与其他语句发生冲突时 Autovacuum 通常会自动取消。因此很多人会认为 Autovacuum 不会真正影响业务,但实际上存在一个例外。
当 PostgreSQL 检测到 relfrozenxid 接近 autovacuum_freeze_max_age 时,会启动一种特殊的 Autovacuum(to prevent wraparound),这种 Autovacuum 不会自动取消。
实际可能出现以下执行流程:
- 表接近事务 ID 回卷风险
- Wraparound Autovacuum 启动
- ALTER TABLE 请求 ACCESS EXCLUSIVE
- ALTER TABLE 等待 Autovacuum
- 后续 SELECT 全部进入阻塞队列
该场景结合前文链式阻塞问题后,极易快速引发严重故障。
优化方案
- 监控 pg_stat_activity 视图,发现防事务 ID 回卷的清理进程时,等待进程执行完成再开展其他操作;
- 定期查询数据表老化状态,提前预判风险,默认阈值为 2 亿事务:
SELECT relname, age(relfrozenxid)
FROM pg_class
WHERE relkind = 'r'
ORDER BY age(relfrozenxid) DESC;
- 规划表结构变更等 DDL 操作前,先检查表老化值。若接近阈值,提前手动执行 VACUUM FREEZE,再执行 DDL 语句。
五、VACUUM 隐藏的 ACCESS EXCLUSIVE 阶段
很多人认为 VACUUM 只会获取SHARE UPDATE EXCLUSIVE,实际上并不完全如此。VACUUM 在最后回收表尾空页时,会执行 truncate,这一阶段需要获取锁 ACCESS EXCLUSIVE。
如果此时存在长时间 SELECT VACUUM 会等待 ACCESS EXCLUSIVE。随后新的 SELECT 会再次触发第一类问题中的“连锁阻塞”。
在流复制备库上,这类问题影响更明显。主库上 SELECT 可以持续等待,但备库上 WAL Replay 无法无限等待。因此当 VACUUM 的 ACCESS EXCLUSIVE WAL 被回放到备库时,如果备库存在冲突查询,WAL Replay 会暂停。一旦超过max_standby_streaming_delay,备库会强制取消冲突查询。这是主备行为之间一个非常重要的差异。
优化方案
- PostgreSQL 12 及以上版本,可单表关闭清理截断功能,配置
vacuum_truncate = false; - PostgreSQL 18 及以上版本,支持全局参数
vacuum_truncate,统一控制全库截断逻辑; - 备库存在长查询业务时,调大
max_standby_streaming_delay参数延长等待时长,设置为-1 代表无限等待。
总结
以上五类异常行为,均是 PostgreSQL 锁机制为保障数据正确性而产生的固有表现。机制设计符合规范,但在实际运维中极易形成风险点。
链式阻塞问题结合其他锁异常场景后,风险会快速放大。配置lock_timeout、持续监控pg_stat_activity视图,是保障数据库稳定运行的基础防护手段。
参考资料
- https://www.postgresql.org/docs/current/explicit-locking.html
- https://www.postgresql.org/message-id/d7df81620708101038k772a2cderb52bb09f5440bd1b@mail.gmail.com
- https://leosjoberg.com/blog/lock-propagation-postgres/
- https://xata.io/blog/migrations-and-exclusive-locks
作者:Shinya Kato
原文链接:
https://dev.to/shinyakato_/5-postgresql-locking-behaviors-that-trip-people-up-4k7n

 浙公网安备 33010602011771号
浙公网安备 33010602011771号