HOW 2026 分论坛演讲:PostgreSQL 在 AI 的应用及实践
HOW 2026 演讲 PPT 下载方式:https://mp.weixin.qq.com/s/PVPEjr4lagmWleBnN34dpw
本文整理自 HOW 2026 中国数据库开源发展峰会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:王丁丁, Oracle、PostgreSQL ACE,公众号:IT 邦德。
AI 正在从“能聊天”,进入“能执行”的阶段。
过去,企业讨论 AI,关注的是模型参数、推理能力和算力规模;而现在,真正决定 AI 是否能落地的,开始变成另外几个问题:
- 数据如何管理?
- 知识如何接入?
- AI 如何理解业务?
- 系统如何稳定运行?
而在这一过程中,数据库的重要性正在被重新放大。无论是 RAG、Agent、智能问数还是 AI 运维,其底层能力都离不开数据库对数据存储、向量检索、上下文关联、状态管理与知识召回的支撑。PostgreSQL 凭借扩展能力、多模数据支持以及成熟的向量生态,正在成为企业 AI 场景中的重要数据底座。
01 AI 时代的数据底座——PostgreSQL 成了最大赢家
当下 AI 赛道火热,各类专业名词层出不穷:LLM、提示词、上下文、Memory、Agents、RAG、Function Calling、Workflow、Skill、Subagent…… 十余种概念让人眼花缭乱。
拨开繁杂术语不难发现,如今绝大多数 AI 技术,最终都围绕 Agent 展开。不少一体化平台更是整合了全套 AI 能力,让普通用户也能轻松上手使用。
AI 技术的四次能力跃迁:从"看见"到"执行"
- 感知型 AI 阶段:以语音识别为代表,让机器读懂外界信息;
- 分析型 AI 阶段:具备数据研判能力,可为人类决策提供辅助;
- 生成式 AI 阶段:生成式 AI 崛起,RAG 技术落地,AI 化身实用知识助手;
- Agent AI 智能执行阶段:多 Agent 技术走向成熟,AI 不再局限于内容生成,能够自主接手各类繁琐工作,真正落地执行任务。
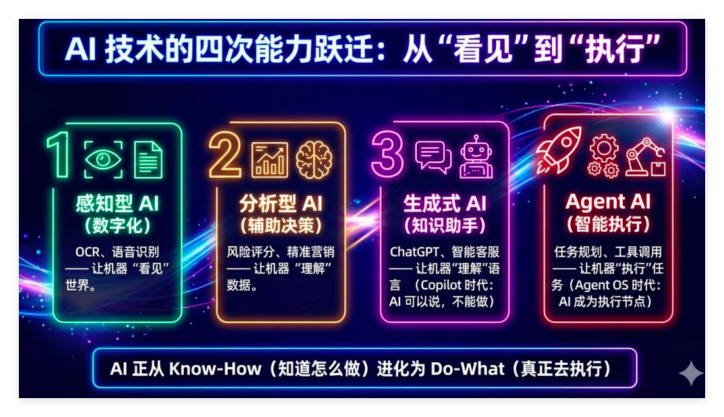
一套成熟、可靠的 AI 系统,离不开三大核心支撑:能思考的大模型、能行动的智能体、具备专业能力的技能库。三者兼备,才能保障 AI 系统安全、稳定地服务于实际业务。
PostgreSQL 向量能力:从插件走向原生展望
AI 全流程的数据存储、向量检索、效果反馈,都高度依赖数据库。作为核心数据底座,PostgreSQL 的向量能力也在持续进化:
现阶段 PG 并未内置原生向量功能,主要依靠第三方插件,实现向量数据存储、检索等能力,补足 AI 场景需求。反观其他主流数据库,虽已上线原生向量功能,但配套索引能力尚有不足。
目前 PG 仍在持续优化向量检索索引,全面支持向量量化与多维度适配。从行业发展趋势来看,未来 PG 也将推出原生向量能力,进一步完善相关算法与功能体系。
PGVECTOR 索引三剑客,场景各有侧重
搭配向量能力的三大索引,各司其职,覆盖不同业务场景:
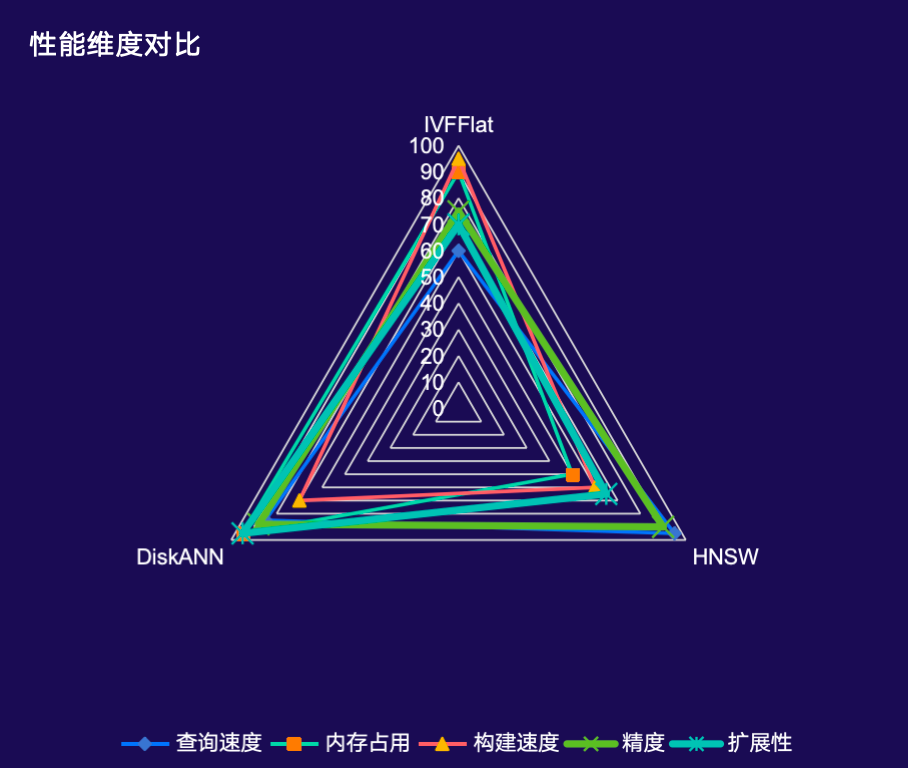
- IVFFlat(内容友好):倒排文件索引,通过聚类将向量分桶。内存占用低,构建速度快,适合内存受限场景。
- HNSW(速度优先):分层可导航小世界图,查询速度极快,精度高。适合对延迟敏感的业务场景。
- DiskANN(十亿级):磁盘优化近似近邻搜索,支持十亿级向量,成本可控。适合超大规模数据集。
PGVECTOR 混合负载能力强大混合负载,一套 SQL 搞定多类型数据
Hybrid Workload:Business Data + JSONB + Vector in One Table
PGVECTOR 提供了业务数据、JSONB 扩展属性与向量数据同表存储的统一数据模型,实现多模数据的混合负载处理。以 products 表为例,对应的混合查询示例如下:

其核心优势是单库即所有:无需维护多个数据库实例,业务数据、元数据、向量数据共存于同一行,事务一致性天然保障。
- 事务一致性:ACID 保证,向量与业务数据强一致。
- 混合查询:向量相似度 + 业务过滤条件一次完成。
- 简化架构:告别多库同步,降低运维复杂度。
- 成本优化:节省专用向量数据库 60-80% 的部署成本。
02 多模扩展——重塑数据智能生态
多模型数据库技术架构
Oracle Database 26ai 提供了高吞吐写入、内存分析、图分析、全 SQL 支持等企业级一体化能力,为复杂业务场景提供了完备的内置功能支持。

PostgreSQL 凭借强大的插件化扩展生态,实现了 “Just use Postgres for Everything” 的架构理念,根据业务需求灵活选配能力,适配各类结构化、文本、XML、CSV 等多类型数据。丰富的扩展生态,能够满足制造业 FDC 系统毫秒级海量数据采集等复杂场景需求。
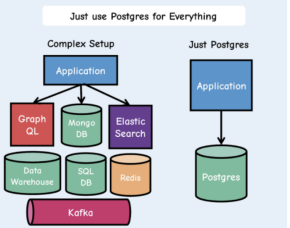
面对复杂业务需求,数据库需要兼顾 SQL 通用性与 NoSQL 扩展性、多模开发便捷性,同时承载 OLTP 与 OLAP 混合负载。得益于扩展机制,PostgreSQL 已从出色的关系型数据库,进化为具备全场景适配能力的多模数据库。
图数据与时序融合
Apache AGE 与 TimescaleDB 作为 PostgreSQL 的扩展插件,分别实现了图数据查询与毫秒级时序处理能力。
- Apache AGE:兼容 Neo4j Cypher 语法,支持关系网络分析与图遍历 + SQL 混合查询,可应用于欺诈检测、社交网络分析、供应链溯源、权限管理等场景。
- TimescaleDB:提供自动分区管理、连续聚合与高比例数据压缩能力,支持海量时序数据高效写入与快速查询,适配 IoT 设备监控、金融行情数据、应用性能追踪、能源管理等场景。
二者融合后,时序数据记录设备状态变化,图数据呈现设备关联关系,可共同支撑智能故障预测与根因分析等复杂场景。
空间数据与 GIS 应用
PostGIS 作为 PostgreSQL 的开源空间数据库扩展,让 PostgreSQL 成为企业级 GIS 首选方案。它支持数百种空间函数,具备完备的地理数据类型、空间计算、多坐标系与空间索引能力。
依托这些能力,PostGIS 可广泛应用于智慧城市、物流追踪、物联网、应急救援等场景,支撑城市部件管理、路径优化、地理围栏、资源调度等空间相关业务。
以下为空间查询示例:
SELECT name, ST_Distance(location,
ST_GeogFromText('POINT(116.4 39.9)'))
FROM stores
WHERE ST_DWithin(location,
ST_GeogFromText('POINT(116.4 39.9)'), 5000)
ORDER BY distance LIMIT 10;
03 RAG 及智能问数——从零搭建企业级智能问答系统
什么是 RAG?
RAG 的架构如图中所示,简单来讲,RAG 就是通过检索获取相关的知识并将其融入 Prompt,让大模型能够参考相应的知识从而给出合理回答。
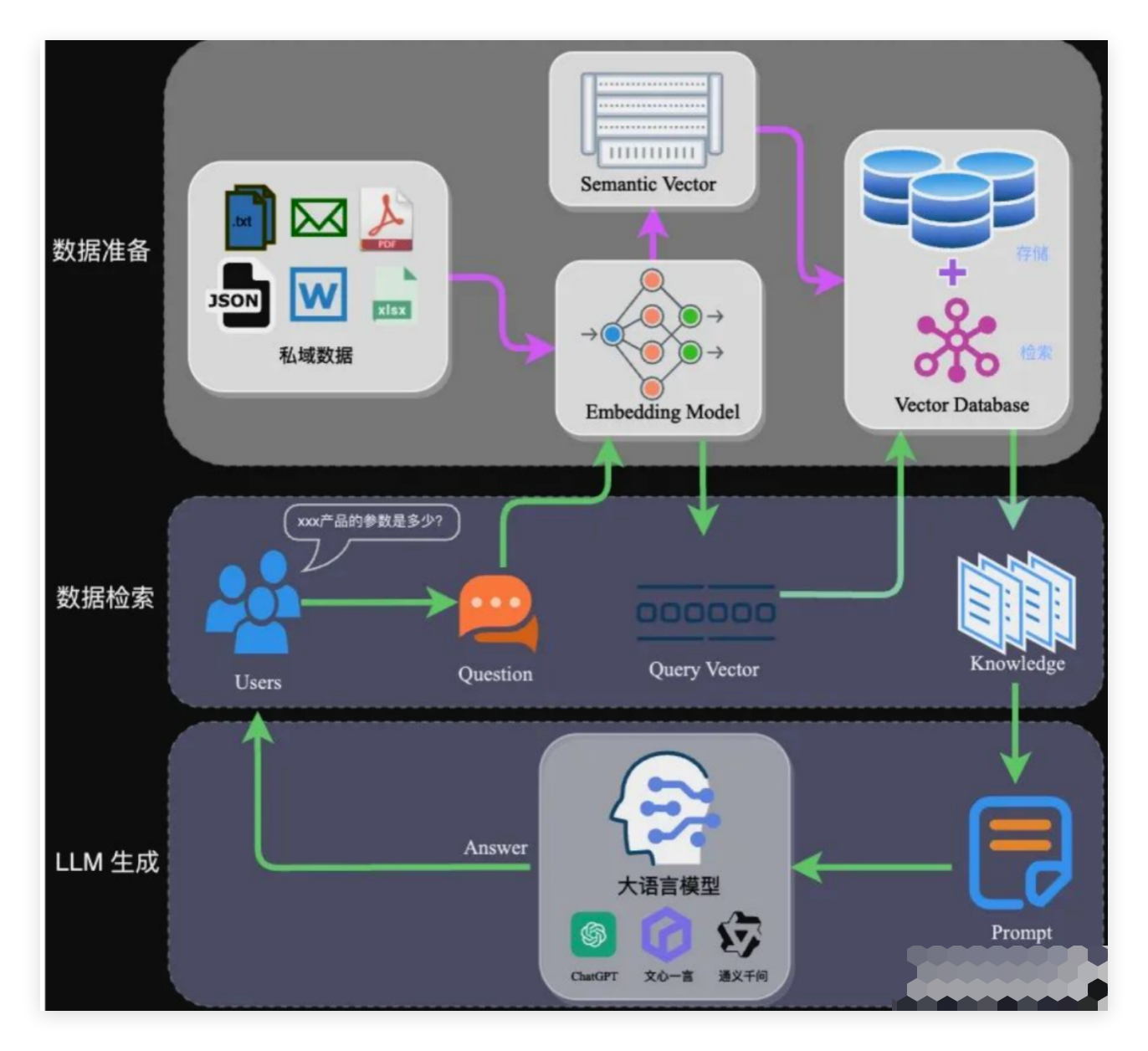
因此,可以将 RAG 的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和 Prompt 工程,将召回的知识合理利用,生成目标答案。
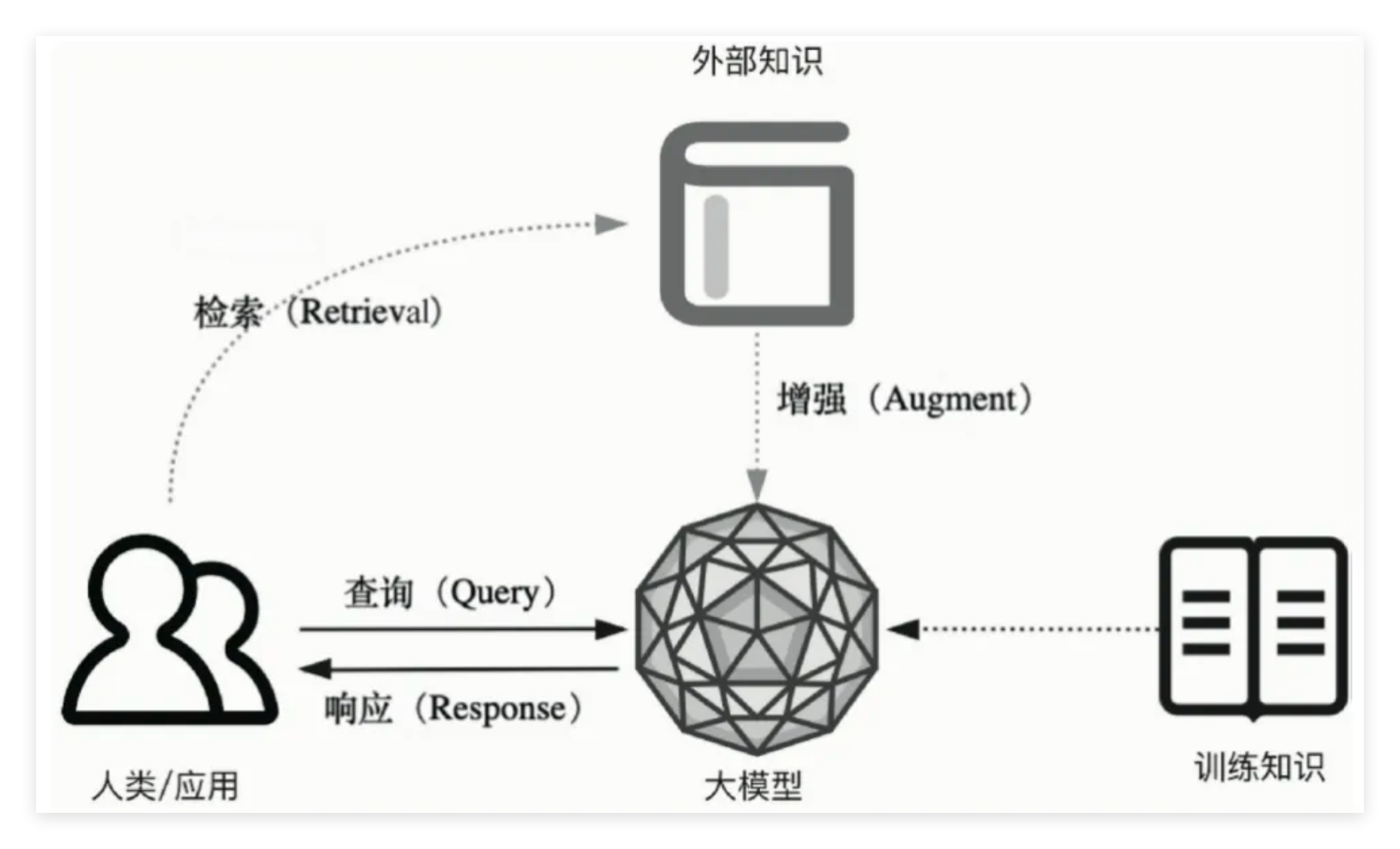
Dify × PostgreSQL 构建企业知识库
Dify 是当前主流的低代码 LLM 应用开发平台,其底层基于 PostgreSQL + PGVector 存储向量数据,可快速搭建企业级生成式 AI 应用,支持复杂工作流编排,无需大量代码开发。其核心价值是:分钟级搭建、可视化编排、数据自主可控、支持企业级部署。
核心功能模块:
- 可视化 Prompt 编排:通过界面拖拽方式设计对话流程,支持变量注入、条件分支、多轮对话管理。
- 数据集与知识库:基于 PGVector 实现文档向量化存储,支持多种格式导入,自动分段与索引。
- Workflow 工作流:可视化节点编排,支持 LLM、代码执行、HTTP 请求、知识检索等节点组合。
- 运营与可观测性:对话日志记录、标注与持续优化,A/B 测试与模型效果评估。
智能问数
基于 PostgreSQL 数据仓库,结合大语言模型实现对话式数据分析:用户以自然语言提问,系统自动完成查询、分析并输出可视化结果。
核心价值:
- 降低分析门槛:非技术人员也能自主完成数据分析,无需学习 SQL 或 BI 工具。
- 提升决策效率:秒级响应数据查询请求,支持实时业务决策。
- 释放数据价值:激活企业沉睡数据资产,转化为实际商业价值。
- 统一数据口径:通过语义层统一管理指标定义,确保数据一致性。
下面的流程图展示了基于 Dify 搭建的智能问数工作流,完整覆盖从用户提问到 SQL 执行、结果回复的闭环:
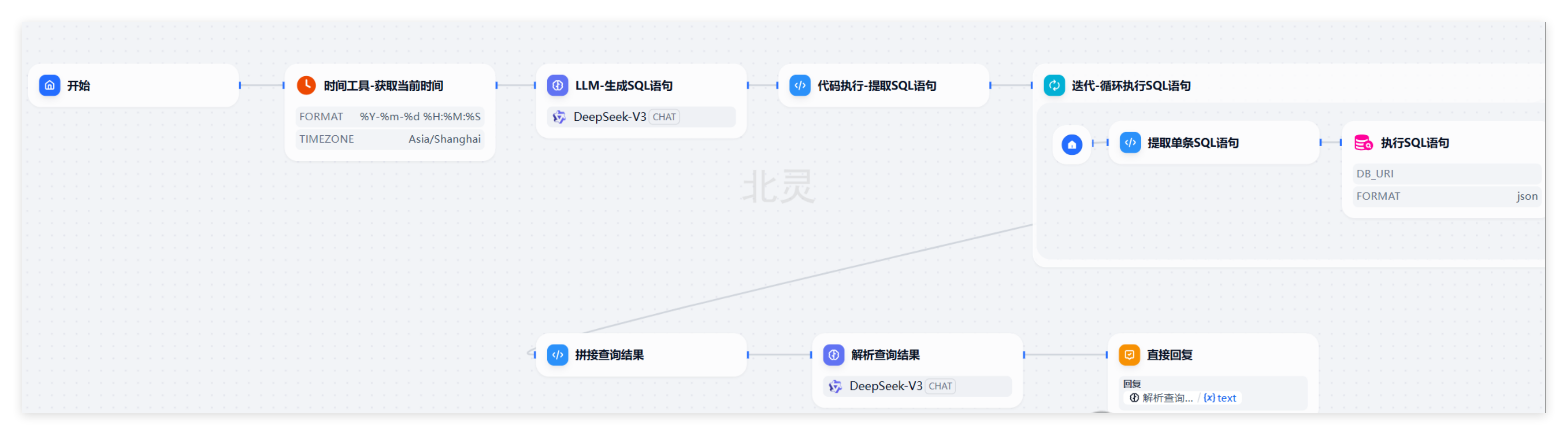
需注意:智能问数的落地效果,核心取决于对业务语义的理解深度,而非单纯的模型能力,更适合具备业务背景的专业人员使用。
Text-to-SQL
Text-to-SQL 利用大语言模型的代码生成能力,将自然语言问题自动转换为精确的 SQL 查询语句,让用户无需掌握 SQL 语法即可完成复杂的数据分析任务。其核心优势为:
- 零 SQL 基础即可查询数据
- 支持复杂的多表关联查询
- 自动 schema 感知与优化
- 企业级安全与权限控制
典型应用场景为业务人员自助数据分析、智能报表生成、数据探索与洞察发现、客服对话式数据查询。
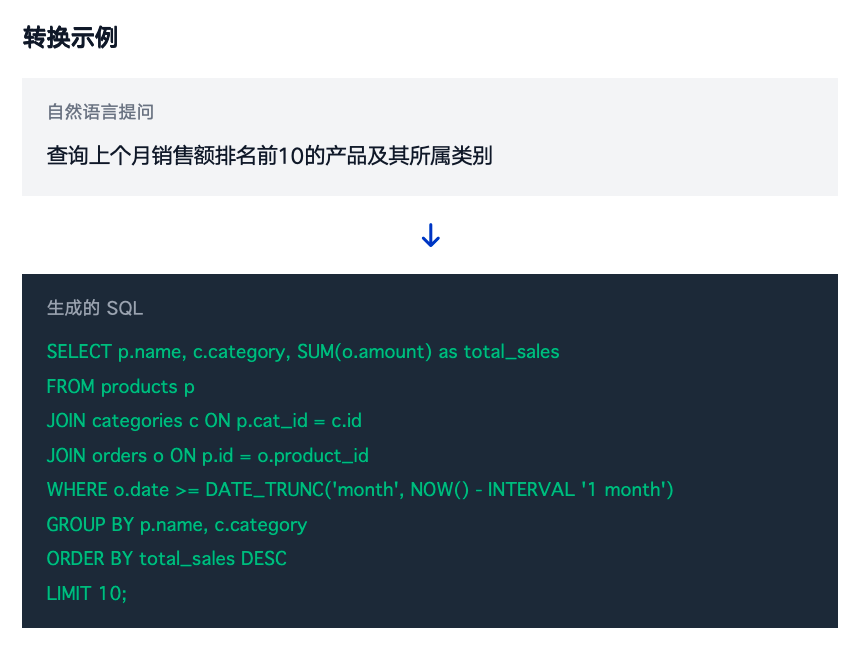
需注意:企业级落地的 Text-to-SQL 并非仅依赖模型生成,而是以 LLM 为核心,深度融合业务知识、强安全管控与持续学习能力的系统,以解决 “黑盒” 风险,保障可控性与适配性。
全文检索+AI 语义增强
PostgreSQL 原生全文检索依赖关键词精确匹配,难以应对模糊查询与语义关联场景;结合 PGVector 向量相似度能力后,可同时实现关键词精确匹配与语义理解的双重优势,大幅提升搜索结果的相关性与覆盖率。

通过 RRF 倒数排序融合、加权评分合并、重排序模型优化等方式,将两种检索结果有机结合,实现检索精度、效率与灵活性的三重提升。
04 智能运维与自愈体系 ——AI 反哺运维
针对数百套 Oracle、PostgreSQL、MySQL 数据库的大规模运维场景,AI 自治运维体系可有效解决传统运维的痛点,实现运维效率与稳定性的双重提升。
传统运维的五大困境
传统数据库运维普遍面临五大核心挑战:
- 被动式救火:"故障发生 → 告警触发 → 人工排查"的事后处理模式,业务已受损才开始介入。凌晨 3 点的告警电话,DBA 被迫从睡梦中惊醒排查。
- 专家经验绑定:慢 SQL 优化、故障根因分析极度依赖 DBA 个人经验。新人上手周期长,资深专家稀缺,人员流动带来运维能力断层。
- 告警风暴:阈值设低一天几百条告警,真正故障被淹没;设高又严重漏报。
- 资源浪费:按峰值预留 30%冗余,资源利用率不足 30%,成本居高不下。
- 安全盲区:高危操作、SQL 注入依赖人工巡检,发现时损失已无法挽回。
AI 自治运维六大核心能力
一套成熟的 AI 运维体系,应具备以下六大核心能力:
- 智能告警与根因分析:动态基线替代静态阈值,告警误报率降低 80%。自动关联指标、日志、SQL,秒级定位根因:"CPU 飙高 → 某 SQL 全表扫描,10 分钟内暴涨 100 倍"。
- 智能 SQL 优化:自动解析执行计划,识别全表扫描、临时表、索引失效,推荐最优索引甚至自动重写 SQL。大促前全业务线 SQL 体检,优化准确率 95%+。
- 智能容量规划:基于历史数据和业务周期预测未来负载,自动给出扩容/缩容建议。某银行落地后资源利用率从 28%提升至 65%,年成本降低 40%。
- 故障预测与自愈:识别磁盘坏道预警、内存泄露趋势、主从延迟异常,提前数小时甚至数天预警。可自愈故障自动修复:kill 长连接、终止死锁、自动扩容。
- 智能安全审计:识别异常访问行为:非工作时间高危操作(drop/truncate)、异常 IP 批量查询、SQL 注入攻击。实时阻断攻击链路,自动生成合规审计报告,效率提升 90%。
- 智能备份与灾备:差异化备份策略:热数据高频备份、冷数据低频备份。自动验证备份集可用性,周期性灾备切换演练,确保 RTO/RPO 符合业务要求,可用性 99.99%。
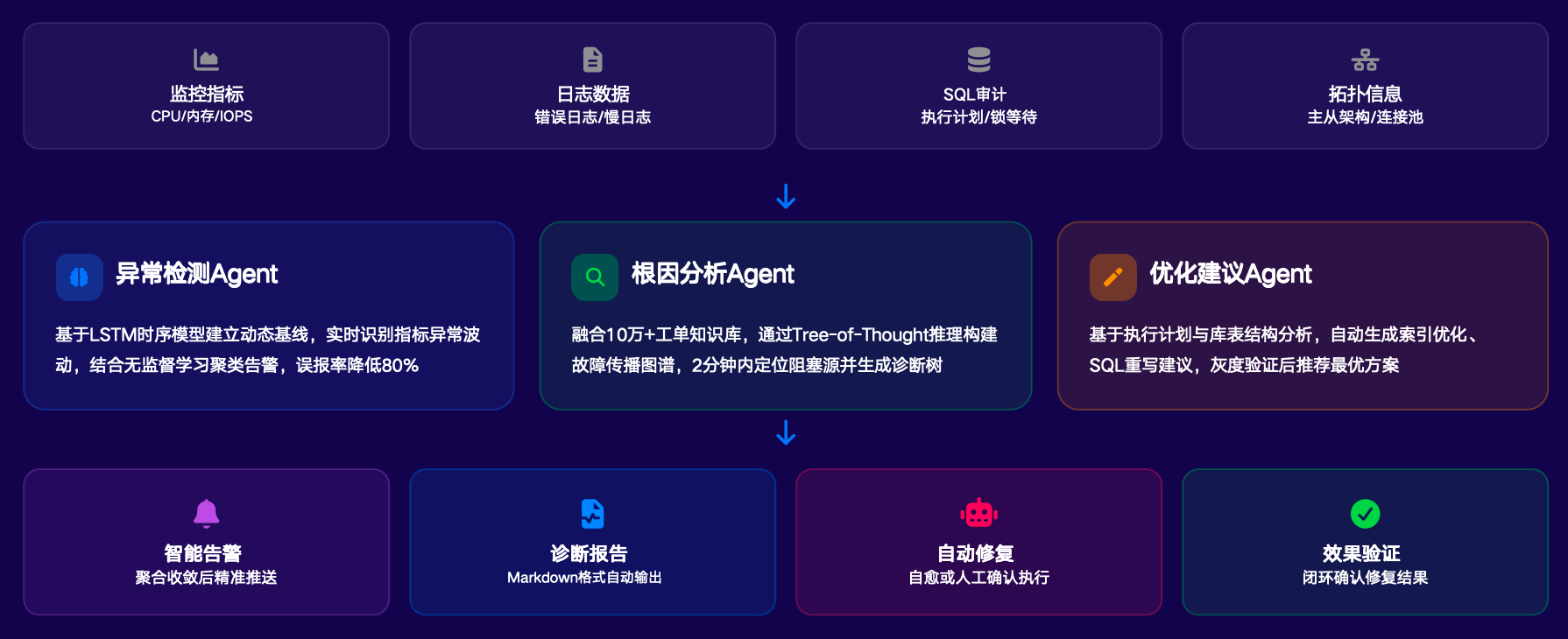
智能诊断运维架构
该体系采用多 Agent 协作架构,实现从监控到修复的全流程闭环:
- 业务层:提供智能告警、报告解析、自动修复、效果验证等能力,运维人员仅需通过弹窗确认即可执行修复操作。
- 原理层:由检测 Agent、根因分析 Agent、优化 Agent 等多模块协作,共同完成诊断与处理。
- 数据源层:采集监控指标、日志数据、网络拓扑信息,为 Agent 提供分析依据。
自动巡检与结果分析
平台支持大规模数据库的自动化巡检,覆盖 40 + 核心指标,巡检效率与质量大幅提升。巡检指标覆盖:
- 性能指标:CPU 利用率、内存使用、连接数、IOPS、锁等待、事务吞吐量。
- 存储健康:表空间碎片率、索引膨胀、WAL 堆积、磁盘坏道预测。
- SQL 质量:慢查询分析、全表扫描检测、索引缺失、执行计划异常。
- 安全配置:弱密码检测、权限审计、SSL 配置、高危操作日志。
落地效果上,平台将 300 余套数据库的全量巡检,从传统的一周缩短至 2 小时内完成,同时自动生成包含健康分数、风险分级与优化建议的巡检报告,运维人员可直接根据指引完成闭环处理。

小结
AI 规模化落地的当下,数据底座成为关键支撑。PostgreSQL 凭借丰富扩展能力,可在单库内统一承载关系、向量、图、时序、空间等多类数据,一站式满足 RAG、智能问数、AI 自治运维等场景需求。其既简化技术架构、降低运维成本,又依托 ACID 保障数据可靠,将持续成为企业智能化建设的核心数据底座。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号