PostgreSQL 性能:云端与本地的延迟分析
PostgreSQL 在各行各业的关键应用中具有极高适用性。尽管 PostgreSQL 提供了良好的性能,但仍存在一些用户不太关注但对整体效率与速度至关重要的问题。多数人认为增加 CPU 核数、更快的存储、更大内存即可提升性能,但还有同样重要的因素需要关注——那就是延迟。
延迟意味着什么?
数据库执行查询操作的耗时,仅占应用程序接收查询结果总耗时的极小部分。下图可直观呈现该过程的内在逻辑:
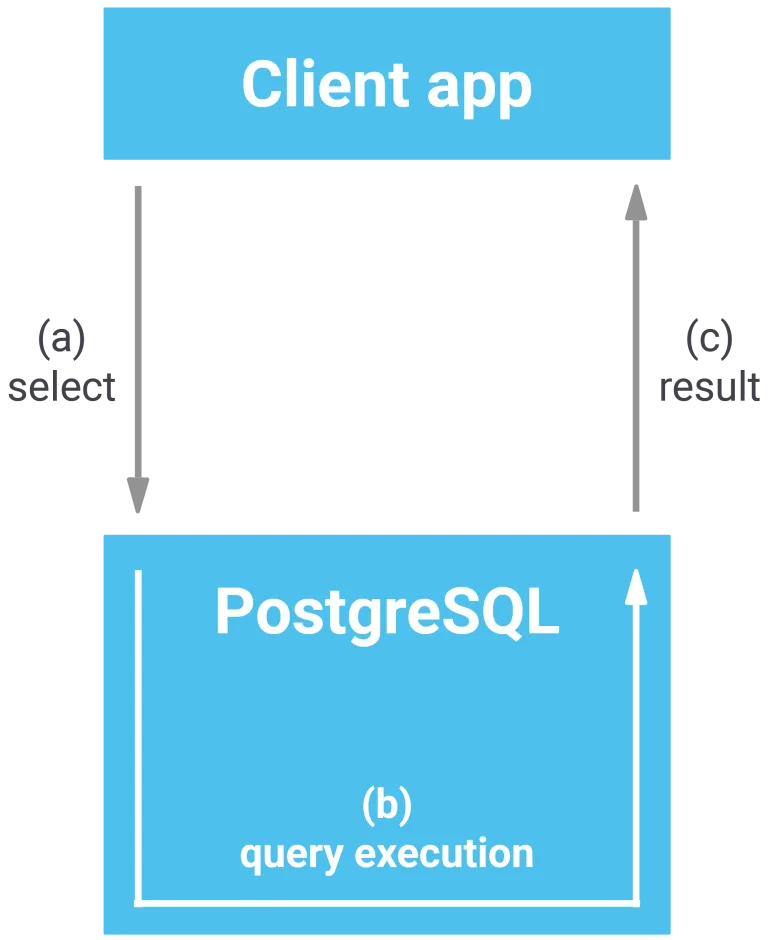
客户端应用发送请求后,驱动程序通过网络向 PostgreSQL 发送消息(a),数据库执行查询(b),并将结果集返回给应用程序(c)。关键问题在于:相较于查询执行时间(b),网络传输时间(a 与 c)是否具有显著影响。通过实验可以加以验证。
首先,使用 pgbench 初始化一个简单的测试数据库。对于本次测试,小规模数据库已足够:
cybertec$ pgbench -i blog
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 0.19 s (drop tables 0.00 s, create tables 0.02 s, client-side generate 0.13 s, vacuum 0.02 s, primary keys 0.02 s).
随后进行第一次基础测试:建立单个 UNIX Socket 连接,运行 20 秒(只读测试):
cybertec$ pgbench -c 1 -T 20 -S blog
pgbench (17.5)
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
maximum number of tries: 1
duration: 20 s
number of transactions actually processed: 1035095
number of failed transactions: 0 (0.000%)
latency average = 0.019 ms
initial connection time = 2.777 ms
tps = 51751.287839 (without initial connection time)
关键指标如下:
- 平均延迟:0.019 毫秒
- 每秒事务处理量(TPS):51751
该数据表现对于单连接场景而言已属良好水平。
下一步执行相同查询测试,但将连接方式从 UNIX 套接字更换为指向本地主机(localhost)的 TCP 连接(非远程连接):
cybertec$ pgbench -c 1 -T 20 -S blog -h localhost
pgbench (17.5)
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
maximum number of tries: 1
duration: 20 s
number of transactions actually processed: 583505
number of failed transactions: 0 (0.000%)
latency average = 0.034 ms
initial connection time = 3.290 ms
tps = 29173.916752 (without initial connection time)
结果出现明显变化,关键指标如下:
- 平均延迟:0.034 毫秒
- 每秒事务数(TPS):29173
吞吐量下降约 44%。下图对此进行了直观展示:
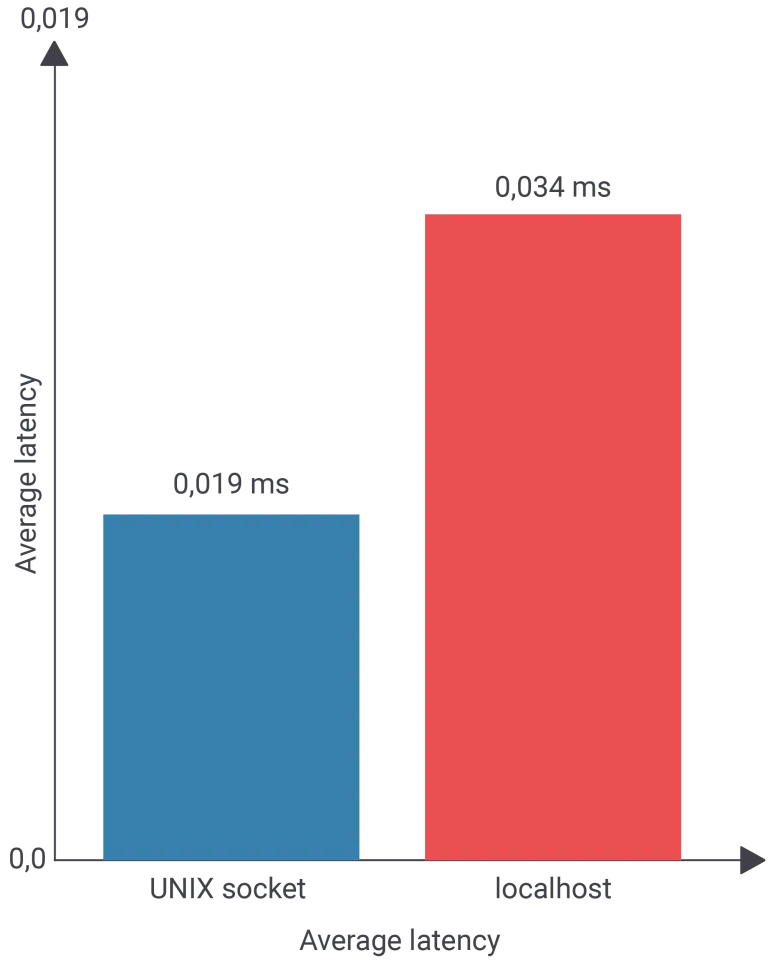
值得注意的是,延迟仅从 0.019 毫秒上升至 0.034 毫秒,变化幅度极小。但由于查询本身执行速度极快,即便如此微小的延迟也会带来显著影响。执行计划可以说明这一点:
blog=# explain analyze SELECT *
FROM pgbench_accounts
WHERE aid = 434232;
QUERY PLAN
------------------------------------------------------------
Index Scan using pgbench_accounts_pkey on pgbench_accounts
(cost=0.29..8.31 rows=1 width=97)
(actual time=0.015..0.016 rows=0 l oops=1)
Index Cond: (aid = 434232)
Planning Time: 0.227 ms
Execution Time: 0.047 ms
(4 rows)
执行计划中的关键数值为 0.016,表示索引扫描在表中定位记录所需的时间。将该数值与额外引入的网络延迟进行对比,即可理解微小变化为何会造成巨大差异。
真实网络环境中的延迟
在实际场景中,应用程序与数据库通常部署在不同的机器上。测试前,先查看 traceroute 的输出结果:
different_box$ traceroute 10.1.139.53
traceroute to 10.1.139.53 (10.1.139.53), 30 hops max, 60 byte packets
1 _gateway (10.0.0.1) 0.212 ms 0.355 ms 0.378 ms
2 cybertec (10.1.139.53) 0.630 ms 0.619 ms *
可以看到,从运行 pgbench 的主机到数据库服务器的路径较短,仅通过内部网络完成通信。
再次运行相同测试,结果如下:
different_box$ pgbench -h 10.1.139.53 -S -c 1 -T 20 blog
pgbench (17.5)
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
maximum number of tries: 1
duration: 20 s
number of transactions actually processed: 47540
number of failed transactions: 0 (0.000%)
latency average = 0.420 ms
initial connection time = 9.727 ms
tps = 2378.123901 (without initial connection time)
关键指标为:
- 平均延迟:0.420 毫秒
- 每秒事务数(TPS):2378
即便延迟仅为 0.420 毫秒,吞吐量已从 5 万 TPS 降至 2378 TPS。虽然该测试仍为单连接,但原因十分清晰:网络传输所消耗的 0.4 毫秒,与索引读取所需的 0.016 毫秒相比,已是数量级上的差距。
下图展示了吞吐量变化情况:
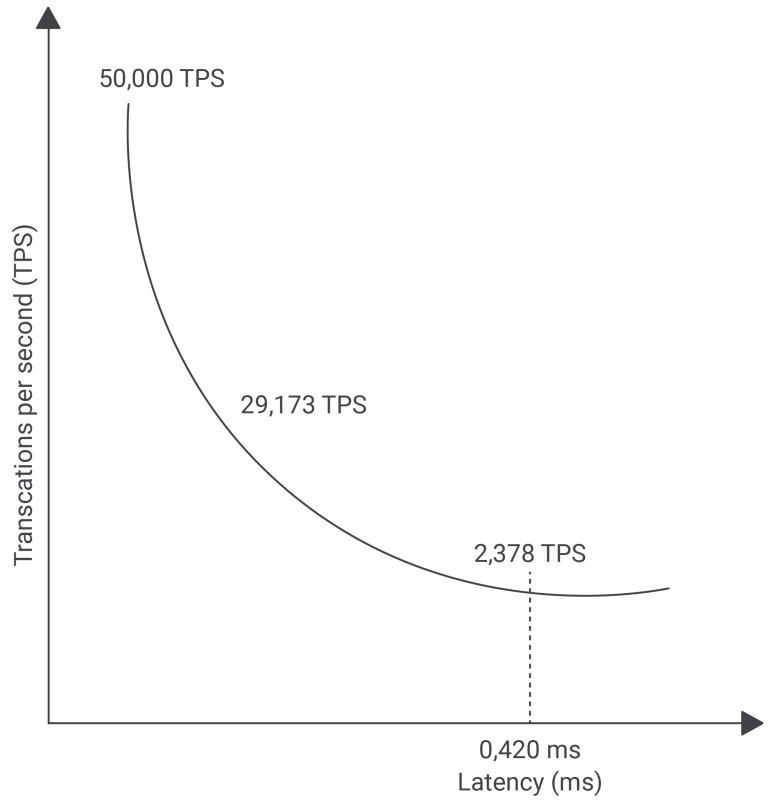
可确定的是,若网络架构中增加更多网络层级,吞吐量数据将进一步显著下降。该问题在云计算环境中尤为突出,每一层负载均衡、每一次网络跳转、每一台路由设备、每一条防火墙规则,均会增加网络延迟,进而降低应用程序运行效率。对于执行耗时极短的查询操作而言,网络延迟产生的额外开销占比越高,查询操作本身的执行耗时占比则越低,其对整体性能的影响程度也随之下降。
并发机制:可行的解决方案?
上述实验展示了极端情况,适用于单一应用在应用与数据库间频繁交互的场景。而在负载较高的业务系统中,通常存在多用户并发访问的情况。若增加并发连接数,系统性能可呈现较为理想的表现:
cybertec$ pgbench -c 4 -j 4 -T 20 -S blog -h localhost
pgbench (17.5)
starting vacuum...end.
transaction type: <builtin: select only>
scaling factor: 1
query mode: simple
number of clients: 4
number of threads: 4
maximum number of tries: 1
duration: 20 s
number of transactions actually processed: 1639827
number of failed transactions: 0 (0.000%)
latency average = 0.049 ms
initial connection time = 5.637 ms
tps = 82007.653121 (without initial connection time)
提取关键数据如下:
- 平均延迟:0.429 毫秒
- 每秒事务数(TPS):82007
使用 4 个并发连接,TPS 达到 82,000,增加更多并发可进一步提升。在现代服务器上,每秒超过 100 万次操作完全可行。但前提是数据库与查询来源距离接近,网络延迟不构成瓶颈。
更快的 CPU 是否有帮助?
常见疑问:增加 CPU 核数或提升单核性能是否有意义?对比如下:
- 索引查找:0.016 毫秒
- 网络延迟:0.490 毫秒
即便 CPU 更快,优化的仅为 0.016 毫秒,占总耗时约 3%,剩余 97% 时间不受影响。本质上,这与吞吐量关系不大,而是延迟问题。对于极短查询,延迟累积可能导致严重性能下降,尤其在云环境下网络复杂度更高。
对于执行时间较长的查询,延迟影响较小;但对于超快小查询,网络延迟可能成为主要性能瓶颈。
总结
延迟在高频、短时查询场景中具有决定性影响。单连接环境下,微小的网络延迟即可导致吞吐量大幅下降;通过并发可以在一定程度上缓解这一问题,但网络距离和拓扑结构仍是关键约束因素。相比之下,单纯提升 CPU 性能对以网络延迟为主导的场景改善有限。在云环境与分布式架构中,延迟问题需要在系统设计阶段予以重点关注。
原文链接:
https://www.cybertec-postgresql.com/en/postgresql-performance-latency-in-the-cloud-and-on-premise/
作者:Hans-Jürgen Schönig
HOW 2026 议题招募中
2026 年 4 月 27-28 日,由 IvorySQL 社区联合 PGEU(欧洲 PG 社区)、PGAsia(亚洲 PG 社区)共同打造的 HOW 2026(IvorySQL & PostgreSQL 技术峰会) 将再度落地济南。届时,PostgreSQL 联合创始人 Bruce Momjian 等顶级大师将亲临现场。
自开启征集以来,HOW 2026 筹备组已感受到来自全球 PostgreSQL 爱好者的澎湃热情。为了确保大会议题的深度与广度,我们诚邀您在 2026 年 2 月 27 日截止日期前,提交您的技术见解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号