
Python模块
模块&包(*****)
模块(modue)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块导入方法
1 import 语句
1 import module1[, module2[,... moduleN]
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path里。
1 import sys 2 print(sys.path)
输出结果是包含所有查找路径的列表:
1 ['/home/ives/PycharmProjects/Ipy/test', '/home/ives/PycharmProjects/Ipy', '/usr/lib/python36.zip', '/usr/lib/python3.6', '/usr/lib/python3.6/lib-dynload', '/usr/local/lib/python3.6/dist-packages', '/usr/lib/python3/dist-packages', '/usr/lib/python3.6/dist-packages', '/home/ives/pycharm-2018.1/helpers/pycharm_matplotlib_backend']
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
2 from…import 语句
语法:
1 from modname import name1[, name2[, ... nameN]]
例如,导入time模块的asctime方法,然后可以直接调用这个方法:
1 from time import asctime 2 3 t = asctime() 4 print(t)
输出:
1 Sun Apr 22 17:14:07 2018
这个声明不会把整个modulename模块导入到当前的命名空间中,只会将它里面的name1或name2单个引入到执行这个声明的模块的全局符号表。
3 From…import* 语句
1 from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
4 运行本质
1 import test 2 from test import add
无论1还是2,首先通过sys.path找到test.py,然后执行test脚本(全部执行),区别是1会将test这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:
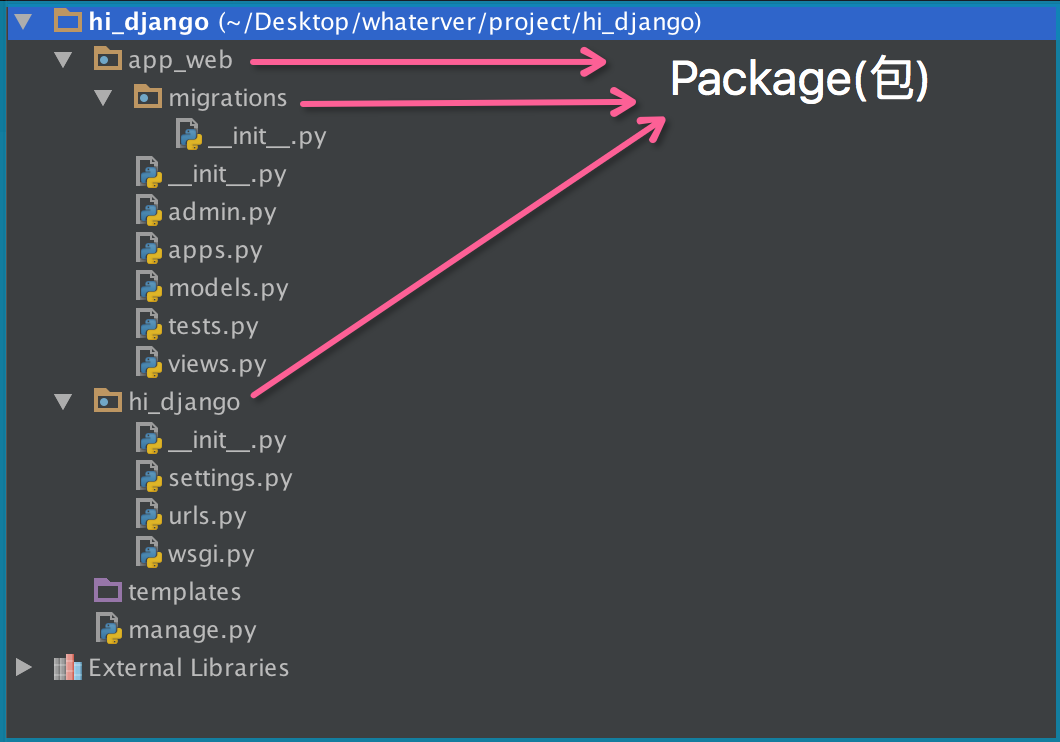
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件。
注意点(important)
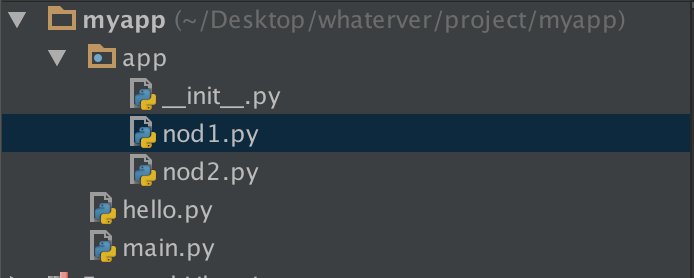
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
1 import sys,os 2 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 3 sys.path.append(BASE_DIR) 4 import hello 5 hello.hello1()
2 --------------
1 if __name__ == "__main__": 2 print("OK")
对于执行文件__name__的的结果就是__main__,而对于被调用的文件则返回的是模块的绝对路径:
1 """ 2 # 我在test包下创建了模块calculation文件: 3 def add(x, y): 4 return x + y 5 print(__name__) 6 """ 7 8 执行文件与test包为同一级 9 from test import calculation 10 print(calculation.add(1,2)) 11 print(__name__)
输出结果:
1 test.calculation #这个输出是因为导入了calculation模块,导入模块会对模块文件进行执行操作,这个是被调用模块的__name输出 2 3 #随后通过calculation调用add方法 3 __main__ #这个是执行文件的__name__输出
通常__name__ == "__main__" 在被调用文件中用来测试代码,在执行文件中意味着不希望被其他人调用执行文件。
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!

1 ##-------------cal.py 2 def add(x,y): 3 4 return x+y 5 ##-------------main.py 6 import cal #from module import cal 7 8 def main(): 9 10 cal.add(1,2) 11 12 ##--------------bin.py 13 from module import main 14 15 main.main()
1 # from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本, 2 # sys.path里有bin.py的当前环境。即/Users/yuanhao/Desktop/whaterver/project/web这层路径, 3 # 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为 4 # sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而 5 # from module/. import cal 时,解释器就可以找到了。
time模块(****)

三种时间表示
在Python中,通常有这几种方式来表示时间:
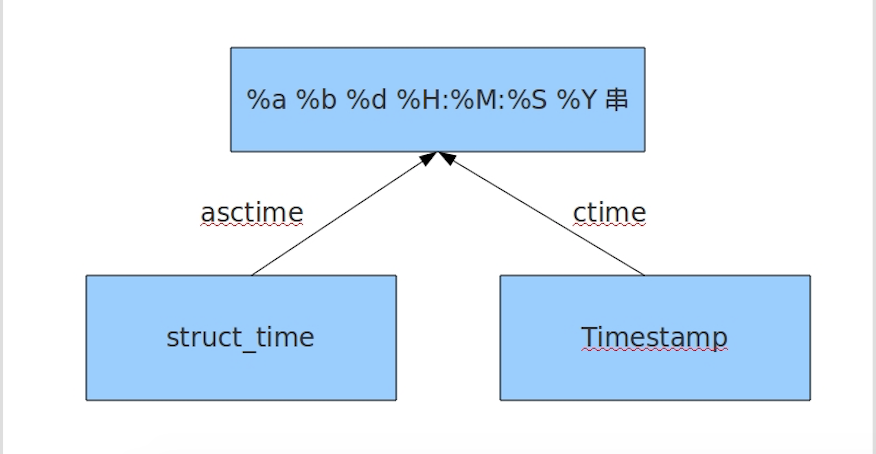
- 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串
- 元组(struct_time) : struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
1 import time 2 3 # 1 time() :返回当前时间的时间戳 4 time.time() #1473525444.037215 5 6 #---------------------------------------------------------- 7 8 # 2 localtime([secs]) 9 # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 10 time.localtime() #time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, 11 # tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0) 12 time.localtime(1473525444.037215) 13 14 #---------------------------------------------------------- 15 16 # 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 17 18 #---------------------------------------------------------- 19 20 # 4 mktime(t) : 将一个struct_time转化为时间戳。 21 print(time.mktime(time.localtime()))#1473525749.0 22 23 #---------------------------------------------------------- 24 25 # 5 asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 26 # 如果没有参数,将会将time.localtime()作为参数传入。 27 print(time.asctime())#Sun Sep 11 00:43:43 2016 28 29 #---------------------------------------------------------- 30 31 # 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为 32 # None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 33 print(time.ctime()) # Sun Sep 11 00:46:38 2016 34 35 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016 36 37 # 7 strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 38 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 39 # 元素越界,ValueError的错误将会被抛出。 40 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 41 42 # 8 time.strptime(string[, format]) 43 # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 44 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) 45 46 #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, 47 # tm_wday=3, tm_yday=125, tm_isdst=-1) 48 49 #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 50 51 52 # 9 sleep(secs) 53 # 线程推迟指定的时间运行,单位为秒。 54 55 # 10 clock() 56 # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。 57 # 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行 58 # 时间,即两次时间差。
1 # datetime 2 import datetime 3 print(datetime.datetime.now()) # 2018-04-22 19:46:03.654474

random模块(**)

import random print(random.random())#(0,1)----float print(random.randint(1,3)) #[1,3] print(random.randrange(1,3)) #[1,3) print(random.choice([1,'23',[4,5]]))#23 print(random.sample([1,'23',[4,5]],2))#[[4, 5], '23'] print(random.uniform(1,3))#1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) print(item)
验证码功能实现:
1 # 验证码功能 2 import random 3 def author_code(): 4 ret = '' 5 for i in range(5): 6 num = random.randint(0, 9) 7 char1 = chr(random.randint(65, 90)) # 在A-Z中随机取出一个字符 8 char2 = chr(random.randint(97, 122)) # 在a-z中随机取出一个字符 9 ret += str(random.choice([num, char1, char2])) 10 return ret 11 12 if __name__ == "__main__": 13 res = author_code() 14 print(res) 15 16 """ 17 字符转asc码 18 print(ord('a')) 19 print(ord('z')) 20 print(ord('A')) 21 print(ord('Z')) 22 """
os模块(****)
os模块是与操作系统交互的一个接口

os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.join()函数用于路径拼接文件路径。
os.path.join()函数中可以传入多个路径:
-
会从最后一个以”/”开头的参数开始拼接,之前的参数全部丢弃。
-
以上一种情况为先。在上一种情况确保情况下,若出现”./”开头的参数,会从”./”开头的参数的上一个参数开始拼接,直到遇到/开头的参数。
import os
print('1', os.path.join('aa', 'bb', 'c.py'))
print('2', os.path.join('aa', '/bb', 'c.py'))
print('3', os.path.join('/aa', '/bb', 'c.py'))
print('4', os.path.join('/aa', '/bb', '/c.py'))
print('5', os.path.join('./aa', './bb', 'c.py'))
print('6', os.path.join('/aa', './bb', './c.py'))
输出:
1 aa/bb/c.py 2 /bb/c.py 3 /bb/c.py 4 /c.py 5 ./aa/./bb/c.py 6 /aa/./bb/./c.py
sys模块(***)

(1) sys.argv 实现从程序外部向程序传递参数
sys.argv 变量是一个包含了命令行参数的字符串列表, 利用命令行想程序传递参数. 其中,脚本的名称总是 sys.argv 列表的第一个参数。
(2) sys.path 包含输入模块的目录名列表。
获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。在import导入module_name时,就是根据sys.path的路径来搜索module.name,也可以自定义添加模块路径。
sys.path.append(“自定义模块路径”)
(3) sys.exit([arg]) 程序中间的退出, arg=0为正常退出
一般情况下执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.exit函数,带有一个可选的整数参数返回给调用它的程序,表示你可以在主程序中捕获对sys.exit的调用。(0是正常退出,其他为异常)当然也可以用字符串参数,表示错误不成功的报错信息。
(4) sys.modules
sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度。它拥有字典所拥有的一切方法.
(5) sys.getdefaultencoding() / sys.setdefaultencoding() / sys.getfilesystemencoding()
sys.getdefaultencoding()
获取系统当前编码,一般默认为ascii。
sys.setdefaultencoding()
设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding(‘utf8’),此时将系统默认编码设置为utf8。(见设置系统默认编码 )
sys.getfilesystemencoding()
获取文件系统使用编码方式,Windows下返回’mbcs’,mac下返回’utf-8’
(6) sys.stdin, sys.stdout, sys.stderr
stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print
不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ),
或者以非标准的方式处理它们.
(7) sys.platform
获取当前系统平台. 如:win32、Linux等。
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
进度条:
import sys,time
for i in range(10):
sys.stdout.write('#')
time.sleep(1)
sys.stdout.flush()
json & pickle模块(****)
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
dic1 = '{"a":123, "b":456}'
print(eval(dic1))
print(json.loads(dic1))
"""
{'a': 123, 'b': 456}
{'a': 123, 'b': 456}
"""
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:


"""
dumps: 将对象序列化
dumps操作会将对象内的单引号转变为双引号,以便json能够识别
"""
import json
list1 = ['foo', {'bar': ('baz', None, 1.0, 2)}]
a = json.dumps(list1)
print(a) # ["foo", {"bar": ["baz", null, 1.0, 2]}]
print(type(a)) # <class 'str'>
b = json.loads(a)
print(b) # ['foo', {'bar': ['baz', None, 1.0, 2]}]
print(type(b)) # <class 'list'>
# c3 = json.loads("['a', 'b']") # json 不认单引号
# dct = str({"1": 111}) # 报错,因为生成的数据还是单引号:{'1': 1}
dumps字典排序:
import json
a = json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)
print(a) # '{"a": 0, "b": 0, "c": 0}'
print(type(a)) # <class 'str'>
dumps自定义分隔符:
import json
# 自定义分隔符由separators(item_separator, key_separator)
a = json.dumps([1, {"a": 123}, 2, 3, 4], separators=('*', '&'))
print(a) # [1*{"a"&123}*2*3*4]
dumps增加缩进增强可读性
import json
print(json.dumps({'a': 5, 'b': 7}, sort_keys=True, indent=2, separators=(',', ':')))
"""
{
"a":5,
"b":7
}
"""
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
dump: 将对象序列化并保存到文件
#将对象序列化并保存到文件
obj = ['foo', {'bar': ('baz', None, 1.0, 2)}]
with open(r"c:\json.txt","w+") as f:
json.dump(obj,f)
loads: 将序列化字符串反序列化
import json
obj = ['foo', {'bar': ('baz', None, 1.0, 2)}]
a= json.dumps(obj)
print(json.loads(a))
# [u'foo', {u'bar': [u'baz', None, 1.0, 2]}]
load: 将序列化字符串从文件读取并反序列化
with open(r"c:\json.txt","r") as f:
print(json.load(f))
pickle
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
python的pickle模块实现了python的所有数据序列和反序列化。基本上功能使用和JSON模块没有太大区别,方法也同样是dumps/dump和loads/load。cPickle是pickle模块的C语言编译版本相对速度更快。
与JSON不同的是pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型。
pickle反序列化后的对象与原对象是等值的副本对象,类似与deepcopy。
import pickle
dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
print(type(dic)) # <class 'dict'>
j = pickle.dumps(dic)
# print(j)
print(type(j)) # <class 'bytes'>
f = open('序列化对象_pickle', 'wb') # 注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) # -------------------等价于pickle.dump(dic,f)
# pickle.dump(dic, f)
f.close()
import pickle
f = open('序列化对象_pickle', 'rb')
data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
print(data['age'])
f.close()
import pickle
f = open('序列化对象_pickle', 'rb')
data = pickle.load(f)
print(data['age'])
shelve模块(* * *)
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r'test')
f['name'] = 'test'
f['age'] = 18
f['x'] = {'a': 1, 'b': 2}
f['y'] = {'a': 1, 'b': {'c': 3}}
f.close()
import shelve
file1 = shelve.open(r'test')
print(file1.keys()) # KeysView(<shelve.DbfilenameShelf object at 0x0000018090A374A8>)
print(file1.get('name'))
print(file1.get('age'))
print(file1.get('x'))
print(file1.get('y'))
print(file1.get('x')['a'])
print(file1.get('y')['b']['c'])
"""
KeysView(<shelve.DbfilenameShelf object at 0x00000229540776A0>)
test
18
{'a': 1, 'b': 2}
{'a': 1, 'b': {'c': 3}}
1
3
"""
xml模块(**)
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。从结构上,很像HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。那么Python是如何处理XML语言文件的呢?下面一起来看看Python常用内置模块之xml模块吧。
本文主要学习的ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型。在使用ElementTree模块时,需要import xml.etree.ElementTree的操作。ElementTree表示整个XML节点树,而Element表示节点数中的一个单独的节点。
xml的格式如下,就是通过<>节点来区别数据结构的:


1 <?xml version="1.0"?> 2 <data> 3 <country name="Liechtenstein"> 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data>
解析和修改XML文件
ElementTree.parse(source, parser=None),将xml文件加载并返回ElementTree对象。parser是一个可选的参数,如果为空,则默认使用标准的XMLParser解析器。
ElementTree.getroot(),得到根节点。返回根节点的element对象。
Element.remove(tag),删除root下名称为tag的子节点 以下函数,ElementTree和Element的对象都包含。
find(match),得到第一个匹配match的子节点,match可以是一个标签名称或者是路径。返回个element findtext(match,default=None),得到第一个配置的match的element的内容 findall(match),得到匹配match下的所有的子节点,match可以是一个标签或者是路径,它会返回一个list,包含匹配的elements的信息 iter(tag),创建一个以当前节点为根节点的iterator。
import xml.etree.ElementTree as ET
tree = ET.parse("xml_sample") # 解析xml文件,生成xml文件树
root = tree.getroot()
print(root.tag) # data 获取根节点的标签
print(root.attrib) # 根节点没有属性,返回{}
print(type(root)) # <class 'xml.etree.ElementTree.Element'>
# 遍历xml文档
for child in root:
print(child.tag, child.attrib) # tag为标签名,attrib为其属性
for i in child:
print(i.tag, i.attrib) # 没有属性的会返回{}
# 只遍历year节点
"""
Create and return tree iterator for the root element.
The iterator loops over all elements in this tree, in document order.
*tag* is a string with the tag name to iterate over
(default is to return all elements).
"""
for node in root.iter('year'):
print(node.tag, node.text) # text获取标签值
# 修改标签值
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated", "yes") # 更新添加属性
tree.write("new_xml.xml") # 将结果更新到一个新的文件
tree.write("xml_sample") # 将结果更新到原文件中
# 删除node
"""
findall(self, path, namespaces=None):
Find all matching subelements by tag name or path.
Same as getroot().findall(path), which is Element.findall().
*path* is a string having either an element tag or an XPath,
*namespaces* is an optional mapping from namespace prefix to full name.
Return list containing all matching elements in document order.
"""
"""
find(self, path, namespaces=None):
Find first matching element by tag name or path.
Same as getroot().find(path), which is Element.find()
*path* is a string having either an element tag or an XPath,
*namespaces* is an optional mapping from namespace prefix to full name.
Return the first matching element, or None if no element was found.
"""
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
for node in root.iter('year'):
if node.text == '2013':
print(node.tag, node.text, root.tag)
构建XML文件
ElementTree(tag),其中tag表示根节点,初始化一个ElementTree对象。
Element(tag, attrib={}, **extra)函数用来构造XML的一个根节点,其中tag表示根节点的名称,attrib是一个可选项,表示节点的属性。
SubElement(parent, tag, attrib={}, **extra)用来构造一个已经存在的节点的子节点 Element.text和SubElement.text表示element对象的额外的内容属性,Element.tag和Element.attrib分别表示element对象的标签和属性。
ElementTree.write(file, encoding='us-ascii', xml_declaration=None, default_namespace=None, method='xml'),函数新建一个XML文件,并且将节点数数据写入XML文件中。
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
自己创建xml文档:
# 创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml, "name", attrib={'enrolled': 'no'}, )
age = ET.SubElement(name, "age", attrib={"checked": 'no'})
age.text = '20'
sex = ET.SubElement(name, 'sex')
sex.text = 'sexual'
name2 = ET.SubElement(new_xml, 'name2', attrib={'enrolled': 'yes'})
age2 = ET.SubElement(name2, 'age')
age2.text = '33'
new_tree = ET.ElementTree(new_xml)
new_tree.write('general.xml', encoding='utf-8', xml_declaration=True)
ET.dump(new_xml)
configparser模块(* *)
configparser模块是python3种自带的一个模块,顾名思义就是进行配置解析工作,可以进行配置文件创建修改删除等工作,主要以类字典方式进行操作。

来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
conf = configparser.ConfigParser()
conf['default'] = {}
conf['default']['ServerAliveInterval'] = '45'
conf['default']['Compression'] = 'yes'
conf['default']['CompressionLevel'] = '9'
conf['default']['ForwardX11'] = 'yes'
conf['bitbucket.org'] = {'User': 'hg'}
conf['topsecret.server.com'] = {}
topsecret = conf['topsecret.server.com']
topsecret['Port'] = '500022'
topsecret['ForwardX11'] = 'no'
with open('example.ini', 'w') as configfile:
conf.write(configfile)
那么如何去查询和修改一个配置文件呢?
import configparser
conf = configparser.ConfigParser()
# ----------查询
print(conf.sections()) # [] ,没有给conf一个配置文件
conf.read('example.ini')
print(conf.sections()) # ['default', 'bitbucket.org', 'topsecret.server.com']
print('bitbucket.org' in conf) # True
print(conf['default']['compression']) # yes
# print(conf['TOPsecret.server.com']) #对于section区分大小写,对于section中的key不区分大小写
print(conf['topsecret.server.com']) # <Section: topsecret.server.com> 返回section对象
print(conf['topsecret.server.com']['port']) # 500022
for key in conf:
print(key)
"""
DEFAULT
default
bitbucket.org
topsecret.server.com
"""
for key in conf['default']:
print(key)
"""
serveraliveinterval
compression
compressionlevel
forwardx11
"""
# conf.options(section) 以列表形式返回section中的key名
print(conf.options('default')) # ['serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11']
print(conf.sections()) # ['default', 'bitbucket.org', 'topsecret.server.com']
print(conf.items('default'))
# [('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes')]
print(conf.items('bitbucket.org')) # [('user', 'hg')]
print(conf.get('bitbucket.org', 'user')) # hg
if 'test' not in conf:
conf.add_section('test') # 增加一个section
conf.add_section('T1')
conf.remove_option('topsecret.server.com', 'forwardx11') # 删除一个option
conf.remove_section('test') # delete a section
conf.set('T1', 'k1', '1111')
conf.write(open('example.ini', 'w'))
hashlib模块(* *)
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
# 普通的字符串MD5加密后可以通过撞库的方式获取的加密前的字符串明文
hash_id = hashlib.md5()
hash_id.update('hello'.encode("utf8"))
print(hash_id.hexdigest())
# 通过增加额外复杂的字符串可以减小撞库的可能性
hash_id = hashlib.md5("s#$%b".encode('utf8'))
hash_id.update('hello'.encode("utf8"))
print(hash_id.hexdigest())
hash_id = hashlib.md5()
hash_id.update("s#$%b".encode('utf8'))
hash_id.update('hello'.encode("utf8"))
print(hash_id.hexdigest())
hash_id = hashlib.md5()
hash_id.update('s#$%bhello'.encode("utf8"))
print(len(hash_id.hexdigest()))
print(hash_id.hexdigest())
# sha256加密,64位密文
hash_id = hashlib.sha256()
hash_id.update('hello'.encode('utf8'))
print(len(hash_id.hexdigest()))
print(hash_id.hexdigest())
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
import hashlib
# ######## 256 ########
hash = hashlib.sha256('898oaFs09f'.encode('utf8'))
hash.update('alvin'.encode('utf8'))
print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac
h = hmac.new('alvin'.encode('utf8'))
h.update('hello'.encode('utf8'))
print (h.hexdigest())#320df9832eab4c038b6c1d7ed73a5940
subprocess模块(****)
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
This module intends to replace several other, older modules and functions, such as: os.system、os.spawn*、os.popen*、popen2.*、commands.*
这个模块一个类:Popen。
#Popen它的构造函数如下: subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None,stderr=None, preexec_fn=None, close_fds=False, shell=False,<br> cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
# 参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。 # 如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参 # 数来指定可执行文件的路径。在windows操作系统上,Popen通过调用CreateProcess()来创 # 建子进程,CreateProcess接收一个字符串参数,如果args是序列类型,系统将会通过 # list2cmdline()函数将序列类型转换为字符串。 # # # 参数bufsize:指定缓冲。我到现在还不清楚这个参数的具体含义,望各个大牛指点。 # # 参数executable用于指定可执行程序。一般情况下我们通过args参数来设置所要运行的程序。如 # 果将参数shell设为True,executable将指定程序使用的shell。在windows平台下,默认的 # shell由COMSPEC环境变量来指定。 # # 参数stdin, stdout, stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE, # 文件描述符或文件对象,也可以设置为None,表示从父进程继承。 # # 参数preexec_fn只在Unix平台下有效,用于指定一个可执行对象(callable object),它将 # 在子进程运行之前被调用。 # # 参数Close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会 # 继承父进程的输入、输出、错误管道。我们不能将close_fds设置为True同时重定向子进程的标准 # 输入、输出与错误(stdin, stdout, stderr)。 # # 如果参数shell设为true,程序将通过shell来执行。 # # 参数cwd用于设置子进程的当前目录。 # # 参数env是字典类型,用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父 # 进程中继承。 # # 参数Universal_newlines:不同操作系统下,文本的换行符是不一样的。如:windows下 # 用’/r/n’表示换,而Linux下用’/n’。如果将此参数设置为True,Python统一把这些换行符当 # 作’/n’来处理。 # # 参数startupinfo与createionflags只在windows下用效,它们将被传递给底层的 # CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等。 parameter
简单命令:
import subprocess a=subprocess.Popen('ls')# 创建一个新的进程,与主进程不同步 print('>>>>>>>',a)#a是Popen的一个实例对象 ''' >>>>>>> <subprocess.Popen object at 0x10185f860> __init__.py __pycache__ log.py main.py ''' # subprocess.Popen('ls -l',shell=True) # subprocess.Popen(['ls','-l'])
subprocess.PIPE
在创建Popen对象时,subprocess.PIPE可以初始化stdin, stdout或stderr参数。表示与子进程通信的标准流。
import subprocess # subprocess.Popen('ls') p=subprocess.Popen('ls',stdout=subprocess.PIPE)#结果跑哪去啦? print(p.stdout.read())#这这呢:b'__pycache__\nhello.py\nok.py\nweb\n'
这是因为subprocess创建了子进程,结果本在子进程中,if 想要执行结果转到主进程中,就得需要一个管道,即 : stdout=subprocess.PIPE
subprocess.STDOUT
创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。
Popen的方法
1 Popen.poll() 2 用于检查子进程是否已经结束。设置并返回returncode属性。 3 4 Popen.wait() 5 等待子进程结束。设置并返回returncode属性。 6 7 Popen.communicate(input=None) 8 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如 果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。 9 10 Popen.send_signal(signal) 11 向子进程发送信号。 12 13 Popen.terminate() 14 停止(stop)子进程。在windows平台下,该方法将调用Windows API TerminateProcess()来结束子进程。 15 16 Popen.kill() 17 杀死子进程。 18 19 Popen.stdin 20 如果在创建Popen对象是,参数stdin被设置为PIPE,Popen.stdin将返回一个文件对象用于策子进程发送指令。否则返回None。 21 22 Popen.stdout 23 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 24 25 Popen.stderr 26 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 27 28 Popen.pid 29 获取子进程的进程ID。 30 31 Popen.returncode 32 获取进程的返回值。如果进程还没有结束,返回None。
supprocess模块的工具函数
supprocess模块提供了一些函数,方便我们用于创建进程来实现一些简单的功能。 subprocess.call(*popenargs, **kwargs) 运行命令。该函数将一直等待到子进程运行结束,并返回进程的returncode。如果子进程不需要进行交 互,就可以使用该函数来创建。 subprocess.check_call(*popenargs, **kwargs) 与subprocess.call(*popenargs, **kwargs)功能一样,只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常。在异常对象中,包 括进程的returncode信息。 check_output(*popenargs, **kwargs) 与call()方法类似,以byte string的方式返回子进程的输出,如果子进程的返回值不是0,它抛出CalledProcessError异常,这个异常中的returncode包含返回码,output属性包含已有的输出。 getstatusoutput(cmd)/getoutput(cmd) 这两个函数仅仅在Unix下可用,它们在shell中执行指定的命令cmd,前者返回(status, output),后者返回output。其中,这里的output包括子进程的stdout和stderr。
1 import subprocess 2 3 #1 4 # subprocess.call('ls',shell=True) 5 ''' 6 hello.py 7 ok.py 8 web 9 ''' 10 # data=subprocess.call('ls',shell=True) 11 # print(data) 12 ''' 13 hello.py 14 ok.py 15 web 16 ''' 17 18 #2 19 # subprocess.check_call('ls',shell=True) 20 21 ''' 22 hello.py 23 ok.py 24 web 25 ''' 26 # data=subprocess.check_call('ls',shell=True) 27 # print(data) 28 ''' 29 hello.py 30 ok.py 31 web 32 ''' 33 # 两个函数区别:只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常 34 35 36 37 #3 38 # subprocess.check_output('ls')#无结果 39 40 # data=subprocess.check_output('ls') 41 # print(data) #b'hello.py\nok.py\nweb\n' 42 43 演示
交互命令:
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
需要交互的命令示例
待续
logging模块(*****)
一 、(简单应用)
import logging
#简单的logging应用,输出到屏幕上,分为5个级别debug、info、warning、error、critical
logging.debug('debuge_message!')
logging.info('info_message!')
logging.warning('warning_message!')
logging.error('error_message!')
logging.critical('critical_message!')
"""
输出结果:
WARNING:root:warning_message!
ERROR:root:error_message!
CRITICAL:root:critical_message!
"""
# 输出结果中只输出了warning、Error、Critical级别,这是默认输出
可见,默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
二 、灵活配置日志级别,日志格式,输出位置
import logging
logging.basicConfig(
level=logging.DEBUG,
# format 定义输出格式
format='%(asctime)s [%(filename)s] [line:%(lineno)d] [%(levelname)s] %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='test.log',
filemode='w'
)
logging.debug('debuge_message!')
logging.info('info_message!')
logging.warning('warning_message!')
logging.error('error_message!')
logging.critical('critical_message!')
查看输出:
Mon, 14 May 2018 14:49:20 [logging_test.py] [line:29] [DEBUG] debuge_message! Mon, 14 May 2018 14:49:20 [logging_test.py] [line:30] [INFO] info_message! Mon, 14 May 2018 14:49:20 [logging_test.py] [line:31] [WARNING] warning_message! Mon, 14 May 2018 14:49:20 [logging_test.py] [line:32] [ERROR] error_message! Mon, 14 May 2018 14:49:20 [logging_test.py] [line:33] [CRITICAL] critical_message!
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
三 、logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
先看一个最简单的过程:
import logging
# logging.basicConfig(level=logging.DEBUG)
# logger = logging.getLogger('root')
logger = logging.getLogger()
# 创建一个handler,用于输出追加到日志文件
fh = logging.FileHandler('test1.log')
# 创建一个handler,用于输出到控制台
fs = logging.StreamHandler()
# 定义格式化输出
fmt = logging.Formatter(fmt='%(asctime)s-%(name)s-[line:%(lineno)d] [%(levelname)s] %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S')
# fmt = logging.Formatter(fmt='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 为文件输出设置格式
fh.setFormatter(fmt)
# 为文件输出设置格式
fs.setFormatter(fmt)
# 为logger对象添加fh和fs对象
logger.addHandler(fh)
logger.addHandler(fs)
logger.debug('debug_message!')
logger.info('info_message!')
logger.warning('warning_message!')
logger.error('error_message!')
logger.critical('critical_message!')
# 使用setLevel可以设置日志输出级别
logger.setLevel(logging.DEBUG)
logger.debug('debug_message!')
logger.info('info_message!')
logger.warning('warning_message!')
logger.error('error_message!')
logger.critical('critical_message!')
"""
输出结果:
Mon, 14 May 2018 15:10:02-root-[line:63] [WARNING] warning_message!
Mon, 14 May 2018 15:10:02-root-[line:64] [ERROR] error_message!
Mon, 14 May 2018 15:10:02-root-[line:65] [CRITICAL] critical_message!
Mon, 14 May 2018 15:10:02-root-[line:69] [DEBUG] debug_message!
Mon, 14 May 2018 15:10:02-root-[line:70] [INFO] info_message!
Mon, 14 May 2018 15:10:02-root-[line:71] [WARNING] warning_message!
Mon, 14 May 2018 15:10:02-root-[line:72] [ERROR] error_message!
Mon, 14 May 2018 15:10:02-root-[line:73] [CRITICAL] critical_message!
"""
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1)
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
只输出了
2014-05-06 12:54:43,222 - root - WARNING - logger warning message
2014-05-06 12:54:43,223 - root - ERROR - logger error message
2014-05-06 12:54:43,224 - root - CRITICAL - logger critical message
从这个输出可以看出logger = logging.getLogger()返回的Logger名为root。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。
(2) 如果我们再创建两个logger对象:
1 logger1 = logging.getLogger('mylogger') 2 logger1.setLevel(logging.DEBUG) 3 logger2 = logging.getLogger('mylogger') 4 logger2.setLevel(logging.INFO) 5 # # 创建一个handler,用于输出追加到日志文件 6 # fh = logging.FileHandler('test1.log') 7 # # 创建一个handler,用于输出到控制台 8 # fs = logging.StreamHandler() 9 10 # # 定义格式化输出 11 # fmt = logging.Formatter(fmt='%(asctime)s-%(name)s-[line:%(lineno)d] [%(levelname)s] %(message)s', 12 # datefmt='%a, %d %b %Y %H:%M:%S') 13 # # fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') 14 # # 为文件输出设置格式 15 # fh.setFormatter(fmt) 16 # # 为文件输出设置格式 17 # fs.setFormatter(fmt) 18 # # 为logger对象添加fh和fs对象 19 logger1.addHandler(fh) 20 logger1.addHandler(fs) 21 logger2.addHandler(fh) 22 logger2.addHandler(fs) 23 24 logger2.debug('debug_message!') 25 logger2.info('info_message!') 26 logger2.warning('warning_message!') 27 logger2.error('error_message!') 28 logger2.critical('critical_message!') 29 30 31 logger1.debug('debug_message!') 32 logger1.info('info_message!') 33 logger1.warning('warning_message!') 34 logger1.error('error_message!') 35 logger1.critical('critical_message!')
结果:

这里有两个个问题:
<1>我们明明通过logger1.setLevel(logging.DEBUG)将logger1的日志级别设置为了DEBUG,为何显示的时候没有显示出DEBUG级别的日志信息,而是从INFO级别的日志开始显示呢?
原来logger1和logger2对应的是同一个Logger实例,只要logging.getLogger(name)中名称参数name相同则返回的Logger实例就是同一个,且仅有一个,也即name与Logger实例一一对应。在logger2实例中通过logger2.setLevel(logging.INFO)设置mylogger的日志级别为logging.INFO,所以最后logger1的输出遵从了后来设置的日志级别。
<2>为什么logger1、logger2对应的每个输出分别显示两次?
这是因为我们通过logger = logging.getLogger()显示的创建了root Logger,而logger1 = logging.getLogger('mylogger')创建了root Logger的孩子(root.)mylogger,logger2同样。而孩子,孙子,重孙……既会将消息分发给他的handler进行处理也会传递给所有的祖先Logger处理。
ok,那么现在我们把
# logger.addHandler(fh)
# logger.addHandler(ch) 注释掉,我们再来看效果:

因为我们注释了logger对象显示的位置,所以才用了默认方式,即标准输出方式。因为它的父级没有设置文件显示方式,所以在这里只打印了一次。
孩子,孙子,重孙……可逐层继承来自祖先的日志级别、Handler、Filter设置,也可以通过Logger.setLevel(lel)、Logger.addHandler(hdlr)、Logger.removeHandler(hdlr)、Logger.addFilter(filt)、Logger.removeFilter(filt)。设置自己特别的日志级别、Handler、Filter。若不设置则使用继承来的值。
<3>Filter
限制只有满足过滤规则的日志才会输出。
比如我们定义了filter = logging.Filter('a.b.c'),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带 a.b.c前缀的Logger才能输出其日志。
filter = logging.Filter('mylogger')
logger.addFilter(filter)
这是只对logger这个对象进行筛选
如果想对所有的对象进行筛选,则:
filter = logging.Filter('mylogger')
fh.addFilter(filter)
ch.addFilter(filter)
这样,所有添加fh或者ch的logger对象都会进行筛选。
完整代码1
1 import logging 2 3 # logging.basicConfig(level=logging.DEBUG) 4 # logger = logging.getLogger('root') 5 logger = logging.getLogger() 6 # 创建一个handler,用于输出追加到日志文件 7 fh = logging.FileHandler('test1.log') 8 # 创建一个handler,用于输出到控制台 9 fs = logging.StreamHandler() 10 11 # 定义格式化输出 12 fmt = logging.Formatter(fmt='%(asctime)s-%(name)s-[line:%(lineno)d] [%(levelname)s] %(message)s', 13 datefmt='%a, %d %b %Y %H:%M:%S') 14 # fmt = logging.Formatter(fmt='%(asctime)s - %(name)s - %(levelname)s - %(message)s') 15 # 为文件输出设置格式 16 fh.setFormatter(fmt) 17 # 为文件输出设置格式 18 fs.setFormatter(fmt) 19 filter1 = logging.Filter('mylogger') 20 fh.addFilter(filter1) 21 fs.addFilter(filter1) 22 # 为logger对象添加fh和fs对象 23 logger.addHandler(fh) 24 logger.addHandler(fs) 25 26 # logger.debug('debug_message!') 27 # logger.info('info_message!') 28 # logger.warning('warning_message!') 29 # logger.error('error_message!') 30 # logger.critical('critical_message!') 31 32 # 使用setLevel可以设置日志输出级别 33 logger.setLevel(logging.DEBUG) 34 logger.debug('debug_message!') 35 logger.info('info_message!') 36 logger.warning('warning_message!') 37 logger.error('error_message!') 38 logger.critical('critical_message!') 39 40 """ 41 输出结果: 42 Mon, 14 May 2018 15:10:02-root-[line:63] [WARNING] warning_message! 43 Mon, 14 May 2018 15:10:02-root-[line:64] [ERROR] error_message! 44 Mon, 14 May 2018 15:10:02-root-[line:65] [CRITICAL] critical_message! 45 Mon, 14 May 2018 15:10:02-root-[line:69] [DEBUG] debug_message! 46 Mon, 14 May 2018 15:10:02-root-[line:70] [INFO] info_message! 47 Mon, 14 May 2018 15:10:02-root-[line:71] [WARNING] warning_message! 48 Mon, 14 May 2018 15:10:02-root-[line:72] [ERROR] error_message! 49 Mon, 14 May 2018 15:10:02-root-[line:73] [CRITICAL] critical_message! 50 """ 51 52 53 # import logging 54 55 # logging.basicConfig(level=logging.DEBUG) 56 # logger = logging.getLogger('root') 57 logger1 = logging.getLogger('mylogger') 58 logger1.setLevel(logging.DEBUG) 59 logger2 = logging.getLogger('mylogger') 60 logger2.setLevel(logging.INFO) 61 # # 创建一个handler,用于输出追加到日志文件 62 # fh = logging.FileHandler('test1.log') 63 # # 创建一个handler,用于输出到控制台 64 # fs = logging.StreamHandler() 65 66 # # 定义格式化输出 67 # fmt = logging.Formatter(fmt='%(asctime)s-%(name)s-[line:%(lineno)d] [%(levelname)s] %(message)s', 68 # datefmt='%a, %d %b %Y %H:%M:%S') 69 # # fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') 70 # # 为文件输出设置格式 71 # fh.setFormatter(fmt) 72 # # 为文件输出设置格式 73 # fs.setFormatter(fmt) 74 # # 为logger对象添加fh和fs对象 75 logger1.addHandler(fh) 76 logger1.addHandler(fs) 77 logger2.addHandler(fh) 78 logger2.addHandler(fs) 79 80 logger2.debug('debug_message!') 81 logger2.info('info_message!') 82 logger2.warning('warning_message!') 83 logger2.error('error_message!') 84 logger2.critical('critical_message!') 85 86 87 logger1.debug('debug_message!') 88 logger1.info('info_message!') 89 logger1.warning('warning_message!') 90 logger1.error('error_message!') 91 logger1.critical('critical_message!')
应用:
1 import os 2 import time 3 import logging 4 from config import settings 5 6 7 def get_logger(card_num, struct_time): 8 9 if struct_time.tm_mday < 23: 10 file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon, 22) 11 else: 12 file_name = "%s_%s_%d" %(struct_time.tm_year, struct_time.tm_mon+1, 22) 13 14 file_handler = logging.FileHandler( 15 os.path.join(settings.USER_DIR_FOLDER, card_num, 'record', file_name), 16 encoding='utf-8' 17 ) 18 fmt = logging.Formatter(fmt="%(asctime)s : %(message)s") 19 file_handler.setFormatter(fmt) 20 21 logger1 = logging.Logger('user_logger', level=logging.INFO) 22 logger1.addHandler(file_handler) 23 return logger1
re模块(*****)
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi')
['alvin']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \
元字符之. ^ $ * + ? { }
import re
ret = re.findall('a..in', 'helloalvin') # . 替代一个字符
print(ret) # ['alvin']
ret = re.findall('^a...n', 'alvinhelloman') # ^表示开头匹配
print(ret) # ['alvin']
ret = re.findall('a...n$', 'testalesn') # $表示末尾匹配
print(ret) # ['alesn']
ret = re.findall('abc*', 'abcccc') # *贪婪匹配【0,+00】,*为前一个字符0-无穷个
print(ret) # ['abcccc']
ret = re.findall('abc*', 'ab') # *贪婪匹配【0,+00】,*为前一个字符0-无穷个
print(ret) # ['ab']
ret = re.findall('abc+', 'abcccc') # +贪婪匹配【1,+00】,+为前一个字符1-无穷个
print(ret) # ['abcccc']
ret = re.findall('abc+', 'ab') # +贪婪匹配【1,+00】,+为前一个字符1-无穷个
print(ret) # []
ret = re.findall('abc?', 'abcccc') # [0,1],?匹配0或1个
print(ret) # ['abc']
ret = re.findall('abc?', 'ab')
print(ret) # ['ab']
ret = re.findall('abc{1,4}', 'abccccccc') # 贪婪匹配,匹配最多个
print(ret) # ['abcccc']
ret = re.findall('abc{1,4}', 'abcc') # 贪婪匹配,匹配最多个
print(ret) # ['abcc']
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
import re
ret = re.findall('abc*?', 'abcccc') # 加上?号后变成惰性匹配,匹配最少个
print(ret) # ['ab']
ret = re.findall('abc+?', 'abcccc') # 加上?号后变成惰性匹配,匹配最少个
print(ret) # ['abc']
元字符之字符集[]:
import re
# ----------------------------字符集[]
ret = re.findall('a[bc]d', 'acd') # [bc] 任一字符匹配
print(ret) # ['acd']
ret = re.findall('a[a-z]d', 'acdaxdafdadd')
print(ret) # ['acd', 'axd', 'afd', 'add']
ret = re.findall('[a-zA-Z0-9]d', 'Adfa1d1xd')
print(ret) # ['Ad', '1d', 'xd']
ret = re.findall('d[a-zA-Z0-9]?', 'dfa1d1xd')
print(ret) # ['df', 'd1', 'd']
ret = re.findall('[.*+]', 'a.cd+') # . +*在字符集[]中无特殊功能
print(ret) # ['.', '+']
ret = re.findall('[.*+]', '*a.cd+') # . +*在字符集[]中无特殊功能
print(ret) # ['*', '.', '+']
"""
#在字符集中有特殊功能的符合:
- :表示范围
^ :取反
\ : 转义
"""
ret = re.findall('[1-9]', '45dfa3')
print(ret) # ['4', '5', '3']
ret = re.findall('[1-9]+', '45dfa3')
print(ret) # ['45', '3']
ret = re.findall('[^ab]+', '45dfa3')
print(ret) # ['45df','3']
ret = re.findall('[\d]+', '45dfa3')
print(ret) # ['45','3']
元字符之转义符\
1 """ 2 反斜杠后边跟元字符去除特殊功能,比如\. 3 反斜杠后边跟普通字符实现特殊功能,比如\d 4 5 \d 匹配任何十进制数;它相当于类 [0-9]。 6 \D 匹配任何非数字字符;它相当于类 [^0-9]。 7 \s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。 8 \S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。 9 \w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 10 \W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] 11 \b 匹配一个特殊字符边界,比如空格 ,&,#等 12 """
import re
ret = re.findall('\d', '213df543sax22')
print(ret) # ['2', '1', '3', '5', '4', '3', '2', '2']
ret = re.findall('\d*', '213df543sax22')
print(ret) # ['213', '', '', '543', '', '', '', '22', '']
ret = re.findall('\d+', '213df543sax22')
print(ret) # ['213', '543', '22']
ret = re.findall('\D+', '213df543sax22')
print(ret) # ['df', 'sax']
ret = re.findall('\s', '\ta\n\r \f\v')
print(ret) # ['\t', '\n', '\r', ' ', '\x0c', '\x0b']
ret = re.findall('\s+', ' \ta\n\r \f\v')
print(ret) # ['\t', '\n\r \x0c\x0b']
ret = re.findall('\S+', '\ta\n\r\f\v')
print(ret) # ['a']
ret = re.findall('\w+', 'asdf*dsfas_\sadf')
print(ret) # ['asdf', 'dsfas_', 'sadf']
ret = re.findall('\W+', 'asdf*dsfas_\sadf')
print(ret) # ['*', '\\']
ret = re.findall('I\b', 'I am LIST')
print(ret) #[]
ret = re.findall(r'I\b', 'I am LIST')
print(ret) #['I']
ret = re.findall('I\\b', 'I# am LIST')
print(ret) #['I']
现在我们聊一聊\,先看下面两个匹配:
ret = re.findall('c\\\\l', 'abc\le')
print(ret) # ['c\\l']
ret = re.findall(r'c\\l', 'abc\le')
print(ret) # ['c\\l']
# -----------------------------eg2:
# 之所以选择\b是因为\b在ASCII表中是有意义的
ret = re.findall('\bblow', 'blow')
print(ret) # []
ret = re.findall(r'\bblow', 'blow')
print(ret) # ['blow']

元字符之分组()
import re
# 分组模糊匹配优先输出组内内容,如果想全部输出需要在括号内加?: ,
# 也即是(?:str)
m = re.findall(r'(ad)+', 'adad')
print(m)
m = re.findall(r'(?:ad)+', 'adadad')
print(m)
# re.search(): 固定格式进行分组搜索,只匹配第一个搜索到的结果,返回一个对象,通过group获取对象内容
ret = re.search("(?P<name>[a-z]+)\d+", 'alex36wusir34xialv33')
print(ret.group(0)) # alex36
print(ret.group(1)) # alex
print(ret.group('name')) # alex 等价于group(1)
print(ret.group()) # alex36 等价于group()
ret = re.search("(?P<name>[a-z]+)(?P<age>\d+)", 'alex36wusir34xialv33')
print(ret.group(0)) # alex36
print(ret.group(1)) # alex
print(ret.group(2)) # 36
print(ret.group()) # alex36
print(ret.group('name')) # alex
print(ret.group('age')) # '36'
元字符之|
ret = re.search('(ab)|\d', 'rabhdg8sd')
print(ret.group()) # ab
re模块下的常用方法
import re
# findall() 返回所有满足匹配条件的结果,放在列表里
res = re.findall('a', 'alvin yuan')
print(res) # ['a', 'a']
# search() 函数会在字符串内查找模式匹配,直到找到第一个匹配后返回一个包含匹配信息的对象
# 该对象可以通过group()方法得到匹配的字符串,如果没有找到匹配的字符串返回None
res = re.search('\d+', 'tset123faster23') # 123
print(res.group())
res = re.search('\d', 'tsetfaster')
"""
print(res.group())
AttributeError: 'NoneType' object has no attribute 'group'
"""
print(res) # None
# re.match() ,与search功能类似,但是仅在字符串开始处进行匹配
# 相当于在search的匹配规则中加入了^功能
res = re.match('a', 'abc')
print(res) # <_sre.SRE_Match object; span=(0, 1), match='a'>
print(res.group()) # a
res = re.match('a', 'bac')
print(res) # None
# re.sub()进行字符串模糊匹配后替换,参数1:匹配规则、参数2:替换对象、参数3:被处理的字符串对象、参数4:替换次数
# 默认情况下会替换所有匹配成功的字符
res = re.sub('\d', 'abc', 'alvin5yuan6', 1)
print(res) # alvinabcyuan6
res = re.sub('\d', 'abc', 'alvin5yuan6')
print(res) # alvinabcyuanabc
# re.compile() 对匹配正则进行编译
obj = re.compile('\d{3}')
res = obj.findall('tes123test2345')
print(res) # ['123', '234']
res = obj.search('tes123test2345')
print(res.group()) # 123
res = re.search(obj, 'tes123test2345')
print(res.group()) # 123
# re.finditer() 返回一个可迭代的对象
res = re.finditer('\d', 'fs1sdf234f5s6')
print(res) # <callable_iterator object at 0x000001A89E649438>
print(res.__next__().group()) # 1
print(next(res).group()) # 2
print(next(res).group()) # 3
print(next(res).group()) # 4
补充:
import re
print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>"))
print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>"))
补充2:
#匹配出所有的整数
import re
#ret=re.findall(r"\d+{0}]","1-2*(60+(-40.35/5)-(-4*3))")
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove("")
print(ret)
参考链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号