面向对象第一单元博客作业
面向对象第一单元总结博客
经历过三周的OO学习经历,下面我想分享一下我关于第一单元作业的设计架构和心得体会。
PART ONE 架构相关(UML类图与耦合度分析)
第一次作业
UML类图
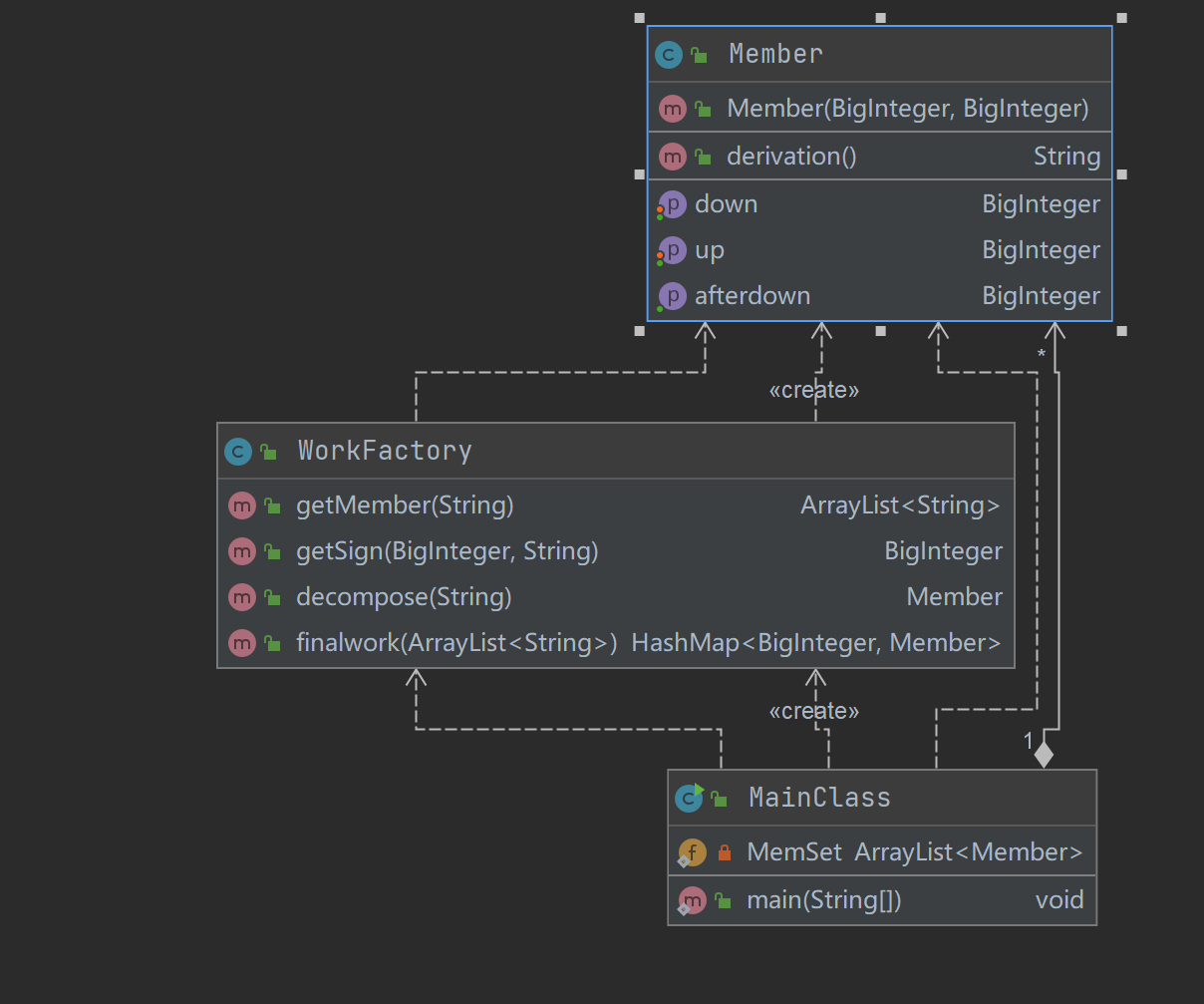
以上使用IDEA自带的工具画出的 UML 类图,可以直观地看到第一次作业我大概开了三个类分成了,主类,处理字符串的类和主类,注意到我并没有开一个表达式类来存放表达式,而是直接在主类中开了一个 Term 的 Arraylist 来表示表达式。可以说,整个过程是十分面向过程的……但是由于题目比较简单,所以影响不是很大。
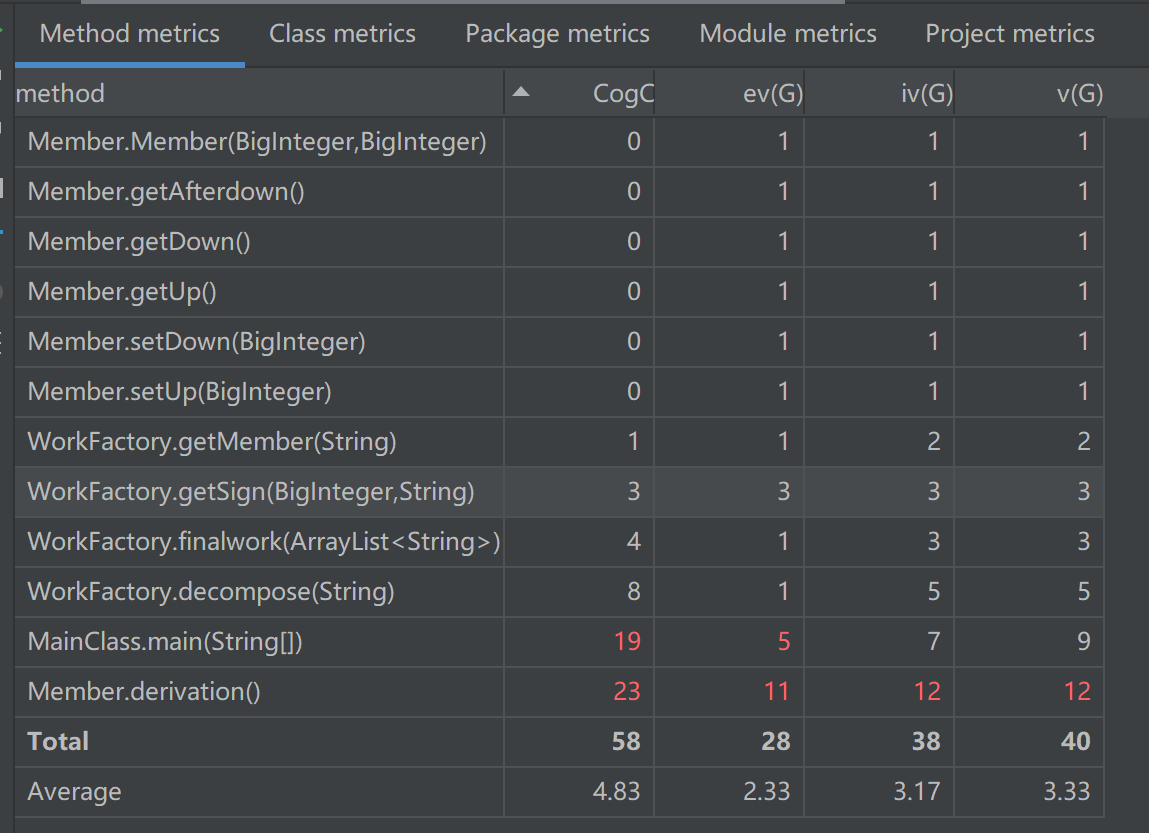
Method metrics
Class metrics
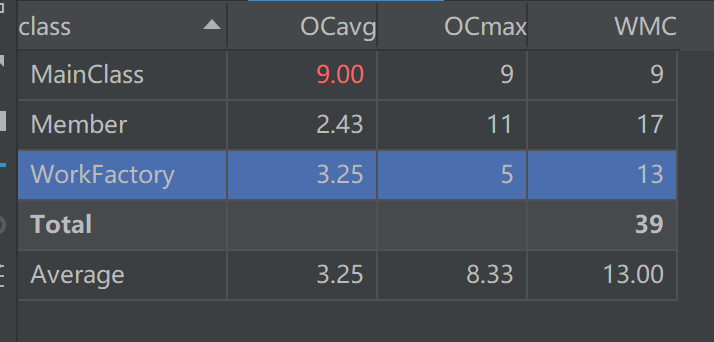
可以发现大致复杂度全出在 Member(项)方法的求导函数和主函数中。实际上,这两个地方由于也第一次写OO意识不够,很多地方就直接用一种面向过程的方法是实现了,将方法当函数用,导致部分复杂度过高。
第二次作业
UML类图

这个图相比于第一次几乎是膨胀了2倍,为什么呢,这就不得不谈到我本次十分鲁莽的架构了。第二次作业为表达式的形式添加了括号。为了解决这个问题,我采用了一个循环嵌套式的架构。我先设计了所有的因子类—— cos 类,sin类,幂函数类,之后设计了项类,根据定义,项由许多 cos 项和 sin 项,幂函数项以及系数组成,所以我利用不同的 Arraylist 表示这些因子,这也是我觉得这个设计最失败的地方,后面说遗憾的时候还会说。
除此之外,为了尽量降低第三次作业的工作量,我在这次作业中也实现了嵌套函数的求导方法,因为我觉得,括号嵌套的模式和函数嵌套的模式实现起来其实把并没有太大的区别。我做的主要的设计是在 sin 和 cos 类中添加一个表达式类型的元素,求导时再次调用表达式求导的方法,由于最后表达式一定会递归到幂函数或者常数,所以递归不会出现找不到终点而爆栈。
Class Metrics
可以发现许多地方耦合度是相当高的,主要问题还是出在一些特殊处理比较多的地方,比如 toString(),equals()。这些函数中我为了尽量降低字符串的长度加了大量特判。
第三次作业
UML类图
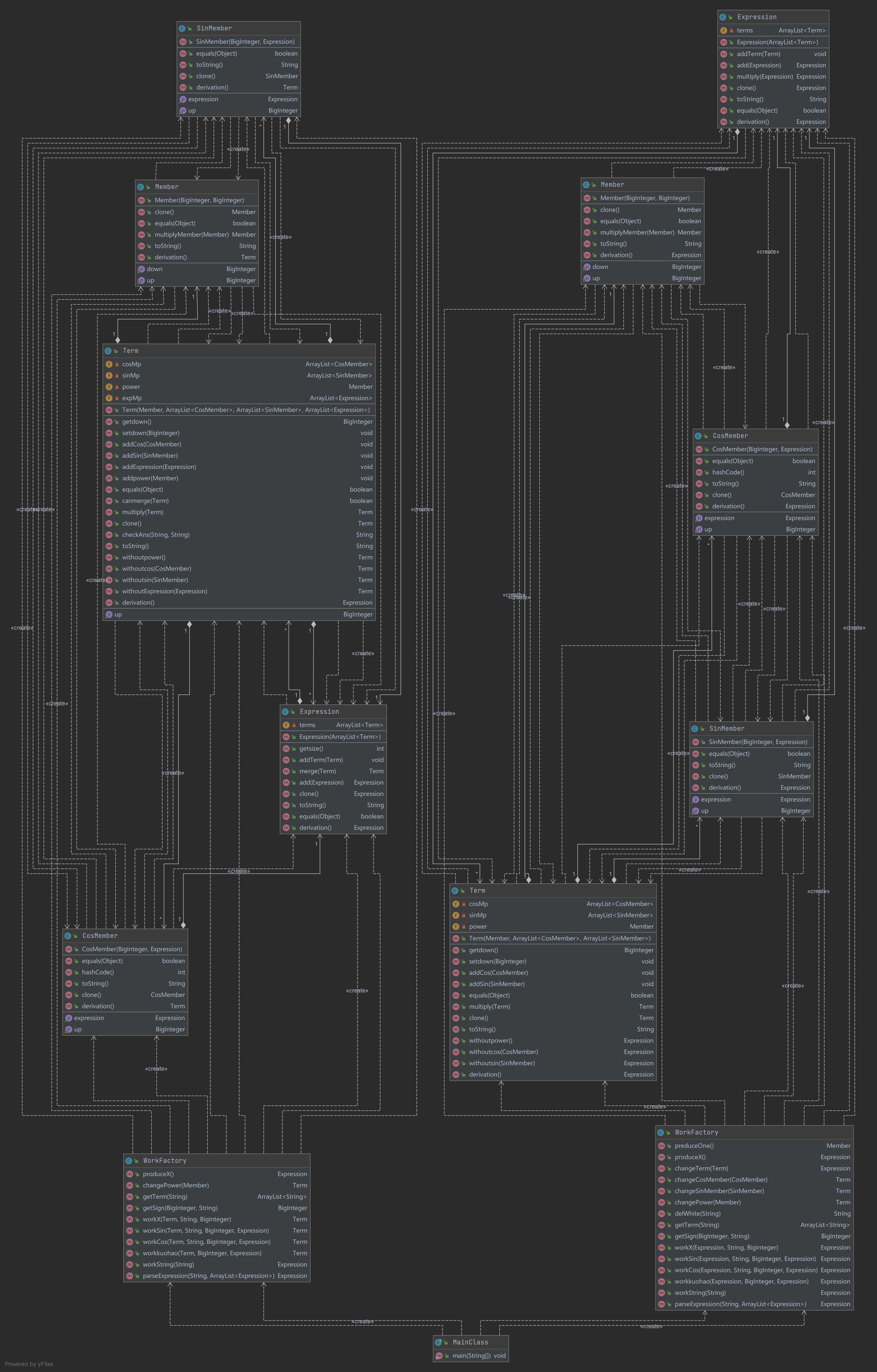
是不是更加可怕了(x),鉴于第二次作业没有出bug,所以尽管有简化代码的想法但最后还是没有去实践,只是在原先的基础上另开了一个类用于检查格式是否正确,还有开了一个异常处理类用于抛出异常。
整体上还是采用了两种架构跑之后比输出长度的思路,因为第三次加的功能第二次的架构完全能够支持,所以我并没有改动了太多,但是为了符合定义的情况下,获得较好的性能分做了很多的输出优化,改动了大部分类的 toString() 方法。
Class Metrics
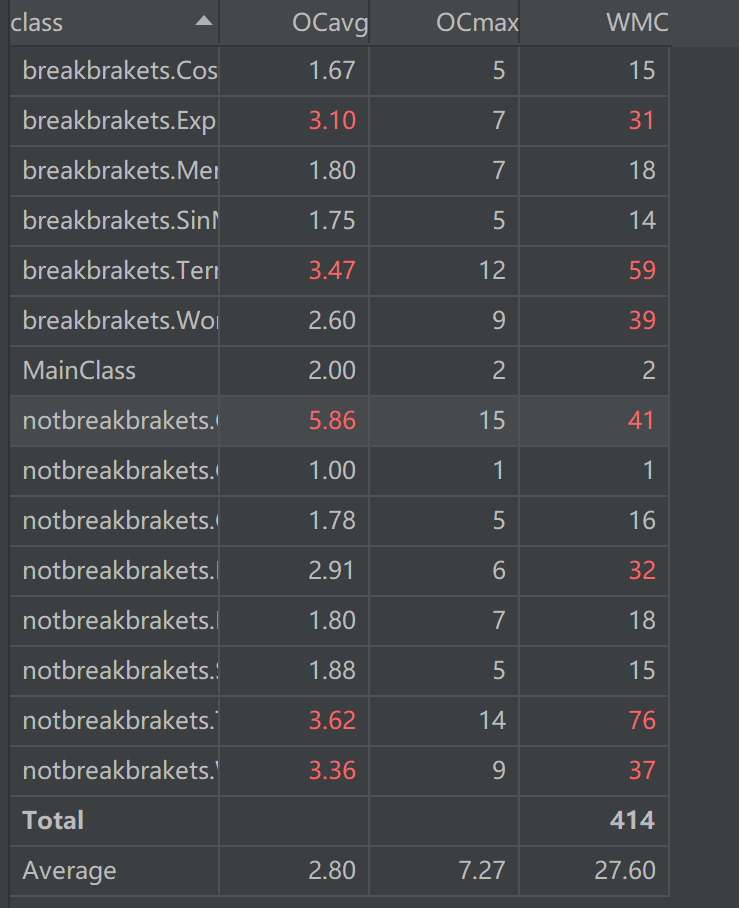
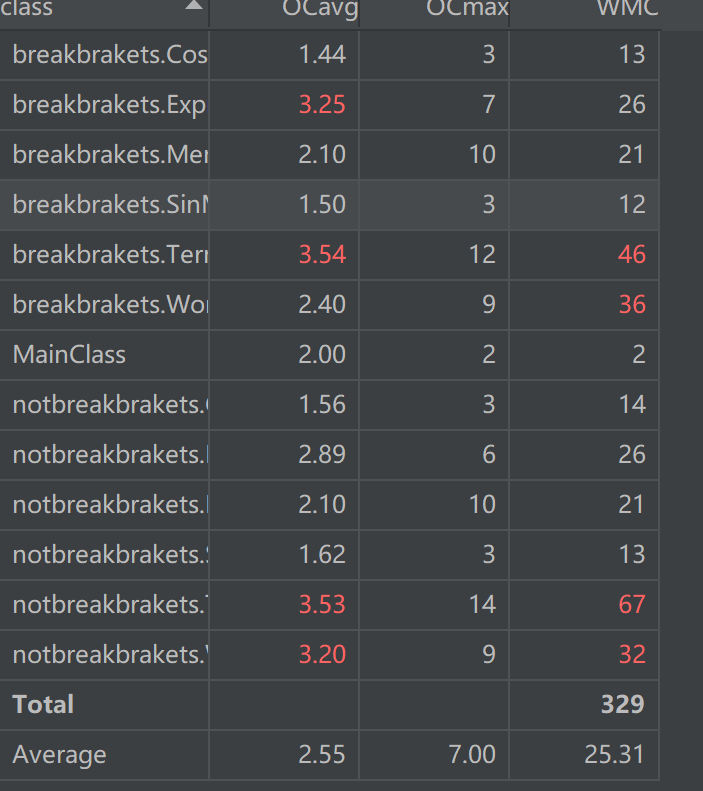
emmm……,真惨(,循环复杂度高,大概是因为我用的所有的容器都是 Arraylist 吧,基本所有操作都是循环完成的,复杂度轻轻松松冲上 \(O(n^2)\) ,此外由于并没有用层次结构,存在一些暴力枚举和暴力判断。其实本来还觉得自己写的不错,但是看了这个分析,我发现我写的万一原来是垃圾,希望以后的作业中能尽量写出一些漂亮的架构。
PART TWO 设计与算法相关
第一次作业
第一次作业的总体需要达到的目标是实现简单只含有幂函数的表达式的求导,乍一看这应该是一个很简单的事情,在学习程序设计和数据结构的时候就写过类似的程序。但是题目给出的是一个经过重定义的表达式模型,这就对我们需求分析的能力提出了挑战。经过一段时间的分析后,我大概将本次实现本次作业的流程分为三个部分,解析字符串,对表达式求导和输出表达式,在第一单元的以后几次作业中我一直沿用这样的实现流程,由于要求比较直接,所以也不需要太复杂的流程。
对于第一个流程解析字符串,对于本次作业来说难度主要是构造出正则表达式,并将信息提取。一开始由于对于正则表达式不够熟悉,所以和室友讨论了很久才设计成功,最终得到了一个十分冗长的表达式
(?<member>[+-]?([+-]?([+-]?((\\d+)|(x(\\*\\*[+-]?\\d+)?))\\*)*[+-]?((\\d+)|(x(\\*\\*[+-]?\\d+)?))))
上述表达式是不包括空格的,目标是捕获出所有的“项”,所以我在进行匹配之前先去除了所有的空格。之后又 通过\(\text{java matcher}\) 类中的 \(\text {group}\) 方法捕获每个项对应参数,并对乘积形式的项进行合并指数。
对于第二个流程,这里就需要谈谈我的类的设计架构,说实话,由于做第一次作业时候对于面向对象的思想了解不够,对整体架构的设计不是很明智,基本上只是分成了三个类,主类,项类和处理字符串类。项类(Member)支持查询指数和系数,以及输出求导之后的字符串,然后我直接在主类中用一个 \(\text {ArrayList<Member>}\) 来表示一个表达式,实现求导。
对于第三个流程,在我目前的架构下,其实就是对容器中的项分别求导然后进行拼接问题。
关于优化
第一次的输出优化是可以达到极致的,我注意到了许多可以优化的地方,包括合并同类项,将 \(x**2\) 转化为 \(x*x\) ,以及将正系数的项放在第一个,这样可以少输出一个符号等,我也确实都做了。这些也基本是一些简单的模拟,非常好实现。
关于自己的bug
这次出了两个bug,一个是书写 toString 函数时出现了笔误,将指数写成系数,不过由于是在一个特判中的错误,被测出来的可能很小,所以真的很佩服 hack 掉我的同学……
另一个直接导致我强侧一个点挂掉了……在输出优化时未考虑到项出现多个零的情况,导致有时候会不输出 0。
这两个都是很细节的 bug 所以改完前后代码行和圈复杂度几乎没有变化。
关于他人的bug
这次我找到了别人的一个 bug。由于最开始阅读代码时并没有看出 bug,所以之后我直接使用 python 评测机来自动生成数据来测试,最后发现了一位同学在一种情况下对于 x 的求导还是 x,于是我就把他 hack 掉了。
第二次作业
这次作业应该是三次作业中最完美的一次了,但是也经历了漫长的思考,设计,码代码和测试并优化的过程。
第二次作业的要求中在原先的幂函数求导的要求上另加了对三角函数的求导过程,并附加了括号的嵌套,这就给整个表达式的呈现方式提供了很大的灵活性。好在指导书上给出了目标表达式的形式化表述,从逻辑上固定了表达式的形式,而且不存在不合法的表达式,也就是说一定可以使用正则表达式将式子表示出来,这样一定程度上降低了解析表达式的难度。
对于解析表达式,根据上述的分析。由于表达式形式被严格定义完成,所以可以沿用上述的方式用正则表达式去严格解析,但是,括号的出现给解析带来了很大的难度,因为表达式和项都是递归定义的!经过与室友的一番讨论,我最终确定了如下的解析算法。注意到,任意表达式都能写成:
如果我们将所有括号中的表达式都去掉,就会得到如下的结果:
而这样的形式,就能设计合适的正则表达式去描述,这里我不再展示我当初写出来的正则表达式(因为又臭又长),在第三次作业我再重点说一种合适的构造正则表达式的方式。按照第一部分所设计出的架构,可以将上述连续乘积形式的每一部分对应到一个固定的因子类,分别进行处理,然后整体得到一个项类,最后将项类组成一个表达式类。这样这样一个表达式就处理成我们想要的样子了。
但是括号里的东西就不要了嘛?当然不是,可以发现,括号里的东西也是一个表达式啊,所以可以重复上述操作就好了啊,编程中什么样的结构形式支持这种反复调用自己的需求呢,当然是递归,怎么递归?对表达式预处理啊,每次都将第一层括号拆开,将括号中的表达式都存在一个数组中,同时删去这一部分。上述过程不就是我们非常熟悉的括号匹配问题嘛?实现它的方法在数据结构课程中就已经教授了,这里不再赘述。每次先递归处理括号内的表达式再处理当前表达式,这就是一个递归的过程。那么递归的终点是什么?就像前面介绍架构说的,循环嵌套的模式,不会达不到重点,在本次作业的终点就是表达式 \(x\) ,且如果实现形式没有问题,是一定可以达到这个终点的。
到此为止,我们基本就可以将表达式从字符串形式转化成我们想要的形式了。之后再调用表达式类的求导的方法便可以得到答案了。
再谈谈求导的实现思路,首先有这样的一个公式
也就是说对于乘积的导函数,可以分别对每一项求导,其它不变。对于表达式求导,可以分别求导然后将结果加起来。
既然都设计了这样的循环嵌套的结构,不如把第三次的一部分也写了,抱着这样的想法,我也实现了嵌套函数的求导,其实也就是 \(sin(f(x))\) 和 \(cos(f(x))\) 的求导,其实实现起来很简单,因为
其实调用一下表示求导,以及将 \(sin\) 类换成 \(cos\) 类,或者相反就行了……,对于不拆括号的版本和拆括号的版本都很好实现。
关于优化
输出优化,合并同类项等,思维难度和实现难度都不大,不多赘述。
前面说过,为了使结果尽可能的短,我实际上实现了两种求导的方式。最初我的想法是,在预处理字符串时候将符号全部拆开来,并合并同类项,最终得到的表达式就不包含任何括号,然后直接进行求导,这种方法得到的结果,由于没有括号的嵌套,有时候会十分的长,而想要进一步优化,只能写合并同类项的方法,实现困难且容易出错。那么怎么做到尽量合并同类项呢,注意到表达式中就存在括号相乘,我为什么一定要拆开呢?于是这就产生了我的第二个架构,不拆括号版本。具体架构上面已经说过,细节实现上与拆括号版本没有太多的区别,只是不再增加表达式相乘的模块,将括号表达式看作一个因子放入项类中。解析表达式和求导方式类似,只是不赘述。
最终我将两个求导方式放入两个包中,取最优结果输出。
关于DEBUG
对于第二次作业,在测试过程中,出了一个令我 de 了很时间的 bug ,就是对于不拆括号的版本中,由于我为了使得结果尽可能的精简,做了很多的特判,导致由于反复调用\(toString()\) 方法,导致递归层数指数式增涨,最终导致对于某些样例复杂度过高而运行超时。对于同一个情况下只需要记忆化递归后的结果然后做出判断即可,不需要反复递归。
这次debug的经历也提醒我了,记忆化对搜索这样很容易就复杂度爆炸的算法能起到很大很大的简化,当然类似的算法还有剪枝等,只不过这里并用不着。
自己的bug
本次作业并没有出 bug ~
他人的bug
本次互测中,在阅读了一位同学的代码后,发现它无法处理常熟求导(这不是样例嘛喂(#`O′)),然后就构造了样例把他 hack 掉了,其他几位同学看代码并没有看出明显的 bug,于是还是用评测机跑,最终又hack掉了一位同学,分析它的代码后,发现他(她)的代码无法处理三个符号的情况,于是我又干掉了这位同学。
第三次作业
本单元最后一次作业,相较于第二次多了一个三角函数中允许嵌套表达式的模式,以及一个检查格式是否正确的功能。
对于第一个功能,其实上次我已经实现了,所以这次作业压力很小,相当于只要按照要求调格式和实现检查格式功能即可。实际上,这次作业写码部分并没有花我很多时间,反倒是因为一些新加的细节 \(\text {de}\) 了很多 \(\text{bug}\)…… ,嵌套的实现前面已说过,不再赘述,这次作业最大的两个问题是格式判断和输出优化。
关于格式判断
如何指明错误的表达式?有个很朴素的想法,用正确的正则表达式来捕获它,如果得到的表达式是和原表达式没有差别的,那么就是正确的表达式,否则就是错误的表达式。
所以设计好一个正则表达式很重要。然而第三次作业的表达式形式相当的复杂,不是很容易就能表示出来的形式,那怎么办?注意到,我们有形式化定义!形式化定义其实就是正则表达式!所以按照形式化定义的写法一步步递进即可。
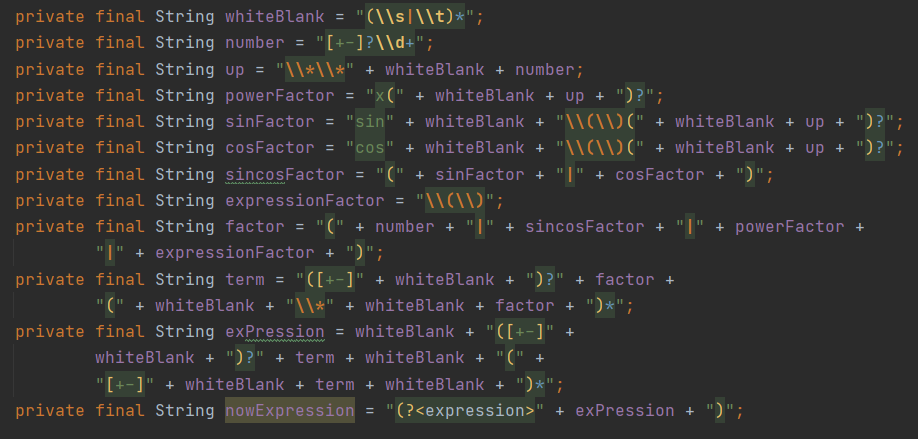
所以课程组给我们的指导书还是很良心的……
判断格式的流程如下:
- 先对所有括号进行匹配,如果括号无法匹配,直接抛出异常
- 去除表达式前后的空格,之后判断表达式是否为空,如果为空,直接抛出异常。
- 做括号匹配,同之前的一样,提取括号中的表达式,之后对处理后的串做匹配。这里需要注意一下,这里表达式需要分为三角函数中的表达式和不同的表达式,可以用一个参数 id 来表示,如果是三角函数中的表达式,需要特殊判断它是否是一个因子。
- 如果表达式合法,解析表达式,判断当前表达式中每一对括号的归属,也就是计算 id,然后对从括号中提取的表达式进行递归判断。
中间其实涉及到了很多细节,我就因为一个细节没有注意到(对空串的判断),导致最终错了一个测试点……
关于优化
首先是输出优化,题目中规定了,三角函数中只能嵌套因子,因此,在很多地方需要补充添加一些括号。但是为了尽量缩短结果,我选则加了一个方法判断当前 项/表达式是否是一个因子,这样可以少加一个 \(()\)。
其次是方法优化,其实我沿用了之前的架构,从不拆括号和拆括号的两种情况中选择一个最短情况输出。
关于自己的bug
这次其实也存在有两个bug,一个被测出来了,一个到最后也没有被发现。
第一个 bug 是被发现了,强测也为此付出了代价。我在去除空格的那里,在while循环语句中,将边界判断放在了对值的判断之后,导致执行判断语句时先执行前面的语句就会导致数组访问越界,该换一下判断顺序就行了。这样一个比较基本的bug,甚至在写c语言是就很容易犯的bug,都没有测出来实在是我的失误。
第二个 bug 是审题失误,没有看到 \(0^0 = 1\),但是最后课程组并没有测试这个点,强测这个点也被ban掉了,所以逃过一劫……
关于他人的bug
这次由于互测限制实在是太多导致到最后都没有谁 hack 谁成功了…… 但是我找出很多同学的对于 WF 的判断有很大的问题。比如一位同学对于诸如 \(sin(+x)\) 这样的样例都没有判成 WF ,但是我始终无法进行hack,这我认为是十分遗憾的,这次我依旧使用python的自动评测机来对它们的代码进行测试。
PART THREE 心得和体会
一些收获
在做这次作业之前,我也写了 pre 的作业,在写 pre 之前,我对面向对象的设计方法完全不了解,甚至在写完pre时,我脑中对于面向对象的方法也十分模糊。可能是因为之前我并没有写过 java 语言的程序,在 pre 中熟悉 java的语法就耗尽了我的全部精力吧……
在第一次作业中,尽管想尝试这用一些面向对象的方法,但最后写着写着又不自觉地用一种 “四不像”的方法实现了。但是通过设计和使用 “项“ 类,我还是对”对象“这样一个存在获得了更深的理解。
第二三次作业由于复杂度的飙升,面向对象的方法相较于面向过程的优势被凸显出来,通过构造出因子类,项类,表达式类,分别实现他们的 clone(),toString(),derivative() 方法,整个复杂的问题就被分解为每个对象负责的一个又一个小问题,最终只需要调用表达式类一个简单的方法就可以将问题成功解决。将问题分解为每个对象起的作用,而不是每一步要干些什么,这样一种设计方式极大的简化了求导的过程和写代码的难度。除此之外,面向对象方法给代码提供了很强的可维护性,我在写完第一个拆括号的方法后,没花多长时间就将不拆括号的版写出来了,因为很多类起到的作用是相差无几的。总之,通过这两次作业我切实体会到了面向对象的魅力。
一些遗憾
三次作业只有一次获得了满分,虽然几乎每次作业在性能分上几乎都拿满了,但除了第二次其他两次都不同程度上出了一些细节上的 bug,一方面说明了我在写代码时不够专心,同时也反应了很多时候我没有考虑足够全面就开始了码代码,导致很多时候就注意不到一些足以致命的细节,也许这就是程序猿之痛吧。回过头来看,其实性能分确实不占多少分(因为每次都发现性能分几乎都是99.99……这样的数字),反倒出现错误损失更大,所以这几次真是捡了芝麻丢了西瓜。
虽说三次作业都没有出现毁灭性的架构问题,但这不代表我在这三次的作业的架构没有任何问题。对于第一次作业来说,我之前也说过,写了一个四不像的架构,几乎是面向过程完成的,就不说了。对于后面两次作业,我写了两个版本,其中其实很多都是复制粘贴的,这样的设计虽然第二第三次作业中没有在这里出现问题,但是事后想想,我觉得这样还是十分危险的,每次出现问题都需要维护两个版本,很容易出错。下面列出了我思考的几个可以改善的方向。
- 取消愚蠢的 “双版本” 模式,将两种版本融合,实际上,可以直接在 “项” 类和 "表达式" 类中开一种方法表示拆括号的情况,解析表达式,求导等步骤之前都采用不拆括号的模式处理,之后再判断得到的结果查括号更短还是不拆括号更短。
- 开一个抽象类表示因子维护,指数 ,获取指数,展示指数,clone,toString ,derivative 等方法,其它四类因子继承这个抽象类,这样就方便 ”项“ 类统一管理,相较于我现在的版本可以减少很多码量。
OO第一次作业结束了,太tm过瘾了,期待可以在以后的OO学习中加深对面向对象方法的理解,提升我的写代码能力,成为一个更加成熟的程序猿。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号