大规模数据分析统一引擎Spark最新版本3.3.0入门实战
 本篇先了解Spark和Hadoop的关系与区别,进一步了解特性和相关组件架构;通过实战部署了Spark最新版本3.3.0的Local、Standalone+历史服务+HA、Yarn的部署完成操作步骤,并通过不同提交方式的示例和WebUI查看加深多Spark多种作业提交原理的理解,并拉开了使用Spark-Shell方式提交本地、集群、yarn交互式使用之门。
本篇先了解Spark和Hadoop的关系与区别,进一步了解特性和相关组件架构;通过实战部署了Spark最新版本3.3.0的Local、Standalone+历史服务+HA、Yarn的部署完成操作步骤,并通过不同提交方式的示例和WebUI查看加深多Spark多种作业提交原理的理解,并拉开了使用Spark-Shell方式提交本地、集群、yarn交互式使用之门。
@
概述
定义
Spark 官网 https://spark.apache.org/
Spark 官网最新文档文档 https://spark.apache.org/docs/latest/
Spark GitHub源码地址 https://github.com/search?q=spark
Apache Spark™是一个开源的、分布式、多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习,用于大规模数据分析的统一引擎。目前最新版本为3.3.0
- Spark是用于大规模数据处理的统一分析引擎,也可以说是目前用于可伸缩计算的最广泛的引擎,成千上万的公司包括财富500强中的80%都在使用。
- Spark生态系统集成了丰富的数据科学、机器学习、SQL分析和BI、存储和基础设施等框架,并将这个生态使用可以扩展到数千台机器大规模数据使用。
- Spark提供了Java、Scala、Python和R的高级api,以及支持通用执行图的优化引擎。
- Spark支持一系列丰富的高级工具,包括用于SQL和结构化数据处理的Spark SQL,用于pandas工作负载的Spark上的pandas API,用于机器学习的MLlib,用于图形处理的GraphX,以及用于增量计算和流处理的Structured Streaming。
Hadoop与Spark的关系与区别
- 框架比较
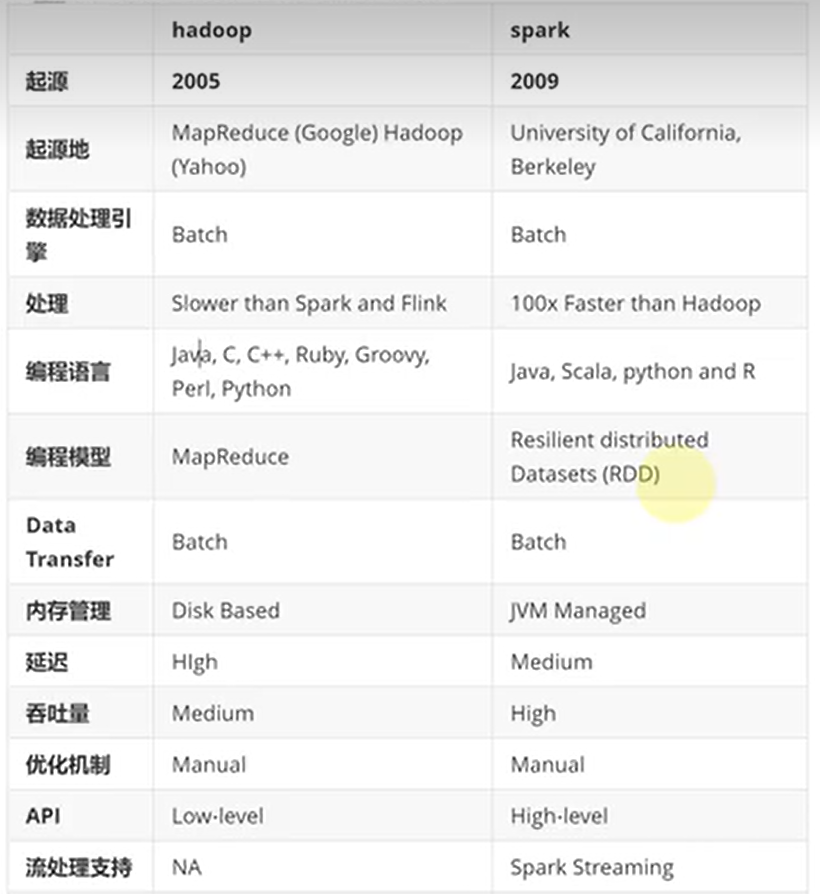
- 处理流程比较
-
spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别:
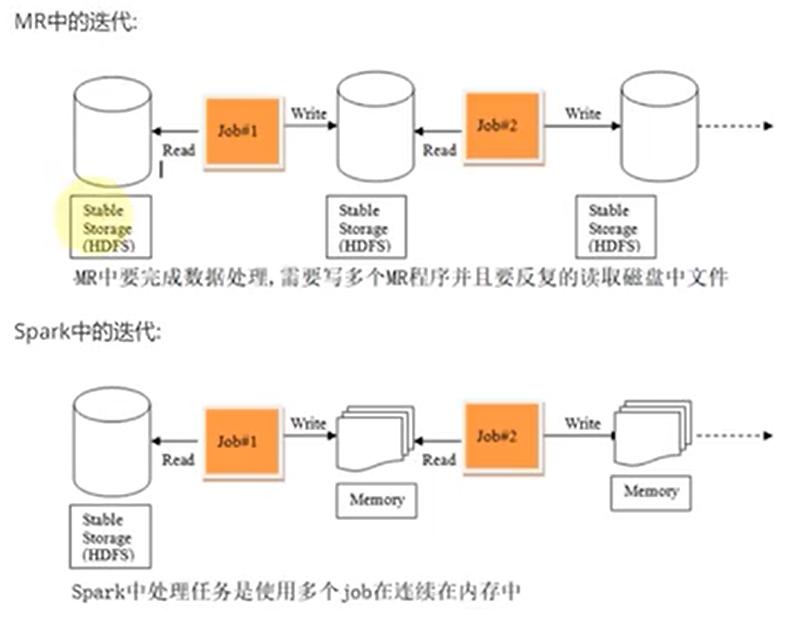
- spark把运算的中间数据(shuffle阶段产生的数据)存放在内存,迭代计算效率更高,mapreduce的中间结果需要落地,保存到磁盘;
- Spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性的数据集,这些集合石弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,mapreduce的容错只能重新计算;
- Spark更通用,提供了transformation和action这两大类的多功能api,另外还有流式处理sparkstreaming模块、图计算等等,mapreduce只提供了map和reduce两种操作,流计算及其他的模块支持比较缺乏;
- Spark框架和生态更为复杂,有RDD,血缘lineage、执行时的有向无环图DAG,stage划分等,很多时候spark作业都需要根据不同业务场景的需要进行调优以达到性能要求,mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,运行较为稳定,适合长期后台运行;
- Spark计算框架对内存的利用和运行的并行度比mapreduce高,Spark运行容器为executor,内部ThreadPool中线程运行一个Task,mapreduce在线程内部运行container,container容器分类为MapTask和ReduceTask。Spark程序运行并行度高;
- Spark对于executor的优化,在JVM虚拟机的基础上对内存弹性利用:storage memory与Execution memory的弹性扩容,使得内存利用效率更高;
-
特点与关键特性
Spark官网对其特点高度概括的四个单词分为为:Simple-简单、Fast-快、Scalable-可扩展、Unified-统一。
- 运行速度快。Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍。
- 简单易使用。Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程。
- 统一通用性。Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算。
- 运行模式多样。Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark关键特性包括:
- 批/流媒体数据:使用多种语言:Python、SQL、Scala、Java或R来统一批量和实时流处理数据。
- SQL分析:为仪表板和特别报告执行快速的分布式ANSI SQL查询。运行速度比大多数数据仓库都快。
- 大规模数据科学:对pb级数据进行探索性数据分析(EDA),而不需要进行降采样。
- 机器学习:在笔记本电脑上训练机器学习算法,并使用相同的代码来扩展到由数千台机器组成的容错集群。
组件

- Spark Core:为Spark的核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed Datasets,RDD)的API定义,RDD是只读的分区记录的集合,只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建;为其他 Spark 功能模块提供了核心层的支撑,可类比 Spring 框架中的 Spring Core。
- Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、 HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD在处理结构化数据时,开发人员无须编写 MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。Spark SQL 适用于结构化表和非结构化数据的查询,并且可以在运行时自适配执行计划,支持 ANSI SQL(即标准的结构化查询语言)。
- Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core进行快速处理。Spark Streaming支持多种数据源,如 Kafka以及TCP套接字等。最为使用DStreams处理数据流的老的API。
- Structured Streaming:使用关系查询处理结构化数据流(使用数据集和DataFrames,比DStreams更新的API);是从 spark2.0 开始引入了一套新的流式计算模型,基于 Spark SQl 引擎具有弹性和容错的流式处理引擎. 使用 Structure Streaming 处理流式计算的方式和使用批处理计算静态数据(表中的数据)的方式是一样的。
- MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
- GraphX: Spark提供的分布式图处理框架,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
集群概述
Spark应用程序在集群中作为独立的进程集运行,由主程序(称为驱动程序)中的SparkContext对象协调。
- 运行在一个集群上,SparkContext可以连接到几种类型的集群管理器(Spark自己独立的集群管理器,Mesos, YARN或Kubernetes),这些管理器在应用程序之间分配资源。
- 一旦连接上,Spark将获得集群中节点上的executor,这些executor是为应用程序运行计算和存储数据的进程。
- 接下来将应用程序代码(由传递给SparkContext的JAR或Python文件定义)发送给执行器。
- 最后,SparkContext将任务发送给执行器运行。
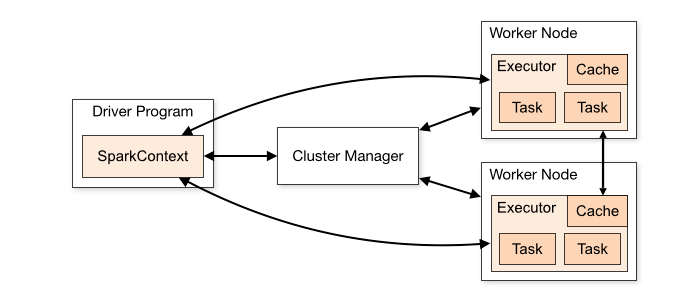
- 提交应用程序:可以使用spark-submit脚本将应用程序提交到任何类型的集群。
- 监控:Driver程序都有一个web UI,通常在4040端口上,显示关于正在运行的任务、执行器和存储使用的信息。只需在web浏览器中访问http://
:4040就可以访问这个WEB UI。 - 作业调度:Spark提供了跨应用程序(在集群管理器级别)和应用程序内部(如果多个计算发生在同一个SparkContext上)的资源分配控制。
集群术语
-
Application 基于Spark构建的用户程序。由集群上的驱动程序和执行程序组成。 Application jar 用户的Spark应用程序Jar,包含他们的应用程序及其依赖项。用户的jar包不应该包含Hadoop或Spark库(这些库会在运行时添加)。 Driver program 运行应用程序main()函数并创建SparkContext的进程 Cluster manager 获取集群资源的外部服务(例如standalone manager, Mesos, YARN, Kubernetes) Deploy mode 区分驱动进程运行的位置。在“集群”模式下,框架在集群内部启动驱动程序。在“客户端”模式下,提交者在集群外启动驱动程序。 Worker node 可以在集群中运行应用程序代码的任何节点 Executor 在工作节点上为应用程序启动的进程,它运行任务并跨任务将数据保存在内存或磁盘存储中。每个应用程序都有自己的执行器。 Task 将被发送到一个执行程序的工作单元 Job 由多个任务组成的并行计算,这些任务响应Spark操作(例如 save,collect)Stage 每个任务被分成更小的任务集,称为相互依赖的阶段(类似于MapReduce中的map和reduce阶段);
部署
概述
Spark作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。
容器式环境:发现集群规模不足够,会自动化生成所需要的环境,不需要多余集群机器时,也会自动删除。
Spark运行环境 = Java环境(JVM) + 集群环境(Yarn) + Spark环境(lib)
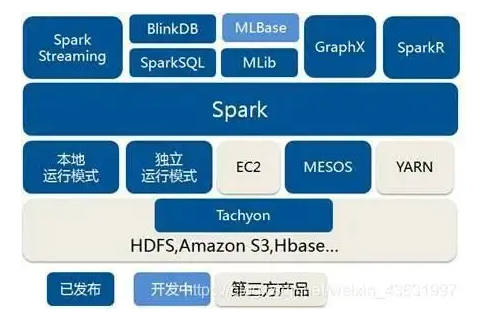
Spark既可以单独运行,也可以通过多个现有的集群管理器运行。目前它提供了几种部署选项
- Local模式:多用于本地测试,如在Idea中编写程序运行测试,本机提供资源 Spark提供计算。
- Standalone:Spark中自带的一个简单的资源调度框架,支持完全分布式。
- Apache Mesos:一个通用的资源管理和调度框架,也可以运行Hadoop MapReduce和服务应用程序。(弃用)
- Hadoop YARN:Hadoop 2和Hadoop 3中的资源管理器。Spark On Yarn是目前生产系统使用最多的部署方式
- Kubernetes:一个用于自动化部署、扩展和管理容器化应用程序的开源系统。Spark On K8s是未来的趋势
环境准备
由于前面的文章已经搭建过Hadoop,环境预准备条件是类似,比如至少3台机器的互通互联、免密登录、时间同步、JDK如1.8版本安装,这里就不再说明了。
Local模式
所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境
# 下载最新版本3.3.0
wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
# 解压
tar -xvf spark-3.3.0-bin-hadoop3.tgz
# 拷贝一个部署spark-local目录
spark-3.3.0-bin-hadoop3 spark-local
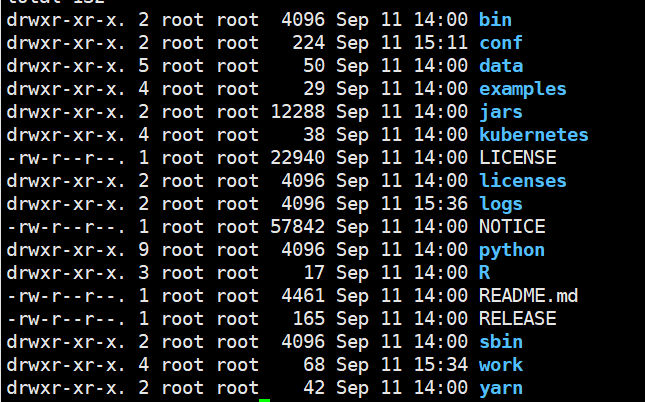
spark文件目录说明
- bin:可执行的二进制命令文件,脚本文件
- conf:配置文件,其中以.template后缀结尾的文件不会起作用,称为模板文件
- data:官方提供的教学数据
- examples:官方案例
- jars:官方案例的jar包
- src:官方案例的源码
- jars:当前spark的lib,类库
- kubernetes:容器式部署环境
- sbin:启动关闭的脚本命令
- python,R,yarn
# 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
参数说明:
- –class表示要执行程序的主类,此处可以更换为自己写的应用程序。
- –master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量。
- spark-examples_2.12-3.0.0.jar 运行的应用类所在的jar包,实际使用时,可以设定为自己打的jar包。
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
Standalone部署
Standalone模式
Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式,Spark的Standalone模式体现了经典的master-slave模式。
# 拷贝一个部署spark-standalone目录
cp -r spark-3.3.0-bin-hadoop3 spark-standalone
# 进入目录
cd spark-standalone/
cd conf
# 准备workers配置文件
mv workers.template workers
# 修改workers内容为
vi workers
hadoop1
hadoop2
hadoop3
# 准备spark-env.sh配置文件
mv spark-env.sh.template spark-env.sh
# spark-env.sh添加如下内容
vi spark-env.s
export JAVA_HOME=/home/commons/jdk8
SPARK_MASTER_HOST=hadoop1
SPARK_MASTER_PORT=7077
# 分发到其他两台上
scp -r /home/commons/spark-standalone hadoop2:/home/commons/
scp -r /home/commons/spark-standalone hadoop3:/home/commons/
# 进入根目录下sbin执行目录和启动
cd sbin/
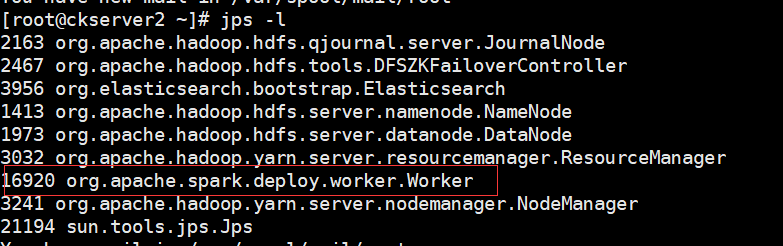
./start-all.sh

当前机器有Master和Worker进程,而另外其他两台上有worker进程
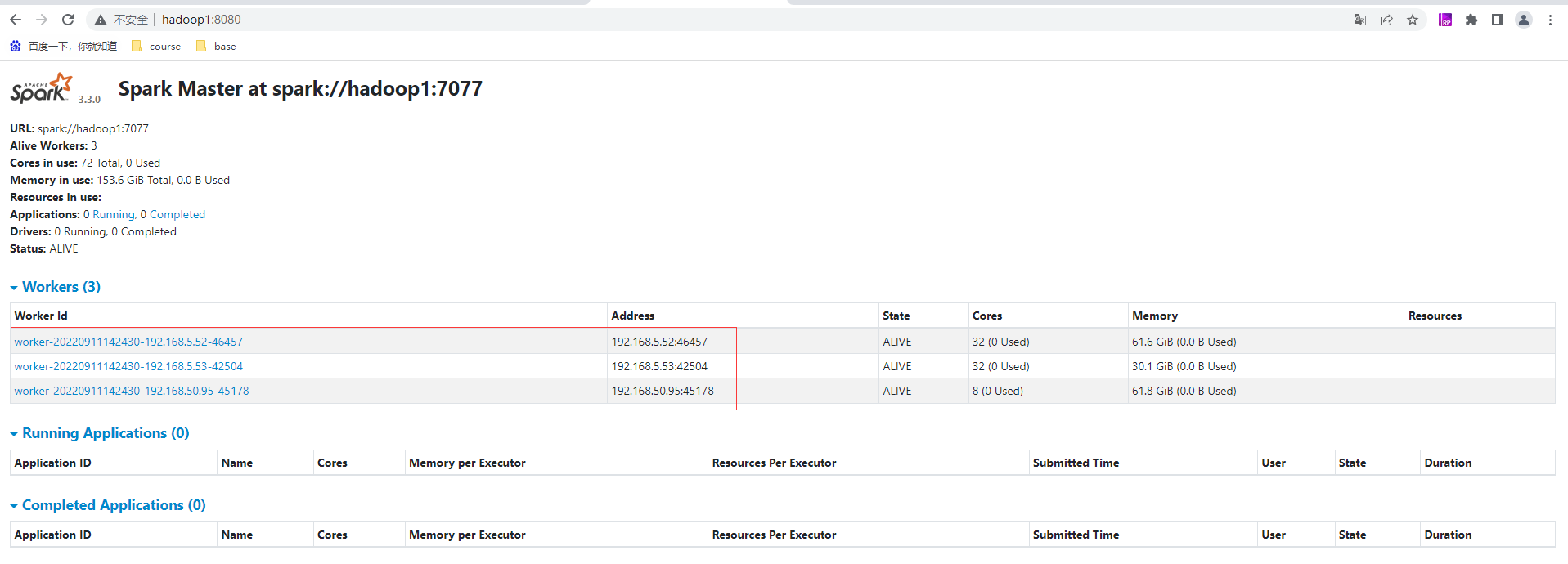
访问WebUi页面:http://hadoop1:8080/ ,如果8080端口有其他服务使用,可以访问8081端口也能正常访问到当前这个Master的页面(默认8081是Worker的)
配置历史服务
由于spark-shell 停止掉后,集群监控页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
# 先停止前面启动的集群
./stop-all.sh
# 准备spark-defaults.conf
cd ../conf
mv spark-defaults.conf.template spark-defaults.conf
# 修改spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myns:8020/sparkhis
# 需要启动Hadoop集群,HDFS上的目录需要提前存在
hadoop fs -mkdir /sparkhis
# 修改spark-env.sh文件,添加如下配置:
vi spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://myns:8020/sparkhis
-Dspark.history.retainedApplications=30"
# 参数1含义:WEBUI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径(读)
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
由于hadoop是HA模式因此配置为hdfs-site.xml下的dfs.nameservices的value值
<property>
<name>dfs.nameservices</name>
<value>myns</value> <!--core-site.xml的fs.defaultFS使用该属性值-->
</property>
# 分发配置到另外两台上
scp spark-defaults.conf spark-env.sh hadoop2:/home/commons/spark-standalone/conf/
scp spark-defaults.conf spark-env.sh hadoop3:/home/commons/spark-standalone/conf/
# 启动集群
./start-all.sh
# 启动历史服务
./start-history-server.sh
访问历史服务的WebUI地址,http://hadoop1:18080/
高可用(HA)
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置。这里使用前面搭建Zookeeper 。
# 停止集群
./stop-all.sh
# 停止历史服务
./stop-history-server.sh
# 修改Spark中的 spark-env.sh 文件,修改如下配置
# 注释如下内容
#SPARK_MASTER_HOST=hadoop1
#SPARK_MASTER_PORT=7077
# 添加如下内容
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=zk1,zk2,zk3
-Dspark.deploy.zookeeper.dir=/spark"
# 分发配置到另外两台上
scp spark-env.sh hadoop2:/home/commons/spark-standalone/conf/
scp spark-env.sh hadoop3:/home/commons/spark-standalone/conf/
# 启动集群
./start-all.sh
# 在另外服务器如hadoop2上启动master
./start-master.sh
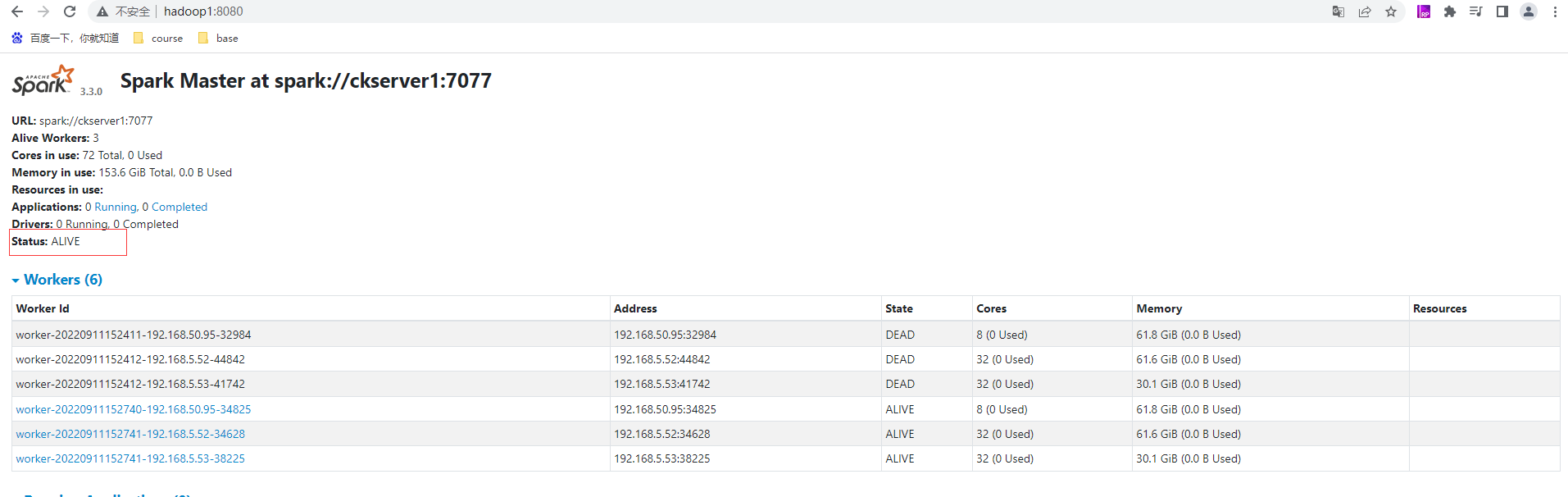
hadoop1的master为ALIVE状态
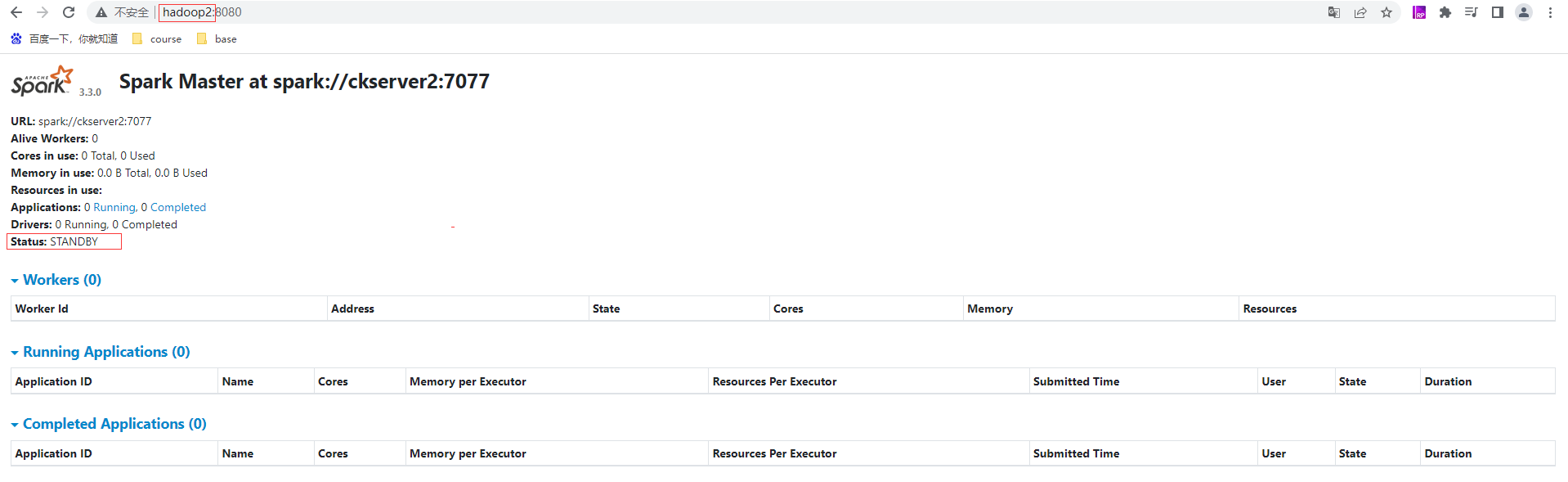
hadoop2的master为STANDBY状态
提交应用到高可用集群,注意提交master要填写多个master地址
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
# 停止mALIVE状态hadoop1的master
./stop-master.sh
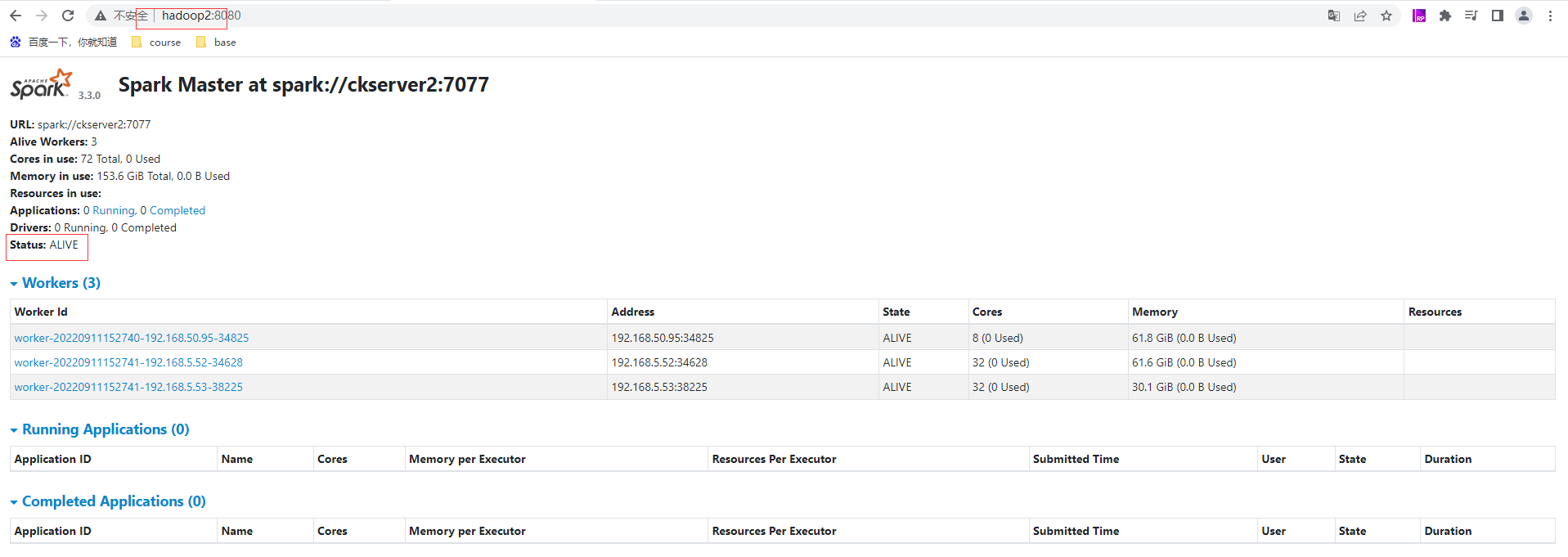
hadoop2的master由原来的STANDBY状态转变为ALIVE状态,实现高可用的切换
提交流程
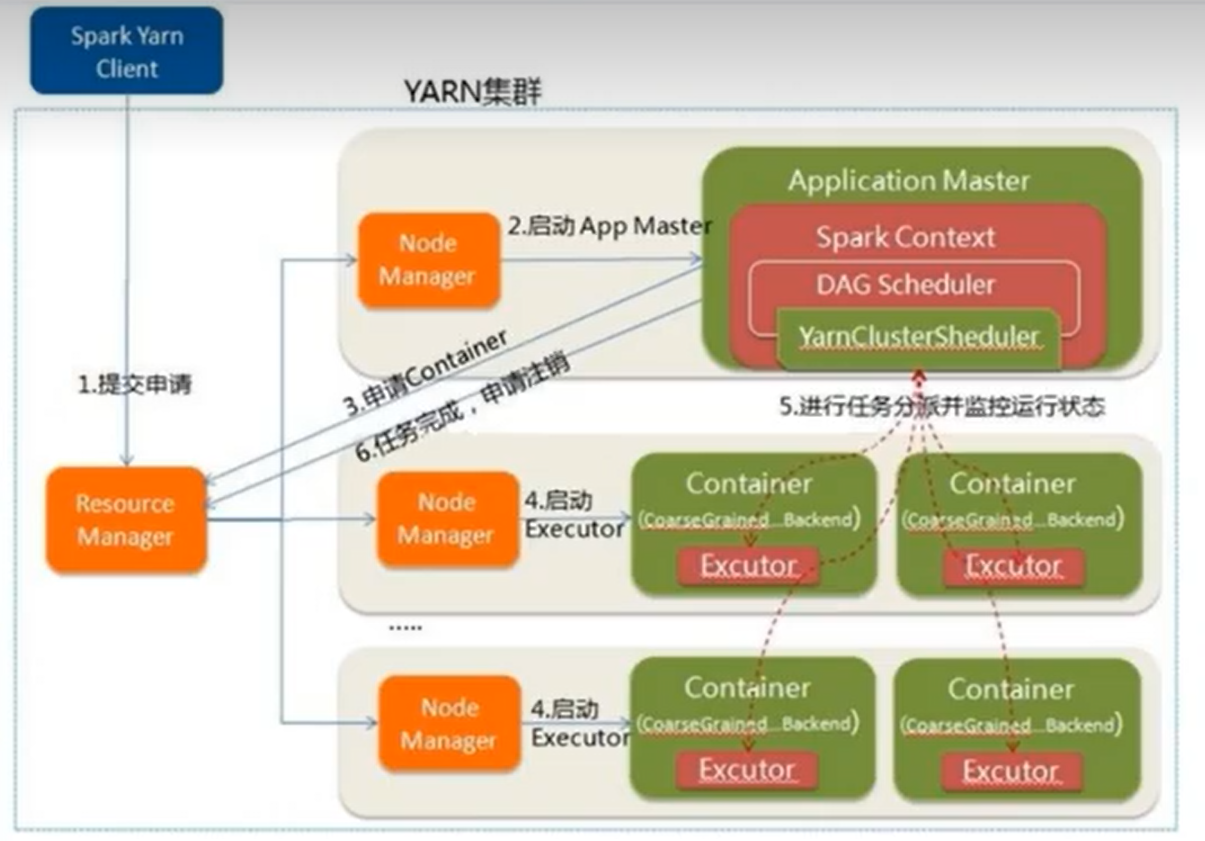
作业提交原理
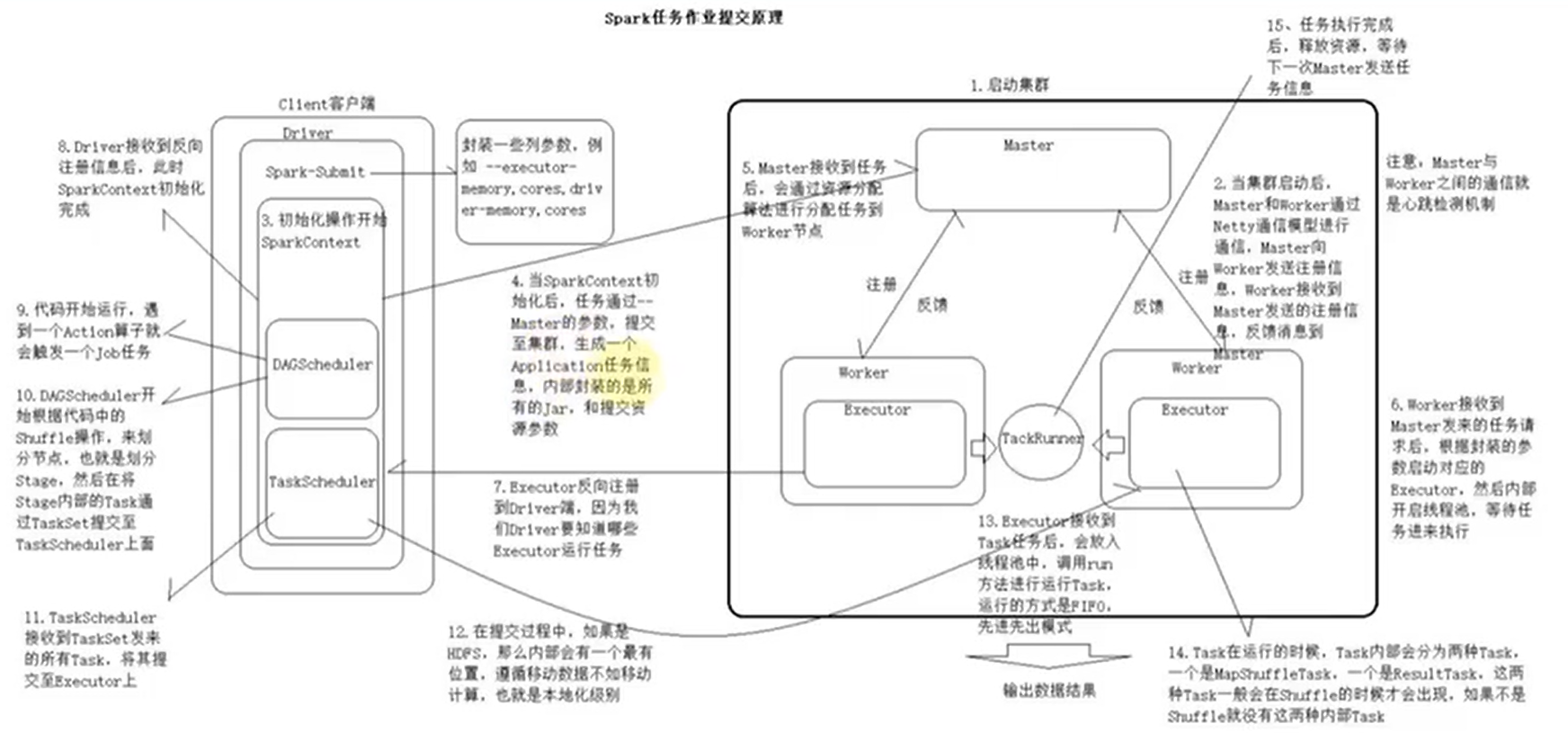
Standalone-client 提交任务方式
# --deploy-mode client 可以省略,默认为client
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
# 其他参数提交应用
bin/spark-submit \
--master spark://hadoop1:7077 \
--class org.apache.spark.examples.SparkPi \
--driver-memory 500m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
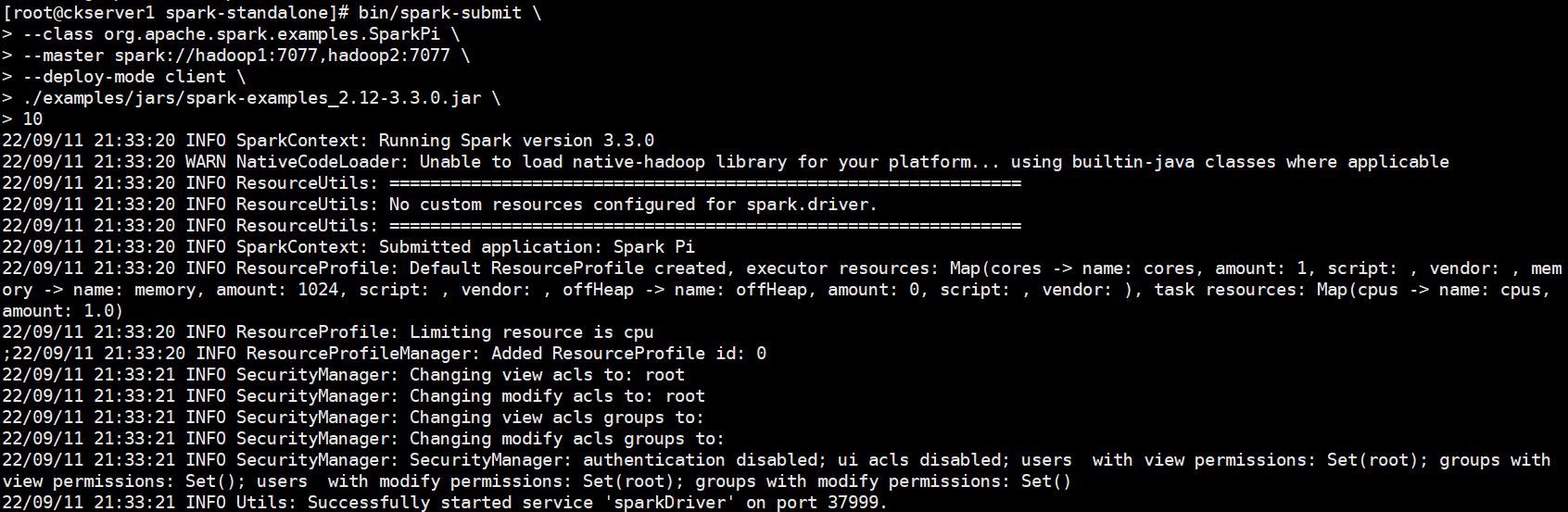
参数说明:
- --class:表示要执行程序的主类,Spark程序中包含主函数的类
- --master:Spark程序运行的模式(环境) 模式:local[*]、spark://hadoop101:7077、 Yarn,spark://hadoop101:7077 独立部署模式,连接到Spark集群,Mater的地址和端口号。
- --executor-memory 1G 指定每个executor可用内存为1G 符合集群内存配置即可,具体情况具体分析。
- --total-executor-cores 2 指定所有executor使用的cpu核数为2个。
- --executor-cores 指定每个executor使用的cpu核数。
- application-jar:打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path都包含同样的jar,spark-examples_2.12-3.0.0.jar 运行类所在的jar包
- application-arguments:数字10表示程序的入口参数,用于设定当前应用的任务数量
查看WebUI后可以看到刚刚提交的任务app-20220911213322-0000信息
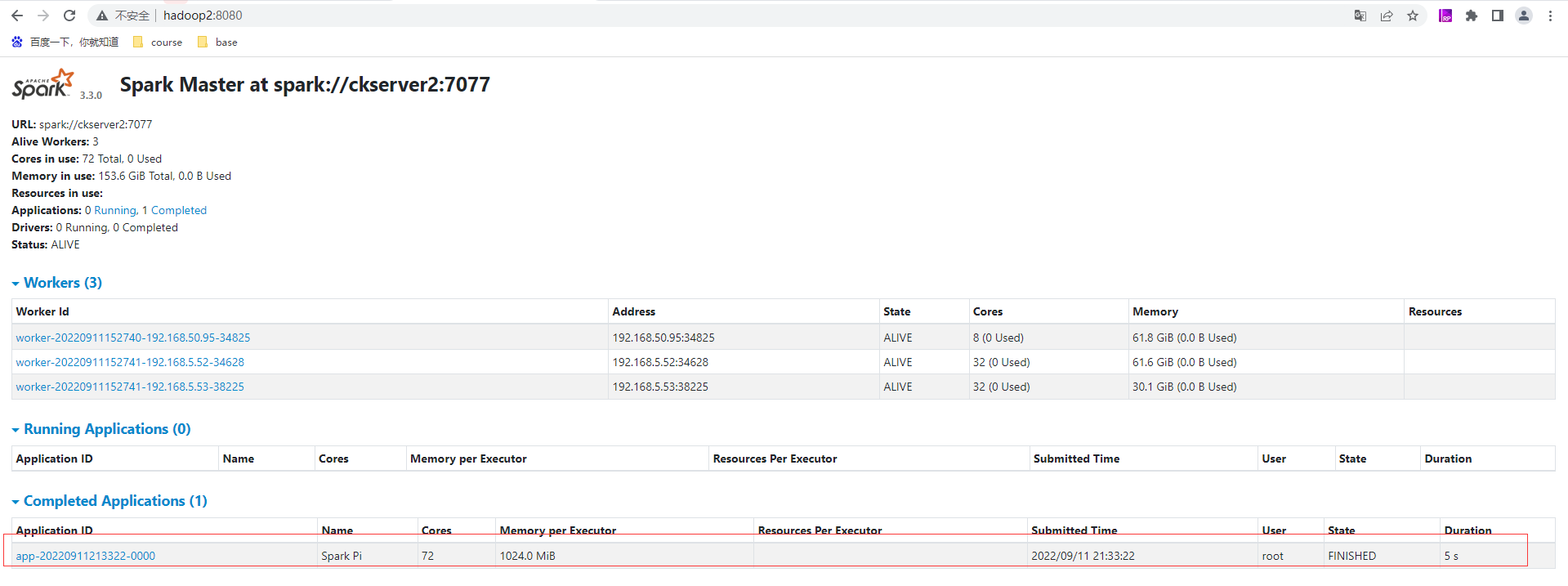
执行任务时,会产生多个Java进程(用于计算)执行完成就会释放掉。其中Master和Worker是资源,默认采用服务器集群节点的总核数,每个节点内存1024M。
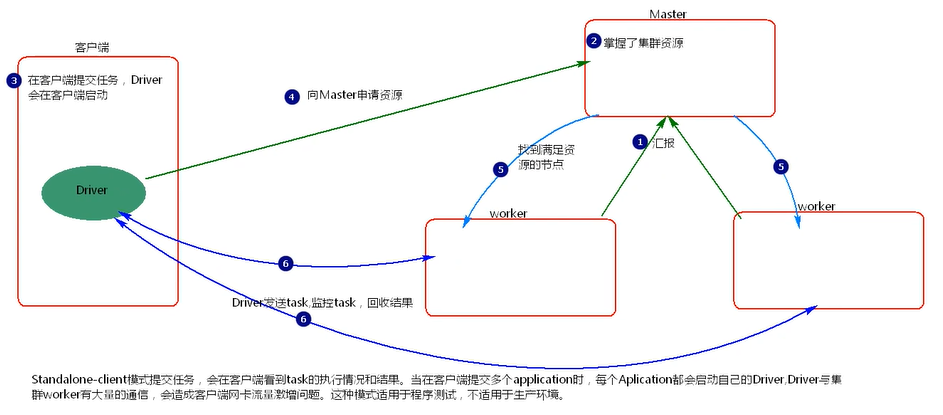
- client 模式提交任务后,会在客户端启动 Driver 进程。
- Driver 会向 Master 申请启动 Application 启动的资源。
- Master 收到请求之后会在对应的 Worker 节点上启动 Executor
- Executor 启动之后,会注册给 Driver 端,Driver 掌握一批计算 资源。
- Driver 端将 task 发送到 worker 端执行。worker 将 task 执行结 果返回到 Driver 端。
当在客户端提交多个Spark application时,每个application都会启动一个Driver。lient 模式适用于测试调试程序。Driver 进程是在客户端启动的,这里的客 户端就是指提交应用程序的当前节点。在 Driver 端可以看到 task 执行的情 况。生产环境下不能使用 client 模式,是因为:假设要提交 100 个,application 到集群运行,Driver 每次都会在 client 端启动,那么就会导致 客户端 100 次网卡流量暴增的问题。client 模式适用于程序测试,不适用 于生产环境,在客户端可以看到 task 的执行和结果
Standalone-cluster 提交任务方式
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077,hadoop2:7077 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
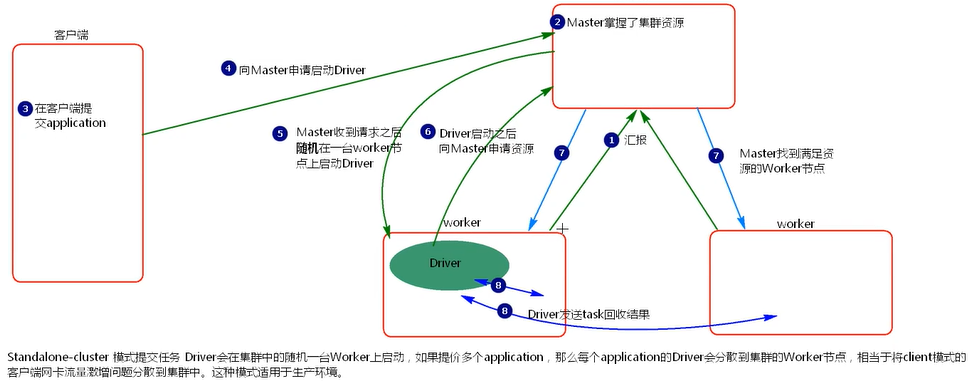
- cluster 模式提交应用程序后,会向 Master 请求启动 Driver
- Master 接受请求,随机在集群一台节点启动 Driver 进程。
- Driver 启动后为当前的应用程序申请资源。
- Driver 端发送 task 到 worker 节点上执行。
- worker 将执行情况和执行结果返回给 Driver 端。
Driver 进程是在集群某一台 Worker 上启动的,在客户端是无法查看 task 的执行情况的。假设要提交 100 个 application 到集群运行,每次 Driver 会 随机在集群中某一台 Worker 上启动,那么这 100 次网卡流量暴增的问题 就散布在集群上。
Yarn部署
独立部署(Standalone)模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是也要记住,Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来需要学习在强大的Yarn环境下Spark是如何工作的(其实是因为在国内工作中,Yarn使用的非常多)。
Yarn Client模式
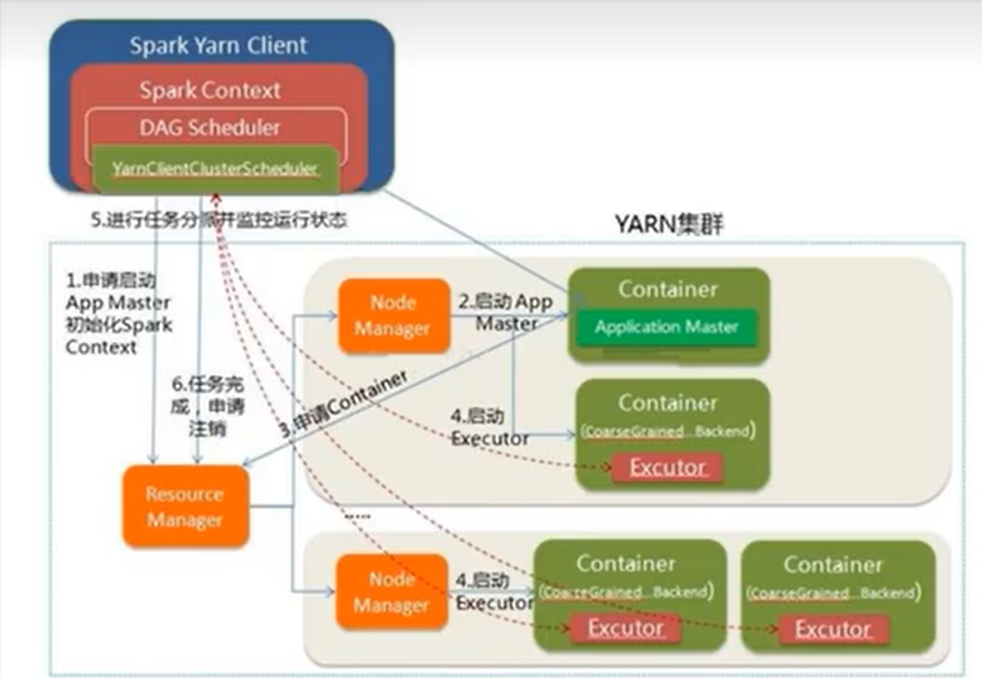
# 重新拷贝一个目录
cp -r spark-3.3.0-bin-hadoop3 spark-yarn
# 修改hadoop配置文件/home/commons/hadoop/etc/hadoop/yarn-site.xml,
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
# yarn-site.xml并分发到其他两台机器
scp /home/commons/hadoop/etc/hadoop/yarn-site.xml hadoop2:/home/commons/hadoop/etc/hadoop/
scp /home/commons/hadoop/etc/hadoop/yarn-site.xml hadoop3:/home/commons/hadoop/etc/hadoop/
# 重启Hadoop
cd /home/commons/hadoop/sbin
./stop-all.sh
./start-all.sh
# 修改conf目录三个配置文件,跟前面的类似稍微修改
mv workers.template workers
# 修改workers内容为
vi workers
hadoop1
hadoop2
hadoop3
# 准备spark-env.sh配置文件
mv spark-env.sh.template spark-env.sh
# 增加下面配置
vi spark-env.sh
export JAVA_HOME=/home/commons/jdk8
HADOOP_CONF_DIR=/home/commons/hadoop/etc/hadoop
YARN_CONF_DIR=/home/commons/hadoop/etc/hadoop
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://myns:8020/sparkhis
-Dspark.history.retainedApplications=30"
# 修改spark-defaults.conf.template文件名为spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
# 修改spark-default.conf文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myns:8020/sparkhis
spark.yarn.historyServer.address=hadoop1:18080
spark.history.ui.port=18080
# 启动历史服务
sbin/start-history-server.sh
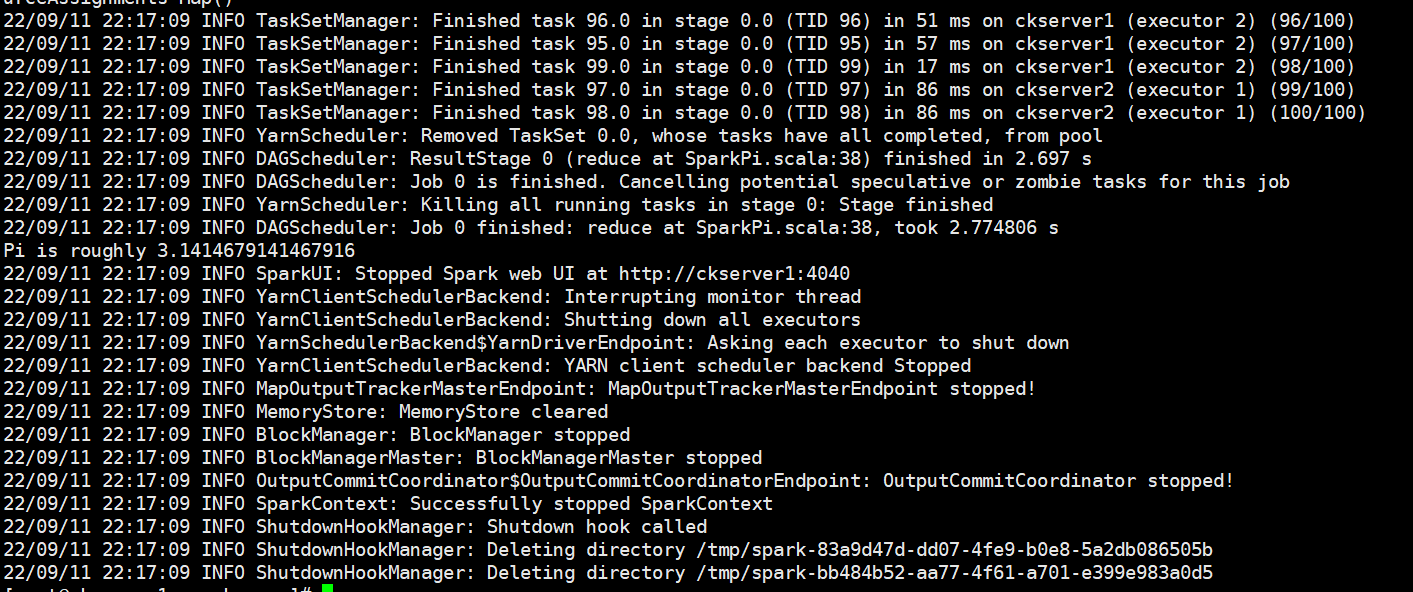
提交yarn client任务
bin/spark-submit \
--master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
--driver-memory 600m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
100
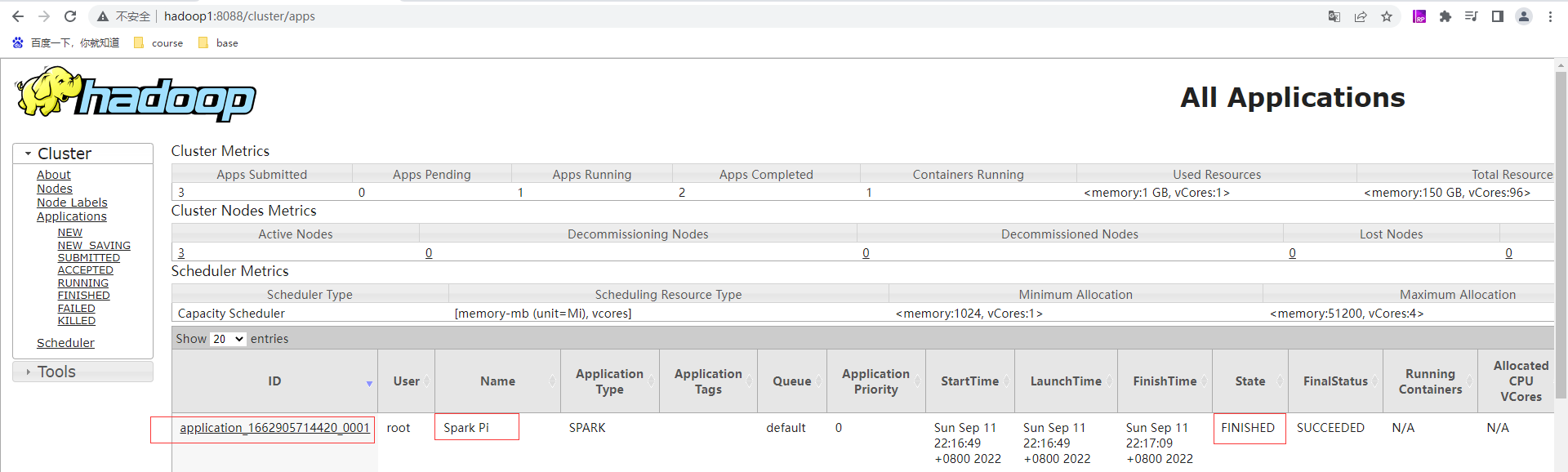
查看yarn的页面:http://hadoop1:8088/cluster 有刚才提交的应用application_1662905714420_0001为状态成功且已完成
Yarn Cluster模式
bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 600m \
--driver-cores 1 \
--executor-memory 800m \
--executor-cores 2 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
100
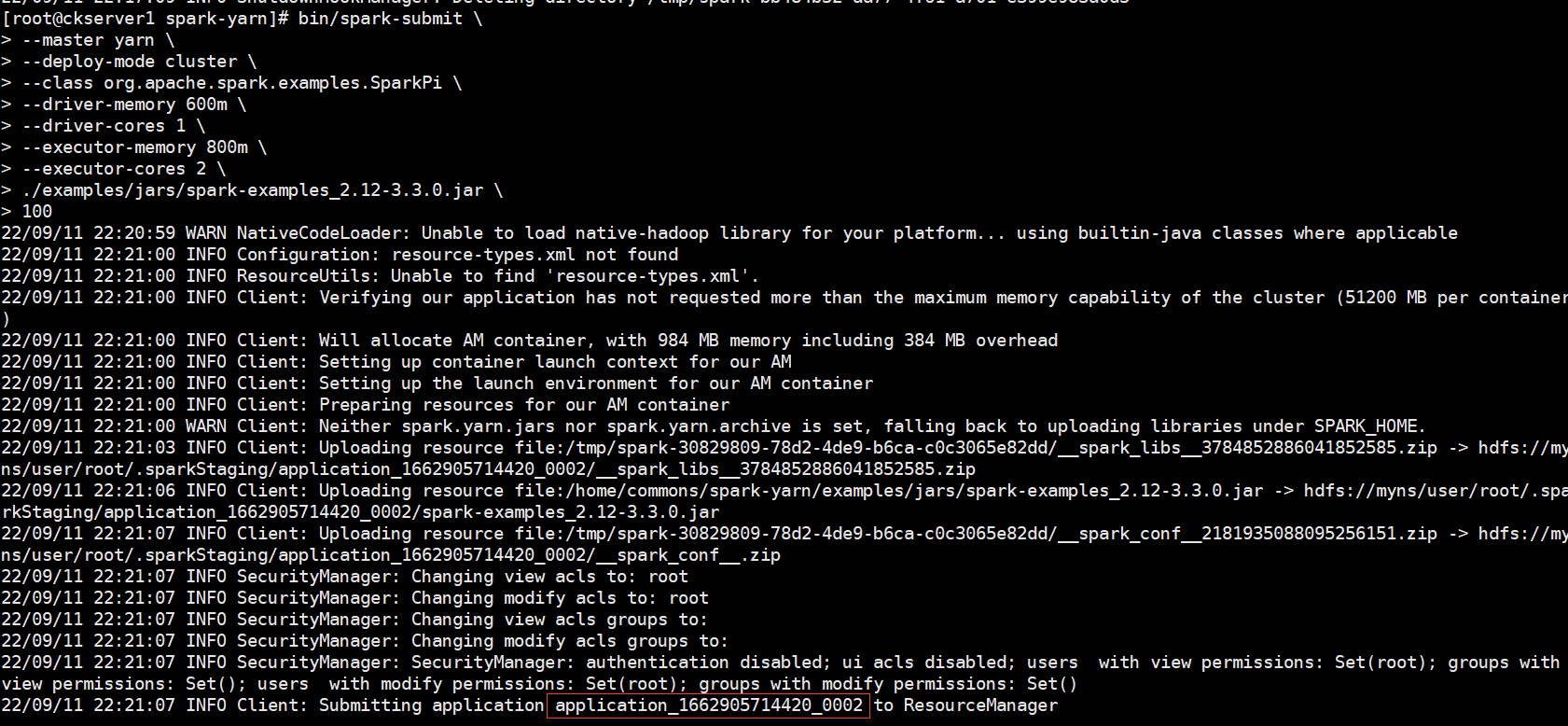
查看yarn的页面:http://hadoop1:8088/cluster 有刚才提交的应用application_1662905714420_0002为状态成功且已完成
Spark-Shell
在Spark Shell中,已经在名为sc的变量中为您创建了一个特殊的SparkContext,如果您自己创建SparkContext会不生效。您可以使用--master参数设置SparkContext连接到哪个主节点,并且可以通过--jars参数来设置添加到CLASSPATH的JAR包,多个JAR包时使用逗号(,)分隔。更多参数信息,您可以通过命令./bin/spark-shell --help获取。
- local模式
bin/spark-shell
# 启动成功后,可以输入网址进行Web UI监控页面访问
# http://虚拟机地址:4040
# 在解压缩文件夹下的data目录中,添加word.txt文件。在命令行工具中执行如下代码指令(和IDEA中代码简化版一致)
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
# 退出本地模式,尽量用命令退出
:quit
- Standalone模式
bin/spark-shell \
--master spark://hadoop1:7077
- Yarn Client模式,由于shell属于交互式方式,因此只有Yarn Client模式,没有Yarn Cluster模式
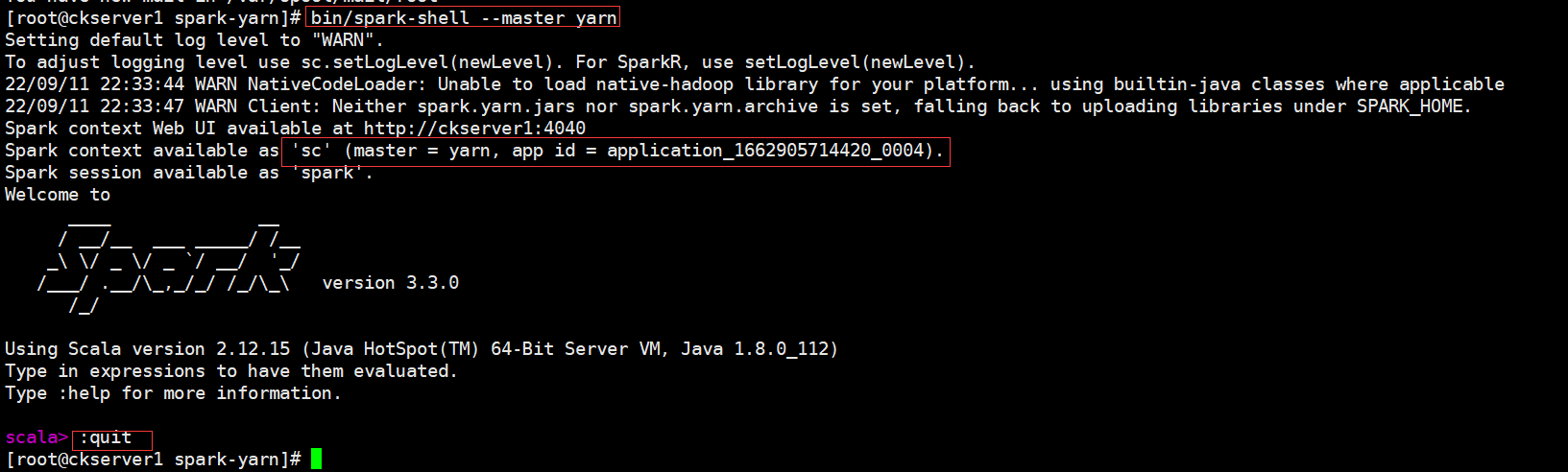
bin/spark-shell \
--master yarn
**本人博客网站 **IT小神 www.itxiaoshen.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号