

Flink如何计算一个需求,一个流的数据计算需要用到多个数据流的结果,通过Flink如何实现?
在 Apache Flink 中,处理多流联合计算的核心是状态管理和时间语义的结合。以下是对每种方案的详细解析,包括原理、优缺点、适用场景及代码示例:
1. Union:合并多个流
原理
- 数据合并:将多个结构相同的流合并为一个流,所有事件按到达顺序处理。
- 无状态操作:Union 是无状态的,不涉及数据关联或状态存储。
代码示例
java
| DataStream<Event> stream1 = ...; |
| DataStream<Event> stream2 = ...; |
| DataStream<Event> mergedStream = stream1.union(stream2); |
优点
- 简单高效:无需状态管理,延迟低。
- 高吞吐量:适合需要快速合并相同结构流的场景。
缺点
- 结构限制:所有流必须类型相同。
- 无区分性:合并后无法区分数据来源(如需标记来源需额外处理)。
适用场景
- 实时日志合并(如多个设备的日志统一分析)。
- 简单数据聚合(如统计所有订单的总数)。
2. Interval Join:基于时间区间的关联
原理
- 时间区间关联:在指定时间范围内(如订单时间与支付时间差在5分钟内)关联两个流的事件。
- 事件时间语义:基于数据自带的时间戳,通过水位线管理时间进度。
代码示例
java
| orders.keyBy(Order::getUserId) |
| .intervalJoin(payments.keyBy(Payment::getUserId)) |
| .between(Time.minutes(-5), Time.minutes(0)) |
| .process(new ProcessJoinFunction<Order, Payment, OrderWithPayment>() { |
| public void processElement(Order order, Payment payment, Context ctx, Collector<OrderWithPayment> out) { |
| out.collect(new OrderWithPayment(order, payment)); |
| } |
| }); |
优点
- 时间准确性:基于事件时间,适合乱序数据场景。
- 内置时间管理:自动处理水位线和迟到数据。
缺点
- 仅支持事件时间:无法直接用于处理时间场景。
- 固定时间范围:时间区间需提前设定,灵活性较低。
适用场景
- 订单与支付的关联(需在指定时间范围内完成)。
- 用户行为序列分析(如点击与下单的时间差)。
3. CoProcessFunction:自定义关联逻辑
原理
- 连接流:通过
connect方法合并两个不同类型的流。 - 键控状态:使用
KeyedState存储中间状态,确保同一键的数据能正确关联。 - 双向处理:分别定义处理两个流的逻辑(
processElement1和processElement2)。
代码示例
java
| orders.connect(payments) |
| .keyBy(order -> order.orderId, payment -> payment.orderId) |
| .process(new KeyedCoProcessFunction<String, Order, Payment, OrderWithPayment>() { |
| private ValueState<Order> orderState; |
| private ValueState<Payment> paymentState; |
| public void open(Configuration config) { |
| orderState = getRuntimeContext().getState(new ValueStateDescriptor<>("order", Order.class)); |
| paymentState = getRuntimeContext().getState(new ValueStateDescriptor<>("payment", Payment.class)); |
| } |
| public void processElement1(Order order, Context ctx, Collector<OrderWithPayment> out) { |
| Payment payment = paymentState.value(); |
| if (payment != null) { |
| out.collect(new OrderWithPayment(order, payment)); |
| paymentState.clear(); |
| } else { |
| orderState.update(order); |
| } |
| } |
| public void processElement2(Payment payment, Context ctx, Collector<OrderWithPayment> out) { |
| Order order = orderState.value(); |
| if (order != null) { |
| out.collect(new OrderWithPayment(order, payment)); |
| orderState.clear(); |
| } else { |
| paymentState.update(payment); |
| } |
| } |
| }); |
优点
- 高度灵活:可实现复杂关联逻辑(如双向状态管理)。
- 状态控制:手动管理状态,适合需要精确控制数据生命周期的场景。
缺点
- 开发复杂度高:需手动处理状态和清理逻辑。
- 性能开销:状态管理可能带来额外资源消耗。
适用场景
- 订单与支付的双向关联(需同时处理订单和支付事件)。
- 复杂事件处理(如检测特定序列的事件)。
4. Window Join:基于窗口的关联
原理
- 窗口分片:将数据按窗口(如时间窗口、计数窗口)分片。
- 窗口内关联:在窗口结束时,对窗口内的数据进行关联计算。
代码示例
java
| DataStream<Order> orders = ...; |
| DataStream<Payment> payments = ...; |
| orders.keyBy(Order::getUserId) |
| .window(TumblingEventTimeWindows.of(Time.minutes(5))) |
| .join(payments.keyBy(Payment::getUserId)) |
| .apply(new JoinFunction<Order, Payment, OrderWithPayment>() { |
| public OrderWithPayment join(Order order, Payment payment) { |
| return new OrderWithPayment(order, payment); |
| } |
| }); |
优点
- 批量处理:适合需要批量分析的场景(如每日统计)。
- 结果确定性:窗口关闭后结果固定,便于后续处理。
缺点
- 延迟较高:需等待窗口关闭才能输出结果。
- 数据不可修改:窗口关闭后无法处理迟到数据(需结合
allowedLateness)。
适用场景
- 每日活跃用户统计(需按天窗口聚合)。
- 批量关联分析(如每小时订单与支付的总数关联)。
5. 扩展方案:广播状态(Broadcast State)
原理
- 广播维度数据:将维度数据(如用户黑名单、配置信息)广播到所有并行实例。
- 连接主流:通过
connect方法将广播流与主流连接,实现动态更新。
代码示例
java
| // 定义广播流(用户黑名单) |
| DataStream<UserBlacklist> broadcastStream = ...; |
| // 定义主流(用户行为) |
| DataStream<UserAction> mainStream = ...; |
| // 广播状态描述 |
| MapStateDescriptor<Void, UserBlacklist> broadcastStateDesc = new MapStateDescriptor<>( |
| "blacklist", |
| Types.VOID, |
| Types.POJO(UserBlacklist.class) |
| ); |
| // 连接流并处理 |
| mainStream.connect(broadcastStream.broadcast(broadcastStateDesc)) |
| .process(new BroadcastProcessFunction<UserAction, UserBlacklist, UserAction>() { |
| private SetState<Boolean> isBlocked; |
| public void open(Configuration config) { |
| isBlocked = getRuntimeContext().getState(new SetStateDescriptor<>("isBlocked", Boolean.class)); |
| } |
| public void processElement(UserAction action, ReadOnlyContext ctx, Collector<UserAction> out) { |
| if (isBlocked.value().orElse(false)) { |
| // 用户被屏蔽,不输出 |
| } else { |
| out.collect(action); |
| } |
| } |
| public void processBroadcastElement(UserBlacklist blacklist, Context ctx, Collector<UserAction> out) { |
| ctx.getBroadcastState(broadcastStateDesc).put(blacklist.getUserId(), blacklist); |
| isBlocked.add(true); |
| } |
| }); |
优点
- 动态更新:维度数据可实时更新,并广播到所有实例。
- 低延迟:主流处理无需等待广播数据同步。
缺点
- 资源消耗:广播数据需存储在所有并行实例中。
- 复杂度:需处理广播状态与主流的关联逻辑。
适用场景
- 实时过滤(如根据动态更新的黑名单过滤用户)。
- 动态配置更新(如实时调整计算规则)。
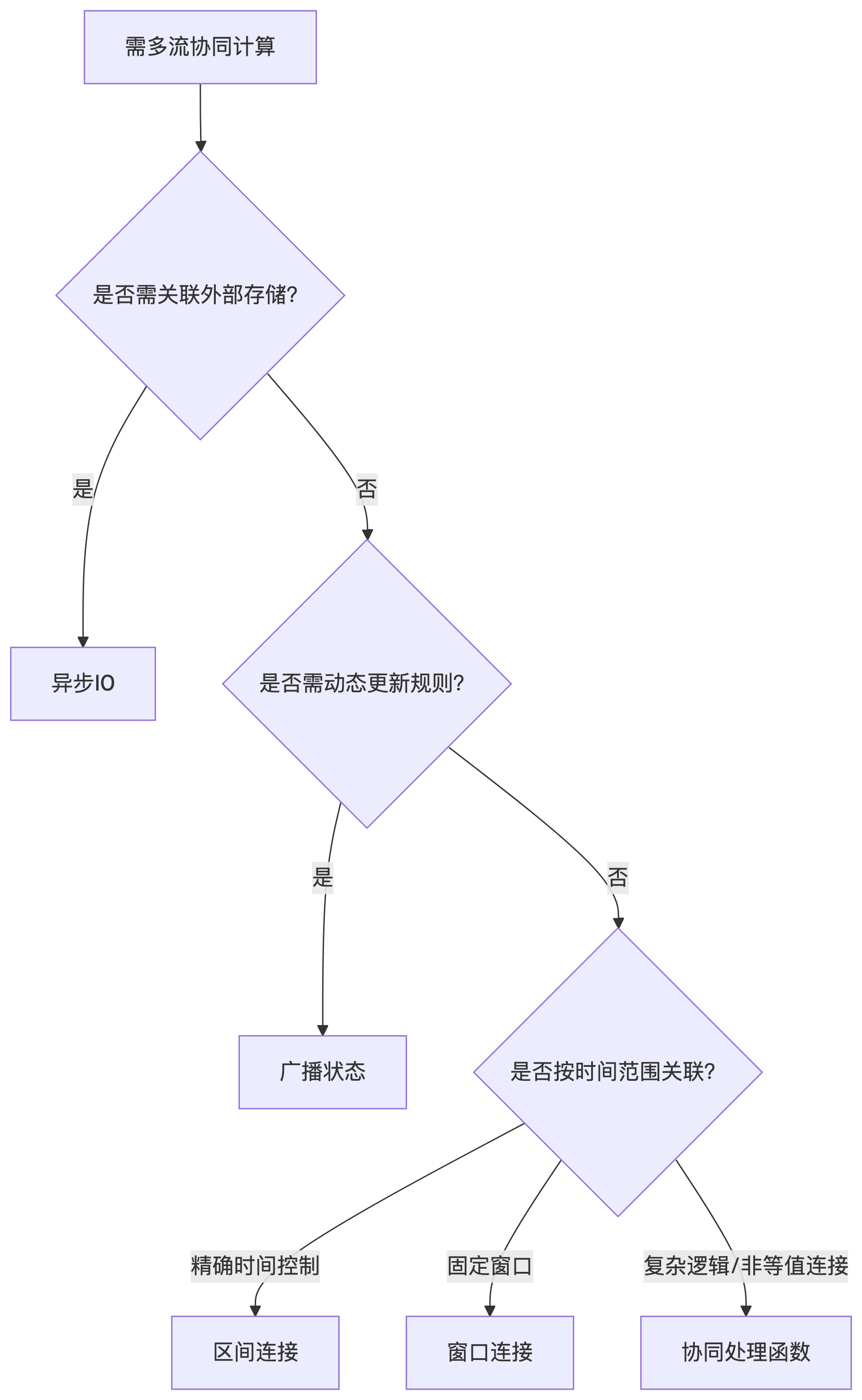
总结:方案选择指南
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Union | 合并相同结构流,无需关联 | 简单高效,低延迟 | 结构限制,无法区分来源 |
| Interval Join | 时间区间内的事件关联(如订单与支付) | 时间准确,内置管理 | 仅支持事件时间,灵活性低 |
| CoProcessFunction | 复杂关联逻辑(如双向状态管理) | 高度灵活,状态控制精确 | 开发复杂,性能开销 |
| Window Join | 基于窗口的批量关联(如每日统计) | 结果确定,适合批量分析 | 延迟高,数据不可修改 |
| Broadcast State | 动态维度数据关联(如用户黑名单) | 实时更新,低延迟 | 资源消耗,复杂度高 |
通过理解每种方案的原理和 trade-offs,您可以根据业务需求(如实时性要求、数据延迟分布、关联逻辑复杂度)选择最合适的方案。
关键陷阱与优化
-
水位线对齐问题
-
多流需保证水位线同步:
stream1.assignTimestampsAndWatermarks()和stream2.assignTimestampsAndWatermarks()使用相同策略 -
解决乱序:在
CoProcessFunction中用水位线触发计算ctx.timerService().registerEventTimeTimer()
-
-
状态爆炸预防
// 为状态设置TTL StateTtlConfig ttlConfig = StateTtlConfig .newBuilder(Time.minutes(30)) .cleanupInRocksdbCompactFilter(1000) // RocksDB专用优化 .build(); stateDescriptor.enableTimeToLive(ttlConfig); -
资源隔离
// 避免Join操作影响Source dataStream.flatMap(...).slotSharingGroup("transform") .join(otherStream).slotSharingGroup("join"); -
异步IO性能调优
AsyncDataStream.orderedWait( input, new AsyncFunction(), 500, // 超时时间(ms) 10000, // 最大并发请求数 AsyncDataStream.OutputMode.ORDERED // 或 UNORDERED );
实战案例对比
| 场景 | 最佳方案 | 原因 |
|---|---|---|
| 实时广告曝光-点击归因 | 区间连接 | 需要精确匹配点击发生在曝光后 0~10 分钟 |
| 用户行为画像更新 | 广播状态 | 画像规则量小(KB级)且需秒级更新至所有任务 |
| 订单关联商品库存 | 异步IO | 商品信息在HBase中存储,需高并发查询 |
| 金融交易风控 | 协同处理函数 | 需组合交易流、黑名单流、并自定义复杂规则(如:同设备多账号高频交易) |
通过深入理解各方案底层机制,可有效规避生产环境中的性能瓶颈与语义错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号