

rocketMQ,rabbitMQ, kafakaMQ的高可用性如何保证(ds)
消息队列的高可用性(High Availability, HA)是分布式系统设计的核心目标,主要通过冗余部署、数据复制、故障自动转移等机制实现。以下针对 RocketMQ、RabbitMQ、Kafka 的高可用机制进行详细分析:
🚀 一、RocketMQ 的高可用性
RocketMQ 采用 主从架构(Master-Slave) 结合 NameServer 协调 实现高可用:
-
主从数据同步
-
同步复制(SYNC_MASTER):消息写入 Master 后,需等待 Slave 确认才返回成功,保证数据零丢失(RPO=0),但延迟较高110。
-
异步复制(ASYNC_MASTER):Master 写入后立即返回,Slave 异步同步,性能高但故障时可能丢失少量数据410。
-
-
故障自动切换
-
当 Master 宕机时,消费者自动切换到 Slave 读取消息,确保消费不中断710。
-
生产端通过将 Topic 的队列(MessageQueue)分散到多个 Broker 组,避免单点故障影响全局7。
-
-
NameServer 轻量级协调
-
多节点部署,无状态且互不通信,通过心跳检测 Broker 存活状态,提供路由信息热备份710。
-
无状态:含义:NameServer 自身不存储任何与客户端会话或持久化状态相关的数据。它内存中维护的路由信息表完全来源于 Broker 的主动注册和心跳维护。
-
互不通信:含义: NameServer 集群中的各个节点之间不进行任何数据同步或协调通信。 它们是彼此独立的、隔离的。
-
轻量级协调:轻量级: 指的是 NameServer 本身的实现相对简单、资源消耗(CPU、内存)低、启动速度快、部署和维护成本低。它不需要复杂的选主逻辑、数据持久化(或仅需非常简单的持久化/恢复机制)、事务处理等。
-
-
-
多副本优化(v5.0)
-
引入 DLedger Controller 插件化选举,支持跨机房部署,优化 RTO(恢复时间)4。
-
- 事务消息
-
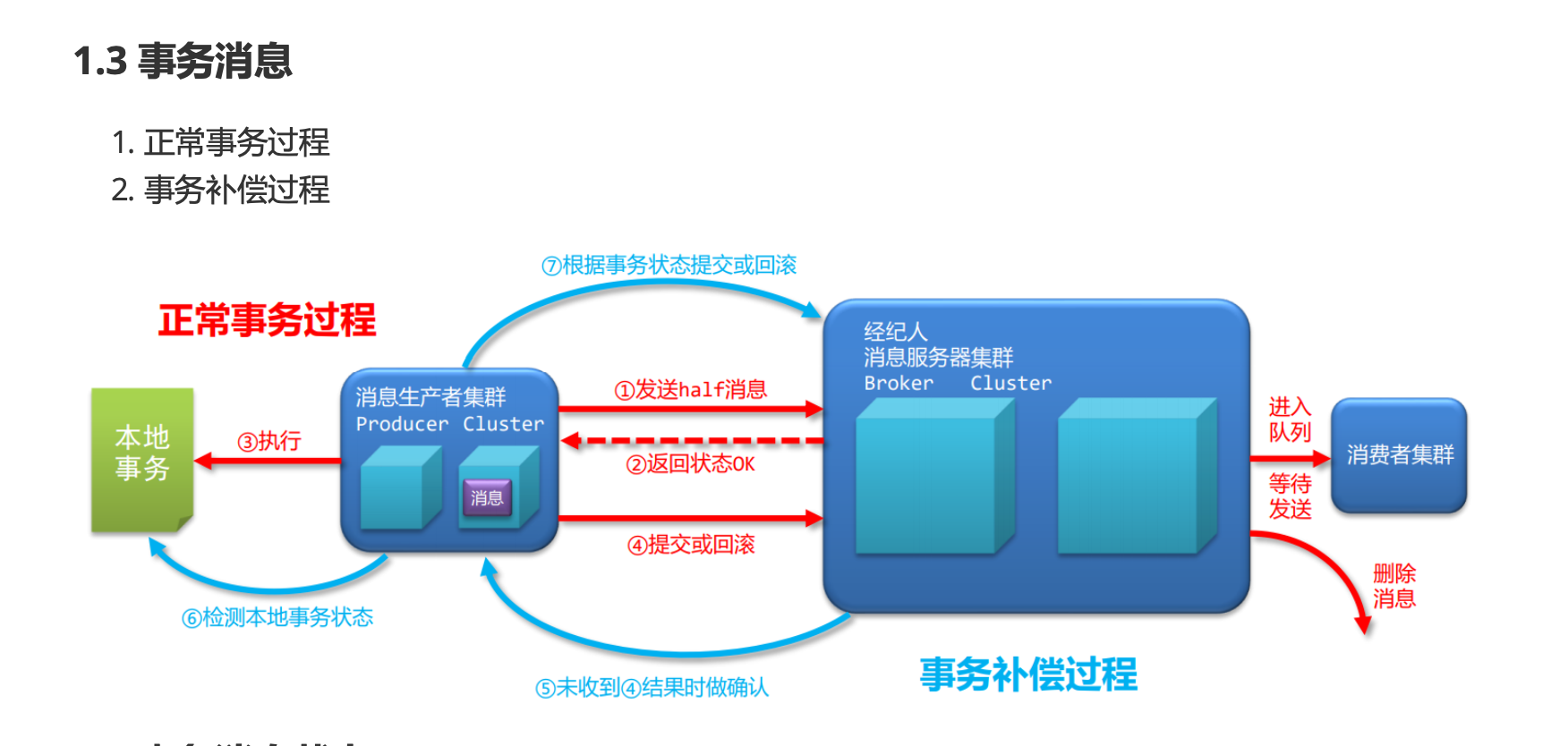
对比 Kafka 的 Zookeeper
适用场景:金融交易等强一致性场景用同步复制;日志采集等高性能场景用异步复制。
🐇 二、RabbitMQ 的高可用性
RabbitMQ 通过 镜像集群模式(Mirror Queue) 实现高可用,但需权衡性能与扩展性258:
-
三种集群模式对比
模式 数据同步方式 高可用性 缺点 单机模式 无 ❌ 仅用于测试 普通集群模式 仅同步元数据,消息存单一节点 ❌ 节点故障导致队列不可用 镜像集群模式 队列数据全节点同步 ✅ 网络开销大,扩展性差 -
镜像集群核心机制
-
数据强同步:生产者写入消息时,队列数据实时复制到所有节点(可通过策略控制同步节点数量)28。
-
故障无缝切换:任意节点宕机,客户端自动连接其他节点继续服务5。
-
-
持久化与负载均衡
-
消息持久化(磁盘)+ 队列持久化,防止节点重启数据丢失5。
-
配合 HAProxy 实现负载均衡,分散连接压力5。
-
局限:全量同步导致网络带宽压力大,且队列无法水平扩展(所有节点存储全量数据)8。
📊 三、Kafka 的高可用性
Kafka 通过 分区多副本 + ISR 机制 + KRaft 共识 实现高可用与强扩展性:
-
分区副本与 ISR 列表
-
每个分区(Partition)配置多个副本(Replica),分布在不同 Broker9。
-
Leader 副本处理读写,Follower 副本异步同步数据。
-
ISR(In-Sync Replicas):与 Leader 数据延迟在阈值内的副本集合。消息需被所有 ISR 确认后才视为提交(
acks=all)9。
-
-
故障自动转移
-
Leader 宕机时,控制器(Controller)从 ISR 中选举新 Leader,秒级切换96。
-
-
KRaft 模式(Kafka 4.0+)
-
取代 ZooKeeper,内置 Raft 协议管理元数据,减少运维复杂度36。
-
元数据存储于
__cluster_metadata主题,通过日志复制实现强一致性6。
-
-
增量重平衡协议(Kafka 4.0+)(KIP-848)
-
消费者组故障时仅局部协调,避免全局暂停,万级消费者组重平衡时间从分钟级降至秒级36。
-
优势:支持十万级分区、横向扩展性强,适合大数据场景9。
💎 四、三种消息队列高可用对比总结
| 特性 | RocketMQ | RabbitMQ | Kafka |
|---|---|---|---|
| 核心架构 | 主从 + NameServer | 镜像队列 | 分区多副本 + KRaft |
| 数据同步 | 同步/异步复制 | 全节点强同步 | ISR 列表异步同步 |
| 故障恢复 | 秒级切换 Slave | 秒级切换节点 | 秒级选举新 Leader |
| 扩展性 | 中等(依赖 Broker 组拆分) | 低(队列数据全量复制) | 高(分区水平扩展) |
| 适用场景 | 电商订单、事务消息 | 企业级应用、中小规模队列 | 日志处理、大数据流 |
设计取舍:
RocketMQ:平衡一致性与性能,适合中等规模事务场景。
RabbitMQ:强可用但牺牲扩展性,适合中小型企业应用。
Kafka:高吞吐与水平扩展优先,适合海量数据场景。
建议根据业务需求选择:强一致性选 RocketMQ 同步复制;简易高可用选 RabbitMQ 镜像模式;超大规模选 Kafka。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号