
idea全局搜索正则表达式同时匹配多个关键字
场景:项目安全扫描需要对打印了token、password、session等关键字的日志进行优化
^.*(log\.).*(token|session|password)
该正则可以同时匹配log.和token或者session或者password同时出现的代码
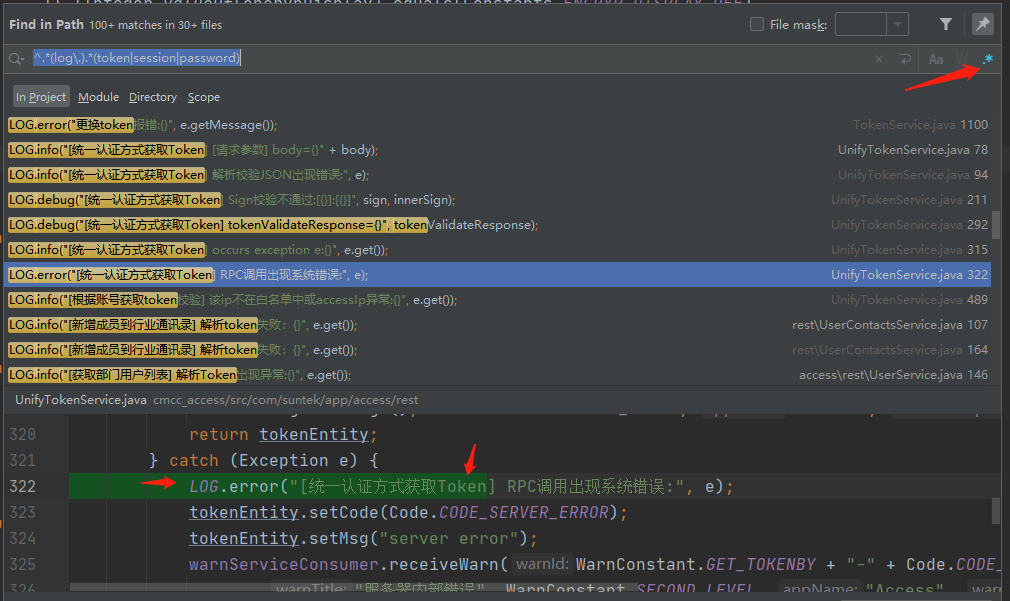
该正则表达式 ^.*(log\.).*(token|session|password) 用于匹配包含敏感信息的字符串,具体含义如下:
结构解析
-
^
表示匹配从字符串的开头开始。 -
.*-
.匹配任意单个字符(除换行符)。 -
*表示前一个元素(此处为.)可以重复 0 次或多次。 -
组合
.*表示匹配任意长度的任意字符(包括空字符串)。
-
-
(log\.)-
log\.匹配字面字符串log.(反斜杠\用于转义.,使其匹配实际点号)。 -
括号
()表示捕获组,记录匹配到的log.。
-
-
.*
再次匹配任意长度的任意字符,允许在log.后存在其他内容。 -
(token|session|password)-
|表示逻辑“或”,匹配token、session或password中的任意一个。 -
括号
()形成第二个捕获组,记录匹配到的敏感词。
-
功能说明
-
目标场景
检测字符串中是否包含log.后跟敏感词(token、session、password),常见于检查日志文件是否意外记录敏感信息(如认证凭据),防止安全泄露。 -
匹配示例
-
"error.log.token=abc123"✅ -
"debug_log.session_id=xyz"✅ -
"system.log.password_reset"✅ -
"log.token_invalid"✅
-
-
不匹配示例
-
"Token is invalid"❌(缺少log.) -
"log_entry.data"❌(缺少敏感词) -
"LOG.PASSWORD"❌(默认区分大小写,大写不匹配)
-
潜在问题
-
误报风险
-
.*可能导致过度匹配,如"clog.xyzpassword"(实际意图可能是clog+xpassword,但会被误判为含log.+password)。
-
-
性能影响
-
.*是贪婪匹配,可能影响效率,尤其在长文本中。可改用非贪婪.*?(如^.*?(log\.).*?(token|session|password)),但需权衡准确性。
-
-
大小写敏感
-
默认区分大小写,若需匹配大小写混合形式(如
Log.TOKEN),可添加修饰符(如i标志):^.*(log\.).*(token|session|password)/i
-
改进建议
-
精确限定范围
若需确保log.与敏感词相邻,可减少中间字符的随意性:^.*log\.\w+(token|session|password)\b匹配
log.后接单词字符(\w+)及敏感词(\b表示单词边界)。 -
排除干扰字符
限制中间字符类型,如仅允许字母、数字和下划线:^.*log\.([a-zA-Z0-9_]+\.)*(token|session|password)
总结
该正则表达式用于识别含 log. 后接敏感词的字符串,适用于安全审计场景,但需注意误报和性能问题,可根据实际需求调整精确度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号